GAN(생성적 적대 신경망)
가상의 이미지를 생성하는 알고리즘
예: 얼굴을 만든다면, 이미지 픽셀들이 어떻게 조합되어야 우리가 생각하는 '얼굴'의 형상이 되는지 알고리즘이 예측한 결과를 출력
- DCGAN(Deep Convolutional GAN): 페이스북의 AI 연구팀이 만들어낸 안정적인 GAN
적대적 경합
진짜같은 가짜를 만들기 위해 GAN 알고리즘 내부에서 생성자(Generator)는 가짜를 만들고 판별자(Discriminator)는 진짜와 비교하는 적대적 경합을 진행
➡️ 경찰과 위조 지폐범 예시: 진짜 지폐와 똑같은 위조 지폐를 만들기 위해 애쓰는 위조지폐범과 이를 구분하기 위해 애쓰는 경찰 사이의 경합이 결국 더 정교한 위조지폐를 만들어냄
Generator(생성자)
처음에는 랜덤한 픽셀값으로 채워진 가짜 이미지로 시작해서 판별자의 판별 결과에 따라 지속적으로 업데이트하며 점차 원하는 가상의 이미지를 만들어냄
DCGAN에서 사용되는 CNN
- optimizer를 사용하는 최적화 과정, 컴파일 과정이 없음
- 풀링 과정 X
- 패딩 과정 추가
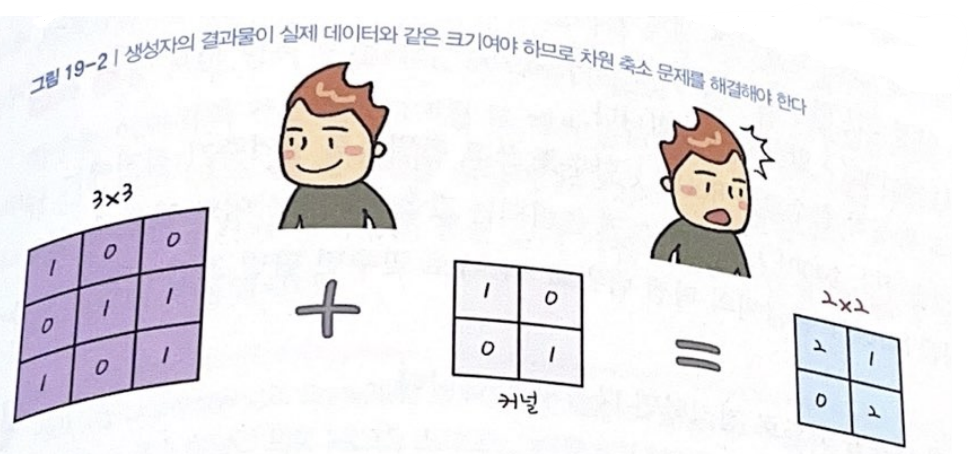
커널을 이동하며 컨볼루션 층을 만들 때 이미지의 크기가 처음보다 줄어듦. 그러나 판별자가 비교할 '진짜' 이미지와 크기가 같아야 하므로 크기를 조절해야 함.
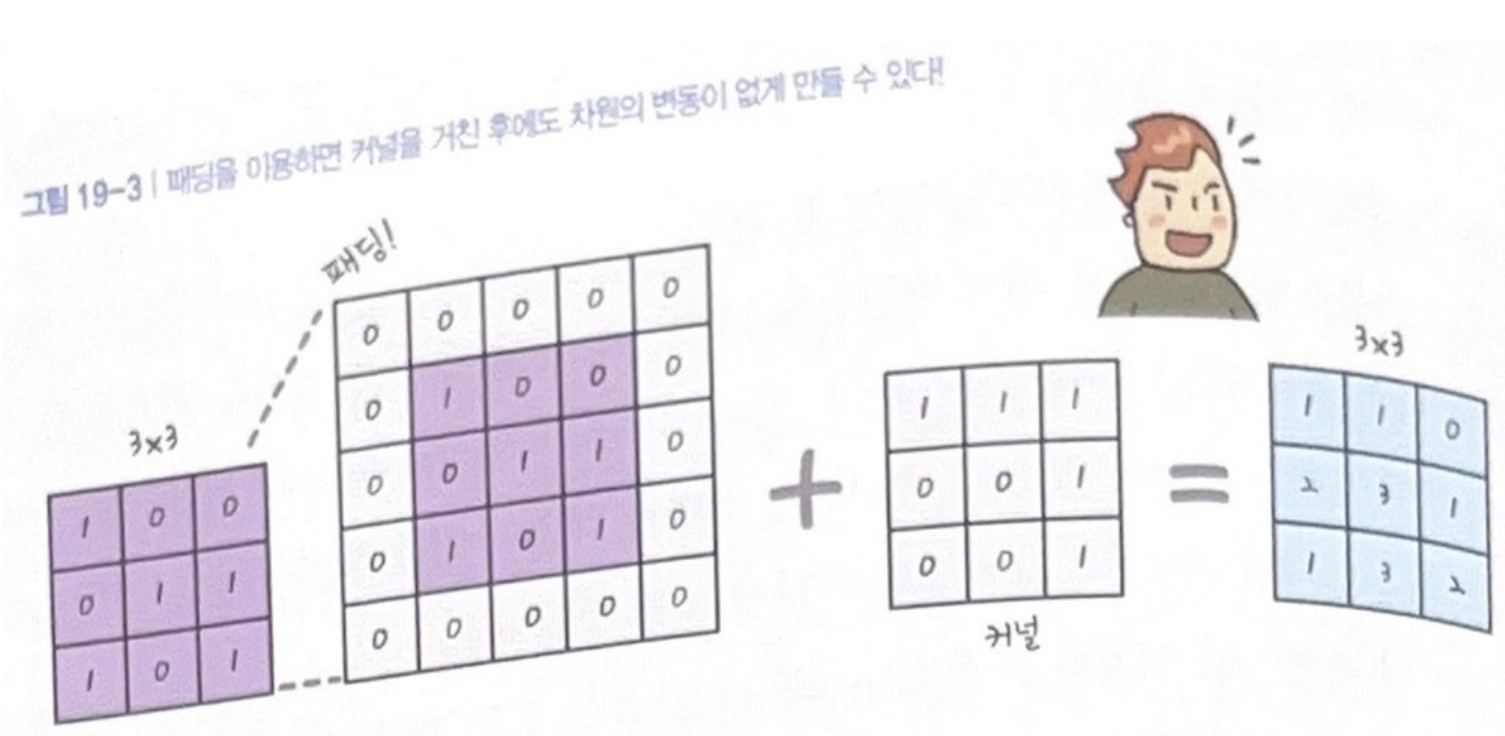
padding = same으로 설정해 입력과 출력의 크기가 다를 경우 자동으로 크기를 확장하고, 확장된 공간에 0을 채워넣음.
