데이터셋 설명
-
MNIST 데이터셋: 미국 국립표준기술원(NIST)이 고등학생, 인구조사국 직원 등이 쓴 손글씨를 수집한 데이터로, 7만개의 글씨에 0~9의 수가 레이블링 되어있음.

-
이미지 데이터를 X, 데이터의 레이블을 y로 설정
-
MNIST 데이터는 전체 7만개의 이미지 중 6만개를 train으로, 1만개를 test로 사전에 정의함
-
이 개수를 출력하고 싶다면
X_train.shape[0]처럼shape()를 사용하면 됨
from tensorflow.keras.datasets import mnist
# 테스트셋 분할
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 이미지 하나만 출력해보기
import matplotlib.pyplot as plt
plt.imshow(X_train[0], cmap='Greys')
plt.show()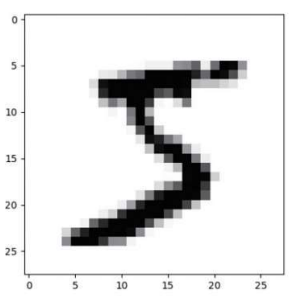
- 이 이미지는 28 * 28 = 784개의 픽셀로 구성됨
➡️ 즉, 속성의 개수가 784개임. - 각 픽셀은 밝기(흰색, 회색, 검은색 등)에 따라 0 ~ 255 사이의 값을 가짐

모델 생성
- 모델 목적: 28*28=784개의 속성을 이용해 0~9의 클래스 10개 중 하나를 맞추기
- 배열 크기 조절(차원 변환): 2차원 배열(28*28) ➡️ 1차원 배열
reshape(총 샘플 수, 1차원 속성의 개수)
X_train = X_train.reshape(X_train.shape[0], 784)-
데이터의 크기 범위 변경(정규화): 0~255 ➡️ 0~1
0~255까지의 수를 각각 255로 나눠서 0~1사이의 수로 바꿔줌 -
클래스(y)를 0, 1만으로 이루어진 배열로 바꾸기
to_categorical(바꾸려는 배열(y_train이랑 y_test), 클래스의 개수(10))
예: 7 ➡️ [0, 0, 0, 0, 0, 0, 0, 1, 0, 0 ] -
딥러닝 프레임 만들기
input값 784개, 은닉층 512개(사용자선택), output값 10개
model = Sequential()
model.add(Dense(512, input_dim = 784, activation='relu'))
model.add(Dense(10, activation='softmax))- 모델 컴파일
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])- 학습 자동 중단 설정
- 모델 저장:
ModelCheckpoint(filepath="저장위치", monitor="val_loss", verbose=1, save_best_only=True) - 학습 중단:
EarlyStopping(monitor="val_loss', patience=10)10번 이상 모델 성능이 향상되지 않으면 중단
- 모델 실행
model.fit(훈련X, 훈련y, 검증셋비율(0.25), epoch, batch_size, verbose=0, ...)
- 베스트 모델: 13th epoch, 실행 중단: 23th epoch
- 과적합 전 학습 중단
CNN
CNN이란?
입력계층, 출력계층, 은닉계층(컴볼루션 계층, ReLU 계층(음수값은 0에 매핑, 양수값은 그대로 유지 - 더 빠른 학습 가능), 풀링 계층)
-
공유 가중치 및 편향: 주어진 모든 계층의 은닉 뉴런에 대해 동일한 공유된 가중치 및 편향 값 존재 ➡️ 객체의 평행이동을 허용 (예: 자동차를 인식하도록 훈련된 신경망은 자동차가 영상의 어느 부분에 있어도 인식이 가능함)
-
분류계층 [마지막 계층]
K차원의 벡터를 출력하는 완전 연결 계층 [마지막 직전 계층]
CNN을 사용해야 하는 경우
영상처럼 복잡한 다량의 데이터, 신경망 구조에서 작동하도록 전처리한 신호가 있는 경우, 시계열 데이터(time-series data)의 경우
CNN 사용 사례
• 의료 영상: CNN은 수천 건의 병리학 보고서를 검토하여 영상에서 암 세포의 유무를 시각적으로 검출할 수 있음. 영상 분류 작업에서는 “NASNet-Mobile과 EfficientNet”이 사용됨. 대부분의 CNN은 “ImageNet 데이터베이스”를 사용해 훈련됨.
