버블 정렬
이웃하는 원소끼리 비교 후 swap하며, 각 pass에서 가장 큰 수를 pass의 제일 뒷쪽으로 이동시키는 과정을 반복하여 정렬
for i=1 to n-1
for j=1 to n-i
if(A[i-1] > A[i])
SWAP(A[i-1], A[i])
return A선택 정렬
각 pass에서 가장 작은 수를 pass의 제일 첫 번째 원소와 swap하는 과정을 반복하여 정렬
for i=0 to n-2
min = i
for j=i+1 to n-1
if(A[min] > A[j])
min = j
SWAP(A[min], A[i])
return A선택 정렬은 입력의 정렬 여부와 상관없이 항상 일정한 시간 복잡도를 나타낸다.
입력에 민감하지 않은 (input insensitive) 알고리즘이며, 원소 간의 자리바꿈 횟수가 최소인 정렬이다.
삽입 정렬
배열을 정렬된 부분(앞부분)과 정렬 안 된 부분(뒷부분)으로 나누고, 정렬 안 된 부분의 가장 왼쪽 원소를 정렬된 부분의 적절한 위치에 삽입하는 과정을 반복하여 정렬
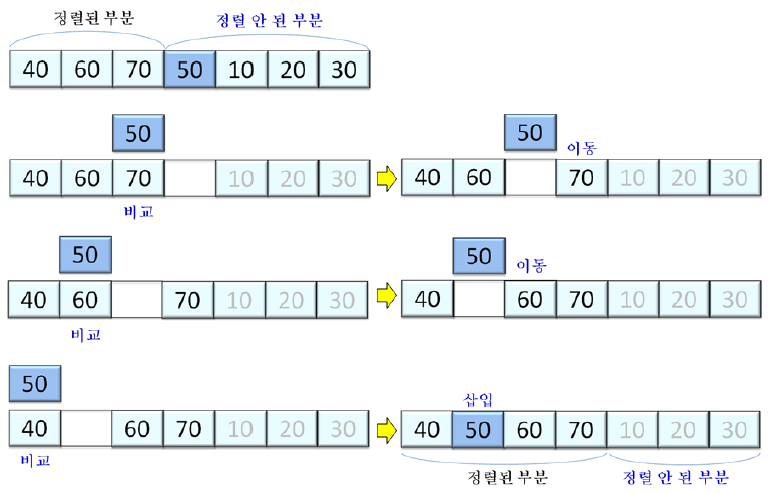
배열의 첫 번째 원소만이 정렬된 부분에 있는 상태에서 정렬을 시작한다.
for int i=1 to n-1
CurrentElement = A[i] // i: 정렬 안된 부분의 가장 왼쪽 원소의 인덱스
j = i-1
while(j>=0 and A[j] > CurrentElement){
A[j+1] = A[j]
j--;
}
A[j+1] = CurrentElement
return A쉘 정렬
간격(gap)을 이용하여 각 그룹별로 삽입정렬을 수행하는 과정을 간격(gap)이 1이 될 때까지 반복하여 정렬
- 삽입 정렬을 이용해서 배열 뒷부분의 작은 숫자들을 앞부분으로 빠르게 이동시키고, 앞부분의 큰 숫자는 뒷부분으로 빠르게 이동시킨다.
- 입력 크기가 매우 크지 않은 경우에 매우 좋은 성능을 보인다.
- gap=1인 쉘 정렬은 삽입 정렬과 완전히 동일하다. 쉘 정렬은 거의 정렬된 입력에 대해 좋은 성능을 보이는 삽입 정렬의 특징을 활용한 정렬이다.
- 정렬을 시작할 때 각 그룹에서 정렬된 부분에 있는 원소들은 배열의 0번 ~ gap-1번까지이다.