- 배치 정규화: 입력 데이터의 평균이 0, 분산이 1이 되도록 재배치 ➡️ 다음 층으로 입력될 값을 일정하게 재배치해서 층의 개수가 늘어나더라도 안정적인 학습을 진행할 수 있음
BatchNormalization()함수 사용 - 생성자의 활성화 함수:
ReLU(), 판별자로 넘겨주기 직전에는tanh()함수를 사용해 출력값을 -1 ~ 1로 맞춤 - 단, 판별자에 입력될 MNIST 손글씨의 픽셀범위도 -1 ~ 1로 통일해야 함
model = Sequential()
model.add(Dense(128*7*7, input_dim = 100, activation = LeakyReLU(0, 2)))- 128, 100은 임의로 정한 수이므로 바꿀 수 있음.
7*7: 이미지의 최초 크기.
MNIST 데이터의 이미지 크기는28*28인데 왜7*7을 넣을까?UpSampling2D함수는 이미지의 가로 세로 크기를 각각 2배씩 늘려줌. 이 함수를 두번 사용했으므로 최종적으로 이미지는 처음 크기에서 가로 세로 각각 4배씩 증가하게 될 것임. 따라서7 * 7을 넣으면7*2*2=28의 계산 과정을 거쳐 이미지 크기가 일치하게 됨.
model.add(BatchNormalization())
model.add(Reshape((7, 7, 128))) Reshape함수를 사용해 컨볼루션 레이어가 받아들일 수 있는 형태로 이미지를 변경함
model.add(UpSampling2D())
model.add(Conv2D(64, kernel_size=5, padding='same')UpSampling2D를 이용해서 2배씩 업샘플링을 한 후Conv2D를 이용해서 컨볼루션 과정 처리함. 이 때,padding='same'조건 덕분에 모자라는 부분은 자동으로 0이 채워짐.