• 오디오 처리 및 신호 처리: 마이크가 있는 모든 기기에서 키워드 검출을 사용하여 특정 단어나 문구("Hey Siri!")가 발화되었을 때 이를 검출할 수 있음. 키워드를 정확하게 학습하여, 어떤 환경에서도 다른 모든 문구는 무시하고 키워드를 검출할 수 있음. YAMNet으로 소리의 위치 추정과 분류를 수행, CREPE로 피치를 추정, VGGish 또는 OpenL3로 특징 임베딩을 추출함.
• 객체 검출
자율주행에서는 표지판이나 다른 객체의 존재 여부를 정확하게 검출하고, 출력을 바탕으로 결정을 내리는 데 CNN을 사용함. 객체 검출(YOLO), 의미론적/인스턴스 분할(AdaptSeg/MASK R-CNN), 비디오 분류(SlowFast)를 사용하여 영상과 비디오를 분석할 수 있음.
• 합성 데이터 생성: GAN(생성적 적대 신경망)을 사용하여 얼굴 인식 및 자율주행을 비롯한 딥러닝 응용 분야에서 사용할 새로운 영상을 생성할 수 있음.
• 라이다: 분류(PointNet), 객체 검출(PointPillars), 의미론적 분할(PointSeg)을 사용하여, 포인트 클라우드 데이터를 분석할 수 있음
전이 학습 (Transfer Learning)
- 전이학습이란? 사전 훈련된 모델로 시작하는 방법
수만장에 달하는 기존의 이미지에서 학습한 정보를 가져와 내 프로젝트에 활용하는 것 (데이터 양이 부족할 때 사용할 수 있는 기법)
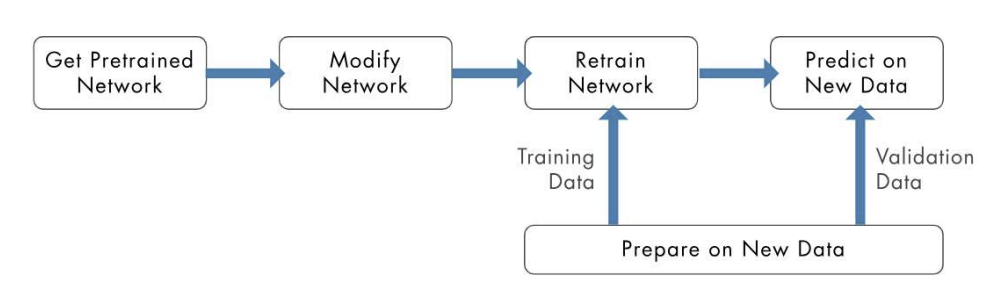
- 전이학습의 필요성: 신경망 성능이 더 좋음
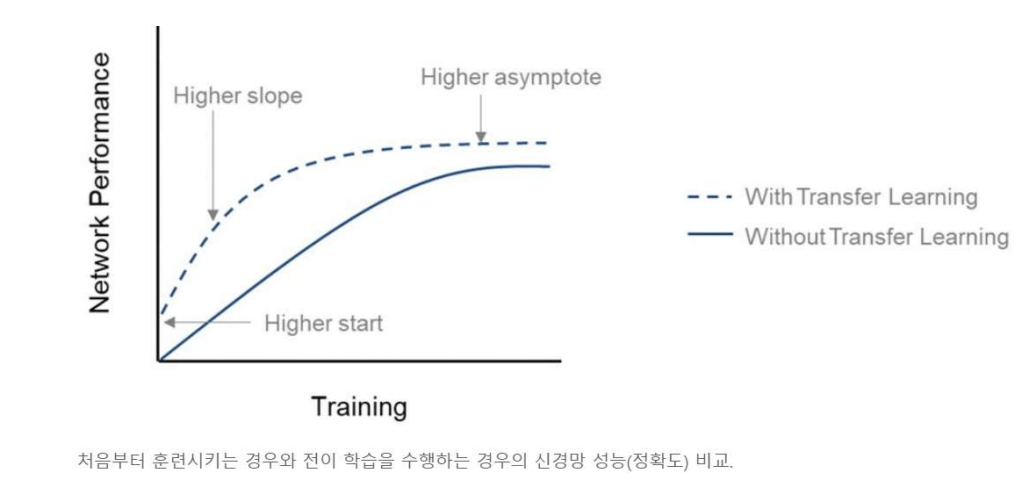
이미지넷(ImageNet)
1000가지 종류로 나뉜 120만개가 넘는 이미지를 놓고 어떤 물제인지 맞추는 이미지넷 이미지 인식 대회 (ILSVRC)에 사용되는 데이터셋이다.
