안녕하세요? 현재 캡스톤 디자인 프로젝트를 진행하며 공부하고 있는 Voice Conversion 모델에 대한 글을 써보려 합니다. 제가 진행하고 있는 프로젝트를 간략히 소개드리면, papago처럼 외국어 텍스트를 작성하면, 텍스트를 읽어주는 오디오를 생성해주는 프로젝트입니다.
다른 점은 표준 발음에 사용자 본인의 음색를 가진 음성으로 외국어 텍스트를 읽어준다는 점이죠. 여기에서 필요한 기술은 크게 3가지인데, 그중 하나가 바로 Voice Conversion 입니다.
Voice Conversion이란?
Voice Conversion에는 souce 화자와 target 화자, 이렇게 2명의 화자가 등장하는데요, 먼저 아래 그림을 보겠습니다.
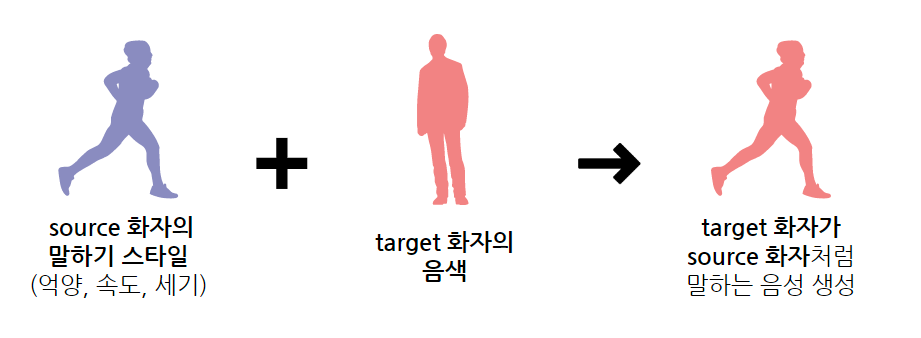
조금 이해가 되시나요? Voice Conversion은 source 화자의 음성 스타일(억양, 속도, 세기)에 target 화자의 목소리 음색을 입혀, 마치 target 화자가 source 화자처럼 말하는 음성을 생성하는 변환 기술을 말합니다. 이 기술은 저희 프로젝트에 필수적입니다. 저희는 표준 발음으로 말하는 사용자 목소리가 필요하니까요!
따라서 source 화자에 표준 발음으로 말하는 데이터셋을, target 화자에 사용자 본인의 목소리 데이터셋을 둔 다음 voice conversion 모델을 돌린다면 1차 목표를 달성할 수 있습니다🎉
MaskCycleGAN-VC 모델
Non-Parallel 모델
MaskCycleGAN-VC 모델은 non-parallel 모델입니다.
non-parallel의 의미는, 꼭 같은 텍스트를 말하는 source과 target의 오디오 쌍을 넣지 않아도 된다는 의미입니다.
S: I went to school today.
T: The weather is really nice!
따라서 non-parallel 모델에는 이렇게 Source와 Target이 아무 상관 없는 문장을 말해도, 문제없이 Voice Conversion을 수행해줍니다.
저희는 최종적으로는 사용자에게 본인의 목소리를 녹음받아야하기 때문에, non-parallel 모델의 사용이 필수적입니다. parallel 모델을 사용한다면 일대일 변환만 가능하기 때문에, 사용자 목소리로 현존하는 모든 문장을 읽어주는 데이터셋..이 필요하겠죠?
GAN 모델이란?
MaskCycleGAN-VC은 non-parallel 모델로 연구된 CycleGAN-VC2 모델의 성능을 향상시킨 모델입니다. 제가 연결해놓은 공식 사이트로 들어가시면, 각 모델별 데모 음성도 들어볼 수 있습니다.
일단 GAN 모델이기 때문에, Generator(생성모델)와 Discriminator(판별모델)라는 서로 다른 2개의 네트워크로 구성이 되어있습니다.
GAN 모델을 간단히 설명드리면, Generator는 실제 데이터셋에 가까운 가짜 데이터를 생성하고, Discriminator는 표본이 실제 데이터인지 가짜 데이터인지 판별합니다. 이 두 네트워크, Generator와 Discriminator에 경쟁을 붙여 서로 학습시키며 정확도를 높여가는 알고리즘입니다. Generator가 데이터를 생성하면, Discriminator는 생성한 데이터가 진짜인지 가짜인지 판별합니다.
