
안녕하세요. 밍기뉴와제제입니다. 요즘 이미지 생성기법에 관심이 생겼습니다. 그래서 데이터 생성 기법의 근본이라 할 수 있는 Generative Adversarial Nets, GAN을 읽어봤습니다.
GAN은 adversarial process를 통해 생성 모델을 만드는 framework입니다. 두 모델이 가지는 '적대적' 관계를 이용한 것이죠. GAN은 적대적 관계를 가진 두 모델이 경쟁을 하며 서로 발전하는 것을 구현해 높은 성능의 생성 모델을 만들어냈습니다.
그러면 지금부터 GAN 리뷰를 시작하도록 하겠습니다.
Introduction
Deep learning은 다양한 곳(natural images, audio waveforms containing speech, and symbols in natural language corpora)에서 좋은 성능의 모델을 만들게 해줬습니다. 논문에서는 이를 '풍부하고 체계적인 모델을 발견'하게 해줬다고 말했습니다.
이 중, 가장 눈여겨볼 부분은 discriminative model 입니다. 많은 정보가 담긴 입력 데이터의 클래스 라벨을 매핑하는 모델을 말하죠. 예를 들면 컴퓨터 비전의 Classification을 생각하시면 되겠습니다. 이런 분별 모델은 역전파와 드랍 아웃을 기반으로 높은 성능을 낼 수 있었습니다.
허나 Deep generative model은 제어하기 힘든 수많은 probabilistic computations(최대 확률 추정 등의 분야에서 사용됨)을 추론하는 것에 대한 어려움, 생성 모델에서 부분적 선형 유닛의 이점을 이용하는 것의 어려움으로 인해 좋은 성능을 내지 못했습니다. 즉, discriminative model을 만들 때와는 다른 방식으로 접근할 필요가 있는 것이죠.
그래서 저자는 앞서 말한 어려움을 피해간 생성 모델의 새로운 측정 과정을 제안했습니다. 바로 adversarial nets framework입니다.
adversarial nets framework?
adversarial nets framework은 generative model, discriminative model을 모두 사용합니다. 각 모델이 수행하는 역할은 다음과 같습니다.
- generative model : 분별모델을 상대로 완벽한 속임수를 수행
- discriminative model : 실제 데이터와 생성 모델이 만들어낸 데이터를 구별
저자는 generative model을 화폐 위조자(counterfeiters), discriminative model은 경찰에 비유하였습니다. 각 모델이 수행하는 역할과 이들이 적대적 관계를 가지고 있다는 걸 쉽게 이해할 수 있는 비유라 생각됩니다.
두 모델이 경쟁하면서 피드백을 받다보면 서로의 실력이 계속 향상될 것입니다. 경쟁은 실력을 상승시키니까요. 이 경쟁은 generative model가 실제 데이터와 구별하기 힘들 정도로 모방 데이터를 잘만들 때까지 계속됩니다.
generative model은 랜덤 노이즈를 multilayer perceptron에 넣어 모방 데이터를 만들고 discriminative model은 multilayer perceptron에 데이터를 넣어 모방 데이터인지 진짜 데이터인지 구분합니다.
저자는 이 둘을 합쳐 adversarial nets라고 말했고 이들을 역전파, 드랍 아웃 알고리즘만 사용해 모델을 학습시키고 순전파(forward propagation)만으로도 모방 데이터를 만들 수 있으며 inference, Markov chains를 사용할 필요가 없다고 말했습니다. 이 부분을 왜 강조한건지는 잘 모르겠습니다.
Adversarial nets
이제 adversarial modeling framework에 대해 설명해 드리도록 하겠습니다.
D, G, 그리고 value function V
adversarial modeling framework는 여러개의 딥러닝 모델들을 학습시킬 때 가장 간단하게 적용할 수 있는 방식입니다. 입력 데이터 X에 대한 generator의 분포 p_g를 학습하기 전에 input noise 변수 p_z(x)를 정의하고 p_z(x)를 data space에 매핑하는 G(z;θ_g)를 정의해야 한다고 합니다.
논문에서는 represent라고 말했지만 읽어본 결과 '정의한다'는 말이 좋겠다 싶어 정의한다고 적었습니다.
여기서 G는 θ_g로 이루어진 multilayer perceptron입니다. 즉, 딥러닝 모델 G를 정의해야 한다고 말하는 것이죠.
