가장 훌륭한 예측선
선형회귀(Linear Regression)
-
단일 선형 회귀 (Simple linear regression): x값(독립변수) 하나, y값(종속변수) 하나로 구성됨
-
다중 선형 회귀 (Multiple linear regression): x값 여러개, y값 하나
y = ax + b
이 때, 기울기 a와 y절편 b를 잘 조절해서 그래프의 점들에 최대한 가까운 선을 긋는 것이 목표임.
최소제곱법 (Method of least squares)
- 일차함수의 기울기 a, y절편 b를 구하는 방법임
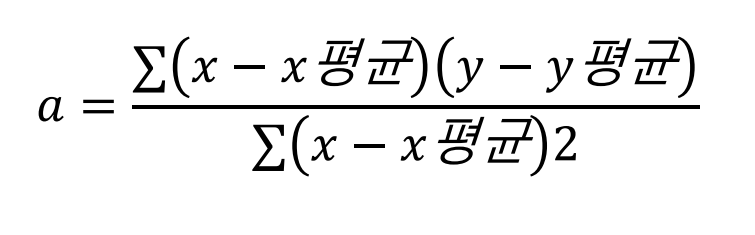

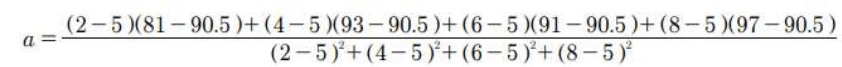
- b = y의 평균 - (x의 평균 * 기울기 a)
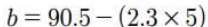
➡️ y = 2.3x + 79

#파이썬의 리스트를 numpy 배열로 바꾸는 과정. 이를 통해 더 여러가지의 계산을 수행할 수 있다.
x = np.array([2, 4, 6, 8])
y = np.array([81, 93, 91, 97])
# 각 원소의 평균 구하는 식
mx = np.mean(x)
my = np.mean(y)
# 첫번째 공식의 분모 부분 실행
divisor = sum([(i - mx)**2 for i in x])
#첫번째 공식의 분자 부분 구하기
def top (x, mx, y, my):
d = 0
for i in range(len(x)):
d += (x[i] - mx) * (y[i] - my)
return d
divided = top(x, mx, y, my)
# 두번째 공식 구하기
b = my - (mx * a)- 최소 제곱법의 한계: 여러개의 입력을 처리하기 어려움
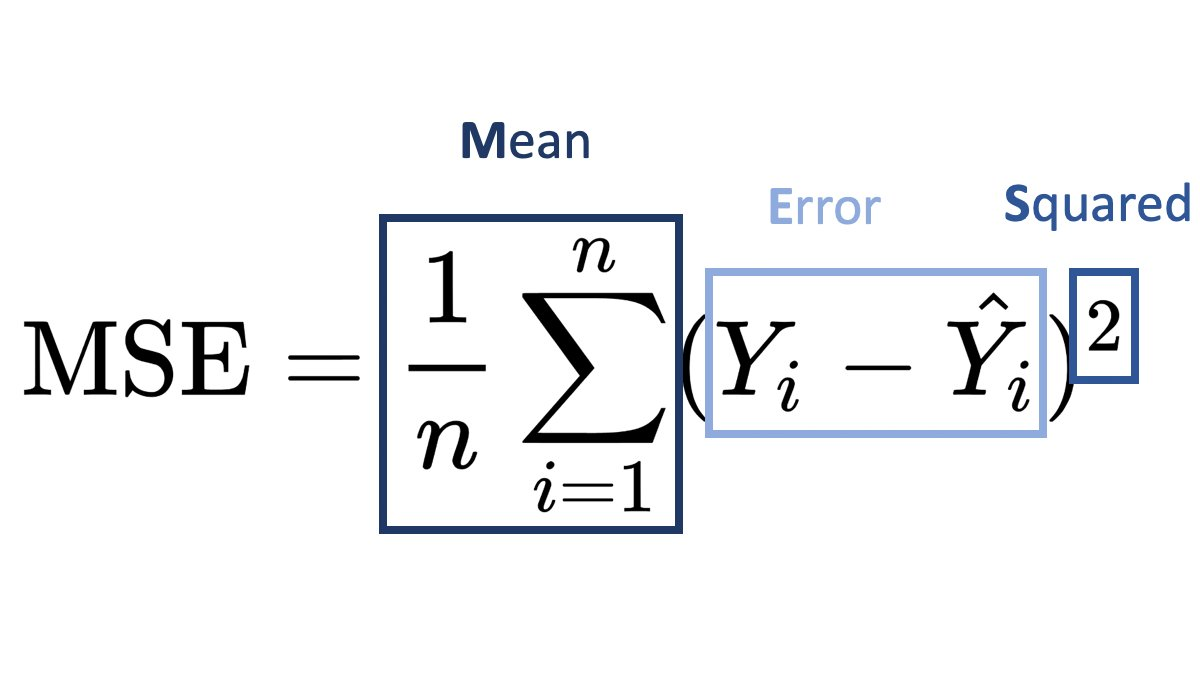
평균제곱오차(Mean Square Error: MSE)
- 여러개의 입력의 경우, 우선 선을 긋고 수정하는 방식을 택함.