전체 크기가 200GB에 이를 만큼 큰 데이터이다
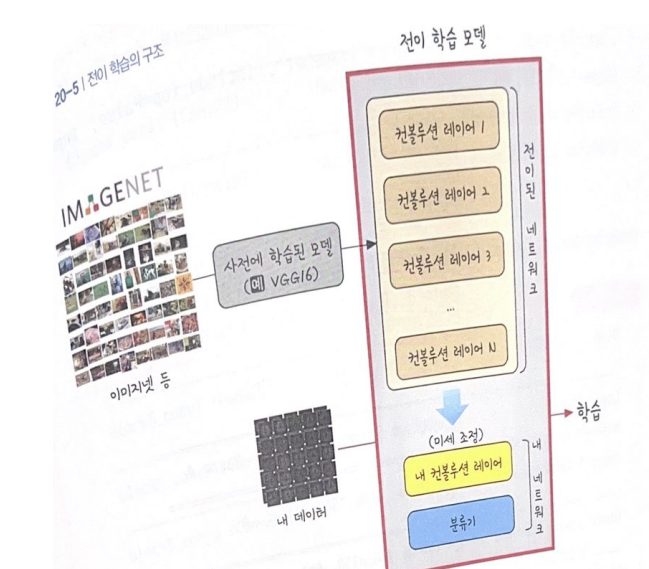
뇌사진만 다루는 치매 뇌 분류기를 만드는데, 뇌사진과 관련없는 수백만장의 이미지넷 학습정보가 큰 역할을 하는 이유는 '형태'를 구분하는 기본적인 학습이 되어있기 때문
딥러닝은 어떤 픽셀의 조합이 '선'이고, 어떤 형태의 그룹이 '면'이 되는지의 정말 기본적인 정보부터 파악해야하며, 이러한 정보가 사전에 주어지지 않는다면 이를 습득하는데에도 많은 시간을 쏟아야 함
전이학습은 대용량의 데이터를 이용해 학습한 가중치 정보를 가져와 내 모델에 적용한 후 프로젝트를 진행할 수 있도록 도움
예제: 치매환자와 일반인의 뇌 사진 구분하기
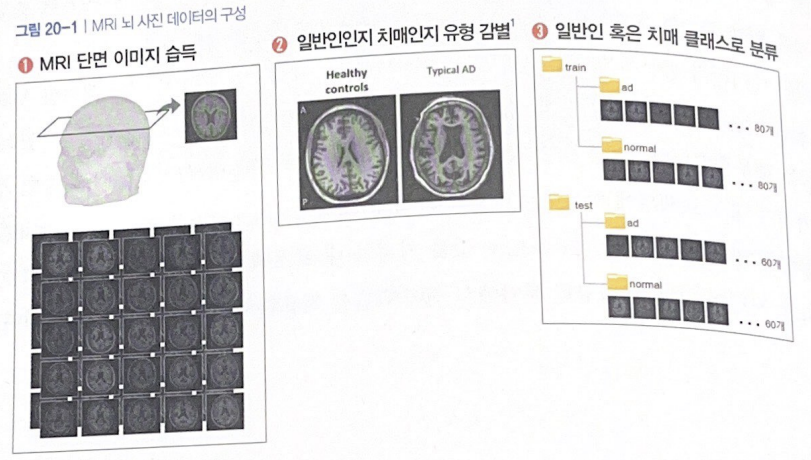
-
데이터
총 280장으로 이루어진 뇌의 단면 사진: 치매환자 140장, 일반인 140장
train : test = 160 : 120
케라스에서 제공하는 데이터가 아닌, 데이터셋을 읽어와야 함:
flow_from_directory()함수로 폴더에 저장된 데이터를 불러옴
이미지 증강:ImageDataGenerator함수 -
VGGNet
옥스포트 대학의 연구팀 VGG에 의해 개발된 모델로, 2014년 이미지넷 이미지 인식 대회 2등 차지
VGG16을 사용해서 기존의 성능을 개선해보자
transfer_model = VGG16(weights='imagenet', include_top=False, input_shape(150, 150, 3))
transfer_model.trainable = False
transfer_model.summary()