그리고 또다른 multilayer perceptron D(x;θ_d)도 정의합니다. D는 입력 데이터 x가 p_g가 아니고 진짜 데이터 분포일 확률을 single scalar로 나타내는 함수입니다.
데이터 분포 : 데이터에 포함될 수 있는 모든 값(혹은 구간)을 나타내는 함수나 리스트입니다. 출처
여기까지 p_g를 출력하는 G(generative model)와 p_g가 아닌 실제 데이터를 구분하는 D(discriminative model)를 정의하는 과정이었습니다.
G, D를 정의했으면 이제 학습을 시켜야 합니다. 두 모델은 동시에 훈련시키며 각 모델의 학습 목표는 다음과 같습니다.
- D : 학습 데이터셋과 G에서 만든 데이터에 correct label을 할당할 확률을 최대값으로 만드는 것
- G : D가 correct label을 제대로 할당할 수 없을 정도로 학습 데이터셋과 유사한 데이터를 만드는 것. 논문에서는 이를 "log(1-D(G(z)))를 최소값으로 만들려는 것(log 1 = 0)"이라 말했습니다.
논문에서는 학습방식을 D와 G의 minimax game with value function V (G, D)라고 말했습니다. 식으로 나타내면 다음과 같습니다.
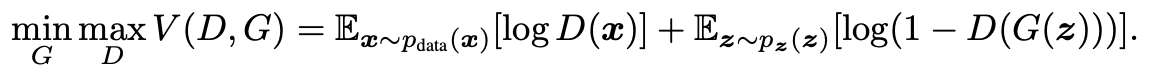
앞서 설명드렸듯 log(D(x))는 D 최대, log(1-D(G(z)))는 G가 최소값으로 만드려는 대상입니다.
Theoretical analysis of adversarial nets
이제 이론적으로 분석을 해봅시다. Theoretical analysis는 Training criterion이 데이터의 생성 분포를 G로 복구하고 D가 non-parametric limit에서 충분한 기능을 가지게끔 한다는걸 보여줍니다. 쉽게 말해 학습 과정을 보여주겠다는 말이죠.
Training criterion는 'Benchmark agreed upon by assessing a training programs success' 라고 합니다.(출처)
무슨 뜻일까 곰곰히 생각해봤는데 이전에 코드를 보며 공부할 때 Loss함수를 담은 변수명으로 criterion이라고 사용하는 경우를 봤습니다. 여기에 논문에 나온 설명도 같이 고려해보면 Training criterion이 Loss Function을 말하는게 아닌가 하는 생각이 듭니다.
non-parametric limit를 검색해보니 non-parametric이 Distribution-Free라는 의미를 가진다는 걸 알았습니다.(출처) 그래서 저는 Training criterion이 D가 어떤 값을 받아도 데이터가 진짜 데이터인지 모방해서 만든 데이터인지 구분할 수 있게끔 만들어주는 역할을 한다고 이해했습니다.
학습 과정을 그림으로 표현하면 다음과 같습니다.
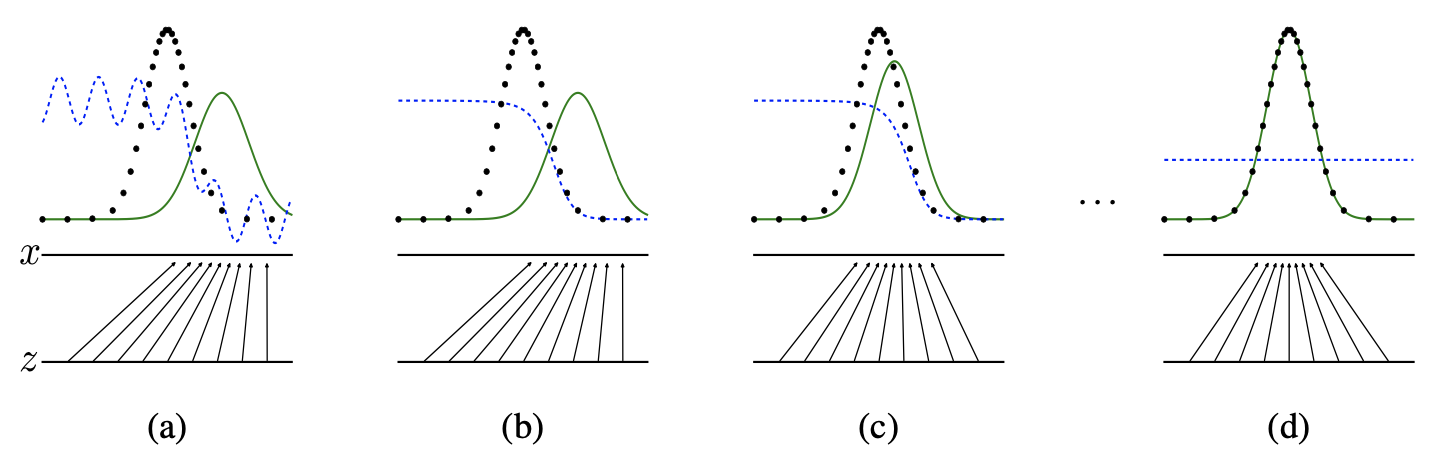
여기서 파란색 점선 : discriminative distribution(데이터 구분), 검은색 점선 : data generating distribution p_x(실제 데이터), 녹색 실선 : generative distribution p_g(생성한 데이터)입니다.
