데이터패턴인식
1.1. setting
딥러닝 모델 생성에 필요한 3가지 요소: 데이터 지도학습: labeling된 데이터 사용 예: CNN, RNN 비지도학습: labeling 되지 않은 데이터 사용 예: GAN, AutoEncoder 컴퓨터 데이터의 양이 많은 경우는 GPU 작업환경을 갖추어야 하나,
2.2. 예측 모델의 기본 원리
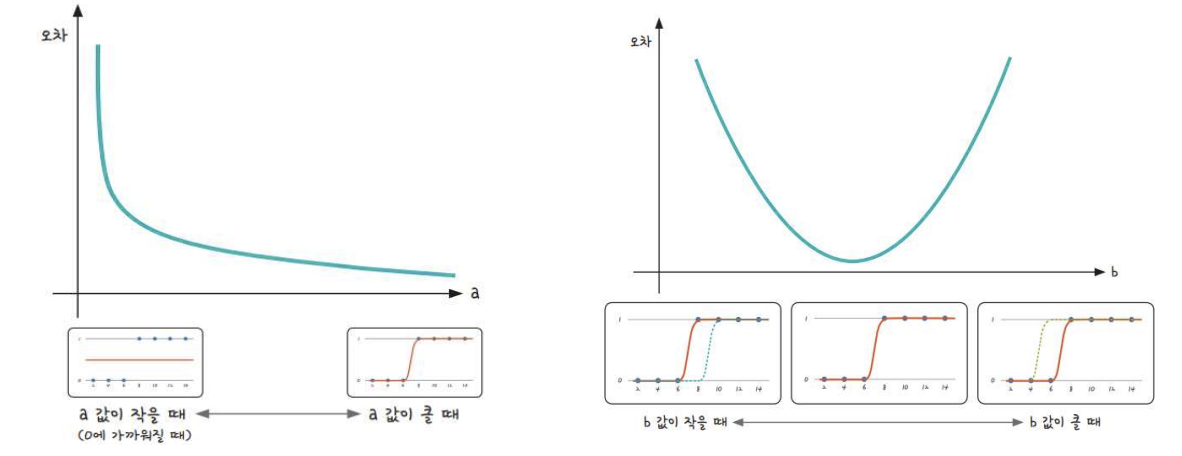
선형회귀(Linear Regression) 단일 선형 회귀 (Simple linear regression): x값(독립변수) 하나, y값(종속변수) 하나로 구성됨 다중 선형 회귀 (Multiple linear regression): x값 여러개, y값 하나 y =
3.3. 딥러닝의 시작, 신경망
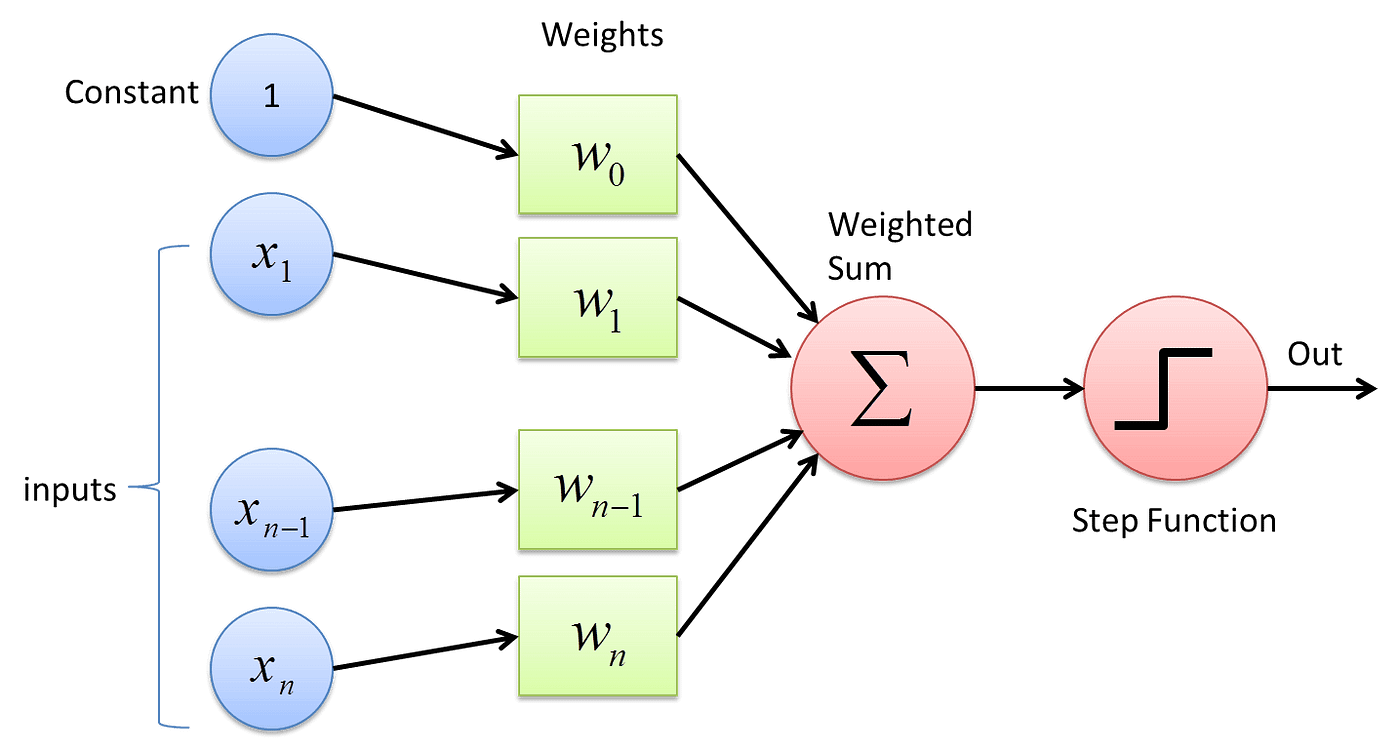
입력값을 여러개 받아 가중치와 곱한 것의 전체 sum을 활성화함수를 거쳐서 0 혹은 1의 값으로 바꾸어 예상값을 출력함. 이 때, 예상값과 실제 값의 차이(오차)에 따라 가중치를 update함. 그래프에서와 같이, XOR 개념은 선으로 1과 0 값을 가진 점들을 분류할
4.딥러닝 모델 설계
