RNN
필요성
문장은 여러개의 단어로 이루어져있고, 그 의미가 올바르게 전달되려면 각 단어가 정해진 순서대로 입력되어야 함
즉, 여러 데이터가 순서와 관계없이 입력되던 것과는 달리 데이터의 입력 순서를 고려해야하는 상황이 생김
- 왜 이름이 순환 신경망일까?
모든 입력값에 이 작업을 순서대로 실행하므로 다음 층으로 넘어가기 전에 같은 층을 순환하듯 맴도는 것처럼 보임
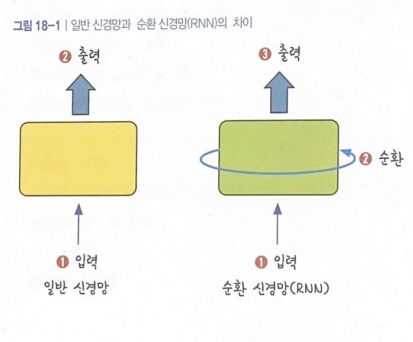
동작
여러 개의 데이터가 순서대로 입력됨
➡️ 앞서 입력받은 데이터를 잠시 기억해두고 기억된 데이터가 얼마나 중요한지 판단해서 별도의 가중치를 부여
➡️ 다음 데이터로 넘어감
예: 인공지능 비서에게 "오늘 주가가 몇이야?"라고 질문
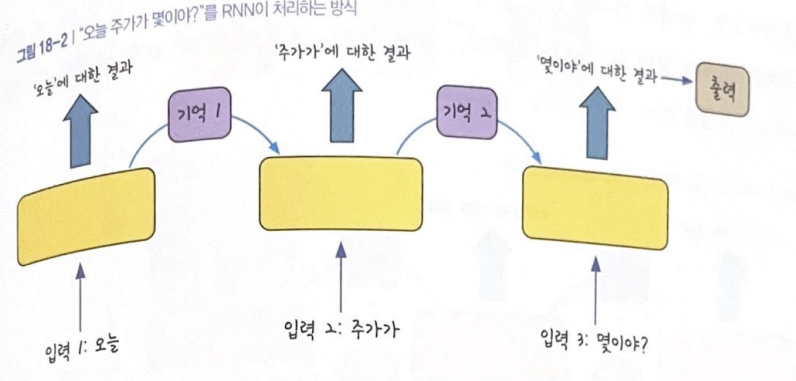
앞서 나온 입력에 대한 결과가 뒤에 나오는 입력값에 영향을 주는 것을 알 수 있음
'주가' 앞에 나오는 단어가 '어제'이냐 '오늘'이냐에 따라 출력값이 완전히 달라짐!
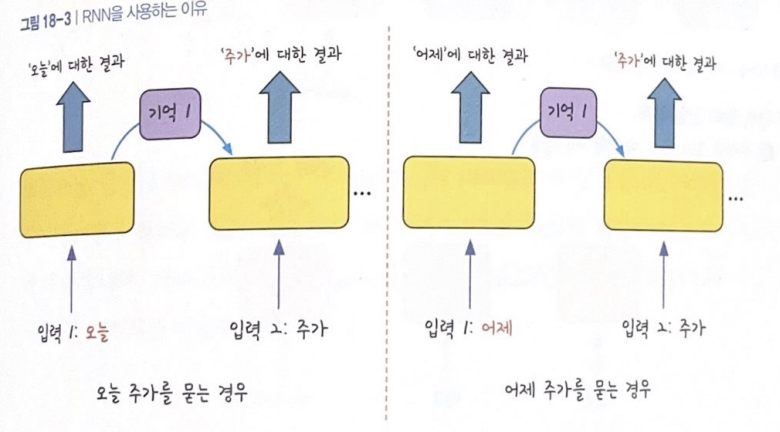
RNN의 단점
한 층 안에서 반복을 여러번 해야 하는 RNN의 특정상 일반 신경망에 비해 기울기 소실 문제가 더 많이 발생하고 해결이 어려움
➡️ LSTM(Long Short Term Memory)의 보완: 반복되기 직전에 다음층으로 기억된 값을 넘길지 여부를 관리하는 단계를 추가함