그리고 밑에 수평선 z는 z가 샘플되는 영역(domain)을 나타냅니다. 여기서는 균일하게 샘플되게끔 설정했습니다. 그리고 수평선 x는 x의 영역 중 일부를 나타냈고 z->x로 향하는 화살표들은 mapping x = G(z)가 non-uniform한 분포 p_g를 transformed samples로 향하게 하는걸 나타냅니다. G는 p_g의 high density에서 줄어들고 low density에서 늘어난다고 하는데 정확히 어떤 뜻인지 제대로 이해하지 못했습니다.
a, b, c, d를 하나씩 설명하면 다음과 같습니다.
- a : 학습이 안된 상태입니다. p_g가 p_data와 형태가 비슷하고 discriminative distribution이 부분적으로 정확한 classifier인 상태입니다.
- b : D가 D*(x) = p_data(x)/((p_data(x) + p_g(x))로 수렴하여 실제 데이터와 생성된 데이터를 구분할 수 있게 학습시킵니다.
- c : G를 학습시킵니다. 이 때 D의 그래디언트는 G(z)가 실제 데이터와 같은 데이터로 분류하게끔 안내해줍니다.
- d : G와 D가 충분한 능력을 가질 때까지 a~c를 여러번 반복합니다. G는 p_g = p_data라고 할정도로 데이터를 잘 생성해냅니다. D는 두 데이터의 차이를 구분할 수 없습니다. 즉, D(x) = 0.5입니다.
저자는 G, D의 학습 방식(game이라고 표기합니다)을 iterative, numerical한 접근법이라 말했습니다. 학습 과정의 inner loop에서 D를 완성시키기 위해 최적화 하는 것은 계산적으로 불가능하고 학습을 위한 데이터셋이 유한하기에 overfitting에 빠질 확률이 높습니다. D의 가중치를 계속 업데이트하는건 하지 않겠다는 거죠.
그래서, 우리는
- D를 k번 학습
- G를 한 번 학습
하는 과정을 반복합니다. 이렇게 학습 시키면 최적의 solution에 가까운 D, G가 만들어집니다. 이를 알기 쉽게 다음과 같이 '알고리즘 1'로 정리해 표시했습니다.

저자는 k=1로 했습니다. D, G를 번갈아가며 한 번씩 가중치를 업데이트 했던 것입니다.
Theoretical Results
G는 p_g를 G(z)의 분포로 정의했습니다. 그래서 위에 있는 알고리즘 1이 G(z)를 p_data에 수렴하게 만들어주길 원했습니다.
저자는 'Theoretical Results'의 결과가 non-parametric setting에서 수행된다고 말했습니다. 다시말해 확률밀도함수(probability density functions, pdf)에 수렴하는걸 학습함으로써 무한한 능력을 가진 모델을 표현할거라고 말했습니다.
Theoretical Results는 'Global Optimality of p_g = p_data'에서 minimax game이 p_g = p_data의 global optimum을 가지고 있는걸 보여주고 'Convergence of Algorithm 1'에서 알고리즘 1이 value function V (G, D)를 최적화시켜 원하는 결과를 얻는 과정을 보여줄 것입니다.
Global Optimality of p_g = p_data
우선 G가 어떤 상태건 최적의 상태인 discriminator D가 있다고 해봅시다.