-
Trainable params : 0 임을 확인하기
-
모델 생성
finetune_model = models.Sequential()
finetune_model.add(transfer_model)
finetune_model.add(Flatten())
finetune_model.add(Dense(64))
finetune_model.add(Activation('relu'))
finetune_model.add(Dropout(0. 5))
finetune_model.add(Dense(1))
finetune_model.add(Activation('sigmoid'))
finetune_model.summary()
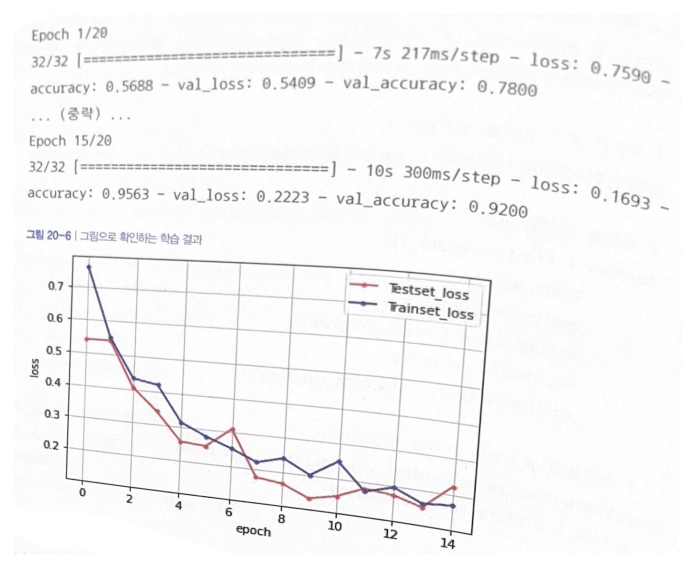
- 적용하기 이전과 달라진 점
이전보다 높은 정확도에서 출발함
학습속도가 빨라짐
그래프의 변화추이가 안정적임
전이학습을 위한 모델 선택 방법
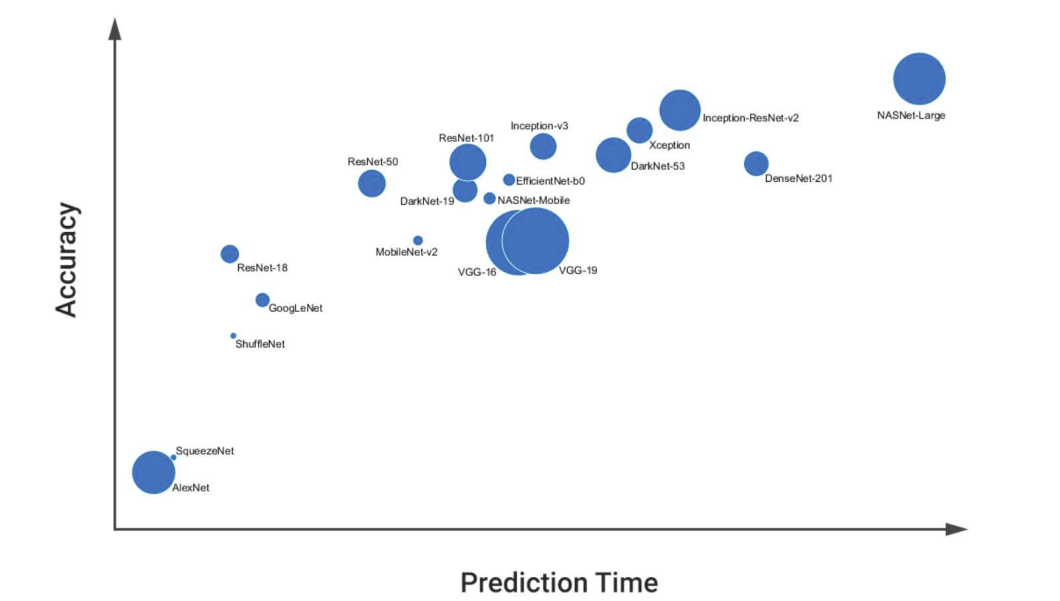
-
예측 속도
예측 속도는 하드웨어 및 배치 크기, 모델의 아키텍처와 크기와 같은 인자에 따라 달라질 수 있음
처음 시작할 때는 SqueezeNet 또는 GoogLeNet처럼 비교적 빠른 모델 중에서 선택하고 그 후에는 빠르게 반복하고 다른 전처리 및 훈련 옵션을 사용해 보기 -
정확도(재훈련하기 전의 모델의 성능)
ImageNet 데이터셋에 대해 좋은 성능을 보이는 모델은 새로운 유사 작업에서도 좋은 성능을 보일 가능성이 높으나, ImageNet에서 정확도 점수가 낮다고 해서 모델이 모든 작업에서 성능이 떨어지는 것은 아님.
