Train(학습) 프로세스
- 모델 - batch size 단위로 추론
- 손실함수(Loss Function) - 모델이 추론한 것과 정답간의 Loss(손실-오차)의 평균
- 옵티마이저(Optimizer) - 파라미터들(weight) 업데이트
유닛/노드/뉴런 (Unit, Node, Neuron)
- 입력 Feature들을 입력받아 처리 후 출력하는 데이터 처리 모듈
- 입력 값에 Weight(가중치)를 곱하고 bias(편향)을 더한 결과를 Activation 함수에 넣어 최종 결과를 출력
레이어/층(Layer)
-
모델이 추론하기 위한 각 단계를 정의
-
실제 처리를 담당하는 Unit들을 모아놓은 구조
-
신경망의 구조와 기능을 정의하며, 데이터의 흐름과 변환을 담당
-
Input Layer(입력층)
- 신경망의 첫 번째 레이어, 외부에서 데이터를 받아들임
- 데이터의 특징이나 속성을 신경망에 전달하는 역할
-
Hidden Layer(은닉층)
- 입력 레이어와 출력 레이어 사이에 위치한 중간 레이어
- 입력 데이터를 받아들여 가중치와 활성화 함수를 적용한 후 출력을 계산
- 신경망의 성능과 복잡도는 은닉 레이어의 수와 각 은닉 레이어의 유닛 수에 따라 크게 영향받음
- 하이퍼파라미터
-
Output Layer(출력층)
- 신경망의 마지막 레이어, 최종 결과를 출력
- 회귀 문제 - 단일 유닛을 가진 출력 레이어가 사용
- 분류 문제 - 클래스 수에 따라 다중 유닛을 가진 출력 레이어가 사용
-
대부분 Layer들은 학습을 통해 최적화할 Paramter를 가짐
-
Layer들 연결한 것 = Network
-
다양한 Layer
- Fully Connected Layer (Dense layer)
- 추론 단계에서 주로 사용
- MLP(Multi Layer Perceptron), DNN(Deep Neural Network)
- Convolution Layer → 전처리, feature 추출
- 이미지 데이터
- CNN(Convolutional Neural Network), FCN(Fully Convolutional Network)
- Recurrent Layer → 전처리, feature 추출
