
Professional Machine Learning Engineer Sample Questions
본 문제들은 Google GCP Machine Learning Engineer 자격증 준비를 위한 예제문제입니다.
1. You work for a textile manufacturer and have been asked to build a model to detect and classify fabric defects. You trained a machine learning model with high recall based on high resolution images taken at the end of the production line. You want quality control inspectors to gain trust in your model. Which technique should you use to understand the rationale of your classifier?

- A. Use K-fold cross validation to understand how the model performs on different test datasets.
- B. Use the Integrated Gradients method to efficiently compute feature attributions for each predicted image.
- C. Use PCA (Principal Component Analysis) to reduce the original feature set to a smaller set of easily understood features.
- D. Use k-means clustering to group similar images together, and calculate the Davies-Bouldin index to evaluate the separation between clusters.
정답
B. Integrated Gradients를 사용하여 이미지 예측을 위한 feature attribution을 효율적으로 계산
본 문제는 image classifier의 성능을 평가할 수 있는 보기를 고르는 문제입니다. Integrated Gradients를 이용하면 이미지 입력의 어떤 pixel값들이 출력을 결정하는데 크게 기여하는지 알 수 있습니다. 입력 이미지의 pixel식별은 이미지 분류로 이어지기 때문에 B가 정답입니다. (GCP에서 사용가능)
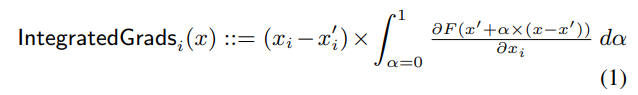

[refrenece : http://isukorea.com/blog/home/waylight3/281]
오답
A → K-folde cross validation은 모델의 예측에 대한 설명력이 없습니다.
C → PCA는 높은 차원의 데이터셋의 차원을 축소 하지만 시나리오에 추가적인 이점이 없습니다.
D → Clustering은 분류 모델이 예측한 이유에 대한 인사이트가 없습니다.
2. You need to write a generic test to verify whether Dense Neural Network (DNN) models automatically released by your team have a sufficient number of parameters to learn the task for which they were built. What should you do?

- A. Train the model for a few iterations, and check for NaN values.
- B. Train the model for a few iterations, and verify that the loss is constant.
- C. Train a simple linear model, and determine if the DNN model outperforms it.
- D. Train the model with no regularization, and verify that the loss function is close to zero.
정답
D. 정규화 없이 모델을 훈련시키고 loss가 0에 가까워지는지 확인합니다.
parameter가 충분하여 설명력이 있다면 loss가 감소해야 합니다.
오답
C → 단순히 선형 모델보다 결과가 좋다고 해서 비선형 데이터 표현을 학습하기에 충분한 parameter가 있다고 보장할 수 없습니다.
3. Your team is using a TensorFlow Inception-v3 CNN model pretrained on ImageNet for an image classification prediction challenge on 10,000 images. You will use AI Platform to perform the model training. What TensorFlow distribution strategy and AI Platform training job configuration should you use to train the model and optimize for wall-clock time?

- A. Default Strategy; Custom tier with a single master node and four v100 GPUs.
- B. One Device Strategy; Custom tier with a single master node and four v100 GPUs.
- C. One Device Strategy; Custom tier with a single master node and eight v100 GPUs.
- D. Central Storage Strategy; Custom tier with a single master node and four v100 GPUs.
정답
D. Central Storage Strategy; Custom tier with a single master node and four v100 GPUs.
D → [Distributed training with Tensorflow]
본 문제는 분산처리가 가능한 작업 구성에 대한 문제입니다. 분산처리가 되는 Strategy가 D밖에 없습니다.
central_storage_strategy = tf.distribute.experimental.CentralStorageStrategy()오답
A,B,C → 모두 단일 장치 구성입니다.
4. You work on a team where the process for deploying a model into production starts with data scientists training different versions of models in a Kubeflow pipeline. The workflow then stores the new model artifact into the corresponding Cloud Storage bucket. You need to build the next steps of the pipeline after the submitted model is ready to be tested and deployed in production on AI Platform. How should you configure the architecture before deploying the model to production?