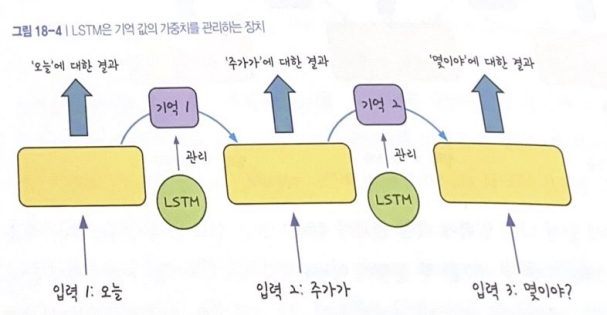
RNN의 장점
입력값과 출력값을 어떻게 설정하냐에 따라 여러가지 상황에 적용 가능
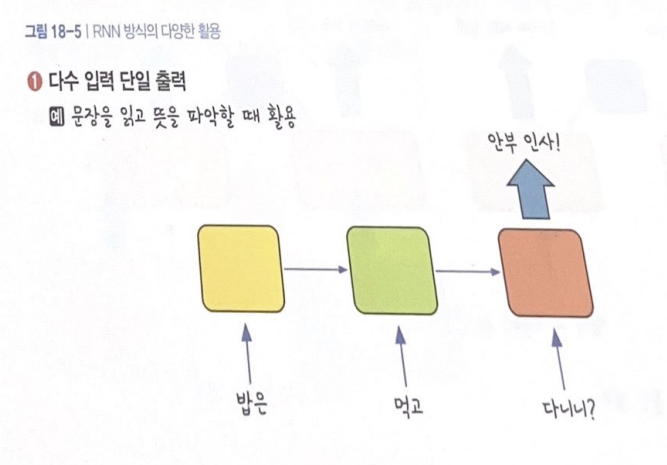
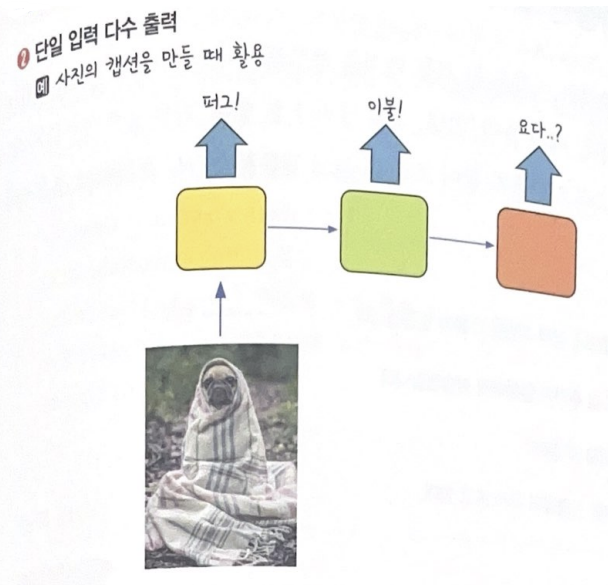
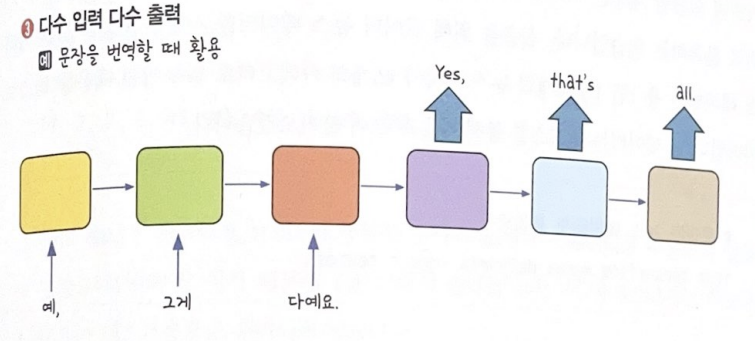
예제 1: 로이터 뉴스 카테고리 분류 (by LSTM)
입력된 문장 의미 파악 ➡️ 모든 단어를 종합해 하나의 카테고리로 분류

목표: 긴 텍스트 읽고 데이터가 어떤 의미를 지니는지 카테고리로 분류하기
데이터 설명
로이터 뉴스 데이터: 1만 1228개의 뉴스 기사가 46개의 카테고리로 나누어진 대용량 텍스트 데이터
코드 설명
np.max(데이터셋) + 1 : 데이터셋의 카테고리 개수 구하기 (0부터 세므로 1을 더해줌)
# 데이터 불러오기
from tensorflow.keras.datasets import reuters
# 테스트셋, 학습셋으로 나누기
(X_train, y_train), (X_test, y_test) = reuters.load_data(num_words=1000, test_split = 0.2)
# y_train의 종류 구하기
category = np.max(y_train)+1
print(category, '카테고리')