model.add(BatchNormalization())BatchNormalization함수를 이용해 데이터의 배치를 정규분포로 만듦
model.add(Activation(LeakyReLU(0.2)))
model.add(UpSampling2D())
model.add(Conv2D(1, kernel_size=5, padding='same', activation ='tanh'))
# 판별자로 넘길 준비를 마침- 활성화함수로
ReLU를 사용하면 학습이 불안정해지는 경우가 많음 - 대신
ReLU함수에서 x값이 음수이면 무조건 0이 되어 뉴런들이 일찍 소실되는 단점을 보완하기 위해, 0 이하에서도 작은 값을 가지게 하는 활성화함수LeakyReLU사용
LeakyReLU(0.2): 0보다 작을 경우 0.2를 곱해라
Discriminator(판별자)
- 둘 중 하나를 결정하는 문제이므로 컴파일 부분은
binary_crossentrophy함수 사용
model = Sequential()
model.add(Conv2D(64, kernel_size=5, strides=2, input_shape=(28, 28, 1), padding="same"))
model.add(Activation(LeakyReLU(0.2))
model.add(Dropout(0.3))
model.add(Conv2D(128, kernel_size=5, strides=2, padding="same"))
model.add(Activation(LeakyReLU(0.2))
model.add(Dropout(0.3))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
# 판별의 결과가 진짜 혹은 가짜 둘 중에 하나가 되어야 하므로 시그모이드 함수 사용
model.compile(loss='binary_crossentrophy', optimizer='adam')
model.trainable = False-
strides옵션은 커널 윈도를 몇 칸씩 이동시킬지를 정하는 옵션(디폴트값은 1칸)
커널윈도를 여러칸 움직이면 가로세로 크기가 더 줄어들어 드롭아웃이나 풀링처럼 새로운 특징을 뽑아주는 효과가 있음 -
Flatten사용해서 2차원에서 1차원으로 바꿈 -
판별자는 가짜인지 진짜인지를 판별만 해줄 뿐, 자기 자신이 학습을 해서는 안되므로
model.trainable = False로 설정함
적대적 신경망 실행하기
- 생성자에서 나온 출력을 판별자에 넣어서 진위여부를 판단하게 만듦
정확도가 0.5에 가까워질 때 (생성 데이터와 실제 데이터가 너무나 유사해졌기 때문에) 목적을 달성해 학습이 종료됨
# 랜덤한 100개의 벡터를 input함수에 집어넣어서 생성자에 입력할 ginput 생성
ginput = Input(shape(100, ))
dis_output = discriminator(generator(ginput))
gan = Model(ginput, dis_output)
gan.compile(loss = 'binary_crossentropy', optimizer='adam')
- 실행 함수 만들기
def gan_train(epoch, batch_size, saving_interval):
# MNIST 데이터 불러오기
(X_train, _), (_, _) = mnist.load_data()
# 이미지만 사용할 것이므로 X_train만 호출
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1).astype('float32')
# 정규화
X_train = (X_train - 127.5) / 127.5
true = np.ones((batch_size, 1)) # 실제 이미지를 입력했으므로 1(참)을 레이블링
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
d_loss_real = discriminator.train_on_batch(img, true)batch_size: 한번에 몇개의 실제이미지와 몇개의 가상이미지를 판별자에 넣을지 결정하는 변수np.random.randint(a, b, c): a부터 b까지의 숫자 중 하나를 랜덤하게 선택한 수를 c개 생성
fake = np.ones((batch_size, 0))
noise = np.random.normal(0, 1, (batch_size, 100))
gen_imgs = generator.predict(noise)
d_loss_fake = discriminator.train_on_batch(gen_imgs, fake)- 학습이 반복될 수록 0(거짓)이라는 레이블을 붙인 생성 이미지들에 대한 예측 결과가 틀리게 됨 (진짜로 착각하므로)
- 판별자의 오차: 실제 이미지 예측 오차와 생성(가짜) 이미지 예측 오차의 평균


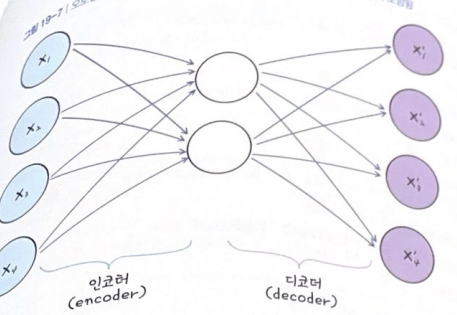
오토인코더(Auto-Encoder)
- GAN은 세상에 존재하지 않는 완전한 가상의 것을 만들어냄
GAN으로 사람의 얼굴을 만들면 진짜같아보여도 실제로 존재하지 않는 이미지가 생성됨 - 오토인코더는 입력 데이터의 특징을 효율적으로 담아낸 이미지를 만들어냄
초점이 좀 흐릿하고 윤곽이 불분명하지만 사람의 특징을 유추할 수 있는 것들이 모여서 이미지가 생성됨

- 오토인코더 활용분야: 영상의학분야 등 아직 데이터 수집이 충분하지 않은 분야
부족한 학습데이터를 늘려주는데에 사용할 수 있음
model = Sequential() # 생성자 모델 만들기
model.add(Conv2D(16, kernel_size=3, padding='same', input_shape=(28, 28, 1), activation='relu'))
model.add(MaxPooling2D(pool_size = 2, padding = 'same')
model.add(Conv2D(8, kernel_size=3, activation='relu', padding='same'))
model.add(MaxPooling2D(pool_size = 2, padding = 'same')
model.add(Conv2D(8, kernel_size=3, strides = 2, activation='relu', padding='same')) # 여기까지는 인코딩
# 디코딩 부분
model.add(Conv2D(8, kernel_size=3, activation='relu', padding='same'))
model.add(UpSampling2D())
model.add(Conv2D(8, kernel_size=3, activation='relu', padding='same'))
model.add(UpSampling2D())
model.add(Conv2D(16, kernel_size=3, activation='relu', padding='same'))
model.add(UpSampling2D())
model.add(Conv2D(1, kernel_size=3, padding='same', activation='sigmoid'))
model.summary()- 인코딩: 입력 값의 차원을 축소시킴
MaxPooling2D을 지나며 절반씩 줄어듦 - 디코딩: 차원을 점차 늘려서 입력값과 같은 크기의 출력값 내보냄
UpSampling2D을 지나며 두배씩 늘어남