Voice Conversion에서 사용하는 GAN 모델이라면, Generator는 Source 화자처럼 말하는 Target 화자의 음성을 생성하고, Discriminator는 실제 Target 화자의 목소리인지 아닌지 판별할 것입니다. 학습이 계속된다면 Generator는 Discriminator가 쉽게 판별할 수 없을 정도로 정확한 변환 음성을 생성할 수 있습니다.
MaskCycleGAN-VC
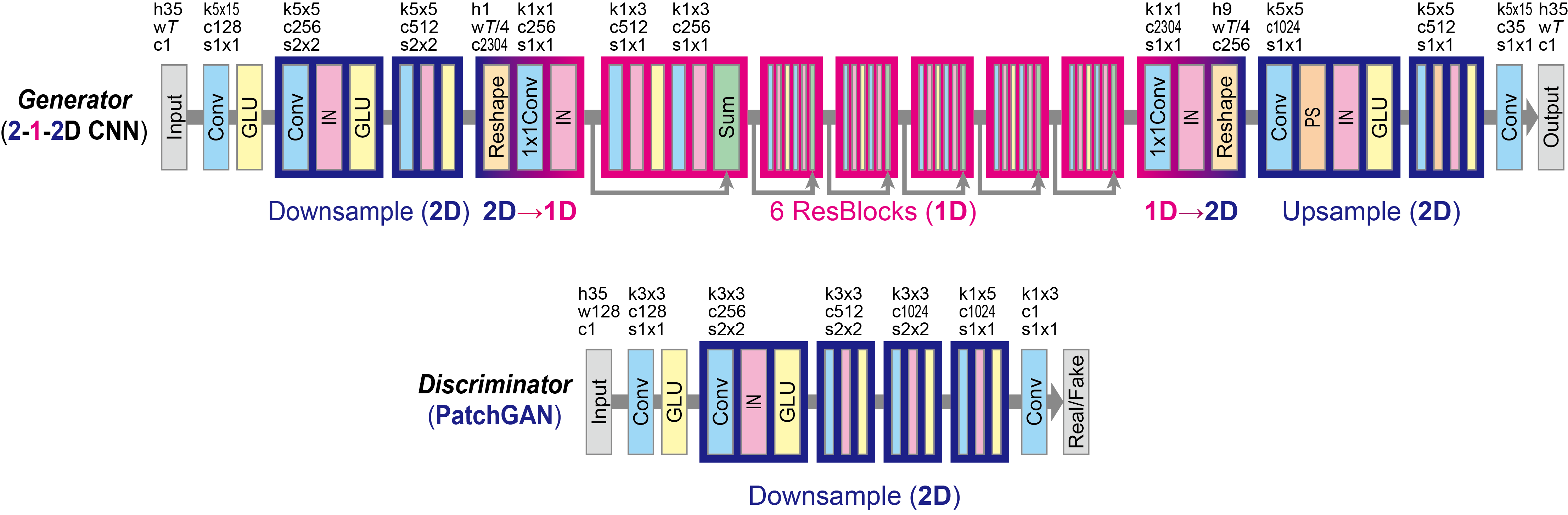
위의 사진은 공식 사이트에서 가져온 CycleGAN-VC2 모델의 구조인데요, 여기에 MaskCycleGAN-VC는 FIF(Filling in Frames) 기법을 추가하여 성능을 향상시켰다고 합니다.
