- 지금까지는 참/거짓, 카테고리 예측 등의 분류 문제를 다룸
- 이번에는 수치예측 문제를 다룰 예정
import pandas as pd
!git clone https://github.com/taehojo/data.git
df.pd.read_csv("./data/house_train.csv")
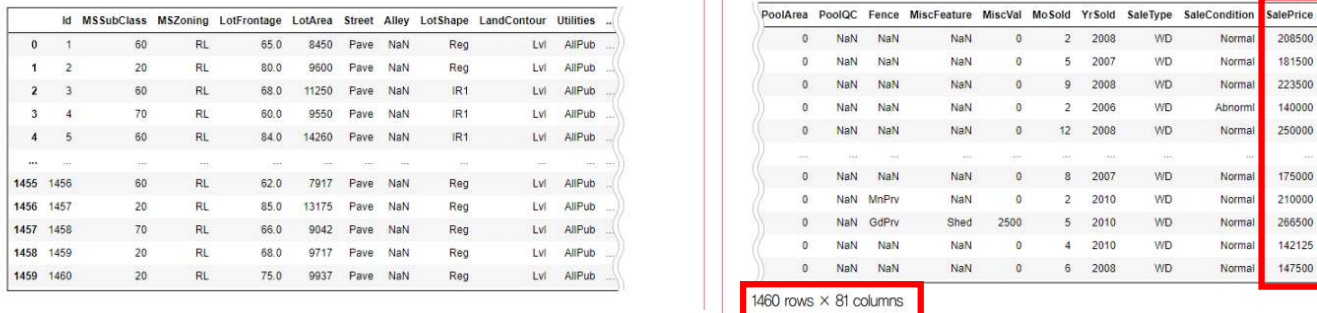
- 총 80개의 속성, 마지막 속성이 우리가 예측해야하는 값인 집값
df.dtypes를 사용해서 데이터의 형태를 알아봄
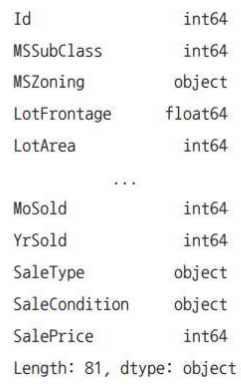
결측치 처리하기
isnull() : 결측치가 있는지 검사하는 함수
df.isnull().sum().sort_values(ascending = False).head(20)
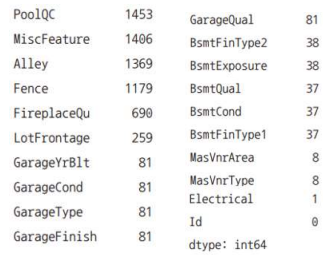
df = df.fillna(df.mean)
df = df.dropna(how = 'any')
df = df.dropna(how = 'all')
카테고리형 변수를 0, 1로 이루어진 변수로 바꾸기
get_dummies() 함수 이용하기: 카테고리형 변수를 모두 one-hot encoding 처리하므로, 전체 열이 81개에서 290개로 증가함
df = pd.get_dummies(df)
속성별 관련도 추출
- 데이터 사이의 상관관계를
df_corr 변수에 저장
- 집값과 관련이 큰 순서로 정렬해
df_corr_sort 변수에 저장
- 집값과 관련도가 가장 큰 열개의 속성 출력
df_corr = df.corr()
df_corr_sort = df_corr.sort_values('SalePrice', ascending = False)
df_corr_sort['SalePrice'].head(10)
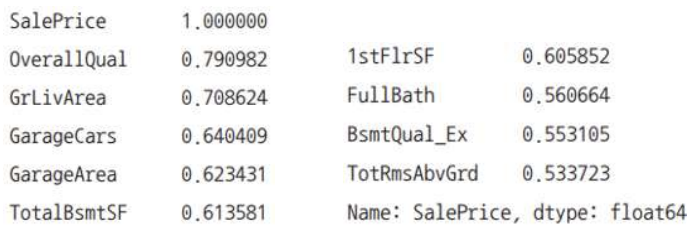
- 상관도 그래프 시각화
cols = ['SalePrice', 'OverallQual','GrLivArea', 'GarageCars', 'GarageArea', 'TotalBsmtSF']
sns.pairplot(df[cols])
plt.show()
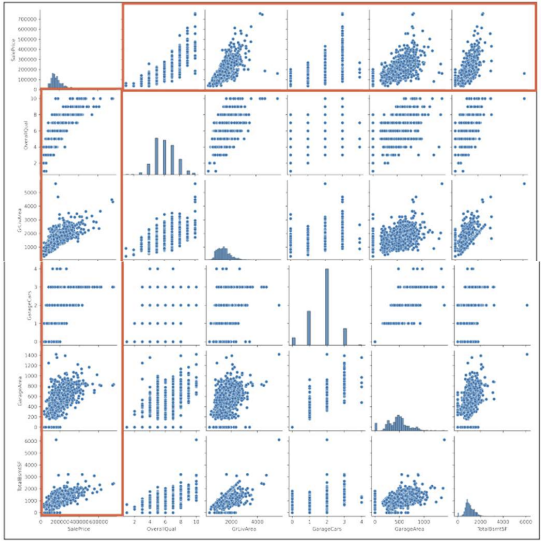
- 이를 통해, 붉은 사각형으로 표시된 부분의 속성들이
SalePrice와 연관이 있음을 알 수 있음
주택 가격 예측 모델
- 선형회귀이므로 손실함수(loss)에
mean_squared_error를 적어줌
- 입력 속성의 개수:
X.shape[1]로 지정해서 자동으로 세도록 함
- 20번 이상 결과가 향상되지 않으면 자동 중단:
EarlyStopping(monitor = "val_loss", patience = 20)
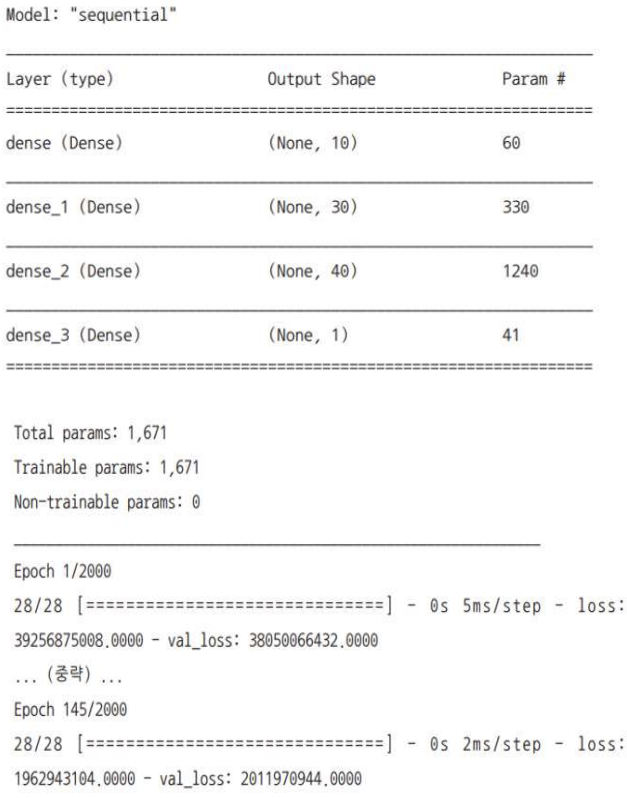
- 학습 중단 시점은 실행할 때마다 다를 수 있음