print(len(X_train), '학습용 뉴스기사 개수')
print(len(X_test), '테스트용 뉴스기사 개수')
print(X_train[0])
print(X_train[0])의 값이 단어가 아닌 숫자임 ➡️ 이미 토큰화를 마친 데이터를 불러왔음을 알 수 있음
각 단어가 몇번째로 많이 나오는 단어인지에 따라 숫자를 붙임
예: 3 ➡️ 3번째로 빈번하게 등장하는 단어
num_words=1000: 기사 안의 단어들 중 빈도가 1~1000에 해당하는 단어만 불러오기 (효율성)
패딩: 각 기사의 단어 수가 각각 다르므로 동일하게 맞춰주는 작업. sequence() 함수 사용
from tensorflow.keras.preprocessing import sequence
X_train = sequence.pad_sequences(X_train, maxlen = 100)
X_test = sequence.pad_sequences(X_test, maxlen = 100) # 단어수 100개로 맞추기원-핫 인코딩: y데이터를 0과 1만으로 이루어지도록 바꿈. categorical() 함수 사용
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)딥러닝 구조 만들기
Embedding(불러온 단어의 총 개수, 기사 당 단어 수)
LSTM(기사 당 단어 수, 활성화 함수)
model = Sequential()
model.add(Embedding(1000, 100))
model.add(LSTM(100, activation = 'tanh'))
model.add(Dense(46, activation = 'softmax'))학습 실행: 모델의 실행 옵션 설정, 조기 중단 설정 EarlyStopping()
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=5)
history = model.fit(X_train, y_train, batch_size = 20, epochs=200, validation_data = (X_test, y_test), callbacks=[early_stopping_callback])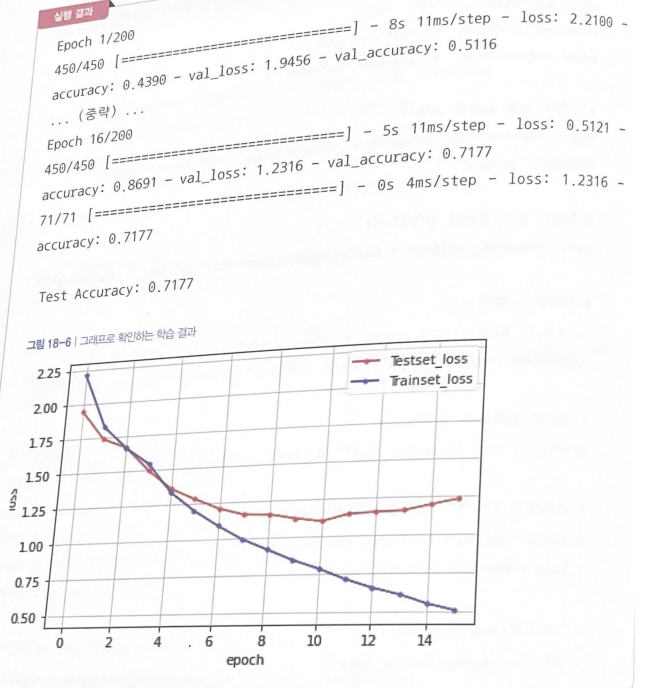
예제 2: IMDB 영화 리뷰
데이터 설명
IMDB: 영화와 관련된 정보, 출연진 정보, 개봉 정보, 영화 후기, 평점 등을 남기는 사이트
- 인터넷 영화 데이터베이스 데이터
- 영화에 관해 남긴 2만 5000여개의 영화 리뷰와 각 리뷰가 긍정적인지 부정적인지에 대한 정보
- 각 단어에 대한 전처리를 마친 상태
- 클래스가 긍정, 부정 2개 뿐이라 원-핫 인코딩 과정이 없는 것 빼고는 이전과 동일한 과정을 거침
코드 설명
load_data()를 이용해 테스트셋 지정: num_words=5000로 설정