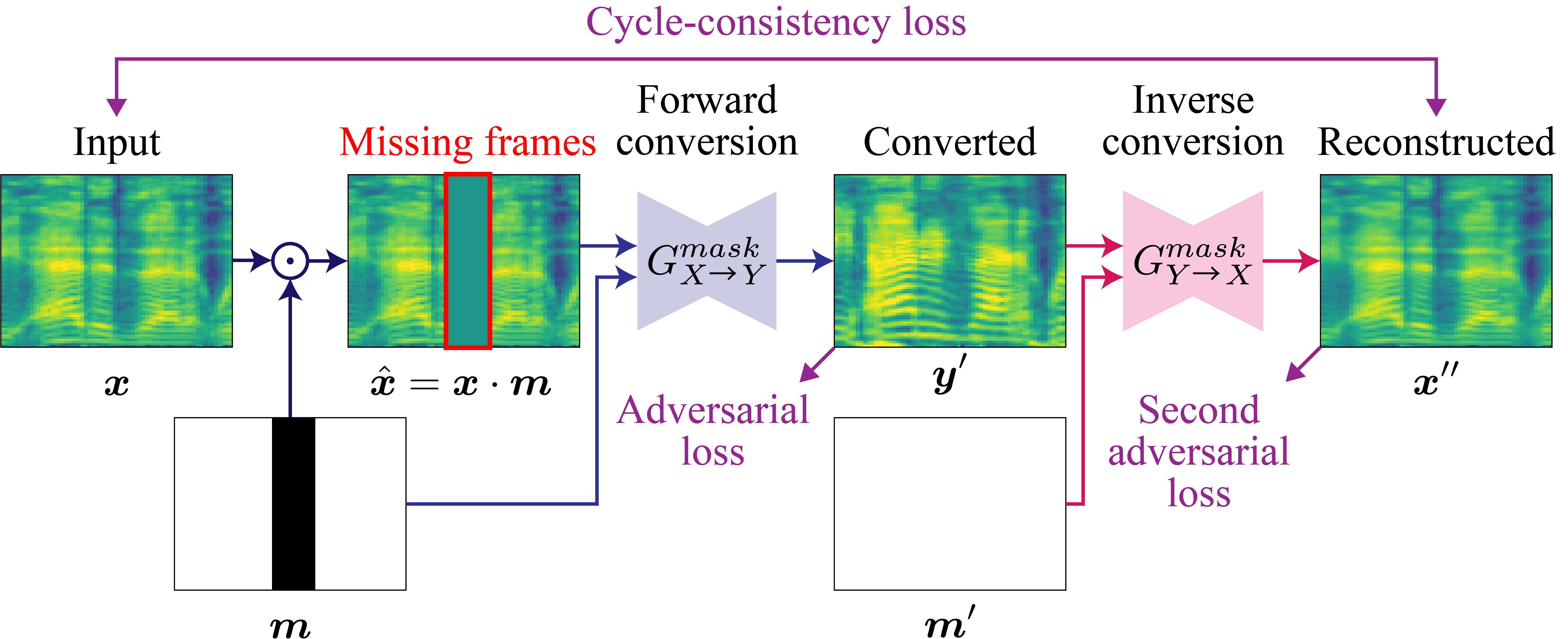
위의 사진이 바로 FIF(Filling in Frame) 기법인데요, 쉽게 설명하면 특정 시점의 오디오가 누락되었을 때 주변 시점의 오디오를 참고하여 채우는 방식입니다.
저희는 이 모델의 데모 음성이 가장 자연스러워, 이 모델을 선택하게 되었습니다.
MaskCycleGAN-VC 모델의 training
저희는 이 비공식 GITHUB의 코드를 참고하여 사용했는데요,
어떻게 사용하면 되는지 지금부터 설명해드리겠습니다.
Readme가 굉장히 자세히 적혀있는데요, 조금씩 틀린 부분이 있어 제가 tranining 시킨 방식을 덧붙여보겠습니다.
1. git clone한 다음, conda 가상환경으로 들어가기
먼저 git을 clone합니다.
git clone https://github.com/GANtastic3/MaskCycleGAN-VC이후 conda 가상환경으로 들어갈 건데요,
먼저 가상환경이 있는지 확인합니다.
conda env list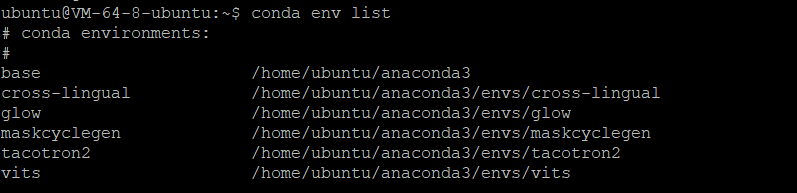
넵, 저는 maskcyclegen이라는 이름으로 MaskCycleGAN-VC 모델을 사용중이어서 가상환경이 이미 존재하는 것을 확인할 수 있습니다.
