딥러닝 모델 생성에 필요한 3가지 요소:
- 데이터
- 지도학습: labeling된 데이터 사용
예: CNN, RNN
- 비지도학습: labeling 되지 않은 데이터 사용
예: GAN, AutoEncoder
- 컴퓨터
- 데이터의 양이 많은 경우는 GPU 작업환경을 갖추어야 하나, 그렇지 않은 경우에는 CPU로도 충분하다. (+ 구글에서 만든 데이터 분석 및 딥러닝용 하드웨어인 TPU도 있다).
- 작업환경을 구축하는 법은 크게 Colab을 활용하는 것과 Anaconda를 설치해 가상환경에서 실행하는 법으로 나뉨.
- 프로그램 코딩
preperation
- 라이브러리: 특정한 기능을 담은 작은 프로그램들(module, api)을 모아놓은 것
from (라이브러리) import (함수명)
import (라이브러리) as (단축된 새로운 이름)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import numpy as np
- 깃허브에 저장된 데이터 불러오는 법
!git clone https://github/taehojo/data.git
mydata = np.loadtxt("./data/ThoraricSurgery3.csv", delimiter=",")
- 속성(attribute)과 클래스(class)의 개념
- 속성은 독립변수(x)에, 클래스는 종속변수(y)에 대응하는 개념
- 예를 들어 해당 의료데이터의 경우, 종양의 유형, 폐활량, 기침, 흡연, 천식 여부 등이 속성이고 이러한 데이터들을 통해 예측한 수술 1년 이후의 생존여부가 클래스입니다. 클래스는 0, 1로 이루어집니다.
- 딥러닝 구조
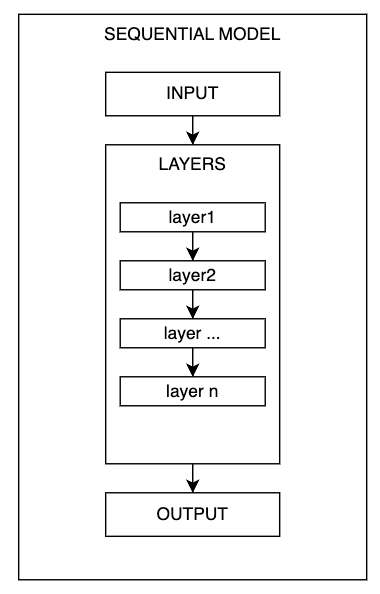
- 각 layer를 생성하는 명령어:
model.add(해당레이어의 모델 옵션)
- 예시 코드
model = Sequential()
model.add(Dense(30, input_dim=16, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
- 딥러닝 설계란 ? 몇 개의 layer를 어떻게 쌓을 지, 내부 변수를 어떻게 정할지 등을 결정하는 것
- 모델 실행
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(X, y, epochs=5, batch_size=16)