오차함수(손실함수) 설정평균 제곱 계열 (선형회귀(결과가 수치로 나옴)에서 사용)(1) 평균 제곱 오차 : mean_squared_error (2) 평균 절대 오차 : mean_absolute_error 실제값과 예측값 사이의 절댓값 평균(3) 평균 절대 백분율 오차
5.데이터 다루기
비만의 원인: 자기관리와 유전 둘 다의 문제임피마 인디언은 1950년대까지만해도 비만인 사람이 단 한명도 없는 민족이었음. 그러나 지금은 전체 부족의 60%가 당뇨, 80%가 비만으로 고통받고 있음\-> 이유? 영양분을 체내에 저장하는 뛰어난 능력(생존스킬)을 물려받은
6.다중 분류 문제 모델 만들기

다중 분류 문제 클래스가 기존에 우리가 다룬 데이터와 같이 0과 1로 이루어진 2개인 이항분류 문제가 아닌, 3개 이상의 여러개의 답중 하나를 고르는 것이 바로 다중분류문제이다. 문제점: 3개의 클래스가 각각 숫자가 아닌 문자열 형태로 되어있어 딥러닝 학습을 적용시키기
7.모델 성능 검증하기
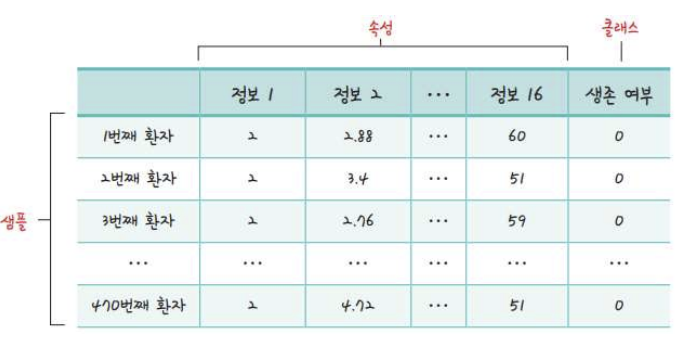
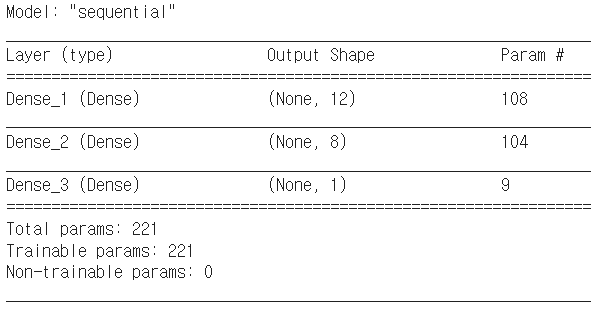
오차역전파가 은닉층의 가중치를 실제로 update시키는 것을 확인하고자 함데이터셋: 광석, 일반 암석에 수중 음파 탐지기를 쏜 후 결과를 모음모델: 음파 탐지기의 수신 결과만을 보고 광적과 일반 암석을 구분하는 모델60번째 열이 광물의 종류를 나타내므로, 일반 암석과