Proposition는 명제, Proof는 증명이라고 해석할까 했지만 그냥 영어를 쓰기로 했습니다.
Proposition 1
증명을 하기 전에 D를 나타내는 식을 세워야합니다. 고정된 G가 있을 때, 최적의 discriminator D를
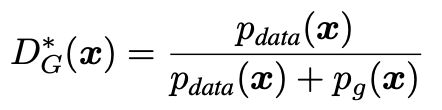
위와 같다고 세워보죠. 이제 Global Optimality of p_g = p_data를 증명해 보도록 하겠습니다.
Proof
어떠한 G가 있을 때, discriminator D의 training criterion은 V(G, D)를 최대값으로 만드는 겁니다. 여기서 V(G, D)는
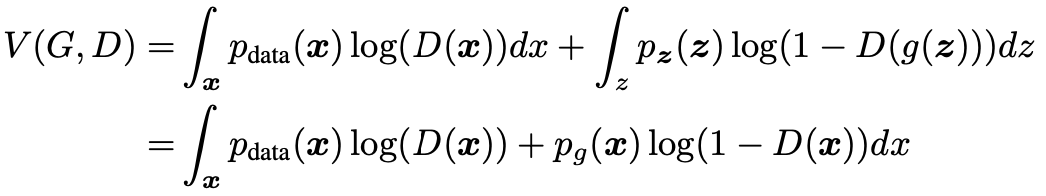
위와 같습니다. 이 식이 최대값을 가지려면 어떤 조건을 만족해야 할까요?
간단한 식으로 조건을 찾아봅시다. (0,0)이 아닌 (a, b) ∈ R^2가 있을 때 y → alog(y) + blog(1 − y)가 최대값을 가지려면 어떻게 하면 되는지 알게되면 V(G, D)가 최대값을 가질 조건을 알 수 있습니다. 이는 미분을 통해 구할 수 있습니다. 미분한 값이 0이 되는 시점의 y를 알면 되는 것이죠.
그러면 미분을 해봅시다. 미분을 하면 a/y - b/(1-y)가 되고 a/y - b/(1-y) = 0이라는 식을 세우고 y에 대해 정리를 하면 y = a/(a + b)가 됩니다.
이를 V(G, D)의 값을 보며 a, b를 바꿔봅시다. a = p_data(x), b = p_g(x)가 되네요. 그려면 p_data(x)/(p_data(x) + p_g(x))가 됩니다.
어라?
앞서 proposition에서 세운 최적의 D와 같네요. 그러니 우리가 세운 최적의 D는 올바른 식이라는 걸 알 수 있습니다.
p_data, p_g는 0~1 사이에 있는 값입니다. 그래서 0~1이 아닌 경우는 고려하지 않기에 논문에서도 값의 범위를 [0, 1]로 정해놨습니다.
여기서 눈여겨볼 부분은 D를 학습시키는 목적은 조건부 확률 P(Y=y|x)의 log-확률(log-likelihood)을 최대화하기 위함으로 해석할 수 있다는 것입니다. 여기서 Y는 입력 데이터 x가 진짜 데이터(p_data)에서 온건지(y=1) 아니면 모방해서 만든 데이터(p_g)에서 온건지(y = 0) 나타내는 변수입니다.
그러니 minimax game
은 다음과 같은 global minimum of the virtual training criterion C(G)로 식을 다시 쓸수 있습니다.
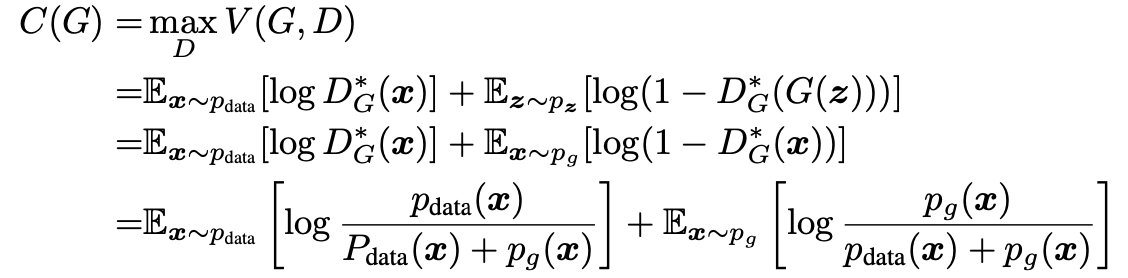
C(G)가 global minimum을 가지려면 p_data(x) = p_g(x)를 만족해야합니다. 만약 이를 만족할 시, -log(4)라는 global minimum를 얻을 수 있습니다.
