안녕하세요. 밍기뉴와제제입니다. 이전에 SSD를 리뷰할 때 다음 논문은 Object Detection이 아닌 다른 task를 수행하는 논문을 리뷰하겠다고 말씀드렸습니다.
그래서 이번에는 Image Segmentation을 수행하는 U-Net을 리뷰해보려고 합니다. U-Net은 Image Segmentation 혹은 Semantic Segmentation라 불리는 영역의 대표적인 논문이며 U-Net의 방식은 지금도 많이 쓰입니다.
지금부터 Semantic Segmentation라고 용어를 통일하겠습니다.
Semantic Segmentation를 다음과 같은 일을 하는걸 말합니다.

(출처 : https://viso.ai/deep-learning/image-segmentation-using-deep-learning/)
왼쪽의 이미지를 받아 오른쪽과 같이 객체의 class별로 구분을 하죠. 구분을 하고 있다는걸 보여주기 위해 색상을 칠한 것이지 색칠을 꼭 해야하는건 아닙니다. Semantic Segmentation은 이제 아이폰의 '인물 사진'모드 등에 필요한 작업이죠. 인물 사진 모드는 사람을 강조하기 위해 나머지 객체를 흐릿하게 처리하며 이 때 Semantic Segmentation을 학습한 모델로 카메라에 담긴 어떤게 사람인지 아닌지 파악합니다.
아무튼, 이러한 Semantic Segmentation을 의료용 Biomedical image 분석에 사용한 모델이 U-Net입니다. Biomedical image은
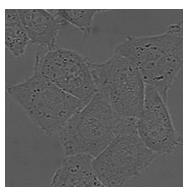
이렇게 세포를 찍은 사진을 말합니다. 사진 속에 있는 세포를 구분하는 것을 U-Net이 하는겁니다.

이렇게 말이죠. 저 회색 사진에서 세포를 구별했다는게 참 신기하기만 합니다.
어떻게 만들고 학습시켰길래 저걸 가능하게 만든걸까요? 지금부터 확인해봅시다.
Introduction
여기서는 U-Net이 나오게 된 배경을 설명해줍니다. 2012년 AlexNet의 등장 이후 컨볼루션 연산을 수행하는 신경망을 여려개 쌓아 이미지를 처리하는 방식이 널리 사용되었습니다. 점점 AlexNet보다 더 덩치가 커지고 그에 따라 더많은 데이터셋이 필요한 모델이 증가했죠.
AlexNet 등의 모델이 주로 이미지 처리로 수행하는 일은 이미지 속 하나의 이미지가 어떤 객체인지 분류(Classification)하는 것이었습니다. 허나 Biomedical image같은건 앞서 보셨듯 한 이미지 안에 여러개의 세포가 들어있기 때문에 픽셀별로 클래스 분류를 해야하는, Localization이 포함된 Classification이 필요했습니다.
이를 해결하기 위한 방식이 나오긴 했습니다. 논문에서 언급한 방식은 픽셀과 픽셀 주변의 영역을 받아 픽셀에 담긴 정보가 어떤 객체를 나타내는건지 판단하는 방식인데요, 이렇게 되면 학습 데이터가 이미지 단위가 아닌 이미지 속 일부가(논문에서는 'patch'라고 합니다) 한 단위가 되기 때문에 훨씬 풍부한 데이터셋을 구현할 수 있다는 장점이 있습니다.
허나 이렇게 객체를 예측하면 patch별로 연산을 하니까 연산 속도가 매우 느리며 서로 중복된 영역을 가지는 patch가 많아 중복된 예측 결과도 많이 나온다고 합니다. 그리고 이런 방식의 또다른 단점으로 localization accuracy와 use of context 사이에 존재하는 trade-off가 있다고 합니다.
patch의 크기가 크면 더 많은 max-pooling layer를 요구하여 localization accuracy가 떨어지고 patch의 크기가 작으면 litte context만 알 수 있다고 합니다. 여러가지 단점이 있는 것이죠.