sequence.pad_sequence()함수를 이용해 패딩: max_len = 500으로 설정
model.Sequential()
model.add(Embedding(5000, 100))
model.add(Dropout(0.5))
model.add(Conv1D(64, 5, padding='valid', activation='relu', strides=1)
model.add(MaxPooling1D(pool_size=4))
model.add(LTSM(55))
model.add(Dense(1))
model.add(Activation('sigmoid')
model.summary() # 현재 설정된 모델의 구조 출력
앞서 이미지에 적용할 때에는 이미지가 2차원 데이터이므로 Conv, MaxPooling을 2D로 적용한 반면, 여기에서는 텍스트 데이터이므로 1D로 적용하기
Conv1D
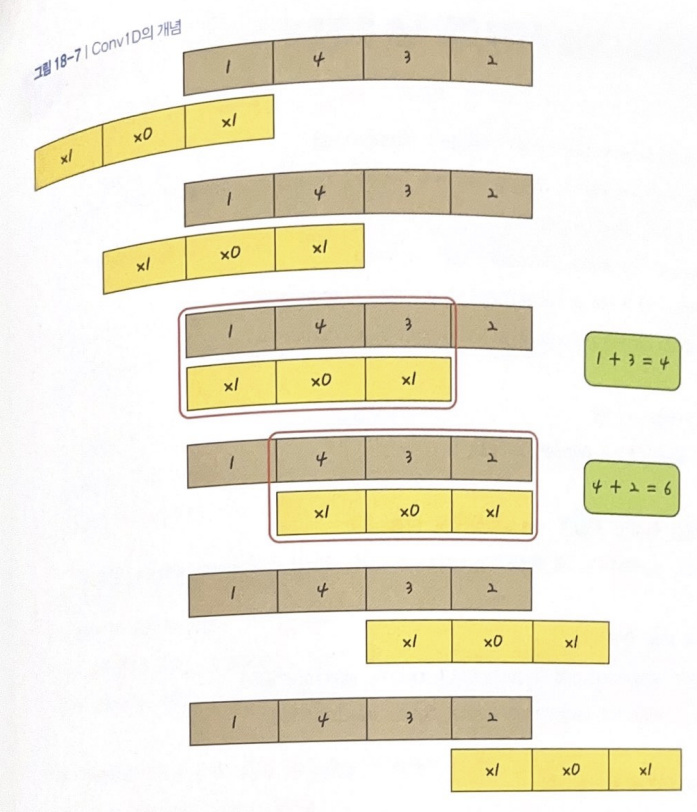
- 노란색 배열: 커널
- 갈색 배열: 원래 배열, 컨볼루션 층
MaxPooling1D

결과

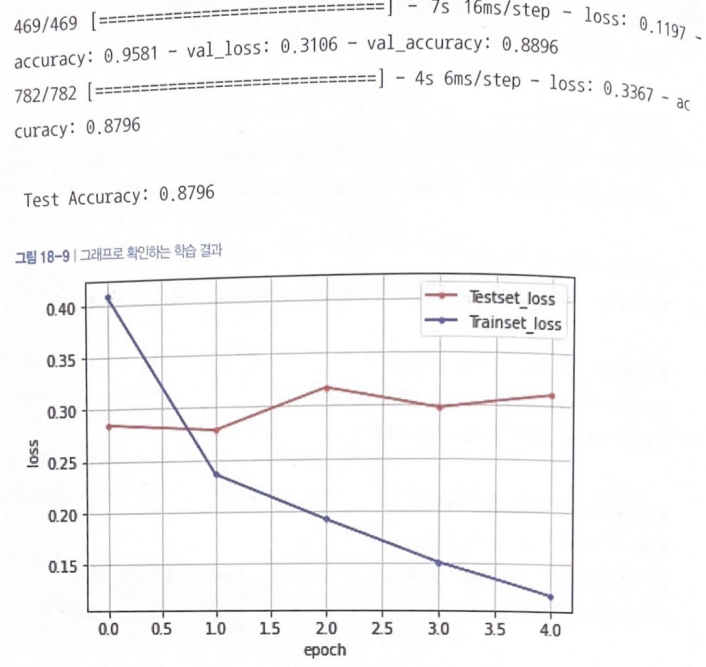
5th epoch에서 테스트셋 정확도 87.96%로 학습 자동 중단
어텐션을 활용한 신경망
알파폴드 2
2020년 12월, 제 14대 세계 단백질 구조 예측 대회 도중 압도적인 정확성으로 단백칠 코드를 예측함
제작자: 구글의 딥마인드 (알파고 제작자)