- A. Deploy model in test environment -> Validate model -> Create a new AI Platform model version
- B. Validate model -> Deploy model in test environment -> Create a new AI Platform model version
- C. Create a new AI Platform model version -> Validate model -> Deploy model in test environment
- D. Create a new AI Platform model version - > Deploy model in test environment -> Validate model
정답
A. 테스트 환경에서 모델 배포 → 모델 유효성 검사 → 새 AI 플랫폼 모델 버전 만들기
모델이 테스트 환경에서 배포된 수 유효성 검사를 할 수 있고, 프로덕션에 배포되기 전 릴리스 버전이 설정되기 때문에 정확합니다.
오답
B → 테스트 환경에 배포 전에 유효성 검사를 할 수 없습니다.
C → 모델이 검증되기 전에 릴리스 후보에 대한 모델 버전이 설정되기 때문에 X
D → 테스트 환경에 배포전에 유효성 검사 X, 모델 검증 전 릴리스 버전 설정 X
5. You work for a maintenance company and have built and trained a deep learning model that identifies defects based on thermal images of underground electric cables. Your dataset contains 10,000 images, 100 of which contain visible defects. How should you evaluate the performance of the model on a test dataset?

- A. Calculate the Area Under the Curve (AUC) value.
- B. Calculate the number of true positive results predicted by the model.
- C. Calculate the fraction of images predicted by the model to have a visible defect.
- D. Calculate the Cosine Similarity to compare the model’s performance on the test dataset to the model’s performance on the training dataset.
정답
A. AUC값을 계산한다.
AUC는 선택된 임계 분류임계 값에 관계없이 모델의 예측 품질을 측정합니다.
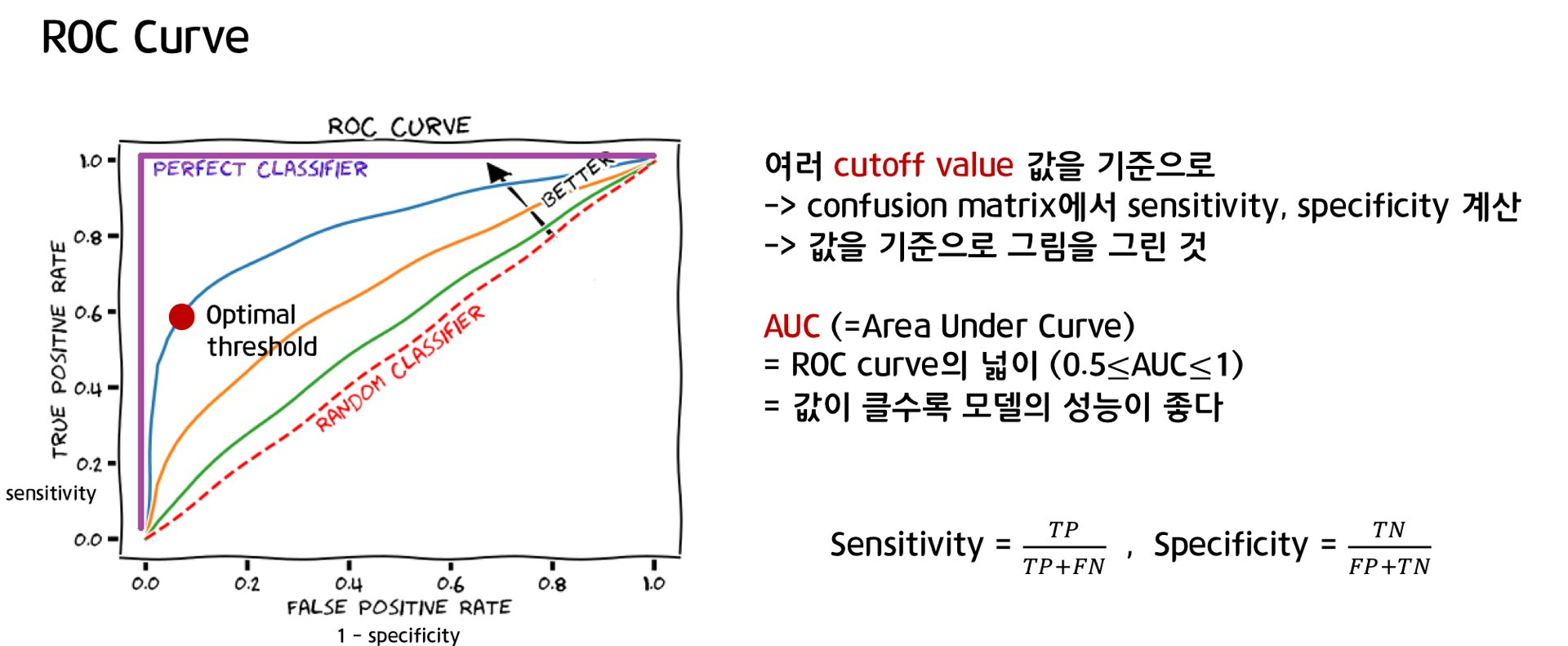
오답
B → 10,000개 중에 100개만 결함입니다. 단순히 TP를 계산하는 것은 의미가 없습니다.