어떤 설정이 잘 동작하는지에 대한 이해가 쌓였다면 이제는 Inception-v3 또는 ResNet-50처럼 더 정확한 모델을 사용해 보고 결과가 개선되는지 확인함. -
크기(모델에 필요한 메모리 사용량)
모델 크기의 중요성은 모델을 어디로 그리고 어떻게 배포하려는지에 따라 달라짐. 리소스가 제약된 타겟에 배포하는 경우에는 신경망의 크기가 중요함.
예: 모델을 임베디드 하드웨어에서 실행할 것인지 또는 데스크탑에서 실행할 것인지에 따라 달라질 수 있음.
예: Raspberry Pi®나 FPGA 같은 에지 기기에 배포할 때는, SqueezeNet 또는 MobileNet-v2처럼 메모리 사용량이 적은 모델을 선택함
전이학습 워크플로에 가장 적합한 모델
a. 시작하기 적합한 단순한 모델(GoogLeNet, VGG-16, VGG-19)을 사용해 신속하게 반복하고 다양한 데이터 전처리 단계와 훈련 옵션을 실험해보기
➡️ 일단 어떤 설정이 잘 작동하는지 파악한 후에는 더 정확한 신경망을 사용해 결과가 향상되는지 확인할 수 있음.
b. 배포 환경으로 인해 모델 크기가 제한되는 경우: 계산할 때 효율적인 경량 모델(SqueezeNet, MobileNet-v2, ShuffleNet)을 선택하는 것이 좋음.
영상 분류에 대한 전이 학습 워크플로: 전이학습 적용 순서
-
사전 훈련된 모델 선택: 단순한 모델을 선호하므로 GoogLeNet 선택
전이 학습이 사전 훈련된 GoogLeNet 모델(1,000개의 객체 범주로 분류하도록 22개 계층이 심층 훈련된 널리 사용되는 신경망)에 대해 수행됨