- 이 때, 이 선이 좋은지 나쁜지를 평가하는 방법으로 가장 많이 사용되는 것이 MSE.
- 역할: 오차의 정도를 판단. 선형회귀에서 사용.
fa = 3
fb = 76 # 가상의 기울기, y절편
def predict(x):
return fa * x + fb
# mse 계산
n = len(x)
def mse(y, yp):
return (1/n) * sum((y - yp)**2)선형회귀모델: 먼저 긋고 수정하기 - 오차 줄이는 법
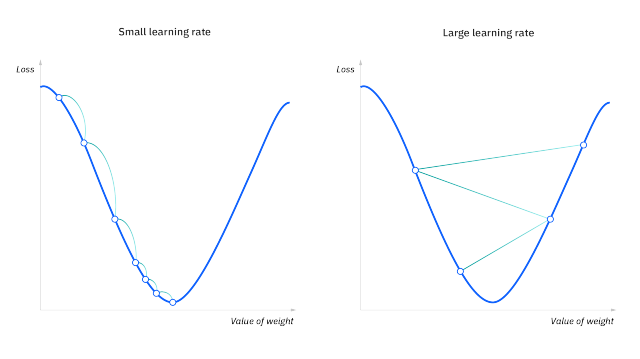
경사하강법(gradient decent)
- 정의: 오차의 변화에 따라 이차함수 그래프를 그리고, 적절한 학습률을 설정해 미분값이 0인 지점을 구하는 것.
- 역할: 오차 수정
-
x축: 기울기, Y축: 오차(loss)
기울기가 2차함수의 가장 아랫쪽 볼록한 부분(미분값 = 0)에 위치할 때 오차가 최소가 됨. -
학습률(learning rate): 이 때, 기울기값을 얼마씩 이동시킬 것인지를 정하는 값이 학습률임.
-
계산 방법
(1) MSE 식에 predicted values = axi + b를 대입

(2) 식을 각각 m, b에 대해 편미분 -> 다중으로 바뀌어서 변수가 많아지더라도 동일하게 각각 편미분하고, update함.