C → 단순히 결함이 있는 이미지의 비율을 계산하는 것은 모델의 정확성을 판단하는데 관련이 없습니다.
D → Cosine Similarity는 거리기반 모델(ex.KNN)에서 유용합니다. image classification 모델의 성능을 확인하는데 적절하지 않습니다.
6. You work for a manufacturing company that owns a high-value machine which has several machine settings and multiple sensors. A history of the machine’s hourly sensor readings and known failure event data are stored in BigQuery. You need to predict if the machine will fail within the next 3 days in order to schedule maintenance before the machine fails. Which data preparation and model training steps should you take?

- A. Data preparation: Daily max value feature engineering with DataPrep; Model training: AutoML classification with BQML
- B. Data preparation: Daily min value feature engineering with DataPrep; Model training: Logistic regression with BQML and AUTO_CLASS_WEIGHTS set to True
- C. Data preparation: Rolling average feature engineering with DataPrep; Model training: Logistic regression with BQML and AUTO_CLASS_WEIGHTS set to False
- D. Data preparation: Rolling average feature engineering with DataPrep; Model training: Logistic regression with BQML and AUTO_CLASS_WEIGHTS set to True
정답
D. 데이터 준비→DataPrep을 사용한 롤릴 평균 기능 엔지니어링
모델학습 → BQML 및 AUTO_CLASS_WEIGHTS가 TRUE로 설정된 로지스틱 회귀
DataPrep : rolling average == moving average == 이동평균
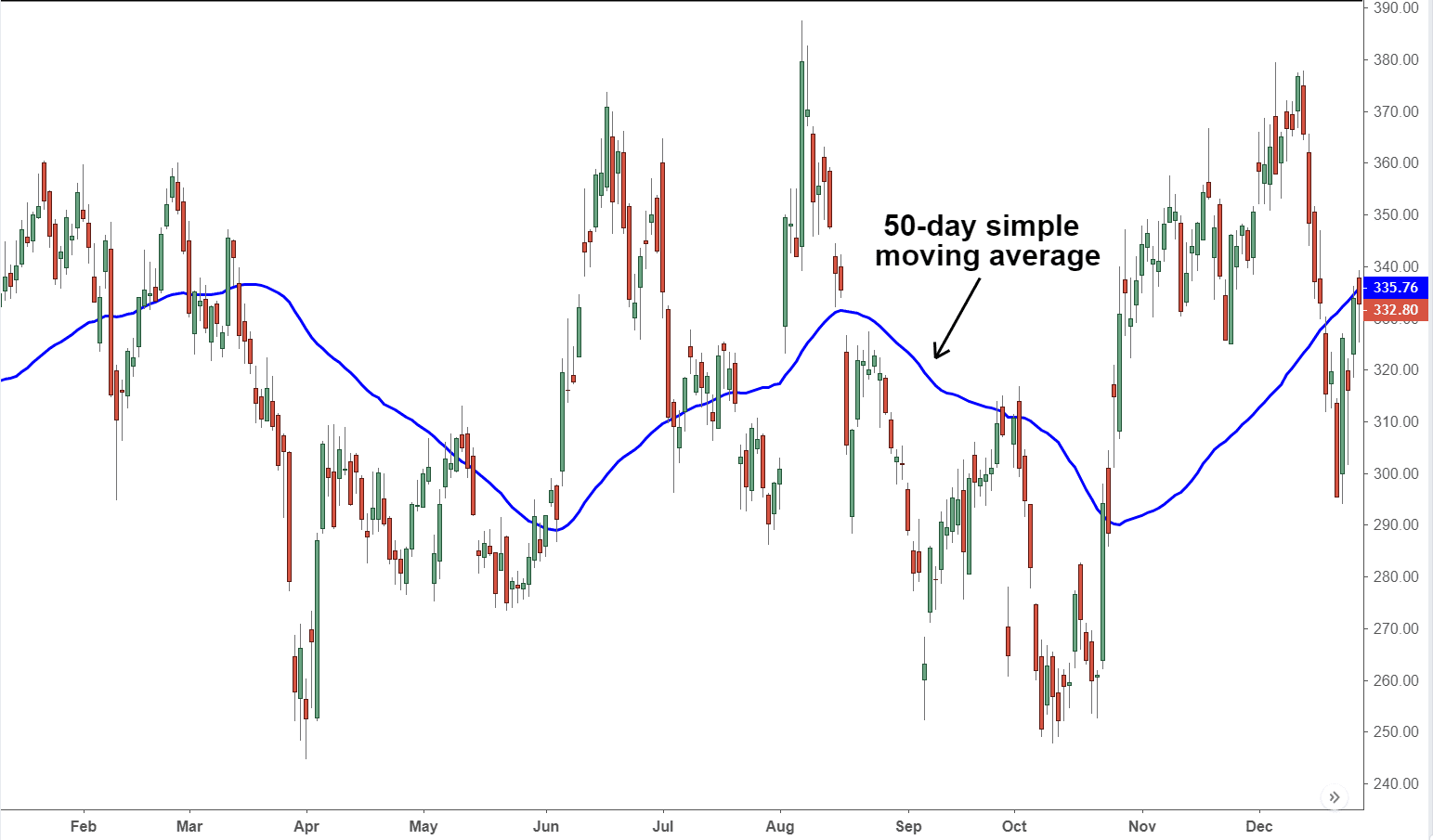
[이동평균 예시 출처 : https://www.investopedia.com/terms/s/sma.asp]
데이터의 잡음과 변동을 고려하였을 때, min/max 보다 이동평균이 추세를 나타내기에 적절합니다.