- Sequential(순차) 데이터
- RNN(Recurrent Neural Network)
- Embedding Layer → 전처리, feature 추출
- Text 데이터
- Fully Connected Layer (Dense layer)
1. 모델 (Network)
- Layer를 연결한 것이 Deep learning 모델
- 적절한 network 구조(architecture)를 찾는 것은 공학적이기 보다는 경험적(Art)접근이 필요
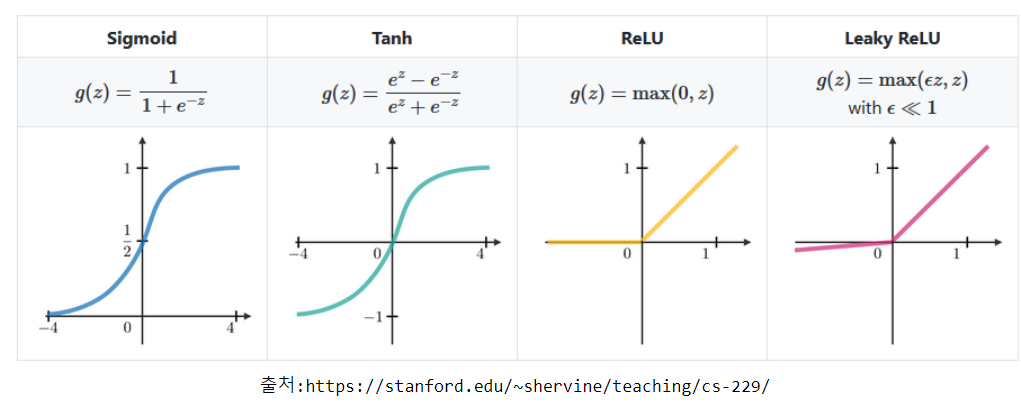
1.1 활성 함수 (Activation Function)
- 인공 신경망에서 레이어의 출력을 결정하는 비선형 함수
- 입력값에 대한 변환을 수행하여 신경망이 비선형 패턴을 학습하고 복잡한 관계를 모델링
- 뉴런의 출력값을 제어하고 다음 레이어로의 신호 전달을 결정하는 역할
-
Sigmoid (logistic function)
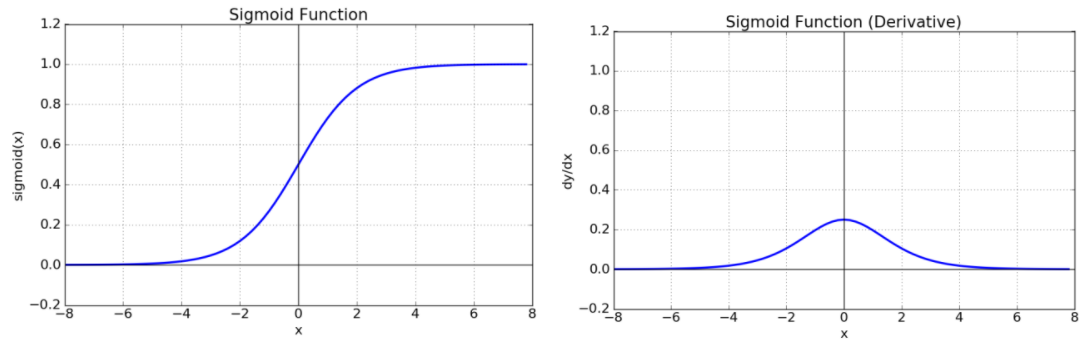
- 0<𝑠𝑖𝑔𝑚𝑜𝑖𝑑(𝑧)<1
- 층을 깊게 쌓을 경우 기울기 소실(Gradient Vanishing) 문제를 발생
- 기울기 소실 : 최적화 과정에서 gradient가 0이 되어서 Bottom Layer의 가중치들이 학습이 안되는 현상
- Binary classification(이진 분류)를 위한 네트워크의 Output layer(출력층)의 활성함수로 사용
-
Hyperbolic tangent
- 잘 사용하지 않음
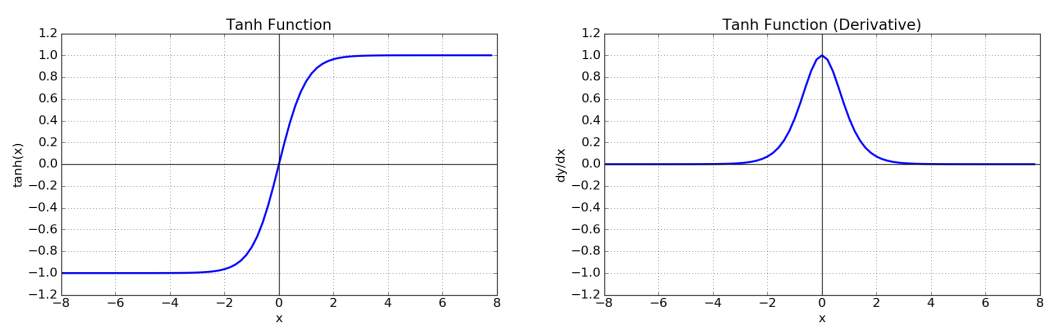
- −1<𝑡𝑎𝑛ℎ(𝑧)<1
- 잘 사용하지 않음
-
ReLU(Rectified Linear Unit)
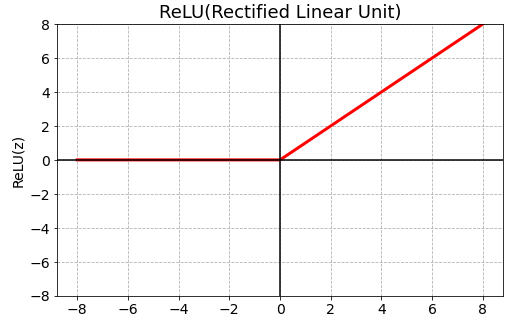
- 기울기 소실(Gradient Vanishing) 문제를 어느정도 해결
- 입력이 0보다 작을 경우 0을 출력하고, 0보다 큰 경우 입력 값을 그대로 출력
- 비선형 변환을 수행하면서도 계산적으로 효율적이어서 많은 신경망 모델에서 사용
- 입력 값이 음수인 경우 (z <= 0) , 학습이 제대로 이루어지지 않을 수 있음 = Dying ReLU