(0번: 첫 번째 그룹의 정렬된 부분에 존재, 1번: 두 번째 그룹의 정렬된 부분에 존재,...)
for each gap h=[h0> h1>...>1]
for i=h to n-1
CurrentElement = A[i] // i: 그룹에서 정렬 안된 부분의 가장 왼쪽 원소의 인덱스
j= i
while(j>=h and A[j-h]> CurrentElement)
A[j] = A[j-h]
j = j-h
A=[j] = CurrentElement
return A- 원소 간의 비교는 아래와 같은 순서로 진행된다.
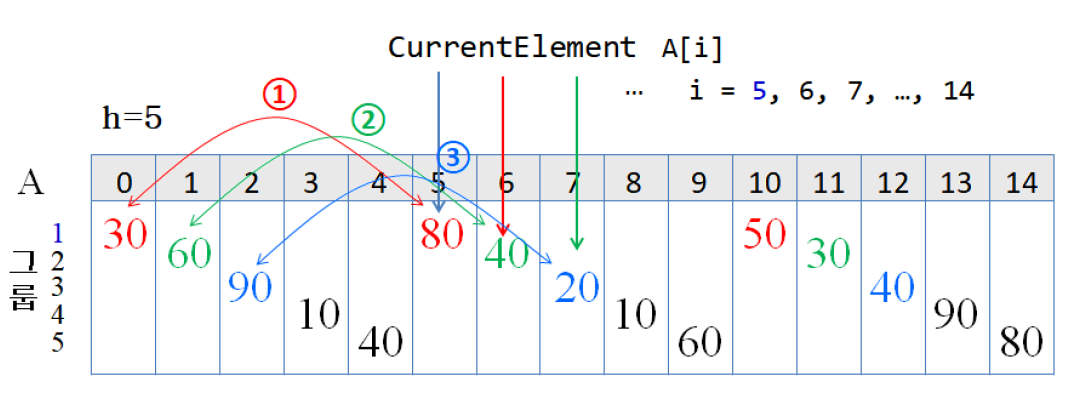
-
시간 복잡도
시간 복잡도는 사용하는 간격(gap)에 따라 분석해야 한다.
(1) 최악 경우 시간 복잡도: 히바드(Hibbard) 간격()
(2) 지금까지 알려진 가장 좋은 성능을 보인 간격: Marcin Ciura(1 4 10 23 57 132 301 701 1750) -
코드로 작성하면 아래와 같다.
배열 A의 원소를 쉘 정렬 기법으로 정렬하는 코드이다.
#include <stdio.h>
#define N 10
int main() {
int h, j, CurrentElement;
int A[N] = { 10,50,20,79,34,30,14,25,21,60 };
int gap[3] = { 5,2,1 };
for (int p = 0; p < 3; p++) { // gap의 크기를 줄이며 반복
h = gap[p];
for (int i = h; i < N; i++) {
CurrentElement = A[i]; // i: 각 그룹에서 정렬 안된 부분의 가장 왼쪽 인덱스
j = i;
while (j >= h && A[j - h] > CurrentElement) {
A[j] = A[j - h]; // 각 그룹별로 삽입 정렬 수행
j -= h;
}
A[j] = CurrentElement;
}
}
for (int i = 0; i < N; i++) {
printf("%d\t", A[i]);
}
}힙 정렬
정렬할 입력으로 최대 힙(Max heap)을 만들고, 루트와 힙의 가장 마지막 노드를 교환한 다음, 힙 크기를 1개 줄이는 과정을 반복하여 정렬
이진 힙(Binary Heap)이란, 힙 조건을 만족하는 완전 이진 트리 (Complete Binary Tree)를 말한다.
이 때 힙 조건 이란, 각 노드의 우선 순위가 자식 노드의 우선 순위보다 높은 조건을 말한다.
최대 힙(Maximum Heap)은 가장 큰 값이 루트에 저장된 힙을 말하고, 최소 힙(Minimum Heap)은 가장 작은 값이 루트에 저장된 힙을 말한다.
- 이진 힙은 완전 이진 트리이므로, 힙의 높이가 이며 노드들을 빈 공간 없이 배열에 저장한다.
- 힙 배열에서 A[i]의 부모는 A[i/2]이며, A[i]의 왼쪽 자식과 오른쪽 자식은 각각 A[2i], A[2i+1]이다.
