초등학생 시절 담임선생님께서 일기장에 남겨주시던 코멘트 기억하시나요?
거기서 아이디어를 얻어 NLP를 적용한 일기장 달이 들어주는 오늘을 개발하게 되었습니다.
프로젝트를 간략히 소개하면, 사용자가 일기를 작성하면 AI가 일기에 대한 감상평을 남겨주고, 일기 내용을 기반으로 그림 일기를 그려주는 일기장 어플리케이션입니다.
오늘은 이 과정에서 학습한 자연어 처리 모델 이론에 대해 정리하려 합니다.
Keysentence Extraction
TextRank를 이용
TextRank 알고리즘은 그래프 기반의 랭킹 알고리즘인데요, TextRank를 이용하여 각 문장의 중요도를 결정했습니다. TextRank 알고리즘의 순서는 아래와 같습니다
1. Sentence Graph를 구축
node: 각 문장(index로 표현)
edge의 weight: 문장 간 유사도
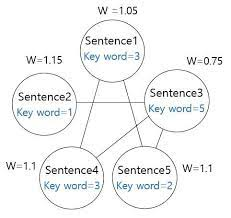
2. 두 문장 간의 유사도 측정
(두 문장에 공통으로 등장한 단어의 개수) ÷ (각 문장의 단어 개수의 log 값의 합)
유사도를 초기화한 다음, 유사도 값이 수렴할 때까지 알고리즘을 반복
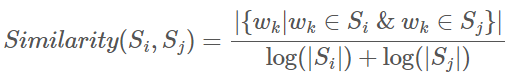
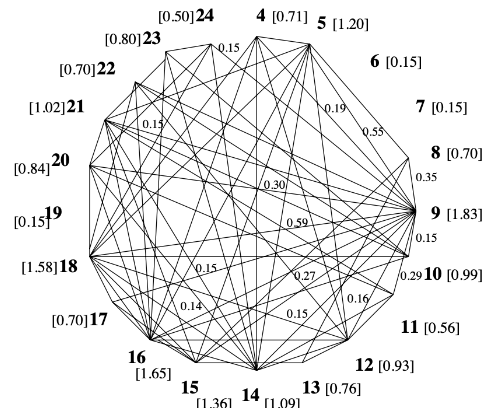
3. TextRank의 특징
문장 간 유사도를 측정하는 방법이 문장에 공통으로 등장한 단어의 개수를 각 문장의 단어 개수의 log값의 합을 나누어 구하므로, 문장의 길이가 길수록 높은 유사도를 가집니다. 따라서 TextRank는 핵심 문장으로 길이가 긴 문장을 선택하는 경향이 있습니다.
다음으로, 문장 사이의 유사도와 중요도 순위를 동시에 얻을 수 있습니다.
구현에는 lovit님의 textrank코드를 참고하였습니다.
4. 추가로 구현한 내용
문장의 위치에 따라 중요도를 다르게 설정하였는데요,
일반적으로 일기의 마지막에 하루가 정리된 문장이나 다짐이 담긴 문장을 작성하기 때문에, 마지막 문장이 다른 문장보다 5배 중요하다고 가정하였습니다.
numpy.ndarray 형태로 bias를 만든 다음, 이를 summarize 함수의 bias에 입력하면 맨 마지막 문장에 가중치가 부여되어 중요한 문장으로 선택될 확률이 높아집니다.
bias = np.ones(len(sents))
bias[-1] = 55. 구현 결과
input: 일기 글 문단
output: 핵심 문장 3개를 리스트 keysents에 저장


감상평 출력
1. KoGPT2 모델을 pretrained 모델로 사용
GPT 계열 모델은 다음 단어 맞히기로 업스트림 태스크를 수행한 언어 모델인데요, 문장 생성 과제에 주로 사용됩니다. 다음 단어 맞히기 과제란 "티끌 모아$MASK" 와 같이 뒷부분을 가려서 input을 생성한 후 모델에 통과시키면, "티끌 모아 태산"과 같이 뒷부분을 올바르게 채운 output을 생성하는 과제를 말합니다.