-
Leaky ReLU
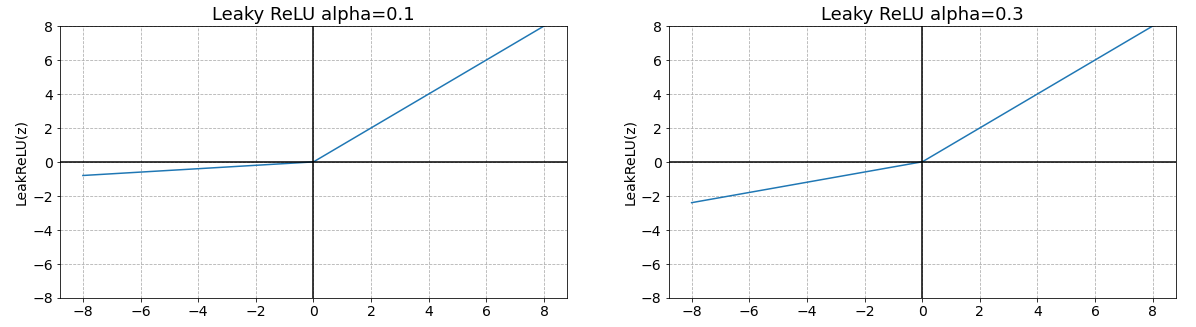
- ReLU의 Dying ReLU 현상을 해결
- 입력 값이 음수일 때 작은 기울기를 갖도록 함
- 음수 z를 0으로 반환하지 않고 alpah (0 ~ 1 사이 실수)를 곱해 반환
-
Softmax
- Multi-class classification(다중 분류)를 위한 네트워크의 Output layer(출력층)의 활성함수
- 은닉층의 활성함수로 사용X
- 출력노드들의 값은 0 ~ 1사이의 실수로 변환되고 그 값들의 총합은 1
1.2 Hidden Layer 에 (비선형) 활성함수 적용 여부에 따른 결과 확인
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(0)
def func(x):
return 3*x**2 + 2 + np.random.rand(*x.shape)*3
# randn() : 평균-0, 표준편차-1 (표준정규분포)를 따르는 난수 생성
X = np.random.randn(100, 1) # (데이터개수, 1)
y = func(X)
plt.scatter(X, y)
plt.show()
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layersactivation 함수를 사용하지 않은 모델
model1 = keras.Sequential() # 빈 모델 생성
# 모델에 layer들 추가
model1.add(layers.InputLayer(input_shape=(1, ))) # input layer - 입력데이터 shape
# Hidden
model1.add(layers.Dense(10))
# Output layer : 회귀 - 추론값이 1개이므로 unit을 1개로 지정
model1.add(layers.Dense(1))
# 모델 컴파일
model1.compile(optimizer='adam', loss='mse')
# 학습
model1.fit(X, y, epochs=200)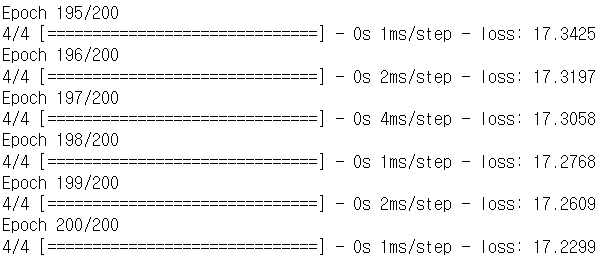
plt.plot(X_new, pred_y, color='r')