단점을 개선한 U-Net
U-Net는 fully convolutional network라는 구조라는, 기존의 방식보다 elegant한 구조로 만들어졌습니다. 이걸 참조해서 만들었다고 하네요.
U-Net은 적은 데이터셋에 학습시켜도 더 좋은 성능이 나오는 모델입니다. U-Net은 특성을 추출하여 점저 해상도가 줄어드는 feature map을 얻다가 up-sampling -> CNN -> 축소하는 과정에서 얻은 같은 해상도의 feature map과 합체하는 과정을 거칩니다. 그림으로 나타내면 다음과 같습니다.
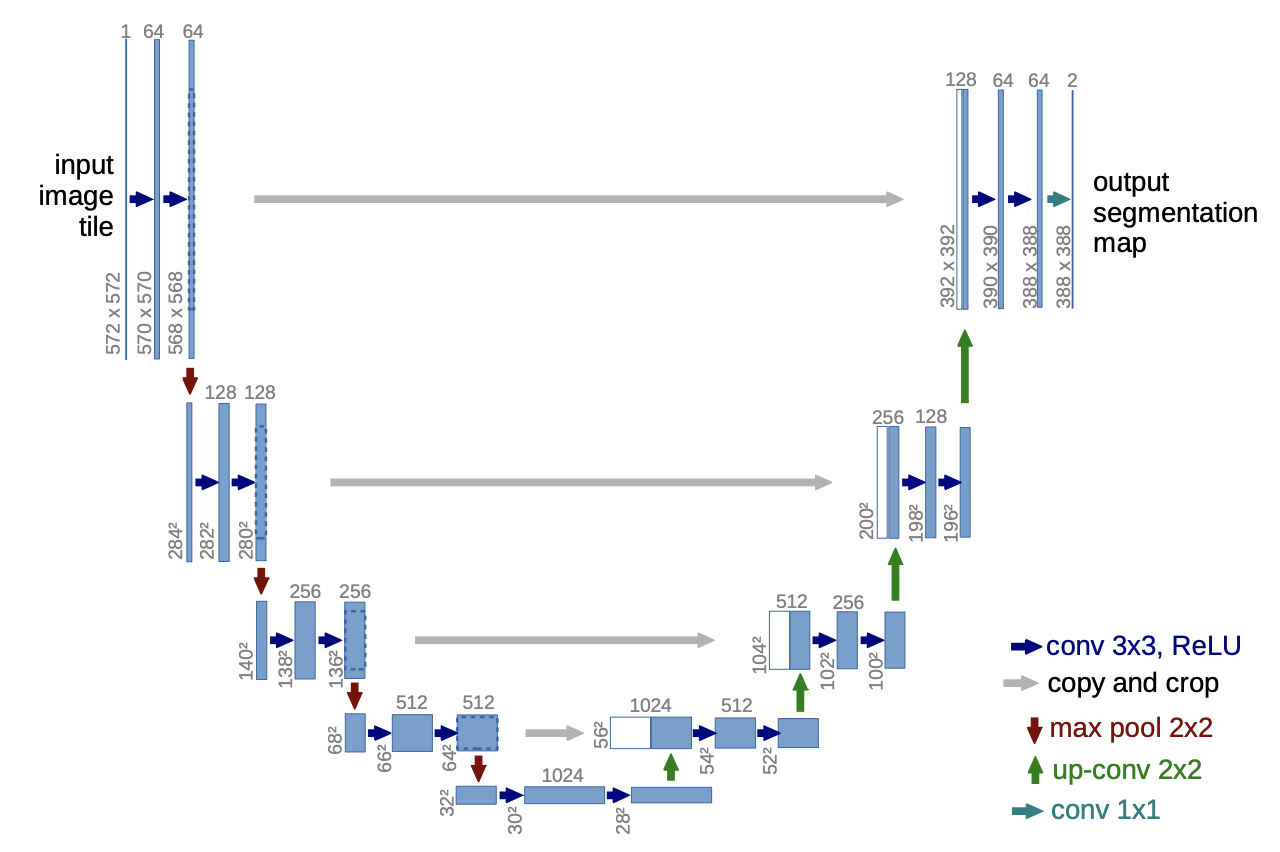
그림을 보면 제가 어떤걸 말씀드리려고 했는지 쉽게 이해하실 것입니다. 이렇게 이미지를 처리하겠다는 아이디어는 참고한 모델이 가지던 main idea라고 하네요.