-
최종 계층 교체
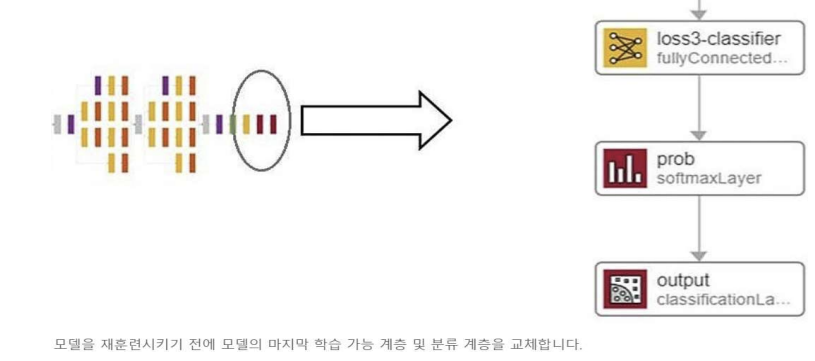
새로운 영상 및 클래스 세트를 분류하도록 신경망을 재훈련하기 위해 GoogLeNet 모델의 마지막 학습 가능 계층과 최종 분류 계층을 교체: 최종 완전 연결 계층(마지막 학습 가능 계층)은 신경망이 학습할 새로운 클래스 개수를 지정하고, 분류 계층은 사용 가능한 새로운 출력 범주에서 출력을 결정함
예: GoogLeNet은 원래 1,000개의 계층에 대해 훈련되었지만, 최종 계층을 교체하여 관심 있는 객체의 n개의 범주만 분류하도록 재훈련 시킬 수 있음
➡️ 최종 완전 연결 계층은 새로운 클래스의 수와 동일한 수의 노드를 포함하도록 수정됨
➡️ 새 분류 계층은 소프트맥스 계층에서 계산된 확률을 기반으로 출력을 생성
-
선택적으로 가중치 동결
• 해당 계층의 가중치를 동결하는 방법: 신경망의 앞쪽 계층의 학습률을 0으로 설정하기
• 효과
훈련 중에 이런 동결 계층의 파라미터는 업데이트되지 않음 ➡️ 신경망의 훈련 속도 대폭 향상 가능
새 데이터셋의 크기가 작은 경우에는 신경망의 과적합을 방지할 수도 있음 -
모델 재훈련
• 재훈련을 통해 새 영상 및 범주와 관련된 특징을 학습하고 식별하도록 신경망을 업데이트함
• 대부분의 경우 재훈련에는 모델을 처음부터 훈련하는 경우와 비교하여 더 적은 수의 데이터만이 필요함 -
신경망 정확도 예측 및 평가