만약 가상환경이 없다면, 본인이 원하는 이름으로 가상환경을 만들어주시면 됩니다.
conda create -n 가상환경이름이후 conda 가상환경으로 들어가줍니다.
conda activate 가상환경이름이때 혹시 아래와 같은 오류가 발생하는 분이 계시다면,
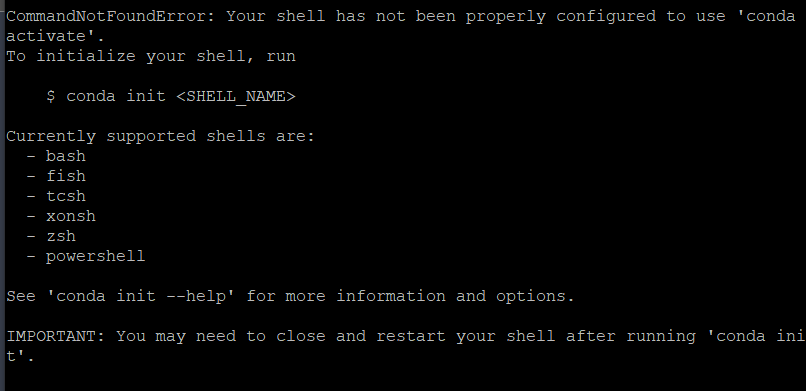
이 코드를 먼저 작성한 후, conda activate를 실행해주세요.
source ~/anaconda3/etc/profile.d/conda.shconda 가상환경에 들어갔다면, 앞에 (가상환경이름)이 붙은 걸 확인할 수 있습니다.

2. 모듈 설치하기
이 github에는 requirements.txt가 없어서, 에러를 만날 때마다 수동으로 계속 설치해줘야 하는데요... 제가 다 설치했기 때문에 requirements.txt를 만들었습니다.
requirements.txt Download
먼저, MaskCycleGAN-VC 파일로 들어가주세요.
cd MaskCycleGAN-VC이후 이 파일에 제가 업로드한 requirements.txt를 다운로드한 다음, requirements.txt 속 모듈들을 모두 설치해줍니다.
pip install -r requirements.txt3. 데이터셋 설치하기
여기 GitHub에서는 2년마다 열리는 VCC(Voice Conversion Challenge)라는 대회에서 2018년에 제공한 데이터셋을 사용합니다. 한명당 2초~4초 길이의 문장 80개를 읽은 데이터셋이고, 총 12명의 화자가 있습니다.
먼저 데이터셋을 MaskCycleGAN-VC 파일에 다운로드 해줍니다.
wget --no-check-certificate https://datashare.ed.ac.uk/bitstream/handle/10283/3061/vcc2018_database_training.zip?sequence=2&isAllowed=y
wget --no-check-certificate https://datashare.ed.ac.uk/bitstream/handle/10283/3061/vcc2018_database_evaluation.zip?sequence=3&isAllowed=y
wget --no-check-certificate https://datashare.ed.ac.uk/bitstream/handle/10283/3061/vcc2018_database_reference.zip?sequence=5&isAllowed=y이후 데이터셋의 압축을 풀어, vcc2018 파일에 저장합니다.
mkdir vcc2018
apt-get install unzip
unzip vcc2018_database_training.zip?sequence=2 -d vcc2018/
unzip vcc2018_database_evaluation.zip?sequence=3 -d vcc2018/
unzip vcc2018_database_reference.zip?sequence=5 -d vcc2018/
mv -v vcc2018/vcc2018_reference/* vcc2018/vcc2018_evaluation
rm -rf vcc2018/vcc2018_reference그러면 아래와 같이 vcc2018_training 폴더와 vcc2018_evaluation 폴더가 생성된 것을 확인할 수 있습니다.

미리 언급하자면, vcc2018_training 폴더에 담긴 데이터셋은 모델 training에 사용할 데이터셋이고, vcc2018_evaluation 폴더에 담긴 데이터셋은 모델 testing에 사용할 데이터셋입니다.
저는 제 목소리로 변환된 음성을 들어보고 싶어서, 제 목소리로 영어문장 80개를 녹음하여 Minjung 폴더에 담아 vcc2018_training 폴더에 넣었습니다. 이때 오디오 파일의 확장자는 wav여야 합니다!

Minjung 폴더가 같이 들어있는 것을 확인할 수 있죠?
이제부터 제 목소리를 target 화자로 하고, VCC2SF2를 source 화자로 해서 MaskCycleGAN-VC 모델을 training해보겠습니다.
아, source 화자인 VCC2SF2의 파일은 MinjungF2 폴더를 새로 생성하여 그대로 내부에 옮겼습니다.
제가 이번에 training할 화자를 정리하자면!