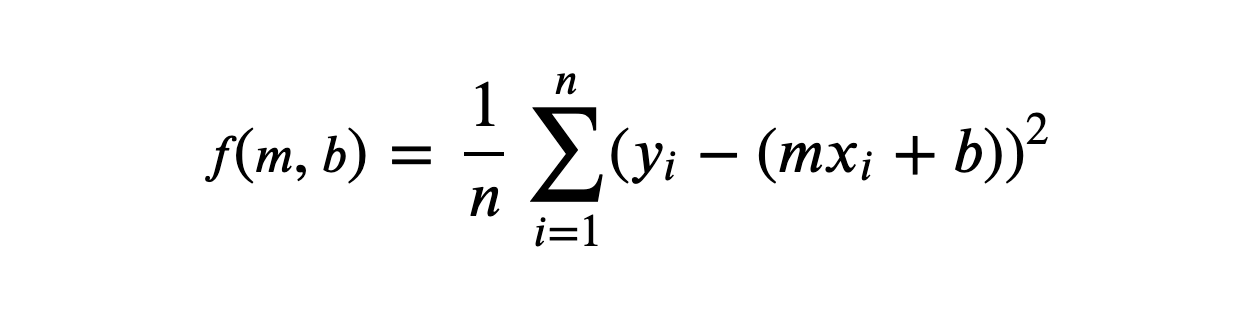
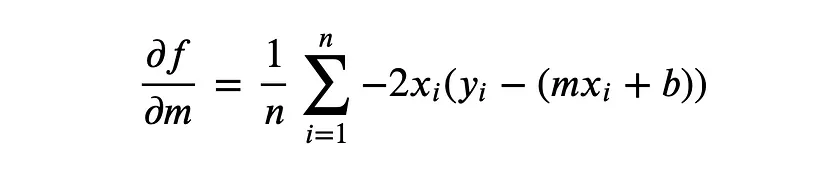
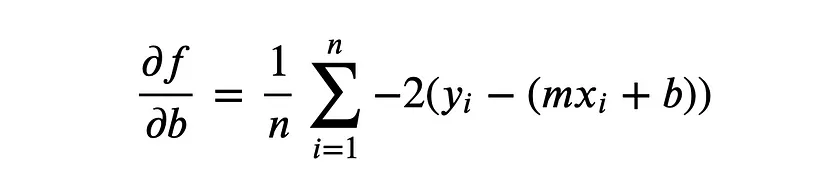
(3) updated m, b 구하기
updated m = m - 학습률 (2)번 a에 대한 편미분 결과
updated b = b - 학습률 (2)번 b에 대한 편미분 결과
다중 선형 회귀 (multiple linear regression)
- 학생들의 공부 시간에 따른 성적 예측 직선을 그렸으나 약간의 오차가 있었음. 왜? '과외횟수' 등 다른 요소가 성적에 영향을 끼쳤으므로.
- y =a1x1 + a2x2 + b
x1 = np.array([2, 4, 6, 8)]
x2 = np.array([0, 4, 2, 3)]
y = np.array([81, 93, 91, 97)]
fig = plt.figure()
ax=fig.add_subplot(111, projection='3d')
ax.scatter3D(x1, x2, y)
plt.show()용어 재정의
- y = ax + b ➡️ H(x) = wx + b
- 평균 제곱 오차 ➡️ 손실함수 (loss function)
- 경사하강법 ➡️ Optimizer
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model.add(Dense(1, input_dim = 1, activation='linear') # 출력값, 입력변수(다중선형회귀이면 얘를 변경해줌), 분석방법
model.compile(optimizer='sgd', loss='mse') # 오차수정: sgd(경사하강법), 오차정도판단: mse(평균제곱오차)
model.fit(x, y, epochs=2000) # 오차 최소화 과정 2000번 반복
#시각화
plt.scatter(x, y)
plt.plot(x, model.predict(x), 'r')
plt.show()
로지스틱 회귀(logistic regression) 모델: 참 거짓 판단하기
- 앞서 봤던 예시(성적, 공부시간의 관계)처럼 수치로 이루어진 데이터는 선형회귀를 사용하기에 적절하다.
- 그러나 합격과 불합격처럼 카테고리로 이루어진 데이터는 로지스틱 회귀를 사용해야 한다.
