모델의 구조(layer들) 정의
Data_set = np.loadtxt("저장위치", delimiter=",")
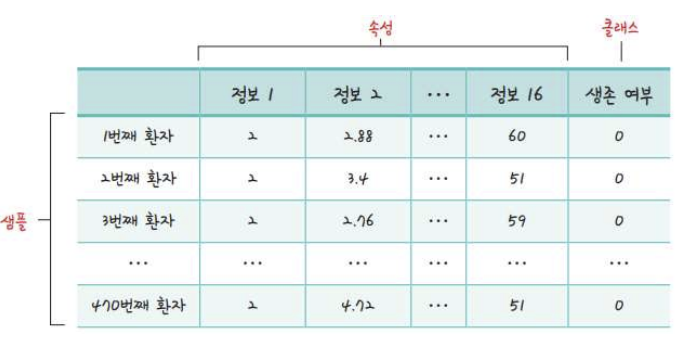
X = Data_set[:, 0 : 16]
y = Data_set[;, 16]
model = Sequential()
model.add(Dense(30, input_dim=16, activation='relu'))
model.add(Dense(1, activation='sigmoid)
model.add() : 층 생성- 일반적인 층 ➡️
Dense(노드(input값 * weight들의 총합 + bias)의 개수, input값 개수, 활성화함수)
- 출력층 ➡️
Dense(1, activation='sigmoid)
- 위의 코드에서는 첫번째 Dense가 은닉층 + 입력층의 역할 수행
모델 컴파일
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
- 오차함수(손실함수) 설정
- 평균 제곱 오차
mean_squared_error (선형회귀(결과가 수치로 나옴)에서 사용)
(1) 평균 제곱 오차 : mean_squared_error
(2) 평균 절대 오차 : mean_absolute_error 실제값과 예측값 사이의 절댓값 평균
(3) 평균 절대 백분율 오차 : mean_absolute_percentage_error 절댓값 오차를 절댓값으로 나눈 후 평균
(4) 평균 제곱 로그 오차 : mean_squared_logarithmic_error 실제 값과 예측 값에 로그를 적용한 값의 차이를 제곱한 값의 평균
- 교차 엔트로피 오차 (로지스틱 회귀(결과가 카테고리로 나옴)에서 사용)
(1) 이항 분류 : binary_crossentropy (카테고리 2개)
(2) 다항 분류: categorical_crossentropy
➡️ 예: 폐암수술환자의 생존률 예측은 생존/사망 중 하나를 택하므로 이걸 사용함
- Optimizer 설정
metrics=['accuracy'] 파트: 학습셋에 대한 정확도에 기반해 결과를 출력하라는 뜻임.
accuracy 대체 가능한 코드들:
(1) val_acc: 검증셋을 적용할 경우, 검증셋에 대한 정확도를 나타냄
(2) loss: 학습셋에 대한 손실값을 나타냄
(3) val_loss: 검증셋에 대한 손실값을 나타냄
모델 실행
history = model.fit(X, y, epochs = 5, batch_size = 16)
epoch : 학습이 모든 샘플에 대해 한번 실행되는 것을 1 epoch라고 함. batch_size : 전체 샘플을 몇개씩 끊어서 집어넣을지 설정하는 것. 너무 크면 학습 속도가 느려지고, 너무 작으면 각 실행 값의 편차가 생겨서 전체 결괏값이 불안정해질 수 있음. 본인의 컴퓨터 메모리가 감당할 만큼의 크기를 찾아야 함.