Source: MinjungF2 내부의 음성 화자 (->VCC2SF2)
Target: Minjung 내부의 음성 화자 (->me)
4. 데이터 전처리하기
이제는 음성 데이터를 음성 데이터를 기본 단위로 나눠보겠습니다.
멜-스펙트로그램이라는 음성 단위로 변환해주어야하는데요,
멜 스펙트로그램으로 나눠주는 코드는 바로 data_preprocessing 폴더 내부의 preprocess_vcc2018.py입니다.
아래의 코드는 MaskCycleGAN-VC 폴더에서 실행해주어야합니다.
제가.. 경로를 MaskCycleGAN-VC 폴더 기준으로 적어놨기 때문입니다.
data_directory 에는 training할 데이터셋이 위치한 폴더 경로를 적어주면 되고, preprocessed_data_directory에는 전처리가 끝난 데이터를 저장할 경로를 적어주면 됩니다.
speaker_ids에는 전처리를 해야하는 화자의 폴더명을 나열해주면 됩니다.
만약 저처럼 음성 데이터를 따로 녹음하신 분들이 계시다면, 이 부분에 폴더명을 추가해주세요!
python data_preprocessing/preprocess_vcc2018.py \
--data_directory vcc2018/vcc2018_training \
--preprocessed_data_directory vcc2018_preprocessed/vcc2018_training \
--speaker_ids Minjung MinjungF2 VCC2SF1 VCC2SF2 VCC2SF3 VCC2SF4 VCC2SM1 VCC2SM2 VCC2SM3 VCC2SM4 VCC2TF1 VCC2TF2 VCC2TM1 VCC2TM2마찬가지로, test에 사용할 음성 데이터셋도 전처리를 해주세요.
만약 test에 사용할 음성 80문장도 따로 녹음했다면, 아래와 같이 speaker_ids에 폴더명을 추가해주시면 됩니다.
python data_preprocessing/preprocess_vcc2018.py \
--data_directory vcc2018/vcc2018_evaluation \
--preprocessed_data_directory vcc2018_preprocessed/vcc2018_evaluation \
--speaker_ids Minjung MinjungF2 VCC2SF1 VCC2SF2 VCC2SF3 VCC2SF4 VCC2SM1 VCC2SM2 VCC2SM3 VCC2SM4 VCC2TF1 VCC2TF2 VCC2TM1 VCC2TM25. Training 시작
MaskCycleGAN-VC 폴더에서 아래의 코드를 입력해줍니다.
이때 주의할 점!
<source_speaker_id>에는 source 화자의 폴더명을,
<target_speaker_id>에는 target 화자의 폴더명을 적어야 합니다.
python -m mask_cyclegan_vc.train \
--name mask_cyclegan_vc_<source_speaker_id>_<target_speaker_id> \
--seed 0 \
--save_dir results/ \
--preprocessed_data_dir vcc2018_preprocessed/vcc2018_training/ \
--speaker_A_id <source_speaker_id> \
--speaker_B_id <target_speaker_id> \
--epochs_per_save 25 \
--epochs_per_plot 10 \
--num_epochs 6172 \
--batch_size 1 \
--decay_after 1e4 \
--sample_rate 22050 \
--num_frames 64 \
--max_mask_len 25 \
--gpu_ids 0 \따라서 저는 아래의 코드를 실행했습니다.
python -m mask_cyclegan_vc.train \
--name mask_cyclegan_vc_MinjungF2_Minjung \
--seed 0 \
--save_dir results/ \
--preprocessed_data_dir vcc2018_preprocessed/vcc2018_training/ \
--speaker_A_id MinjungF2 \
--speaker_B_id Minjung \
--epochs_per_save 25 \
--epochs_per_plot 10 \
--num_epochs 6172 \
--batch_size 1 \
--decay_after 1e4 \
--sample_rate 22050 \
--num_frames 64 \
--max_mask_len 25 \
--gpu_ids 0 \몇가지를 살펴보면, 일단 num_epochs는 총 돌려야하는 에포크 횟수입니다. 무려 6172번의 에포크를 권장하고 있습니다. 따라서 당연히 한번에 training을 끝낼 순 없습니다.
여기서 사용되는 것이 바로 checkpoint 파일(확장명: ckpt)인데요,
checkpoint를 사용하면 training을 중간에 끊더라도 기록이 저장되어 training을 이어서 할 수 있습니다.