8.모델 성능 향상시키기
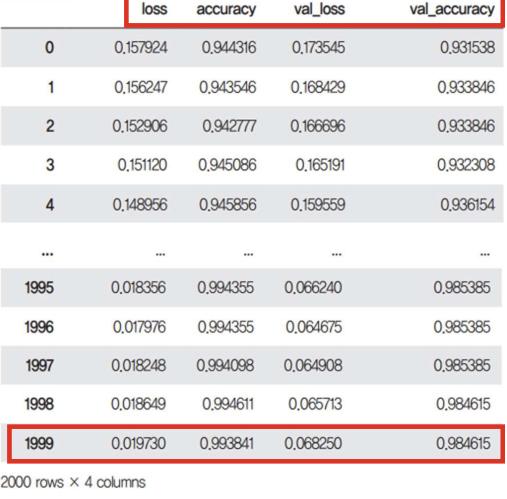
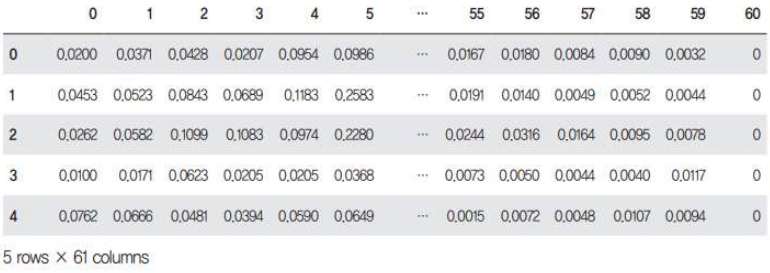
레드와인, 화이트와인 구분 모델을 다룸 검증셋(Validation set) 검증셋이란? 최적의 학습 파라미터를 찾기 위해 학습 과정에서 사용하는 것. train : val : test = 6 : 2 : 2 여기서, test set은 traintestsplit는
9.실제 데이터로 모델 생성하기
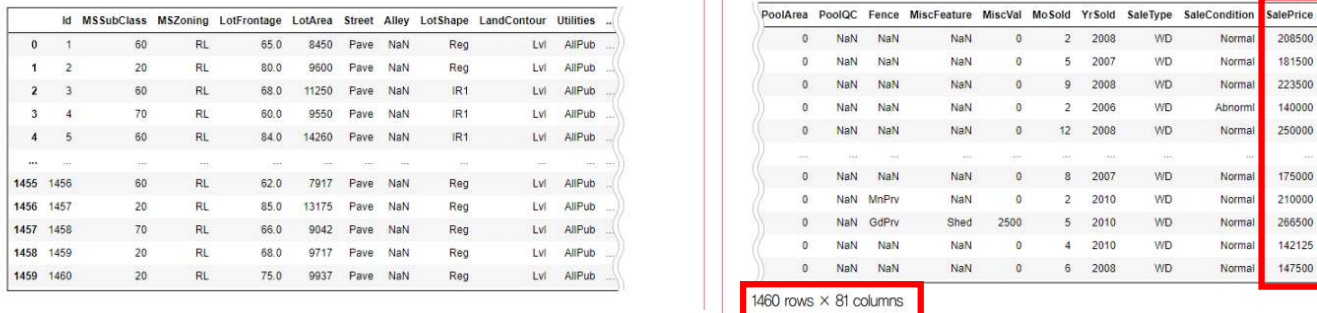
지금까지는 참/거짓, 카테고리 예측 등의 분류 문제를 다룸이번에는 수치예측 문제를 다룰 예정총 80개의 속성, 마지막 속성이 우리가 예측해야하는 값인 집값df.dtypes를 사용해서 데이터의 형태를 알아봄isnull() : 결측치가 있는지 검사하는 함수결측치 채워주기데
10.이미지 인식, CNN(Convolutional Neural Network)
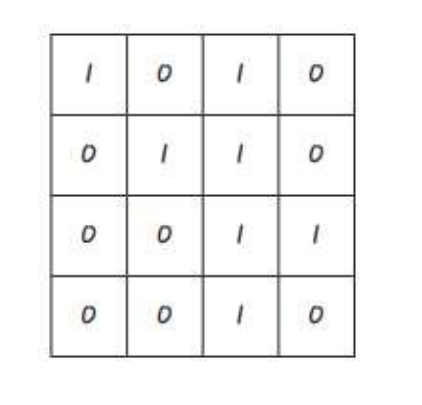