U-Net의 구조가 가지는 특징은 여러가지가 있습니다. 우선 upsampling과정에서 channel의 숫자가 더 많기 때문에 higher resolution layer에 context information을 전파할 수 있다고 하네요. 아마 combine할 때 낮은 해상도가 가지는(우측에 있는) feature map의 채널이 왼쪽에 있는 feature map들보다 더 많아서 나온 말이 아닌가 싶습니다.
그리고 점점 해상도가 줄어드는 경로(contracing path)가 점점 해상도가 늘어나는 경로(expansive path)와 layer 개수가 거의 대칭되기 때문에 U자 형태를 가지고 있습니다. 그리고 Fully connected layer(FCN layer)를 사용하지 않았기 때문에 patch에서 얻은 정보만 가지고 해당 patch에서 classification을 수행할 수 있고 이 과정을 이미지 전체에 대해 시행하기 때문에 seamless한 segmentation이 가능합니다. GPU 메모리의 한계성 때문에 이 방식 말고는 거대한 이미지를 처리할 수 없다고 합니다.
U-Net은 Data augmentation도 사용했습니다. elastic deformation을 적용해 학습용 데이터셋이 기존의 Data augmentation을 사용할 때보다 많이 늘어났다고 합니다. 이러한 Data augmentation는 Biomedical segmentation에 중요하다고 하는데요, deformation이 조직(근육 조직 등)의 공통적 variation으로 가장 많이 쓰이는 방식이고 사실적 deformation은 효과적으로 시뮬레이션 될 수 있기 때문이라고 합니다. 제대로 이해하지 못했습니다😭
learning invariance를 위해 deformation을 사용하는 방식의 효능은 여기서 확인하실 수 있습니다.
그리고 세포가 찍힌 사진의 경우 세포가 여러개 붙어있어 구분이 힘들다는 문제가 있습니다. 이들을 따로 따로 구분해줘야 하죠. U-Net은 붙어있는 세포 사이즐ㄹ 구분하는 구분하는 것에 높은 가중치를 둔 loss function으로 이를 구현했습니다.
U-Net은 Semantic Segmentation에서 다른 모델과 비교했을 때 좋은 성능을 보여줬으며 자세한 결과는 Experiments에서 확인하실 수 있습니다.
Network Architecture
앞서 올린 모델의 구조를 다시 확인해봅시다.
U-Net은 사이즈가 줄어드는 경로(contracting path, 왼쪽)와 사이즈가 늘어나는 경로(expansive path, 오른쪽)로 구성되어 있습니다.
contracting path
contracting path는 우리가 아는 전형적인 CNN과 같습니다.