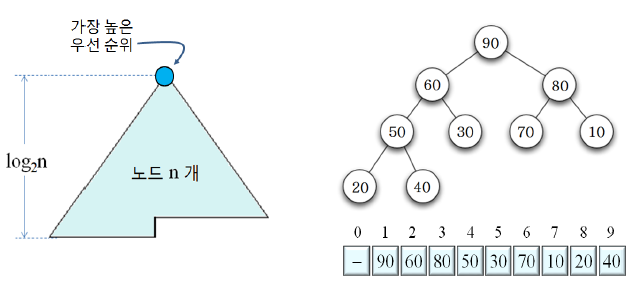
배열 A에 대해서 최대 힙을 만든다.
heapSize = n
for i=1 to n-1
SWAP(A[1], A[heapSize])
heapSize -=1
DownHeap() // 위배된 힙 조건을 만족시키는 함수
return ADownHeap()은 부모 노드가 자식 노드보다 작을 경우, 자식 노드와 부모노드를 교환하여 위배된 힙 조건을 만족시킨다.
큰 입력에 대해 DownHeap()을 수행하면 자식 노드를 찾아야 하므로, 너무 많은 캐시 미스로 인해 페이지 부재(page fault)를 야기한다.
힙 만드는데 O(n)시간, DownHeap은 O(logn)시간이 걸리므로, 시간 복잡도는 이다. 최선 / 최악 / 평균 시간 복잡도가 동일하다.
정렬 문제의 하한
어떤 문제에 대한 시간 복잡도의 하한(lower bound)라 함은, 어떠한 알고리즘도 문제의 하한보다 빠르게 해를 구할 수 없음을 의미한다. 이는 문제가 지닌 고유한 특성의 영향을 받으며, 문제의 하한은 어떤 특정 알고리즘에 대한 시간 복잡도의 하한을 뜻하는 것이 아니다.
- 최댓값을 찾는 문제의 하한
각 숫자를 적어도 한 번 비교해야하므로, 적어도 (n-1)번의 비교가 필요하다. - 정렬 문제의 하한
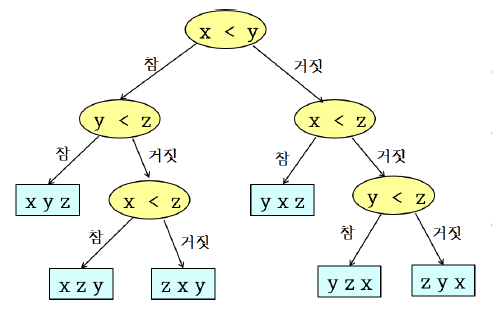
정렬에 필요한 모든 경우의 숫자 대 숫자 비교가 이뤄져야 한다.
아래는 정렬된 결과를 얻기 위해서 반드시 필요한 노드들이 정의된 결정 트리이다.
정렬 문제는 적어도 결정 트리 높이만큼의 비교가 필요하다.
결정 트리의 단말 노드는 개이므로, 결정 트리의 높이는 적어도 이다.
이므로, 비교 정렬의 하한은 이다. (∵ )
즉, 점근적 표기 방식으로 하한을 표기하면 이다.
기수 정렬(Radix sort)
제한적인 범위 내에 있는 숫자에 대해서 각 자릿수 별로 정렬
기수 정렬은 숫자 대 숫자로 비교가 이뤄지는 비교 정렬과 다르게, 숫자들을 한 자리씩 부분적으로 비교한다.
기수 정렬에서 기(radix)는 특정 진수를 나타내는 숫자들을 의미한다.
- 10진수의 기는 0, 1, 2, ..., 9
- 2진수의 기는 0, 1
아래는 입력에 대해 기수 정렬을 시행하는 과정을 보여준다.