주요 알고리즘: 어텐션
RNN의 한계
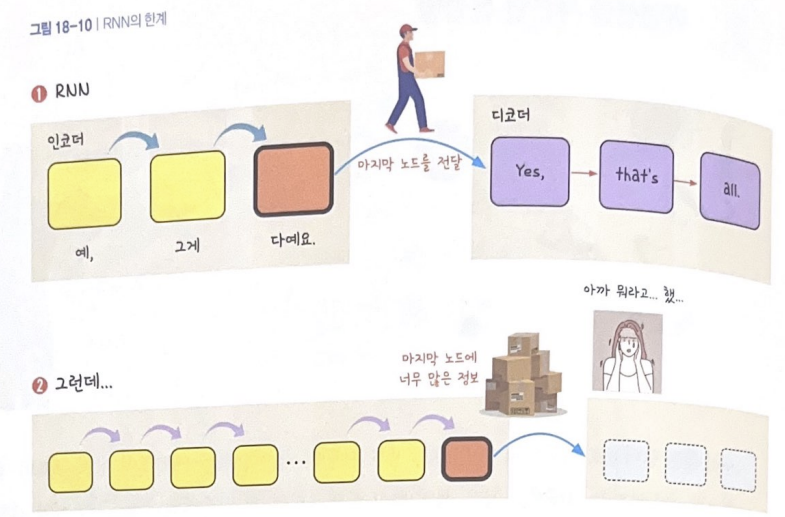
- 입력값의 길이가 너무 김
선두에서 전달받은 결괏값이 중간에 희미해짐
문백벡터(주황색 마지막 셀)가 모든 값을 제대로 디코더에 전달하는 것이 어려워짐
어텐션
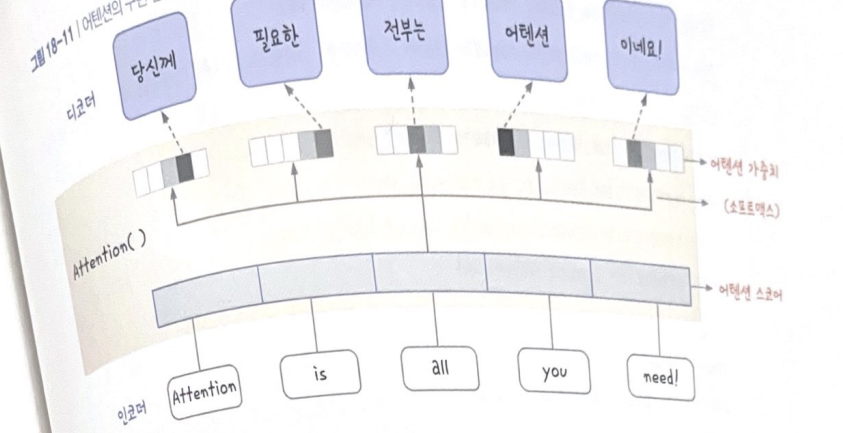
인코더와 디코더 사이에 층을 하나 만듦
➡️ 새로 삽입된 층에는 어텐션 스코어(각 셀로부터 계산된 스코어들)가 모임
➡️ 어텐션 스코어에 소프트맥스 함수를 적용해 어텐션 가중치 만들기
➡️ 어텐션 가중치를 이용해 입력값 중 어떤 셀을 중점적으로 볼 지를 판단
예: 첫번째 출력 단어인 '당신께'에 대응하는 단어는 'you'임을 학습
➡️ 매 출력마다 모든 입력값을 두루 활용하게 함
➡️ 마지막 셀에 모든 입력이 집중되던 RNN의 단점 극복
!pip install attention
# 앞서 작성한 모델 구조에 attention 추가
model.Sequential()
model.add(Embedding(5000, 500))
model.add(Dropout(0.5))
model.add(LTSM(64, return_sequences=True))
model.add(Attention())
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid')