• 모델 재훈련 후에는 새 영상을 분류하고 신경망의 성능을 평가할 수 있음
전이학습에 대한 대화형 방식의 접근법
• 심층 신경망 디자이너 앱 사용 ➡️ MATLAB, TensorFlow, PyTorch에서 사전 훈련된 모델 가져오기, 최종 계층의 수정 및 새 데이터를 사용한 신경망 재훈련을 비롯한 전체 전이 학습 워크플로를 거의 또는 전혀 코딩 없이 대화형 방식으로 완료할 수 있음
CNN 학습 과정
- input 이미지
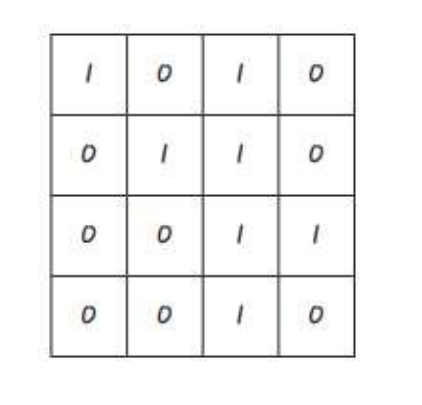
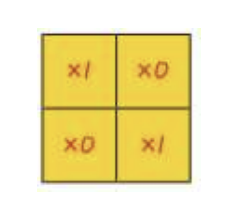
- 커널
크기: 2*2 (이미지에 따라 사용자 지정)
가중치: 커널 안에 있는 숫자 (이미지에 따라 사용자 지정)
3. input 이미지에 커널 적용
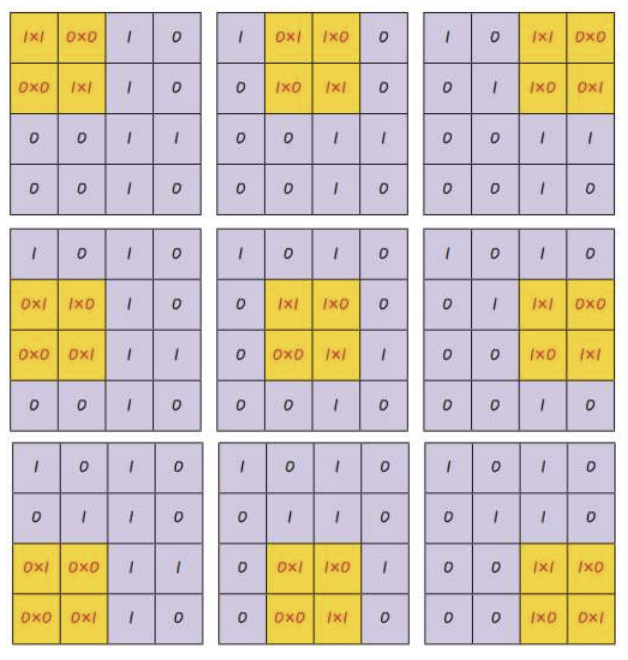
예: 맨 윗쪽 왼쪽 칸에 적용
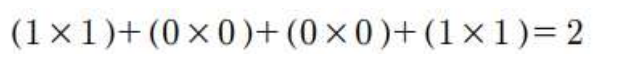
- 결과: 컨볼루션 층 생성
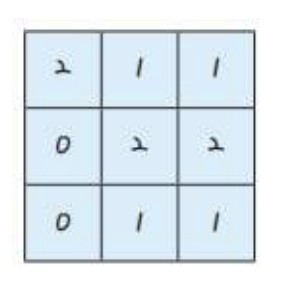
- 커널 수 = 컨볼루션 층 개수
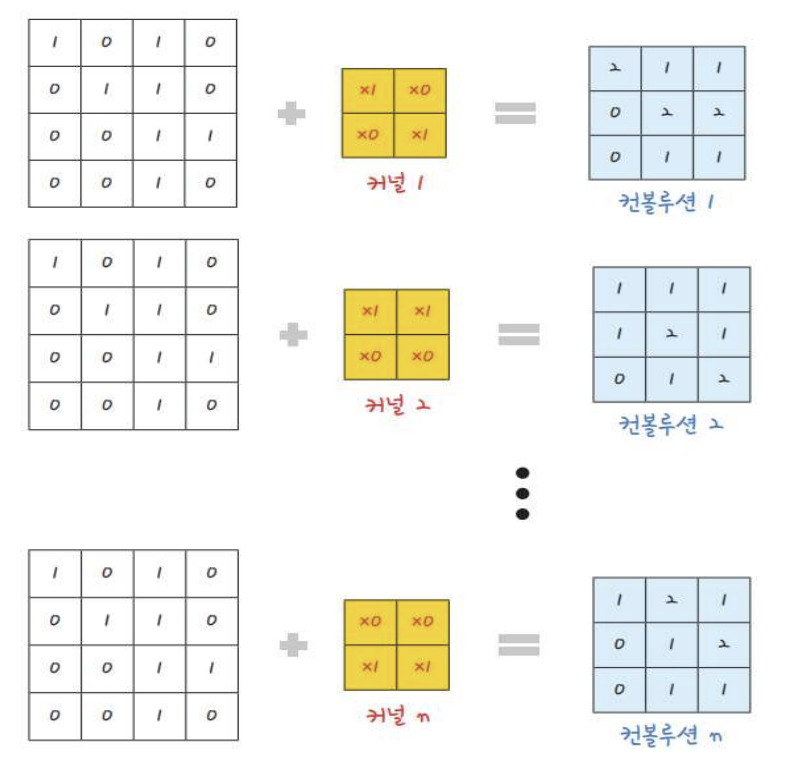
model.add(Conv2D(32, # 커널 개수
kernel_size=(3, 3), # 커널 크기
input_size=(28, 28, 1), # 데이터 크기: 행, 열, 색상(3) 또는 흑백(1)