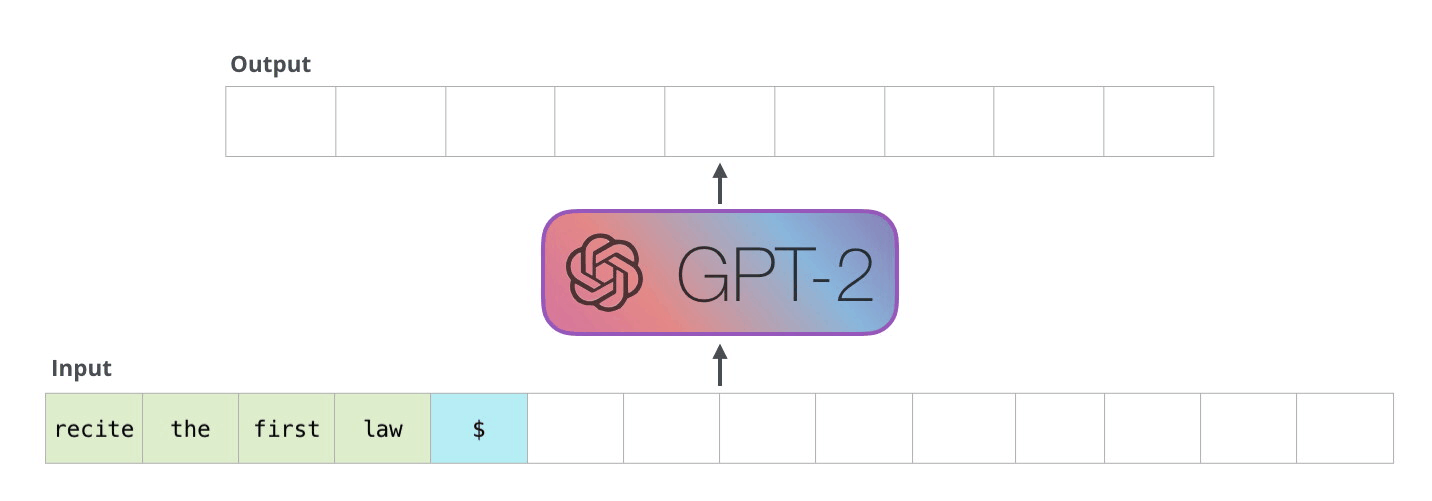
2. 파인튜닝 방식으로 학습
파인튜닝 방식이란 다운스트림 태스크 데이터 전체를 사용하여 학습하는 방식으로, 파인튜닝을 수행할 경우 다운스트림 데이터에 맞게 모델 전체를 업데이트합니다.
파인튜닝 학습에 사용한 dataset은 chatbot 개발에 주로 사용되는 dataset인 songys님의 dataset으로 선택하였습니다. 질문에 대한 적합한 답변이 정리된 dataset입니다. 일기의 핵심문장을 선택하면, 이를 input으로 모델에 통과시켜 감상평을 얻을 계획이므로, 핵심 문장을 질문으로, 감상평을 답변으로 생각하면 챗봇의 메커니즘과 유사하다고 판단하였습니다.
파인튜닝 방식으로 training할 수 있는 이유는 업스트림 태스크와 다운스트림 태스크가 동일한 과제를 수행하기 때문입니다. 질문에 대한 올바른 답변을 구하는 다운스트림 태스크는 질문$MASK ≫ 질문 $답변를 구하는 과제라고 볼 수 있으므로, 업스트림 태스크인 다음 단어 맞히기와 동일한 형태의 과제입니다. 따라서 pretrained 모델의 구조 변경 없이 다운스트림 데이터에 맞게 모델 전체를 업데이트하는 파인튜닝 방식을 이용할 수 있습니다.
