A Survey on Multimodal Large Language Models
Shukang Yin1* , Chaoyou Fu2∗‡†, Sirui Zhao1∗‡, Ke Li2, Xing Sun2, Tong Xu1, Enhong Chen
School of CST., USTC & State Key Laboratory of Cognitive Intelligence, Tencent YouTu Lab
23.06
git
Abstract
MLLMs (Multimodal Large Language Models)를 4가지로 분류해 조사한다.
- M-IT (Multimodal Instruction Tuning)
- M-ICL (Multimodal In-Context Learning)
- M-CoT (Multimodal Chain-of-Thought)
- LAVR (LLM-Aided Visual Reasoning)
[1] M-IT (Multimodal Instruction Tuning)
Background
Instruction Tuning이란?
Instruction tuning은 pretrained LLM을 instruction-formatted dataset으로 finetuning 하는 기술을 말한다. 이러한 방법을 통해 LLM은 unseed tasks들에 대해서도 새 instruction으로 일반화 해 0 shot에서의 성능을 향상시킬 수 있다.
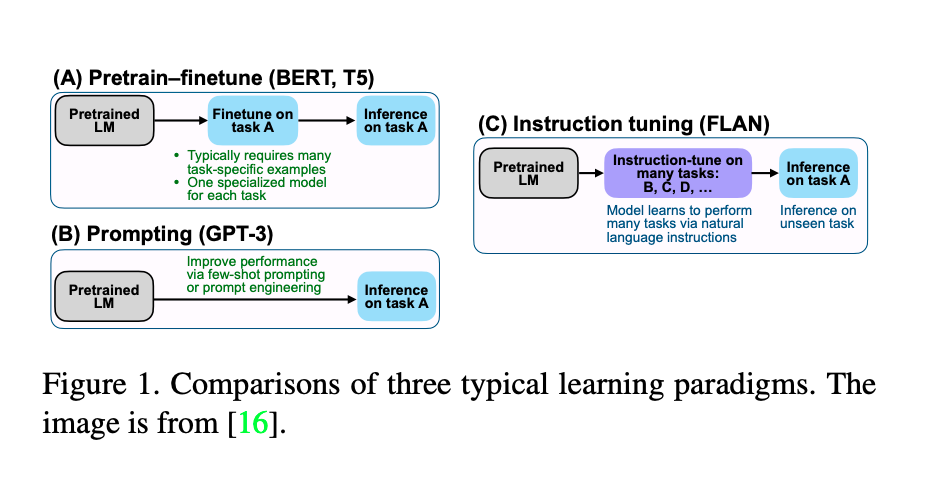
- tuning과 관련된 세 가지는 Figure 1과 같이 3가지로 서술할 수 있다.
supervised finetuning: 많은 task-specific data로 task-specific model을 학습prompting: prompt engineering으로 특정한 task에 대해 잘 수행하도록 한다.instruction tuning: 특정 task에 fit하도록 학습시키기 보다는,unseen tasks에 대해 어떻게 일반화하는 지를 학습한다. multi-task prompting과 더 연관있다고 할 수 있다.
Multimodal Instruction Samples
-
데이터는 instruction과 input-output pair로 구성된다.
instruction: task를 natural language sentence로 설명한 것을 말한다.E.g., Describe the image in detail.input: VQA (Visual Question-Answering) 처럼 image-text pair 일 수도 있고
Image Captioning 처럼 image 일 수도 있다.output: input에 conditioned된 instruction에 대한 정답.