plt.show()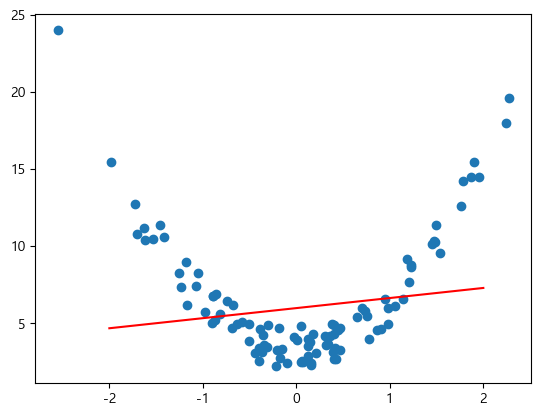
⇒ Underfitting 발생
activate 함수를 사용한 모델
model2 = keras.Sequential([
# 첫번째 layer에 input shape을 지정하면 Inputlayer을 추가하지 않아도 된다.
layers.Dense(10, input_shape=(1, )),
# 비선렬 활성함수
layers.ReLU(),
# 출력 layer
layers.Dense(1)
])
model2.compile(optimizer='adam', loss='mse')
model2.fit(X, y, epochs=200)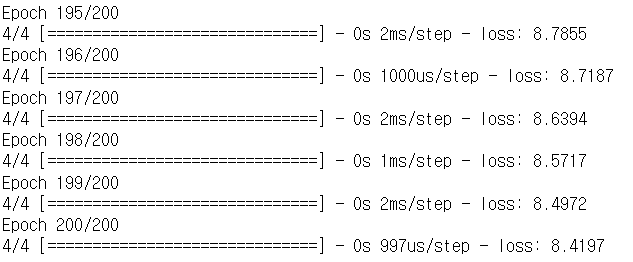
⇒ activate 함수를 사용하니까 오차가 줄었음
X_new = np.linspace(-2, 2, 1000).reshape(1000, 1)
pred_y = model2.predict(X_new)
plt.scatter(X, y)
plt.plot(X_new, pred_y, color='r')
plt.show()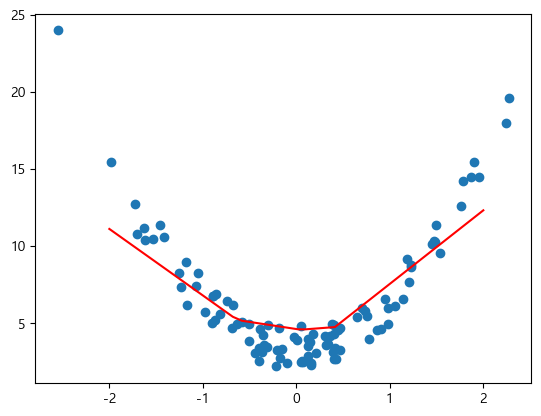
2. 손실함수(Loss function, 비용함수)
- Model이 출력한 예측값(prediction)과 실제 데이터(output)의 차이를 계산하는 함수
- Loss값(손실)이 최소화 되도록 파라미터(가중치와 편향)를 업데이트
- 해결하려는 문제의 종류에 따라 표준적인 Loss function 있음
2.1 Classification (분류)
- cross entropy (log loss) 사용
𝑙𝑜𝑔(모델이출력한정답에대한확률) - Binary classification (이진 분류)
- 모델이 양성(1)의 확률을 출력
- binary_crossentropy를 loss function으로 사용
- Multi-class classification (다중 클래스 분류)
- categorical_crossentropy를 loss function으로 사용
- Regression (회귀)
- 연속형 값을 예측
- Mean squared error를 loss function으로 사용
2.2 평가지표 (Metrics)
- 모델의 성능을 평가하는 지표
- 손실함수(Loss Function)와 차이
- 손실함수 - 모델을 학습할 때 가중치 업데이트를 위한 오차를 구할 때 사용
- 평가지표 - 모델의 성능이 확인하는데 사용
2.3 문제별 출력레이어 Activation 함수, Loss 함수 (*암기)
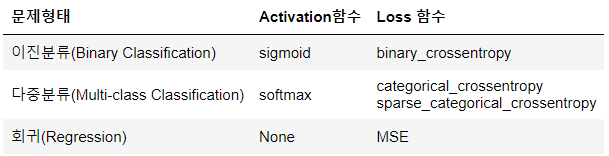
sparse_categorical_crossentropy: categorical_crossentropy를 계산하기 전에 y(정답)을 one hot encoding 처리한다
3. Optimizer (최적화 방법)
-
신경망의 가중치와 편향을 조정하여 손실 함수를 최소화하는 최적의 모델 파라미터(weight, bias)를 찾는 최적화 알고리즘
-