이런 고마운 checkpoint는 epoch_per_save에 설정된 에포크 횟수마다 1번씩 저장되는데요, github에는 100번에 1번씩 저장하도록 설정했지만 저는 불안하여 25번에 1번씩 저장하도록 설정해두었습니다.
(불안한 이유: 만약 에포크가 99번까지 돌아간 상황에서 서버와의 연결이 끊어졌다면, 1부터 다시 돌려야합니다... 😢)
만약 저처럼 저장되는 에포크 횟수를 작게 설정하셨다면, checkpoint 파일의 크기가 상당하니 주기적으로 checkpoint 파일을 지우시길 권장드립니다! checkpoint 파일은 save_dir로 설정한 폴더 내부에 name로 설정한 폴더 속 ckpts 파일에 있습니다.
여기서는 results/mask_cyclegan_vc_MinjungF2_Minjung 폴더가 되겠네요!

만약 checkpoint 파일을 이용하여 이어서 training을 계속하고 싶다면,
--continue_train을 추가로 붙여주세요!
꼭 기존에 생성된 checkpoint 파일이 있을 때만 붙여주셔야 합니다.
python -m mask_cyclegan_vc.train \
--name mask_cyclegan_vc_MinjungF2_Minjung \
--seed 0 \
--save_dir results/ \
--preprocessed_data_dir vcc2018_preprocessed/vcc2018_training/ \
--speaker_A_id MinjungF2 \
--speaker_B_id Minjung \
--epochs_per_save 25 \
--epochs_per_plot 10 \
--num_epochs 6172 \
--batch_size 1 \
--decay_after 1e4 \
--sample_rate 22050 \
--num_frames 64 \
--max_mask_len 25 \
--gpu_ids 0 \
--continue_traintraining이 잘 되는 것을 확인할 수 있습니다.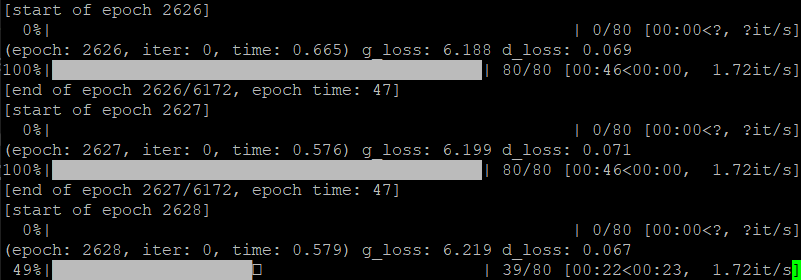
MaskCycleGAN-VC 모델의 testing
MaskCycleGAN-VC 폴더에서 아래의 코드를 실행해줍니다.
이때도 training할 때와 동일하게,
<source_speaker_id>에는 source 화자의 폴더명을,
<target_speaker_id>에는 target 화자의 폴더명을 적어야 합니다.
추가로 load_epoch에는 가장 최근에 저장된 checkpoint epoch 횟수를 적어주세요.
python -m mask_cyclegan_vc.test \
--name mask_cyclegan_vc_<source_speaker_id>_<target_speaker_id> \
--save_dir results/outputs/ \
--preprocessed_data_dir vcc2018_preprocessed/vvcc2018_evaluation \
--gpu_ids 0 \
--speaker_A_id <source_speaker_id> \
--speaker_B_id <target_speaker_id> \
--ckpt_dir /home/ubuntu/MaskCycleGAN-VC/results/mask_cyclegan_vc_MinjungF2_Minjung/ckpts \
--load_epoch <가장 최근에 저장된 checkpoint epoch 횟수> \
--model_name generator_A2B \아래의 사진을 확인하시면, 저는 글 작성 시점에 가장 최근에 저장된 checkpoint epoch 횟수가 2950인 것을 확인할 수 있습니다.