-
modality는 보통 다음 두 가지로 구성된다
image-text pair: image를 natural lanugage sentence 형태로 서술ASR (Automatic Speech Recognition): speech의 transcription
Multimodal Instruction의 Goal
- MLLM은 주어진 instruction과 multimodal input에 대해 답을 예측한다.
next token prediction으로 학습되기 때문에, objective는 다음과 같이 표현된다.A = f(I, M; \theta); I: Instruction M: Multimodal input R: Groundtruth \theta: Model parameters A: predicted answerL(\theta) = - SUM_{i=1}^{n} log p(R_i | I, R <i; \theta) N: Groundtruth respose의 길이
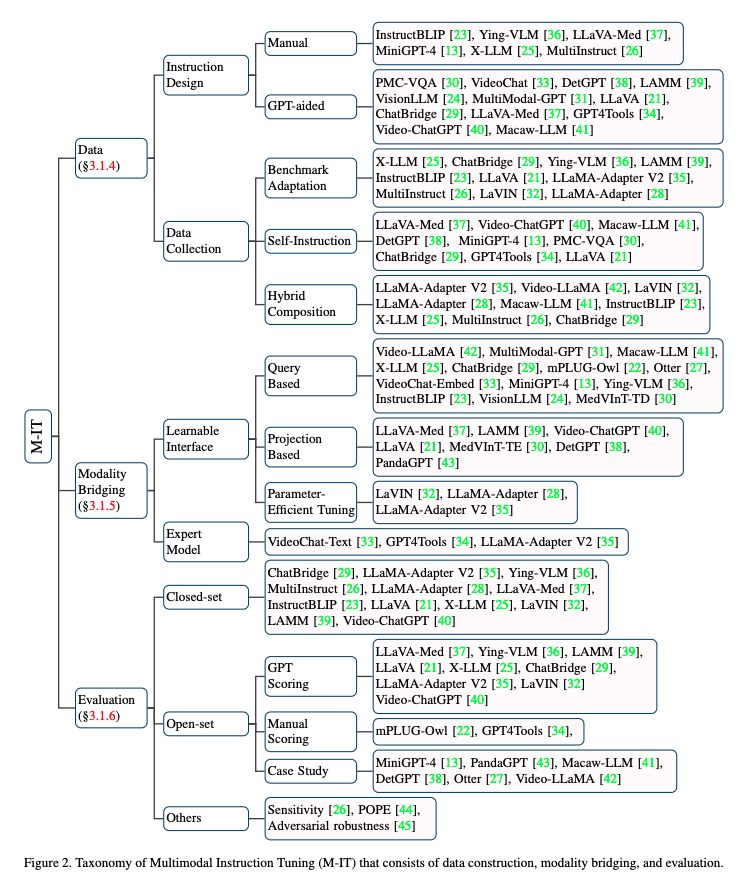
Data
- Data를 모으는 방법은 다음과 같이 3가지이다.
benchmark adaptation- benchmark dataset에는 high-quality data가 많아서 instruction-formatted dataset들이 구성되어 있는 것들이 있다. (E.g., VQA)
instruction의 경우 manual하게 design해주거나, OpenAI GPT 생성 등으로 만들어낼 수 있다.

limitation: 존재하는 VQA나 caption dataset들의 답변이 간결하기 때문에, MLLM의 output 길이에 한계를 가져다 줄 수 있다.해결 방법(1) instruction modify하기
ChatBridges는 answer에 따라 short, brief or a sentence or single sentence를 instruction에 작성, InstructBLIP도 short, briefly를 짧은 response 데이터에 작성(2) 현재 존재하는 정답의 길이를 늘리기
M^3IT는 Chat GPT로 original question, answer, context를 rephrase함.
- benchmark dataset에는 high-quality data가 많아서 instruction-formatted dataset들이 구성되어 있는 것들이 있다. (E.g., VQA)
self-instruction- few hand-annotated samples로 textual instruction-following data를 생성해내 학습함.
LLaVA는 image를 caption text와 bounding box들로 translate,
GPT-4를 사용해 새로운 데이터를 만들어내, LLaVA-Instruction-150k 데이터셋을 구성함.
이러한 아이디어를 발전시킨 것으로 MiniGPT-4, ChatBridge, GPT4Tools, DetGPT 등이 있음
- few hand-annotated samples로 textual instruction-following data를 생성해내 학습함.
hybrid composition- M-IT data가 아니라 language only user-assistant conversation data도 conversational 능력 및 instruction following 능력을 향상시키는 데 도움을 줄 수 있다.
Lavin은 language-only와 M-IT 데이터 중에 random으로 sampling을 진행한다.
MultiInstruct는 여러 type의 data를 합쳐 random shuffle한 mixed instruction tuning이 multimodal data에 solely tuning 하는 것보다 나쁘지 않음을 제안했다.
- M-IT data가 아니라 language only user-assistant conversation data도 conversational 능력 및 instruction following 능력을 향상시키는 데 도움을 줄 수 있다.
Modality Bridging
- text와 다른 modality 간의 gap을 catastrophic forgetting 없이 잘 연결하기 위해,
visual encoder와 LLM 사이의 learnable interface가 필요함.
또는 image를 language domain으로 translate 하는 과정이 필요함.
Learnable Interface- benchmark dataset에는 high-qua
(1) learnable group query token 사용
E.g., Flamingo, BLIP-2(2) embed image feature를 projection:
E.g., LLavA는 simple linear layer, MedVInTTE는 two-layer multilayer perceptron 사용
LLaMA-Adapter, LaVIN
- benchmark dataset에는 high-qua
Expert Model- benchmark dataset에는 high-qua
TBD
- benchmark dataset에는 high-qua

Lowes is currently running a customer feedback survey for all customers who have visited Lowes stores in the United States and Canada. Participants are asked simple questions about their recent visits to Lowes. Customers who take part in the survey will receive a free $500 gift card. To share your experience, visit the https://lowescomsurvey.page portal.