3. 학습 알고리즘
먼저, dataset의 데이터를 전처리하여 다음 단어 맞히기와 동일한 task가 되도록 만들어줍니다. 전처리하는 순서는 아래와 같습니다.
a. 일기 핵심 문장을 토큰나이저로 토큰화
b. 토큰화한 일기 핵심 문장 앞뒤로 시작과 끝을 알려주는 특수 토큰을 붙임
c. 감상평 부분을 특수 토큰으로 채워 가림
다음으로, 전처리를 마친 데이터를 이용하여 파인튜닝을 진행합니다.
a. 전처리 과정을 거친 dataset을 이용하여 epoch 10회로 학습 진행
b. toach.argmax 함수를 이용하여 prediction 값이 가장 큰 값을 다음 문자로 선택한다.
이외에 일기장 코멘트에 맞게 추가로 구현한 알고리즘은 아래와 같습니다.
먼저, Chatbot dataset의 한계로, Chatbot 답변처럼 감상평을 출력하는 경우가 생겼습니다. Training한 모델을 테스트하는 과정에서 저도요! 혹은 좀 더 자세히 말씀해주시겠어요? 와 같은 문장을 감상평으로 출력하는 경우가 발생했습니다. 본질적으로는 Chatbot dataset의 답변 내용을 감상평에 맞게 수정해야했지만, 1만개 이상의 dataset을 모두 수정하는 것에는 무리가 있어 아래의 알고리즘을 통해 해결했습니다.
a. 1개가 아닌 3개의 핵심문장을 keysents 리스트에 저장하도록 keysentence extraction 알고리즘을 수정
b. 1순위 핵심문장부터 차례로 감상평 출력 모델에 통과시킴
c. 출력된 감상평의 길이가 8초과이고, 감상평에 "?"와 "저"가 들어가지 않으면 바로 감상평으로 채택
d. c의 조건을 만족하지 못할 경우, 다음 순위의 핵심문장을 모델에 통과시킴
e. 3개의 핵심 문장에 대한 감상평 모드가 c의 조건을 만족하지 못할 경우, 3개 중 길이가 가장 긴 감상평을 input 일기글에 대한 감상평으로 선택
구현 코드는 아래와 같습니다.
moon_comment = '' # 최종 선택된 감상평 문자열을 저장
max_comment = '' # 3개 중 길이가 가장 긴 감상평 문자열을 저장
comment = ''
for sent in keysents:
comment = model.comment(sent)
# 감상평이 마침표, 느낌표, 물음표로 끝나지 않는다면, 끝에 마침표를 붙임
if(comment[-1] is not '?' and (not '.' or not '!')):
comment = comment + '.'
# 길이가 가장 긴 감상평을 max_comment에 저장
if(len(max_comment)<=len(comment)):
max_comment = comment
# 감상평의 길이가 8 초과이고, 감상평에 물음표와 ‘저’가 들어가지 않으면 최종 감상평으로 선택
if(len(comment)>8 and '?' not in comment and '저' not in comment):
moon_comment = comment
break
# 3개의 핵심 문장에 대한 감상평 모두가 위의 조건을 만족하지 못할 경우
if(moon_comment is ''):
moon_comment = max_comment # 길이가 가장 긴 감상평을 최종 감상평으로 선택
print(moon_comment)4. 구현 결과
input: 핵심 문장 3개를 저장한 리스트 keysents
output: 감상평 한줄


그림일기 이미지 생성
일기 글에 대한 keyword를 추출한 다음, keyword를 영어로 번역하여 그림을 그리도록 설계하였습니다.
그림 일기 생성에는 Pixray라는 open source 프로그램을 이용하였는데요, pixray 프로그램은 영어 단어를 입력하면, 영어 단어에 맞는 이미지를 그려줍니다. 25번의 iteration동안 loss를 계속 줄여가며 최종 그림 이미지를 출력하는 원리로 작동합니다.
아래는 작동 결과입니다.
input: mountain_climbing
output:


안녕하세요, 혹시 일기 데이터셋은 어디에서 얻으셨는지 여쭈어도 괜찮을까요?