식을 세웠으니 이를 증명해야겠습니다.
Proof
p_data(x) = p_g(x)면 p_data(x)/(p_data(x) + p_g(x)) = 0.5가 됩니다. 그러면
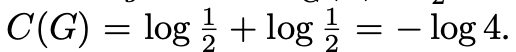
가 되겠습니다. E는 기대값을 나타내는건데 log(0.5)의 기대값은 log(0.5)로 같기 때문에 여전히 -log(4)가 되겠습니다.
그리고 이 부분부터 제가 완벽히 이해하지 못했는데, C (G) = V (D*_G , G)에서 -log(4)가 나오는 부분을 빼면
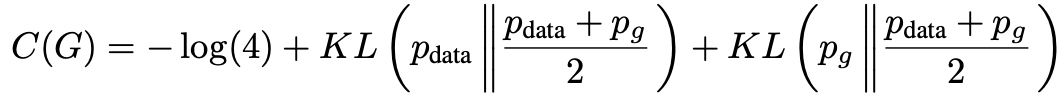
이런 식을 얻는다고 합니다. 여기서 KL은 쿨백-라이블러 발산입니다. 저도 처음보는 겁니다. 두 확률분포의 차이를 계산할 때 사용하느 것이라고 하네요.
KL을 이용해 표현한 C(G)는 모델의 분포와 데이터 셍성 과정 사이의 Jensen–Shannon divergence을 가지고도 표현할 수 있습니다.
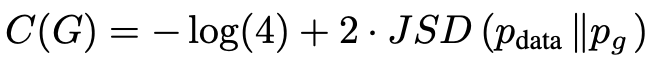
여기서 두 분포 사이의 Jensen–Shannon divergence는 non-negative하고 두 분포가 같다면 0이 나오기 때문에 C∗ = − log(4)가 C(G)의 global minimum이라는 것, 그리고 -log(4)를 얻을 수 있는 유일한 조건은 p_g = p_data라는걸 보여줬습니다.
즉, generative model G가 실제 데이터 분포를 완벽히 복제해야 virtual training criterion C(G)의 global minimum을 얻을 수 있는 것이죠.
Convergence of Algorithm 1
여기서는 알고리즘 1이 value function V (G, D)를 최적화시켜 원하는 결과를 얻는 과정을 보여준다고 앞써 말씀드렸습니다.
이를 보여주기 위해 Proposition을 추가로 세워야 하는데요, 다음과 같습니다.
Proposition 2
G, D가 충분한 능력을 갖고 있고 알고리즘 1의 각 단계에 있을 때, discriminator D는 G가 최적의 상태에 다다르게 만들어주고 p_g는 다음의 criterion을 향상시키는 방향으로 업데이트되어 p_data로 수렴한다.
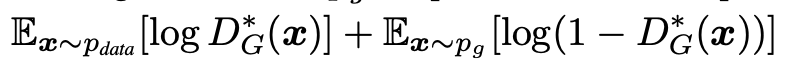
앞서 말씀드린 알고리즘 1이 G, D를 원하는 성능까지 성장시키는 걸 수학적으로 나타냈습니다. 이제 이를 증명해봅시다.
Proof
Proposition 2에서 언급한 criterion에 있는 p_g의 함수인 V(G, D) = U(p_g, D)를 고려해봅시다.
우리는 U(pg, D)는 p_g에 있는 볼록한 부분(convex)이라는 걸 눈여겨 봐야합니다. 볼록 함수의 상한을 하위미분한 것은 최대값을 얻을 수 있는 점에서 함수를 미분한게 포함되어 있는데요, 수학적으로는 'f(x) = supα∈A fα(x) 와 fα(x)가 모든 α에 대해 x에서 convex일 때, β = argsupα∈A f_α(x)인 조건 아래 ∂fβ(x) ∈ ∂f 이다'로 표현할 수 있습니다.
하위미분 : 미분을 일반화하여 미분이 불가능한 볼록 함수를 미분하는데 사용하는 방법입니다.