경사하강법(Gradient Descent)와 오차 역전파(back propagation) 알고리즘을 기반으로 파라미터들을 최적화
-
Gradient Decent (경사하강법)
- 최적화를 위해 파라미터들에 대한 Loss function의 Gradient값을 구해 Gradient의 반대 방향으로 일정크기 만큼 파라미터들을 업데이트
-
오차 역전파(Back Propagation)
- 파라미터를 최적화 할 때 추론한 역방향으로 loss를 전달하여 단계적으로 파라미터들을 업데이트
- Loss에서부터(뒤에서부터) 한계단씩 미분해 gradient 값을 구하고 이를 Chain rule(연쇄법칙)에 의해 곱해가면서 파라미터를 최적화
3.1 계산 그래프 (Computational Graph)
- 복잡한 계산 과정을 자료구조의 하나인 그래프로 표현한 것
- 그래프는 노드(Node)와 엣지(Edge)로 구성
- 노드 - 연산을 정의
- 엣지 - 데이터가 흘러가는 방향
- 계산 방향 : 순전파(Forward propagation), 역전파(Back propagation)
- 국소적 계산 : 자신과 관계된 정보(입력 값들)만 가지고 계산한 뒤 그 결과를 다음으로 출력
- 복잡한 계산을 단계적으로 나눠 처리 → 문제를 단순하게 만들어 계산
- 딥러닝에서 역전파를 이용해 각 가중치 업데이트를 위한 미분(기울기) 계산을 효율적
- 중간 계산결과를 보관
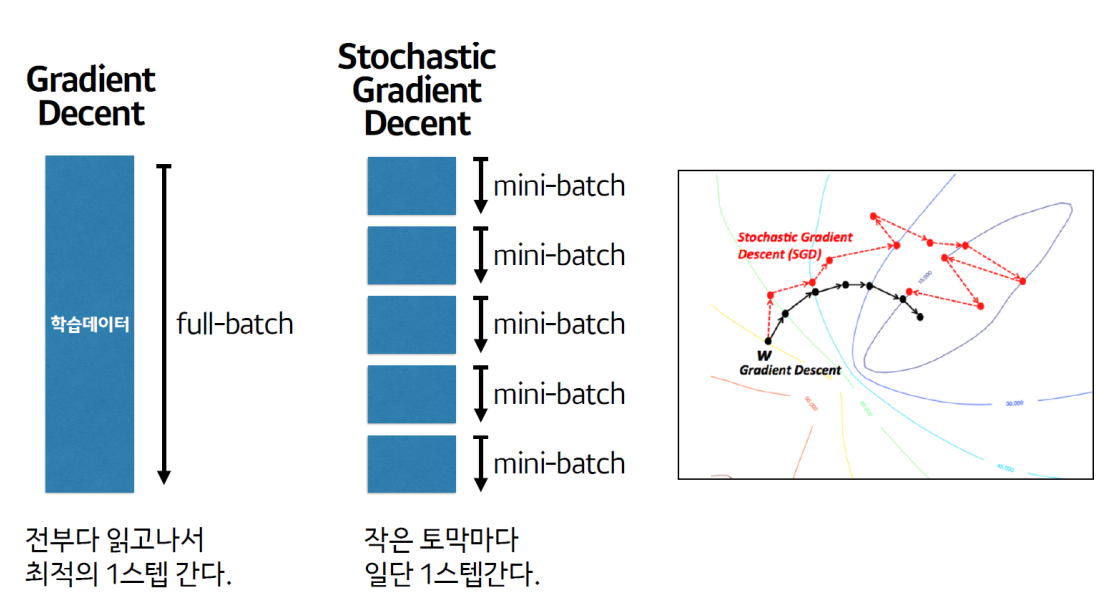
3.2 파라미터 업데이트 단위
-
1step의 data 단위
-
Batch Gradient Decent (배치 경사하강법)
- 1 step = 1 epoch
- 모든 학습 데이터를 한 번에 사용하여 가중치를 업데이트하는 방식
- 전체 학습 데이터셋에 대한 손실 함수의 그래디언트(기울기)를 계산하고, 이를 사용하여 가중치를 업데이트
- 장점 : 전체 데이터셋을 고려하여 업데이트하므로 안정적
- 단점 : 메모리 요구량 큼, 학습 속도가 느릴 가능성, 대규모 데이터셋에는 계산 비용이 큼
-
Mini Batch Stochastic Gradient Decent (미니배치 확률적 경사하강법)
-
1epoch당 1 step 수 = data 수 / batch 수
-
배치 경사하강법과 확률적 경사하강법의 장점을 결합한 옵티마이저
-
학습 데이터를 작은 미니배치(mini-batch)로 나누어 각 미니배치에 대한 손실 함수의 그래디언트를 계산하고, 이를 사용하여 가중치를 업데이트
-
미니배치의 크기는 일반적으로 2의 제곱수 ex) 32, 64, 128…
-
장점 : 계산 비용 줄임, 배치 경사하강법에 비해 빠른 학습 속도
*스텝(Step): 한번 파라미터를 업데이트하는 단위
-
-
SGD를 기반으로 한 주요 옵티마이저
- 방향성을 개선한 최적화 방법
- Momentum
- NAG(Nesterov Accelerated Gradient)
- 학습률을 개선한 최적화 방법
- Adagrad
- RMSProp
- 방향성 + 학습률 개선 최적화 방법
- Adam
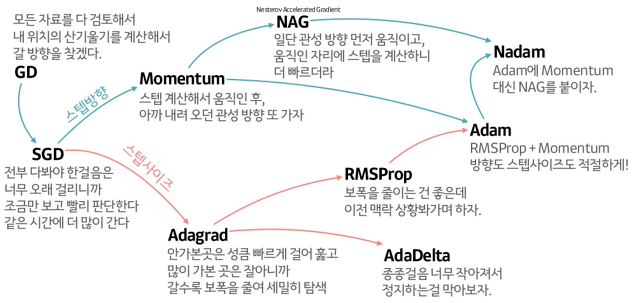
- Adam
- 방향성을 개선한 최적화 방법