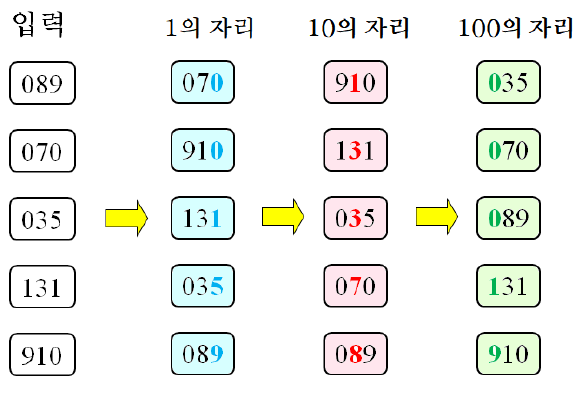
(1) LSD 기수 정렬
1의 자리부터 k자리로 기수 정렬을 진행하는 경우, Least Significant Digit(LSD) 기수 정렬 혹은 RL(Right-to-Left) 기수 정렬이라고 부른다.
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define N 10 // 기의 개수 (ex. 10진수 -> N=10)
#define M 20 // 입력 배열의 크기
#define D 3 // 입력의 최대 자리수 (ex. 100 -> D=3)
/* Queue 구조체 */
typedef struct {
int data[M];
int front, rear; // front 다음칸부터 데이터가 삽입됨
}QueueType;
void init(QueueType* Q) {
Q->front = Q->rear = 0;
}
int isEmpty(QueueType* Q) {
return Q->front == Q->rear;
}
int isFull(QueueType* Q) {
return (Q->rear + 1) % M == Q->front;
}
void enqueue(QueueType* Q, int item) {
if (isFull(Q))
printf("Full\n");
else {
Q->rear = (Q->rear + 1) % M; // rear를 옆으로 한칸 옮김
Q->data[Q->rear] = item;
}
}
int dequeue(QueueType* Q) {
if (isEmpty(Q))
printf("Empty\n");
else {
Q->front = (Q->front + 1) % M;
return Q->data[Q->front];
}
}
void createArray(int * list) {
for (int i = 0; i < M; i++) {
list[i] = rand() % 999 + 1; // 1~999 사이의 난수로 배열 생성
}
}
void printArray(int* list) {
for (int i = 0; i < M; i++) {
printf("%d\t", list[i]);
}
printf("\n");
}
/* 기수 정렬 */
void radixSort(int* list) {
int i, b, d, factor = 1;
QueueType Q[N]; // N개의 Queue를 생성 (N: 기의 개수)
for (b = 0; b < N; b++) {
init(&Q[b]); // Queue 초기화
}
for (d = 0; d < D; d++) { // D는 배열 원소의 자릿수를 의미. D=3이므로, 일의자리->십의자리->백의자리 순서로 기수 정렬 시행
for (i = 0; i < M; i++) { // 각 자릿수의 숫자가 k이면 Q[k]에 삽입
enqueue(&Q[(list[i] / factor) % 10], list[i]);
}
for (b = i = 0; b < N; b++) {
while (!isEmpty(&Q[b])) // d번째 자리수가 0,1,2,...,9인 수들의 순서로 list에 저장됨
list[i++] = dequeue(&Q[b]);
}
factor *= 10; // 자리수를 1 증가 (ex. 일의자리 -> 십의자리)
}
}
int main() {
srand(time(NULL));
int A[M];
createArray(A);
printArray(A);
radixSort(A);
printArray(A);
}(2) MSD 기수 정렬
k자리부터 1의 자리로 기수 정렬을 진행하는 경우, Most Significant Digit(MSD) 기수 정렬 혹은 LR(Left-to-Right) 기수 정렬이라고 부른다.
입력의 최대 자릿수를 k, 입력의 개수를 n, 분류하는 그룹의 개수를 r (ex. 10진수 -> r=10)이라고 하면
루프 1회당 시간이 소요된다.
따라서 시간 복잡도는 이고, k<<n, r<<n이면, 시간 복잡도는 이다.
외부 정렬
입력을 주기억 장치에 수용할 만큼의 데이터에 대해서만 내부 정렬을 수행하고, 그 결과를 보조 기억 장치에 일단 다시 저장한다.