이를 좀더 알기 쉽게 나타내면 "corresponding한 G가 있을 때 최적의 D에서의 p_g를 만드는데 사용될 gradient를 계산하는게 U(p_g, D)에 들어있다"고 보시면 되겠습니다.
supD U(pg,D)는 C(G)를 증명할 때 증명되었듯 균일한 global optima를 가진 p_g에 있는 convex입니다. 그러니 p_g를 조금씩, 그러나 충분할 정도로 업데이트 하다보면 p_g는 p_x에 수렴하게 됩니다. 이렇게 증명이 끝납니다.
수학적으로 증명하니까 어우...쉽지 않습니다. 더 많은 공부가 필요합니다.
이론적으로는 이렇게 완벽한 D, G를 만들 수 있지만 실제로 만들려고 할 때는 그렇지 않습니다. adversarial nets은 G(z; θ_g)를 통해 제한된 값의 집합인 p_g 분포를 나타내게 된다고 하네요.
그래서 p_g대신 G의 parameter인 θ_g를 최적화 했다고 합니다. p_g를 수렴시킨다는 걸로 증명한게 적용되지 않은거죠. 그러나, 최적화된 θ_g를 가진 G는 실전에서 완벽한 성능을 자랑합니다. GAN이 이론적으로 보장된게 부족한데도 불구하고 사용할 수 있는 reasonable model을 제공한 것입니다.
Experiments
이제 성능을 테스트한 결과를 확인해봅시다. 저자는 G, D를 MNIST, TFD(Toronto Face Database), CIFAR-10에서 학습시키고 테스트해봤습니다.
G는 활성화 함수로 ReLU, 시그모이드 함수를 혼합한걸 사용하고 D는 maxout을 활성화 함수로 사용했습니다. G는 noise를 입력 데이터로 받아 데이터를 생성합니다.
p_g에 있는 test set data들의 확률은 G로 생성된 데이터들에 Gaussian Parzen window을 맞추는 방식으로 측정하며 측정된 확률은 p_g에 속한 log 확률로 변환합니다. 여기서 말하는 확률은 진짜 데이터인지, 생성된 데이터인지 구분하는 확률이 아닌가 싶습니다. 이 때 Gaussian의 표준편차 σ는 검증 데이터셋의 교차 검증을 통해 값을 정합니다.
이 과정은 실제 확률을 다루기 힘든 generative 모델들을 평가할 때 사용하는 방식이라고 하네요.
평가 결과는 다음과 같습니다. Parzen window 기반의 log 확률을 측정한 값들입니다.
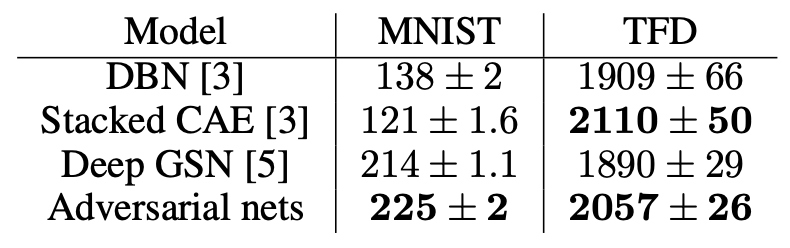
위 방식을 사용해 확률을 측정하는건 분산이 조금 크고 이미지 등의 고차원 데이터에서 좋은 효과를 내지 못하지만 저자의 지식으로 사용가능한 방식 중에서는 가장 좋은 방식이었다고 합니다.
저자는 sample은 가능하지만 직접적으로 확률을 측정할 수 없는 generative model은 평가 방식을 더욱 연구할 수 있게 동기부여를 해준다는 이점이 있다고 하는데 음...긍정적인 사람이구나 싶었습니다.
다음의 사진들은 학습을 완료한 generative model에서 생성한 데이터들을 일부 가져온 것들입니다.

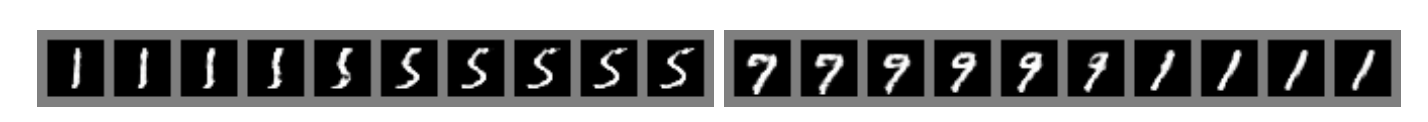
정말 잘 만들어냈습니다. 이런 사진들을 통해 generative model의 가능성이 어떤지 확인할 수 있습니다.