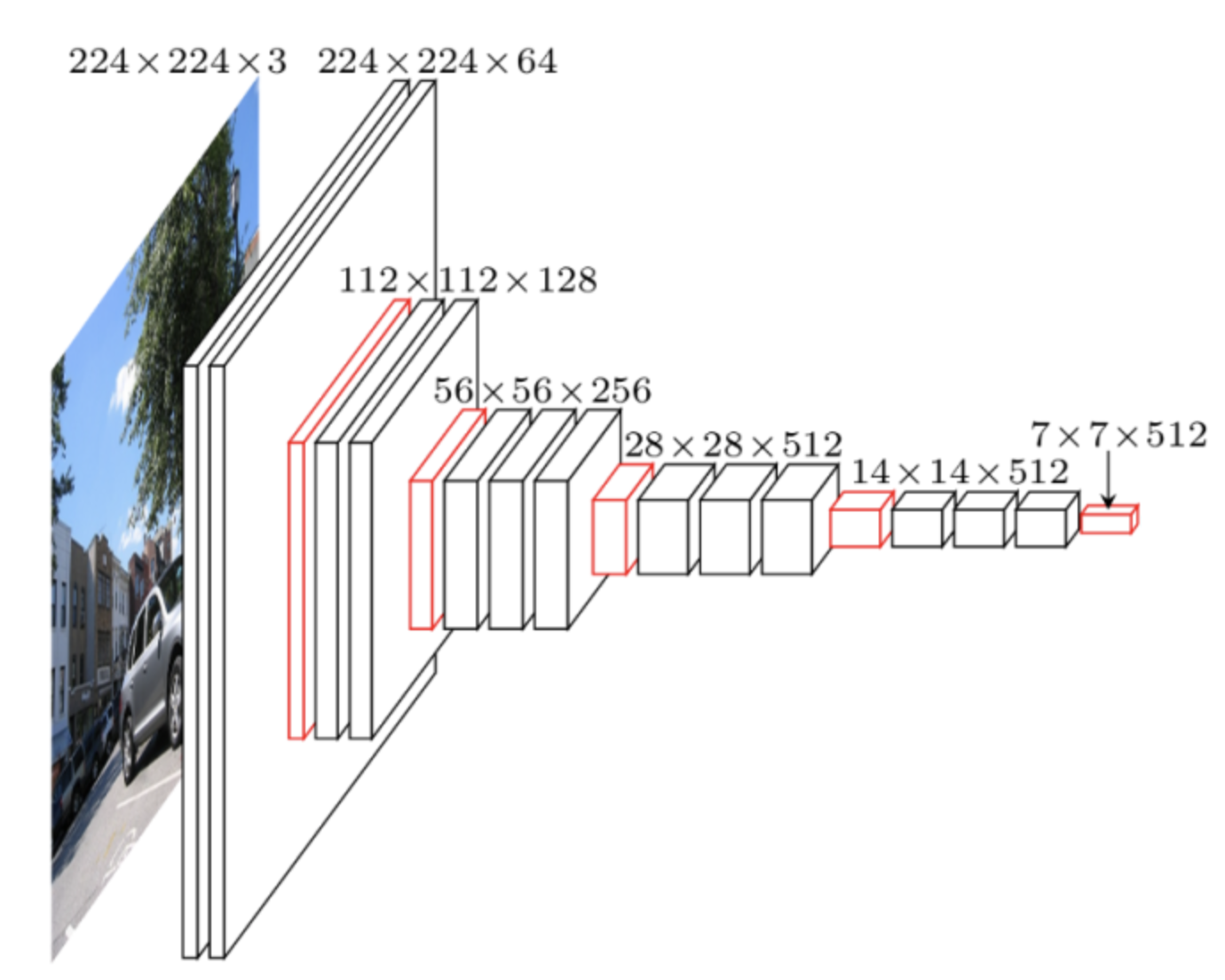
(출처 : https://www.jeremyjordan.me/convnet-architectures/)
이렇게 특성 추출을 하며 점점 feature map의 사이즈가 줄어드는 구조를 가지는 것이죠.
contracting path는 3x3 사이즈의 kernel을 가진 CNN(3x3 CNN)을 2번 적용하며 이 과정에서 활성화 함수로 ReLU(rectified linear unit)를 사용합니다. 그리고 stride = 2의 2x2 max pooling을 적용해 너비와 높이를 반으로 줄여버립니다(downsampling).