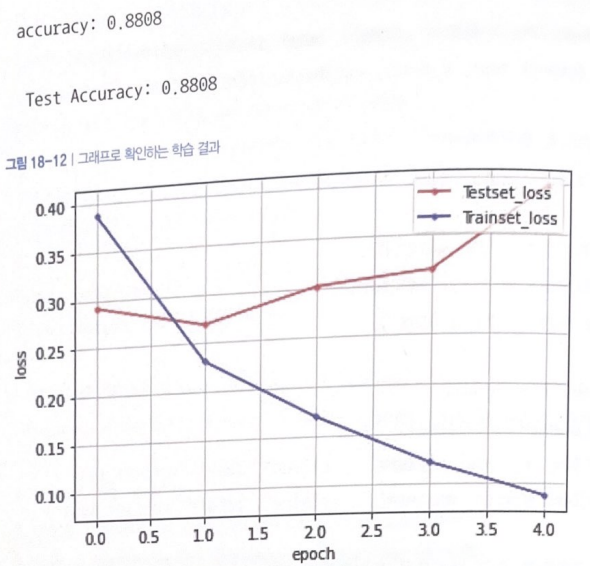
정확도: (어텐션 X) 84.54% ➡️ (어텐션 O) 88.08%
어텐션의 한계점 (교수님 피피티 추가)
seq2seq 구조의 한계점
• Decoder가 단어를 예측할 때, encoder의 마지막 시점 은닉층 정보(contect vector, C)만을 활용
➡️ 각 단어 예측 시 더 중요하게 집중해야 하는 encoder 부분 단어가 다른데, 이를 반영할 수 없음
- 과정
- 내용을 잘 요약할 수 있는 Context Vector, C (단 1개의 vector)
를 만듦 - 그 한 개의 벡터를 이용해서, 번역하고자 하는 한글의 모든 단어들을
만들어 냄
- 문제 & 대안
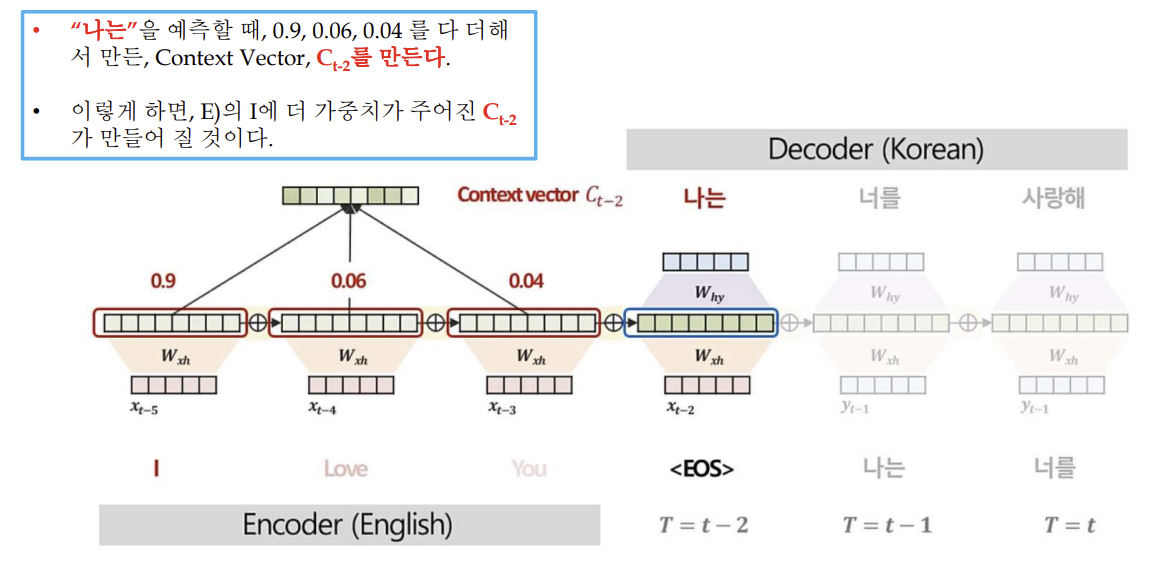
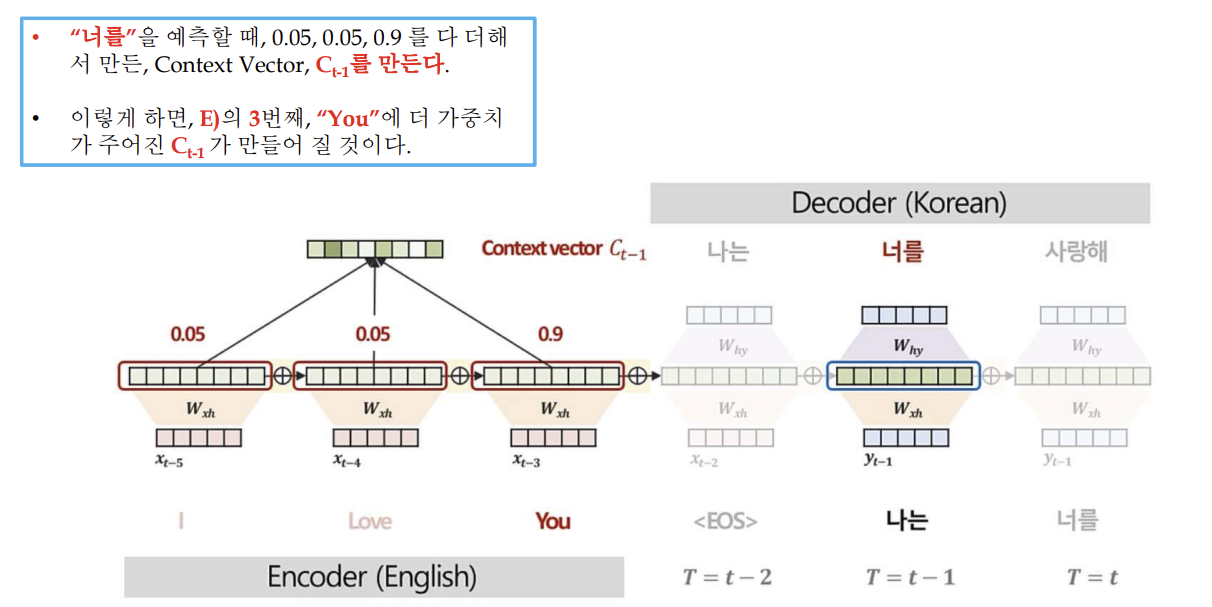
문제: “나는”을 만들 때, Context Vector의 모든 부분이 중요하지는 않으나, 어떤 부분이 더 중요한지를 반영하지 못함
대안: “나는” 예측 시, Context Vector의 매 시점 정보를 참고하고, 중요한 단어가 어떤 것인지 알려서 중요도에 따라 다르게 집중할 수 있도록 하자. 즉, “나는“을 처리할 때, Context Vector의 (I, Love, You, 3개) 중에서, 어떤 단어가 더 “나는”에 가까운 단어인지를 알려주자. - 각 내적 값들을 확률값으로 표현하자.
