- 레드와인, 화이트와인 구분 모델을 다룸
검증셋(Validation set)
- 검증셋이란? 최적의 학습 파라미터를 찾기 위해 학습 과정에서 사용하는 것.
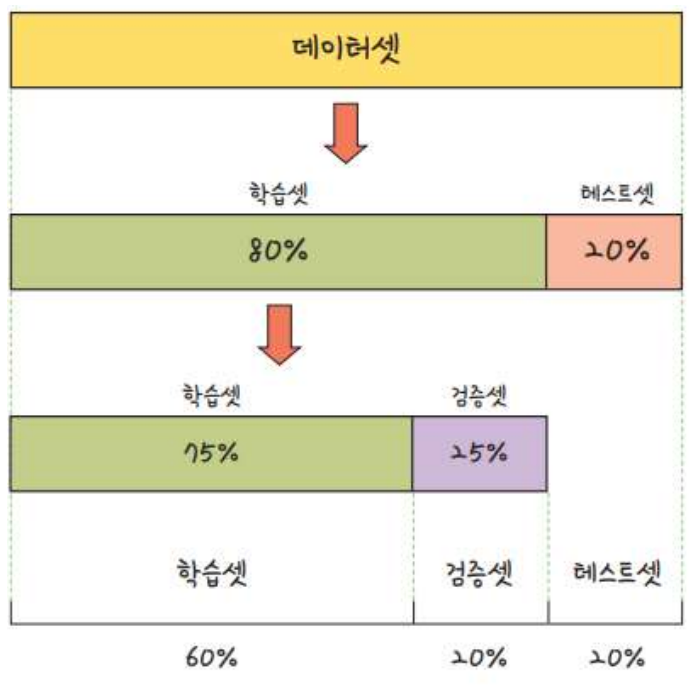
- train : val : test = 6 : 2 : 2
history = model.fit(X_train, y_train, epochs=50, batch_size = 500, validation_split=0.25)-
여기서, test set은
-
train_test_split는test_size로 설정된 비율로 test set을, 나머지 비율(0.8)로 train set을 분류함.
더 많은 가짓수로 나누는 기능은 없음 (여기서 val까지 나눌 수는 없음.)
epoch 설정
- 만약 50번의 epoch 중 최적의 학습이 40번째에서 이루어졌다면, 이 40번째의 모델을 어떻게 불러올 수 있을까?
- epoch마다 모델의 정확도를 기록하며 저장하는 방법을 알아보자.
modelpath = "./data/model/all/{epoch:02d}-{val_accuracy:4f}/hdf5"
# 50번째 epoch의 정확도가 0.9346 -> 50-0.9346.hdf로 저장되도록 지정한 형식의 경로를 만듦
from tensorflow.keras.callbacks import ModelCheckpoint
# 학습 중인 모델을 저장하는 ModelCheckpoint() 함수를 keras api로부터 불러옴
checkpointer = ModelCheckpoint(filepath = modelpath, verbose = 1)
# verbose: 진행현황 모니터링 기능임. 1로 설정하면 켜는 것
# 모델 실행 -> 결과는 history에 저장됨
# history.params: model.fit()의 설정값이 저장됨
# history.epoch: epoch 정보
# history.history: loss, accuracy, val_loss, val_accuracy <- 우리에게 필요한 정보!
history = model.fit(X_train, y_train, epochs=50, batch_size=500, validation_split = 0.25, verbose = 0, callbacks = [checkpointer])
score = model.evaluate(X_test, y_test)
print("test accuracy: ", score[1]) # 결과 출력hist_df = pd.DataFrame(history.history)로 불러와 살펴보자.
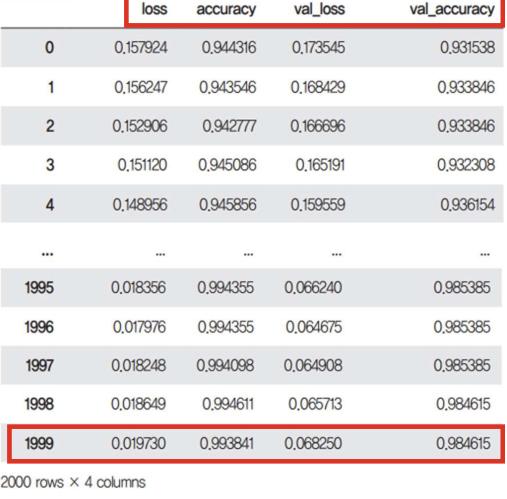
총 2000번의 학습결과가 저장되어있다. 이 때, 오차를val_loss(모델을 검증셋에 적용해 얻은 오차)와loss(모델을 학습셋에 적용해 얻은 오차)로 나눠서 저장해보자.
y_vloss = hist_df['val_loss']
y_loss = hist_df['loss']이를 각각 그래프로 그려보면 다음과 같다.
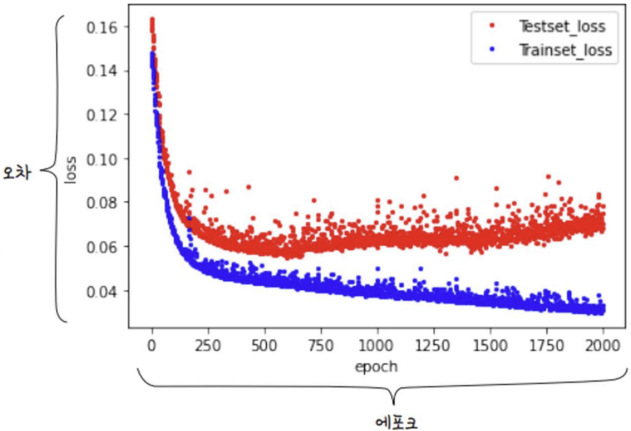
주목해야 할 부분은 학습이 오래 진행될 수록 학습셋의 오차(loss)는 줄어들이잠 검증셋의 오차(val_loss)는 다시 커진다는 것이다.
이 때, 검증셋의 오차가 다시 커지기 직전까지 학습한 모델이 최적의 횟수로 학습한 모델이다.
그렇다면 검증셋의 오차가 커지기 전에 학습을 자동으로 중단시키고, 그 지점의 모델을 저장하는 방법을 알아보자.
학습의 자동 중단
from tensorplow.keras.callbacks import EarlyStopping
# 최적화된 모델이 저장될 폴더와 모델 이름 지정
modelpath = "./data/model/Ch14-4-bestmodel.hdf5"
early_stopping_callback = EarlyStopping(monitor="val_loss", patience=20)
# monitor: model.fit()의 실행 값 중 어느 것을 선택할지를 지정
# patience: 지정된 값이 몇번 이상 향상되지 않으면 종료시킬지를 지정
# 최적의 모델 update, 저장
checkpointer = ModelCheckpoint(filepath = modelpath, monitor = 'val_loss', verbose = 0, save_best_only = True)
# 모델 실행 (어차피 자동으로 최적의 epoch를 찾아 멈출 예정이므로 epoch는 넉넉히 선언) -> 실제 394번에서 멈춤
history = model.fit(X_train, y_train, epochs = 2000, batch_size = 500, validation_split = 0.25, verbose = 1, callbacks = [early_stopping_callback, checkpointer])EarlyStopping(): 학습이 진행되어도 테스트셋의 오차가 줄어들지 않으면 자동으로 학습을 멈추게 하는 함수