activation='relu') # 활성화 함수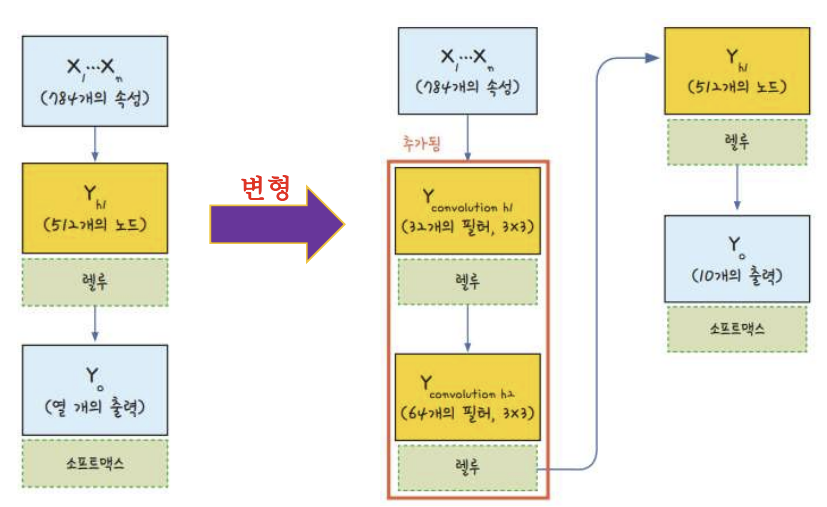
맥스 풀링 (Max Pooling)
- input 이미지
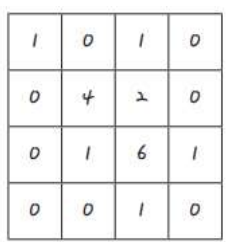
- 맥스 풀링 적용해 구역 나누기
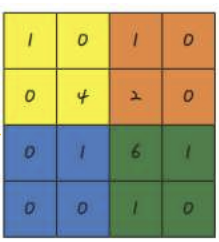
- 각 구역에서 가장 큰 값 추출
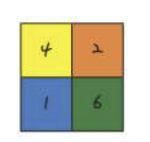
model.add(MaxPooling2D(pool_size=(2, 2))pool_size로 input 이미지가 나뉨 -> 몇 조각으로 나뉠지는 모르지만 하나의 조각의 크기는 우리가 지정할 수 있음
드롭 아웃 (Drop out)
- 노드, 층이 많아진다고 학습이 무조건적으로 좋아지는 것은 아님 (과적합)
- 드롭아웃: 은닉층에 배치된 노드 중 일부를 임의로 끄는 것
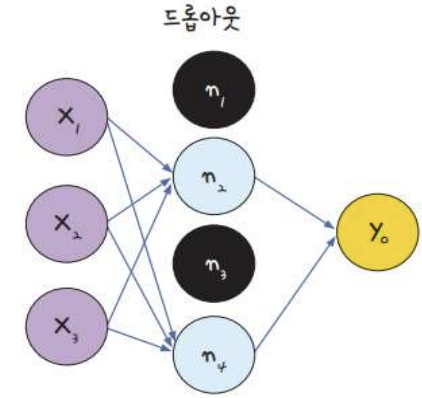
model.add(Dropout(0.25))플래튼(Flatten)
컨볼루션, 맥스풀링층 - 이미지를 2차원 배열로 사용
활성화 함수가 있는 층 - 1차원 배열로 사용
- 플래튼: 2차원 배열 ➡️ 1차원 배열
model.add(Flatten())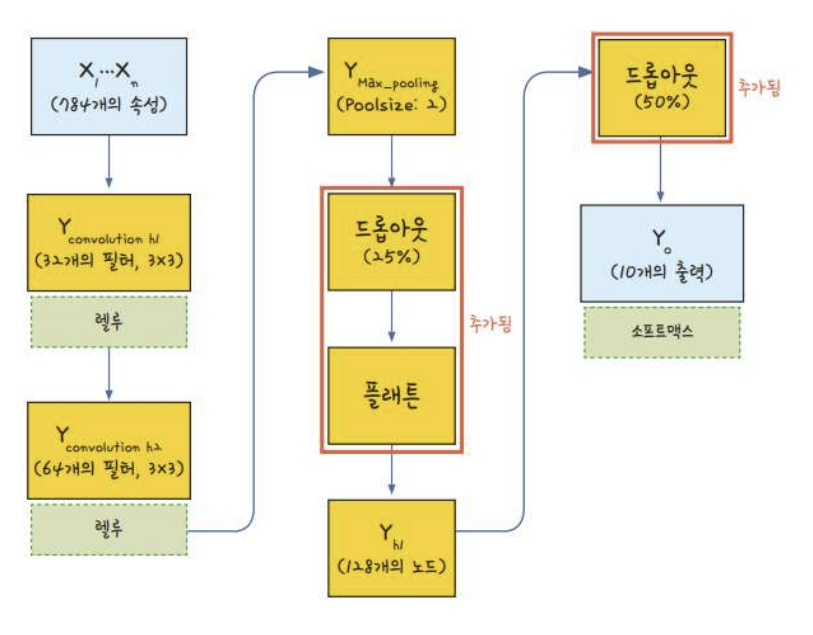
- 모델이 100%를 맞추지 못한 이유: 데이터 안에 사람조차 확인하기 어려운 글씨도 포함되어있었으므로