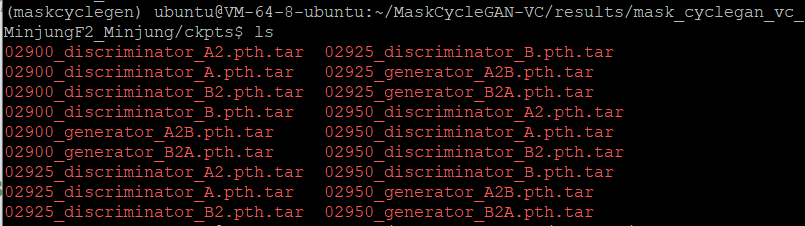
따라서 아래와 같이 작성해줍니다.
python -m mask_cyclegan_vc.test \
--name mask_cyclegan_vc_MinjungF2_Minjung \
--save_dir results/outputs/ \
--preprocessed_data_dir vcc2018_preprocessed/vcc2018_evaluation \
--gpu_ids 0 \
--speaker_A_id MinjungF2 \
--speaker_B_id Minjung \
--ckpt_dir /home/ubuntu/MaskCycleGAN-VC/results/mask_cyclegan_vc_MinjungF2_Minjung/ckpts \
--load_epoch 2950 \
--model_name generator_A2B \test 오디오가 잘 생성되는 것을 확인할 수 있습니다.
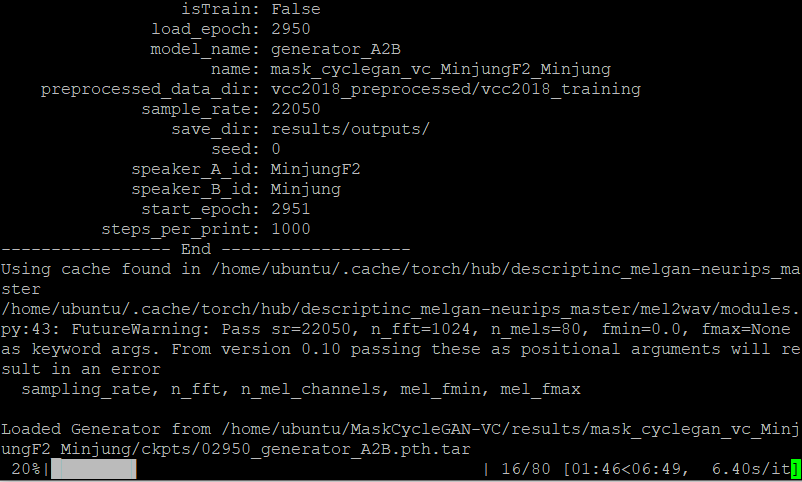
Test 오디오 들어보기
WinSCP
저는 클라우드의 ubuntu 서버에서 모델을 돌리다보니 서버에 저장된 오디오 파일을 로컬로 가져오지 못하여 고생을 했는데요, 로컬과 서버 사이에 간단한 drag and drop으로 파일 업로드와 다운로드가 가능한 툴이 있어 소개해드립니다. window를 사용하는 분들만 사용이 가능합니다.
위의 링크로 들어가서 다운로드해주신 다음, 본인이 개발에 사용하고 있는 서버에 로그인해주시면 됩니다.
test 오디오가 저장된 폴더 내부의 converted_audio 폴더를 선택한 다음, 마우스 우클릭으로 다운로드를 선택해주시면 로컬에 오디오가 저장됩니다.

다운로드가 잘 되는 것을 확인할 수 있습니다.
Test 오디오
에포크 6172번 중 2950번 돌린 모델에 통과시킨 오디오인데요,
6172번을 모두 돌리면 결과를 다시 업데이트하도록 하겠습니다.
먼저 target 화자, 즉 제 목소리입니다.
training에 사용한 아래의 목소리 녹음들을 통해서 target 화자의 목소리 음색을 먼저 파악해주세요.
Target 목소리 녹음 - 1
Target 목소리 녹음 - 2
Target 목소리 녹음 - 3
다음은 source 화자가 말하는 음성을 target 화자의 목소리로 변환한 오디오입니다. 변환된 오디오 링크를 클릭하면, source 화자처럼 말하는 target 화자의 목소리 결과물을 들을 수 있습니다.
- Source 목소리 -> 변환된 오디오
- Source 목소리 -> 변환된 오디오
- Source 목소리 -> 변환된 오디오
지금까지 Voice Conversion 모델의 원리와 실행 방법, 그리고 결과물을 살펴보았습니다. 권장 에포크 횟수의 절반밖에 돌리지 않았음에도 target 화자의 목소리와 상당히 유사한 결과물이 나온 것을 확인할 수 있었는데요, 에포크를 거듭할수록 결과물이 매끄럽게 변했기 때문에 최종 결과물이 어떻게 나올지 저도 많이 궁금하네요😋
다음에는 TTS(Text-to-Speech)와 Voice Conversion을 연결하는 방법에 대한 포스트로 만나겠습니다 :)

잘 읽었어요~ 좋아요.