MNIST 데이터셋: 미국 국립표준기술원(NIST)이 고등학생, 인구조사국 직원 등이 쓴 손글씨를 수집한 데이터로, 7만개의 글씨에 0~9의 수가 레이블링 되어있음. 이미지 데이터를 X, 데이터의 레이블을 y로 설정. 이 이미지는 28 * 28 = 784개의 픽셀로
11.자연어 처리(NIP: Natural Language Processing)

자연어: 우리가 평소에 말하는 음성, 텍스트
12.순환신경망(RNN: Recurrent Neural Network), Attention
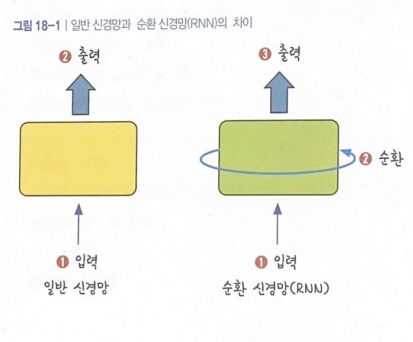
필요성문장은 여러개의 단어로 이루어져있고, 그 의미가 올바르게 전달되려면 각 단어가 정해진 순서대로 입력되어야 함즉, 여러 데이터가 순서와 관계없이 입력되던 것과는 달리 데이터의 입력 순서를 고려해야하는 상황이 생김동작여러 개의 데이터가 순서대로 입력됨 ➡️ 앞서 입력
13.GAN(Generative Adversarial Networks), 오토인코더

GAN(생성적 적대 신경망) 가상의 이미지를 생성하는 알고리즘 예: 얼굴을 만든다면, 이미지 픽셀들이 어떻게 조합되어야 우리가 생각하는 '얼굴'의 형상이 되는지 알고리즘이 예측한 결과를 출력 DCGAN(Deep Convolutional GAN): 페이스북의 AI 연구