Model training : BQML을 사용하면 BigQuery에서 표준 SQL 쿼리를 사용하여 머신러닝 모델을 만들고 실행할 수 있습니다.
'auto_class_weights=TRUE' 옵션은 학습 데이터에서 클래스 라벨의 균형을 맞춥니다. 기본적으로 학습 데이터는 가중치가 더해지지 않습니다. 학습 데이터 라벨의 균형이 맞지 않는 경우 모델은 가장 인기 있는 라벨 클래스에 더 가중치를 둬서 예측하도록 학습할 수 있습니다.
센서 데이터의 이동 평균을 사용하고 BQML , AUTO_CLASS_WEIGHTS의 매개 변수를 사용하여 가중치의 균형을 맞추기 때문에 정확합니다.
Dataprep by Trifacta documentation
오답
A,B → DataPrep이 적절하지 않습니다.
C → 모델 학습이 불균형 데이터 세트에 대한 클래스 레이블의 균형을 맞추지 않기 때문에 C는 올바르지 않습니다.
7. You are an ML engineer at a media company. You need to build an ML model to analyze video content frame-by-frame, identify objects, and alert users if there is inappropriate content. Which Google Cloud products should you use to build this project?

- A. Pub/Sub, Cloud Function, Cloud Vision API
- B. Pub/Sub, Cloud IoT, Dataflow, Cloud Vision API, Cloud Logging
- C. Pub/Sub, Cloud Function, Video Intelligence API, Cloud Logging
- D. Pub/Sub, Cloud Function, AutoML Video Intelligence, Cloud Logging
정답
C. Pub / Sub, Cloud Function, Video Intelligence API, Cloud Logging
Video Intelligence API는 부적절한 구성 요소를 찾을 수 있고 기타 구성 요소는 실시간 처리 및 알림 요구 사항을 충족합니다.
오답
A → 경고 및 알림 기능이 없습니다.
B → 동영상에 적절하지 않습니다.
D → AutoML Video Intelligence는 맞춤 설정의 경우에만 사용해야합니다.
8. You work for a large retailer. You want to use ML to forecast future sales leveraging 10 years of historical sales data. The historical data is stored in Cloud Storage in Avro format. You want to rapidly experiment with all the available data. How should you build and train your model for the sales forecast?