Advantages and disadvantages
adversarial nets framework는 이전에 존재하던 것들과 비교했을 때 장점과 단점을 모두 가지고 있습니다.
단점은 '생성된 데이터의 분포 p_g(x)을 확실하게 표현하는 것이 없다는 것'과 '학습할 때 D는 G와 잘 동기화 되어야한다(synchronized well)는 것'입니다. 여기서 동기화를 잘해야 한다는 것은 G가 D의 학습 없이 너무 많이 학습 되어선 안된다는 뜻입니다. 만약 D의 가중치를 조정하는 과정 없이 G만 계속해서 가중치를 조정할 경우, G는 p_data의 분포를 따르는 데 충분한 다양성을 지닐 수 없게 되는 "Helvetica scenario"에 빠지게 되어 우리가 원하는 G를 얻지 못하게 됩니다.
논문에서 "Helvetica scenario"를 'G collapses too many values of z to the same value of x to have enough diversity to model p_data'라고 말했는데 제대로 해석하기가 어려웠습니다.
이제 장점을 봅시다. 저자는 역전파로 그레디언트를 구할 수 있기 때문에 Markov chain이 필요하지 않다는 것, 학습 과정에 inference를 할 필요가 없다는 것, adversarial nets framework와 다양한 함수를 합칠 수 있다는 것을 장점으로 꼽았습니다. 다음의 표를 통해 Adversarial models과 다른 것들을 비교하실 수 있습니다.
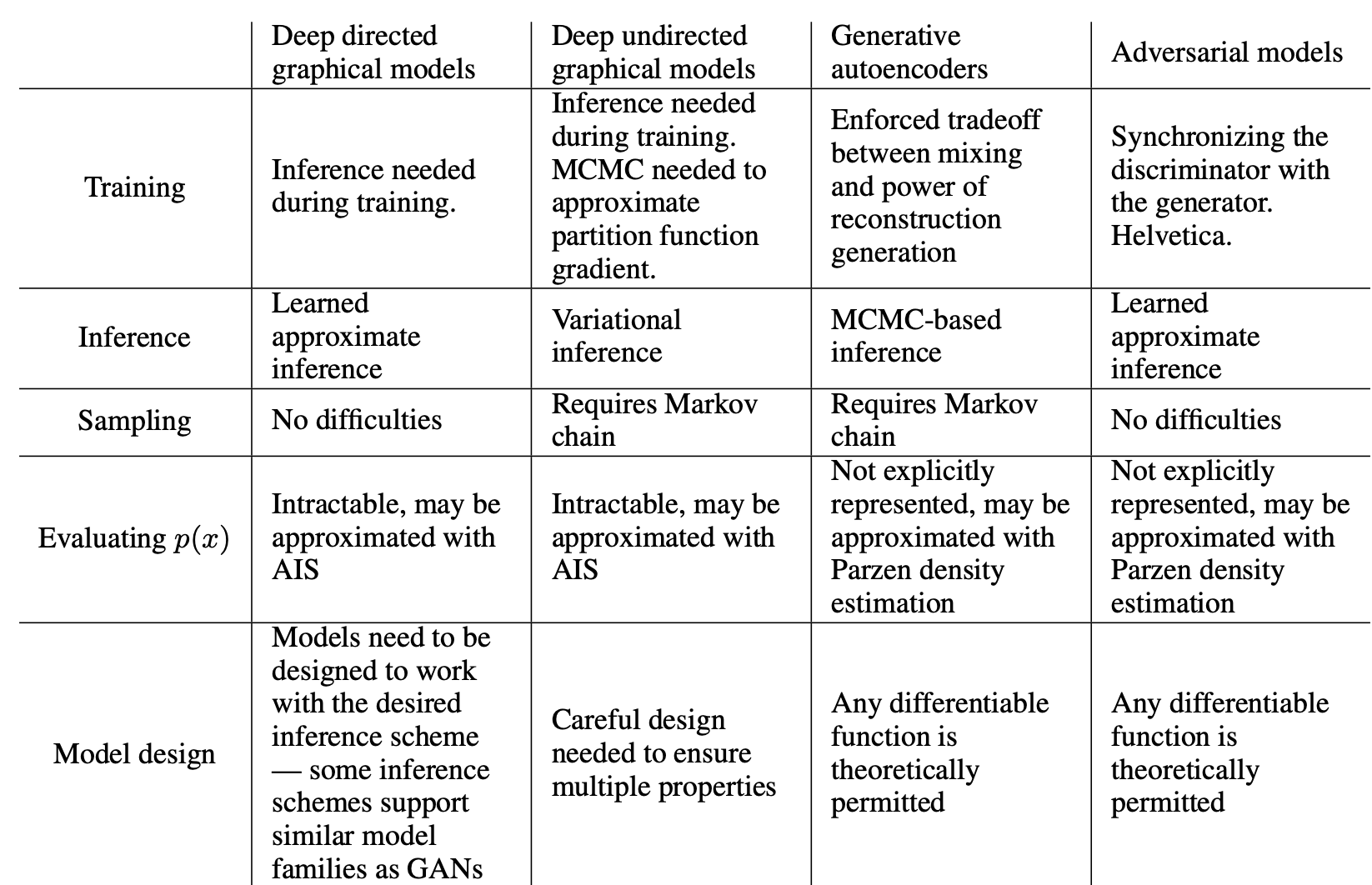
앞서 말한 장점들은 주로 계산에 관한 내용들이었습니다. 허나 adversarial nets framework는 statistical advantage도 가지고 있습니다. 모델을 만들 때, 데이터 예제를 통해 직접적으로 가중치를 업데이트하는게 아니라 dircriminator D를 통한 그레디언트의 흐름으로만 가중치를 업데이트 할 수 있다는 것입니다.
이는 입력 데이터의 구성요소들이 generator의 가중치 속에 직접적으로 복사되는게 아니라는 뜻과 같습니다. 그리고 매우 예리하면서도 퇴화된 분포를 나타낼 수 있다는 것도 장점으로 꼽혔습니다. Markov chain은 다양한 모드와 혼합될 수 있게 조금 흐릿한 분포를 요구한다고 하네요.