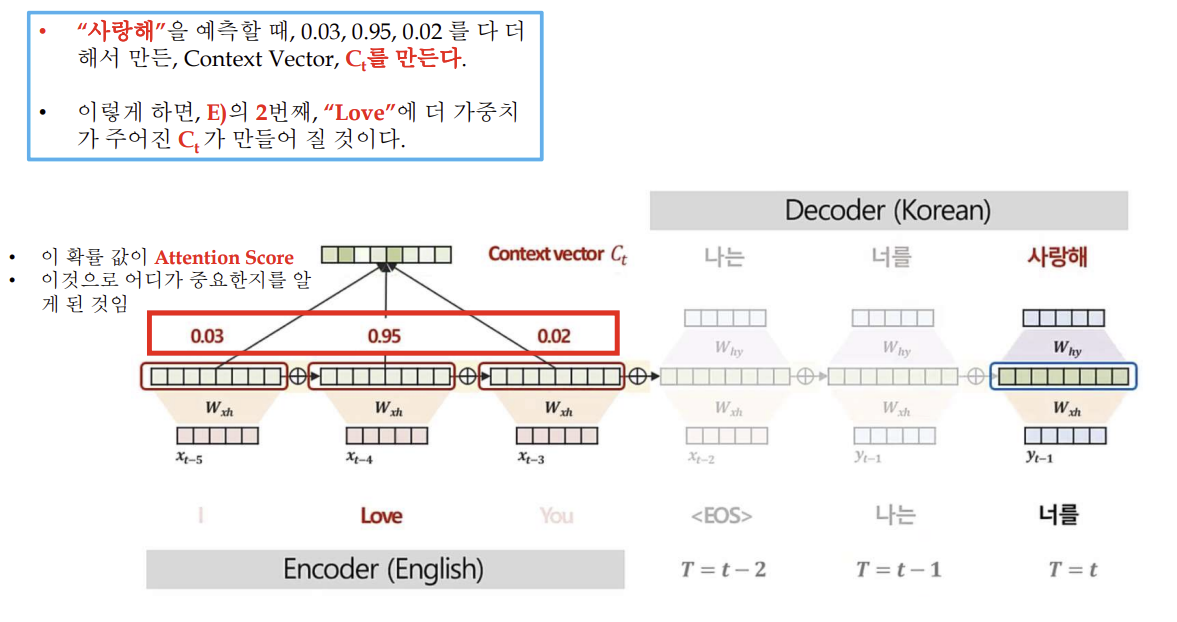
어텐션의 작동 과정 설명 그림
어텐션 구조의 장점
- attention score(집중하는 정도)를 구할 수 있음
➡️ 모델이 예측에 필요한 부분을 정량적으로 해석할 수 있음
➡️ 관측치 별 중요도 도출이 가능하므로 원인인자 규명 가능 - 기존 딥러닝 모델의 단점: 뛰어난 예측력에 비해 해석이 부족함
➡️ attention은 속성별, 시간별 중요도 산출이 가능함
➡️ 그러므로 attention은 해석 가능한 인공지능 기법 (eXplainable AI)라고 할 수 있음