- A. Load data into BigQuery and use the ARIMA model type on BigQuery ML.
- B. Convert the data into CSV format and create a regression model on AutoML Tables.
- C. Convert the data into TFRecords and create an RNN model on TensorFlow on AI Platform Notebooks.
- D. Convert and refactor the data into CSV format and use the built-in XGBoost algorithm on AI Platform Training.
정답
A. BigQuery에 데이터를 로드하고 BigQueryML에서 ARIMA모델 유형을 사용합니다.
BigQuery ML은 빠르고 신속한 실험을 위해 설계되었으며 통합 쿼리를 사용하여 Cloud Storage에서 직접 데이터를 읽을 수 있기 때문에 A가 정확합니다. ARIMA는 주식예측처럼 시계열 데이터를 예측할 때 사용되는 모델입니다.
오답
B → AutoML Tables은 빠른 반복 및 빠른 실험에 적합하지 않습니다. 데이터 처리나 하이퍼파라미터튜닝을 하지 않더라도 모델을 만드는 데에 최소 1시간이 소요됩니다.
C → custom TF 모델을 짜려면 데이터 처리와 하이퍼파라미터 튜닝이 필요하기 때문에 적절하지 않습니다.
D → AI Platform을 사용하려면 CSV 구조로 데이터를 사전 처리해야하는데, 시간이 오래 걸릴 수 있으므로 빠른 반복에 적합하지 않습니다.
9. You need to build an object detection model for a small startup company to identify if and where the company’s logo appears in an image. You were given a large repository of images, some with logos and some without. These images are not yet labelled. You need to label these pictures, and then train and deploy the model. What should you do?

- A. Use Google Cloud’s Data Labelling Service to label your data. Use AutoML Object Detection to train and deploy the model.
- B. Use Vision API to detect and identify logos in pictures and use it as a label. Use AI Platform to build and train a convolutional neural network.
- C. Create two folders: one where the logo appears and one where it doesn’t. Manually place images in each folder. Use AI Platform to build and train a convolutional neural network.
- D. Create two folders: one where the logo appears and one where it doesn’t. Manually place images in each folder. Use AI Platform to build and train a real time object detection model.
정답
A. Google Cloud의 데이터 라벨링 서비스를 사용하여 데이터에 라벨을 지정합니다. AutoML Object Detection을 사용하여 모델을 학습시키고 배포합니다.
AI Platform Data Labeling Service documentation
Could AutoML Vision Object Detection documentation
오답
B → Vision API는 소규모 스타트업 회사 로고에 작동되지 않을 수 있습니다.
C→ 수동으로 라벨링하는 작업은 시간이 오래걸립니다.
D→ object detection으로 라벨링하는 것은 정확하지 않습니다. 또한 real time object detection은 이미지보다 비디오에서 객체를 감지하도록 설계되었습니다.
10. You work for a large financial institution that is planning to use Dialogflow to create a chatbot for the company’s mobile app. You have reviewed old chat logs and tagged each conversation for intent based on each customer’s stated intention for contacting customer service. About 70% of customer inquiries are simple requests that are solved within 10 intents. The remaining 30% of inquiries require much longer and more complicated requests. Which intents should you automate first?

- A. Automate a blend of the shortest and longest intents to be representative of all intents.
- B. Automate the more complicated requests first because those require more of the agents’ time.
- C. Automate the 10 intents that cover 70% of the requests so that live agents can handle the more complicated requests.
- D. Automate intents in places where common words such as “payment” only appear once to avoid confusing the software.
정답 : C. 라이브 에이전트가 더 복잡한 요청을 처리할 수 있도록 요청의 70%를 처리하는 10개의 인텐트를 자동화합니다.
인텐트 : 어플리케이션 구성요소 간에 작업 수행을 위한 정보를 전달하는 역할
Diagoflow : Google의 챗봇 플랫폼
