[Paper Short Review] Unified Language-Vision Pretraining in LLM with Dynamic Discrete Visual Tokenization (LAVIT)
Paper Review
목록 보기
4/4
Unified Language-Vision Pretraining in LLM with Dynamic Discrete Visual Tokenization
Yang Jin, Kun Xu, Kun Xu, Liwei Chen, Chao Liao, Jianchao Tan, Quzhe Huang, Bin Chen, Chenyi Lei, An Liu, Chengru Song, Xiaoqiang Lei, Di Zhang, Wenwu Ou, Kun Gai, Yadong Mu
Peking University, Kuaishou Technology
23.09
official: git
Summarization
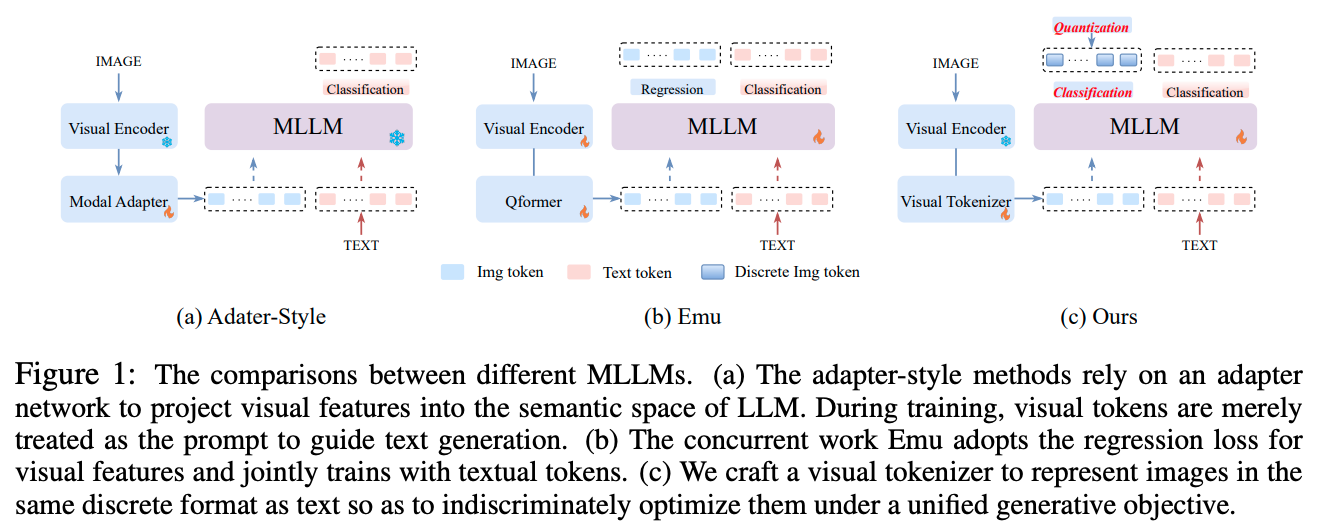
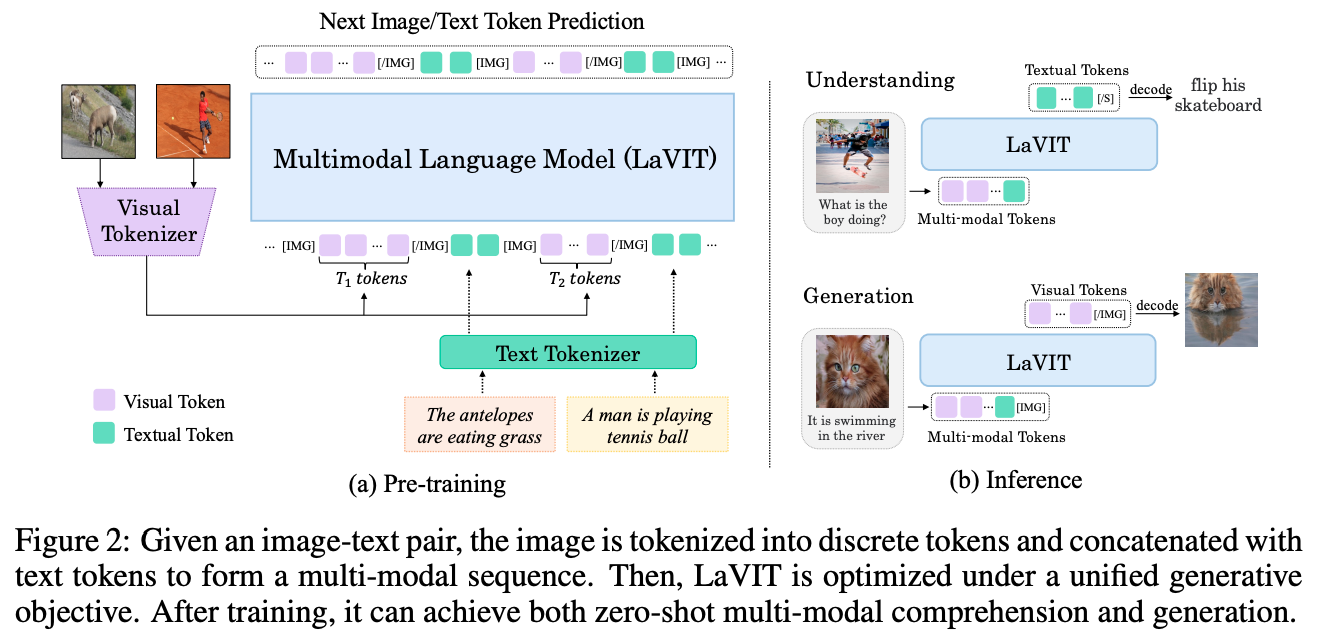
Dynamic Visual Tokenizer 사용해, 이미지 내에서 중요하다고 생각되는 영역 추출해 내 사용
Code 분석
Understanding Model Generation 부분
LAVIT/models/lavit_for_understanding.py의 일부
-
def generate( self, samples, use_nucleus_sampling=False, num_beams=2, max_length=36, min_length=8, top_p=1.0, top_k=50, repetition_penalty=1, length_penalty=1, num_captions=1, temperature=1, **kwargs ): """ Usage: Generate the textual caption of input images Args: samples (dict): A dictionary containing the following keys: - image (torch.Tensor): A tensor of shape (batch_size, 3, H, W) use_nucleus_sampling (bool): Whether to use nucleus sampling. If False, use top-k sampling. num_beams (int): Number of beams for beam search. 1 means no beam search. max_length (int): The maximum length of the sequence to be generated. min_length (int): The minimum length of the sequence to be generated. top_p (float): The cumulative probability for nucleus sampling. repetition_penalty (float): The parameter for repetition penalty. 