이후, 정렬된 블록들을 반복적인 합병을 통해서 하나의 정렬된 거대한 블록으로 만든다.
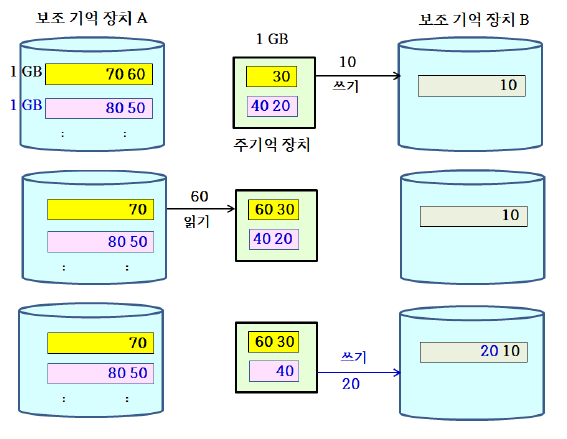
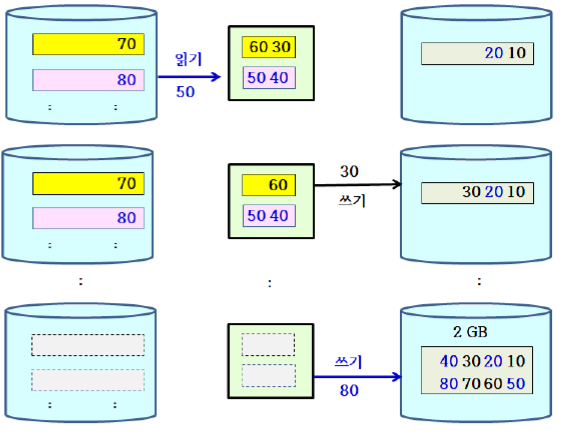
외부 정렬에서는 보조 기억 장치에서의 읽고 쓰기를 최소화하는 것이 매우 중요하다.
외부 정렬 알고리즘의 의사 코드는 아래와 같다.
M = 주기억 장치의 용량
외부 정렬 알고리즘은 입력이 저장된 보조 기억 장치 외에 별도의 보조 기억 장치를 사용. 이러한 보조 기억 장치를 편의상 HDD라고 부르겠다.입력: 입력 데이터가 저장된 입력 HDD
출력: 정렬된 데이터가 저장된 출력 HDD
- 입력 HDD에 저장된 입력을 M만큼씩 주기억 장치에 읽어 들인 후, 내부 정렬 알고리즘으로 정렬하여 별도의 HDD에 저장한다. 다음 단계에서 별도의 HDD는 입력 HDD로 사용되고, 입력 HDD는 출력 HDD로 사용된다.
- while (입력 HDD에 저장된 블록 수 >1){
- 입력 HDD에 저장된 블록을 2개씩 선택하여, 각각의 블록으로부터 데이터를 부분적으로 주기억 장치에 읽어들여서 합병을 수행한다. 이때 합병된 결과는 출력 HDD에 저장한다. 단, 입력 HDD에 저장된 블록 수가 홀수일 때에는 마지막 블록은 그대로 출력 HDD에 저장한다.
- 입력과 출력 HDD의 역할을 바꾼다.
}- return 출력 HDD
예시로 128GB 입력과 1GB 주기억 장치에 대한 외부 정렬 수행 과정을 살펴보면,
- 1GB의 정렬된 128개를 별도의 HDD에 저장
- 2GB의 정렬된 블록 64개가 출력 HDD에 만들어짐
- 4GB의 정렬된 블록 32개가 출력 HDD에 만들어짐
...- 128GB의 정렬된 블록 1개가 출력 HDD에 만들어짐
- 출력 HDD를 리턴
입력 크기가 N이고, 메모리 크기가 M이고,
마지막에 만들어진 1개의 블록 크기가 M이라면,
k는 while 루프가 수행된 횟수이고,
이므로,
k = 이다.
따라서 시간 복잡도는 이다.