시그모이드 함수(sigmoid)
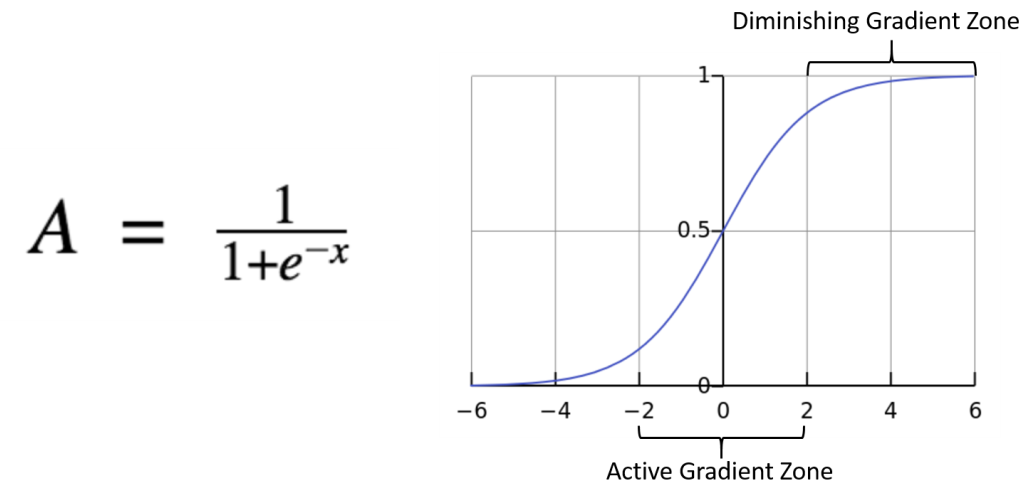
계수 의미
x = ax + b
- a는 그래프의 경사도를 결정함
- b는 그래프의 좌우이동을 의미함

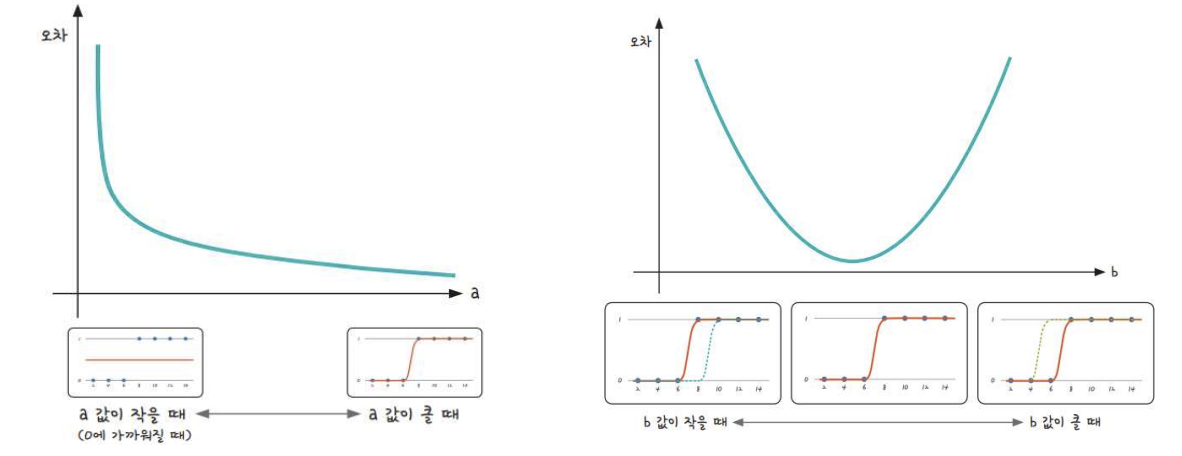
계수에 따른 오차
- a값이 작을수록 커짐 (발산)
- a값이 커진다고 오차가 없어지지는 않음
- b값이 너무 작아지거나 너무 커지면 오차도 커짐
교차 엔트로피(cross entropy error) 함수
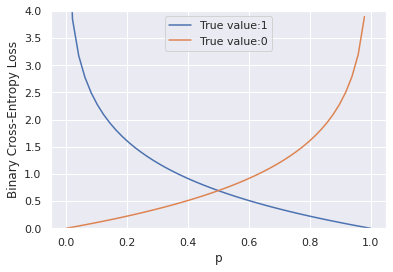
-{y * logh + (1-y) * log(1-h)}
1:-logh0:-log(1-h)
정리
- 선형회귀: 평균 제곱 오차함수
- 로지스틱회귀: 교차 엔트로피 오차함수