1.0 means no penalty. num_captions (int): Number of captions to be generated for each image. Returns: captions (list): A list of strings of length batch_size * num_captions. """ image = self.process_image(samples["image"]) if "prompt" in samples.keys(): prompt = samples["prompt"] else: prompt = '' # Prepare image token ids with self.maybe_autocast(): image_embeds, image_attns = self.compute_dynamic_visual_embeds(image) if prompt != "": if isinstance(prompt, str): prompt = [prompt] * image.size(0) else: assert len(prompt) == image.size( 0 ), "The number of prompts must be equal to the batch size." self.llama_tokenizer.padding_side = "left" prompt_tokens = self.llama_tokenizer( prompt, padding="longest", return_tensors="pt", add_special_tokens=False ).to(image.device) with self.maybe_autocast(): prompt_embeds = self.llama_model.get_input_embeddings()(prompt_tokens.input_ids) inputs_embeds = torch.cat([image_embeds, prompt_embeds], dim=1) attention_mask = torch.cat([image_attns, prompt_tokens.attention_mask], dim=1) else: inputs_embeds = image_embeds attention_mask = image_attns # For captioning, supress the token ids > 32000 (Visual Tokens) supress_range = 32000 + self.visual_vocab_size + 2 suppress_tokens = [x for x in range(32000, supress_range)] with self.maybe_autocast(): outputs = self.llama_model.generate( inputs_embeds=inputs_embeds, attention_mask=attention_mask, do_sample=use_nucleus_sampling, temperature=temperature, num_beams=num_beams, max_new_tokens=max_length, min_new_tokens=min_length, suppress_tokens=suppress_tokens, bos_token_id=self.llama_tokenizer.bos_token_id, eos_token_id=self.llama_tokenizer.eos_token_id, pad_token_id=self.llama_tokenizer.pad_token_id, repetition_penalty=repetition_penalty, length_penalty=length_penalty, num_return_sequences=num_captions, ) output_text = self.llama_tokenizer.batch_decode(outputs, skip_special_tokens=True) output_text = [text.strip() for text in output_text] output_text = [text.split('.')[0] for text in output_text] return output_text ```