이 과정을 여러번 적용하는데 downsampling을 할 때 마다 kerel의 개수를 2배 늘립니다. 즉, channel의 크기를 2배로 늘리는 것이죠.
expansive path
expansive path는 contracting path와 좌우로 대칭되는 구조를 가집니다. 3x3 CNN을 2번 적용한 뒤 feature map의 너비와 높이를 2배로 늘리는(upsampling) 과정을 여러번 반복하는데 upsampling을 할 때마다 적용하는 CNN에 있는 kerel의 개수를 반으로 줄입니다.
이 때, Kernel의 개수를 반으로 줄인 CNN에 적용하기 전에 반대쪽 contracting path에서 같은 층에 있는 feature map과 합칩니다. 논문에서는 concatenation라고 표현했습니다. U-Net의 구조를 나타낸 그림에서 'copy and crop'이 이에 해당됩니다.
그러니까 정리하면 다음과 같은 것이죠.
CNN -> upsampling -> 맞은편 contracting path의 feature map을 copy and crop -> CNN ->...
여기서 crop을 하는 이유는 contracting path에 있는 feature map과 expansive path에 있는 feature map의 해상도가 같지 않기 때문입니다.
맨 마지막 단계에서 3x3 CNN을 2번 거치고 upsampling 대신 1x1 CNN을 사용해 channel의 개수를 2개로 줄입니다. 왜냐하면 최종적으로 판단할 클래스 개수가 2개(foreground, background)이기 때문입니다.
위와 같이 foreground, background 2가지로 전체 이미지에 있는 픽셀들을 분류하는 겁니다.
이렇게 U-Net은 23개의 CNN 레이어들로 구성되어 있고 segmentation map에 seamless tiling을 하기 위해 max pooling을 할 때 너비(x-size)와 높이(y-size)에 모두 적용하는 것이 중요합니다.
Training
여기서는 학습을 어떻게 시켰는지 나옵니다.
저자는 GPU 메모리를 최대한 활용하기 위해 이미지 파일을 여러개의 배치로 나눴습니다. 학습용 데이서텟의 단위가 이미지가 아닌 이미지 '일부'인거죠. 그래서 데이터셋 구성에 필요한 이미지 개수는 줄이면서 데이터셋 내 입력 파일의 개수는 늘렸습니다. 그리고 모멘텀을 0.99로 설정해 이전에 조정한 가중치를 현재 시점의 가중치를 조정하는데 상당히 많이 반영했습니다.
그리고 energy function이라는게 나옵니다. 얘는 맨 마지막에 얻은 feature map에 픽셀 단위로 soft-max를 수행하고 여기에 cross entropy loss function을 적용하는 식이라고 하는데요, 식은 다음과 같습니다.
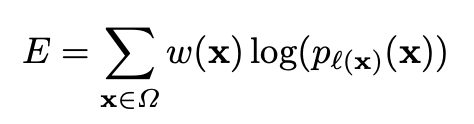
여기서 x는 feature map에 있는 각 픽셀을 말합니다. 각 픽셀에서 계산한 걸 다 더한거죠. w(x)는 weight map이라고 픽셀 별로 가중치를 부과하는 역할을 합니다.
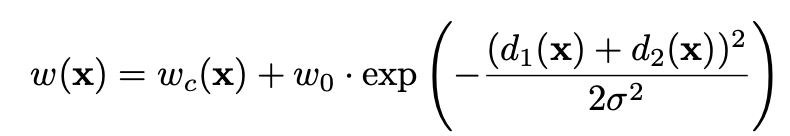
이게 바로 weight map인데요, 이 식은 특정 클래스가 가지는 픽셀의 주파수의 차이를 보완해주는 식이라고 보시면 됩니다. 같은 세포 클래스라도 픽셀값에 차이가 있으니 그런걸 채워준다 뭐 그런뜻이 아닌가 싶습니다.