음...기존의 데이터를 정확히 모방해 퀄리티는 같으면서 완전 똑같은 데이터가 아니라 조금 차이가 나는 데이터를 생성한다는 것을 이렇게 설명한건가 싶습니다.
Conclusions and future work
저자들은 자신들이 쓴 GAN을 기점으로 발전될 수 있는 방향을 말했습니다. 논문에서는 'admits many straightforward extensions'이라고 말합니다.
- G, D에 C를 입력데이터로 추가하면 조건부 generative model p(x|c)를 얻을 수 있다.
- auxiliary network가 x를 가지고 z를 예측하게끔 학습시키면 Learned approximate inference를 수행할 수 있다. 이는 wake-sleep 알고리즘으로 학습된 inference net과 비슷하지만 auxiliary network는 학습이 끝난 generative model을 위해 학습될 것이라는 이점을 가지고 있다.
- 가중치를 공유하는 조건부 모델의 family가 x의 모든 부분집합 S에 대한 조건부 확률 p(xS | x̸S)을 나타내게끔 학습시킬 수 있다.
- Semi-supervised learning : 라벨링된 데이터가 적을 때, discriminator or inference net에서 얻은 특성들이 classifier의 성능을 향상시킬 수 있다.
- Efficiency improvements : 학습하는 동안 z를 sample하는 더 나은 방식을 만들어내어 학습을 엄청 가속화 시킬 수 있다. 여기서 방식은 'G, D를 조정하거나 더 나은 분포를 결정하는 방식'을 말한다.
이렇게 GAN을 기반으로 발전할 수 있는 방향이 매우 많습니다. 저자는 GAN이 adversarial modeling framework의 실행 가능성을 증명했고 이러한 연구에 대한 방향이 유용하다는걸 증명했다고 말하며 논문을 끝냅니다.
후기
힘들었습니다. 낯선 분야의 논문이라 많은 부분에서 힘들었는데 특히 자세히 쓰여진 식을 이해하는게 제일 힘들었습니다. 솔직히 말하면, 지금도 100% 이해하지는 못했습니다. 제가 관심 있는 컴퓨터 비전에 GAN을 적용한다고 가정하고 대입하며 이해하려고 해봤는데 음...쉽지 않았습니다.
그래도 머리를 많이 굴릴 수 있게 만들어줘서 고마운 논문이었습니다. 앞으로도 이러한 논문을 많이 접했으면 좋겠습니다.
그러면 다음 논문에서 뵙겠습니다.