그리고 weight map은 같은 클래스 사이에 가질 수 있는 짧은 간격에 대해 학습하게끔 만들어주는 기능을 합니다. 세포 사이에 떨어진 간격이 짧아 세포별로 구별이 힘든 경우가 바로 이런 경우죠.
d1은 바로 가장 가까운 클래스의 테두리와의 거리, d2는 두 번째로 가까운 클래스의 테두리와의 거리를 말합니다. σ는 5, w_0 = 10입니다.
정리해보면, 이러한 weight map에 log(픽셀에서 얻은 클래스별 예측값을 soft-max한 것)를 곱한 것이 E라고 할 수 있겠습니다.
참고 자료 : weight map의 효과를 시각적으로 확인
이렇게 세포 사이에 간격이 촘촘한 경우, 이런 간격을 구분할 수 있도록 학습하게끔 만들어줍니다.
마지막에는 가중치를 초기화하는 방식을 말해줍니다. U-Net의 가중치는 헌 뉴런에 들어오는 노드의 개수를 N이라고 하면 root(2/N)의 표준 편차를 가진 가우시안 분포를 이용해 가중치를 초기화 합니다.
예를 들어 3X3 CNN에 channel = 64인 feature map이 들어오면 해당 CNN의 N = 9*64 = 576입니다.
Data Augmentation
Data Augmentation는 학습용 데이터셋이 별로 없을 때 사용하기 유용한 기술입니다. 다양한 구성의 데이터셋으로 만들어주니 invariance하고 rubustness한 성질을 가지는 모델로 학습되겠죠.
현미경 등으로 촬영하는 사진들(microscopical image)은 색깔이 다양하지 않고 회색빛깔로 이루어져있고 객체간 구별도 선명하지 않기 때문에 Data Augmentation을 이용해 풍부한 데이터셋을 만드는게 더욱 필요합니다. U-Net은 Data Augmentation를 위해 shift, rotation 등을 수행합니다.
논문에서는 이를 ''we primarily need shift and rotation invariance as well as robustness to deformations and gray value variations'라고 말합니다.
U-Net은 shift, rotation 외에 random-elastic deformation이라는 기법을 사용해 Data Augmentation을 구현하기도 했습니다. 저자는 random-elastic deformation이 "작은 데이터셋을 가지고 segmentation network를 학습시킬 때 key concept으로 보인다"고 말했습니다.
마지막으로 저자가 어떻게 Data Augmentation을 구현했는지 순서대로 적어놨습니다.
- coarse 3 x 3 grid에 random displacement vectors을 이용해 smooth deformation을 수행합니다. displacement는 10개 픽셀이 가지는 값들의 표준편차를 따르는 가우시안 분포에서 임의로 뽑은 값으로 수행합니다.
- bicubic interpolation을 이용해 픽셀 단위로 displacement를 계산합니다.
- contracting path의 맨 끝에 있는 Drop out layer가 더욱 implicit한 Data augmentation을 수행합니다.
Experiments
이제 성능 평가 부분입니다.
EM segmentation challenge
우선 U-Net은 전자현미경으로 관찰되는 뉴런 구조에서 cell segmentation task를 수행했습니다. EM segmentation challenge에서 제공되는 데이터셋으로 학습했다고 하네요.
데이터셋은 전자 현미경으로 찍은 512 x 512 해상도의 이미지 30장으로 이루어져있고 이미지의 각 부분에 세포는 흰색으로, 세포막(membrane)은 검은색으로 색칠한 ground truth segmentation map을 만들었습니다. 상상만 해도 힘든 과정이지 않았을까 싶습니다. 테스트용 이미지도 있는데 ground truth segmentation map은 공개되지 않았다고 하네요.
평가 지표는 warping error, Rand error, pixel error가 있는데 이들에 대한 자세한 설명은 여기서 확인하실 수 있습니다. 대략적으로 '얼마나 정확히 세포 영역을 구분할 수 있냐?'를 여러 측면에서 확인한 것이라 보시면 됩니다.
저자는 U-Net을 포함한 10개의 모델을 가지고 성능을 평가했고, 평과 결과는 다음과 같았습니다.
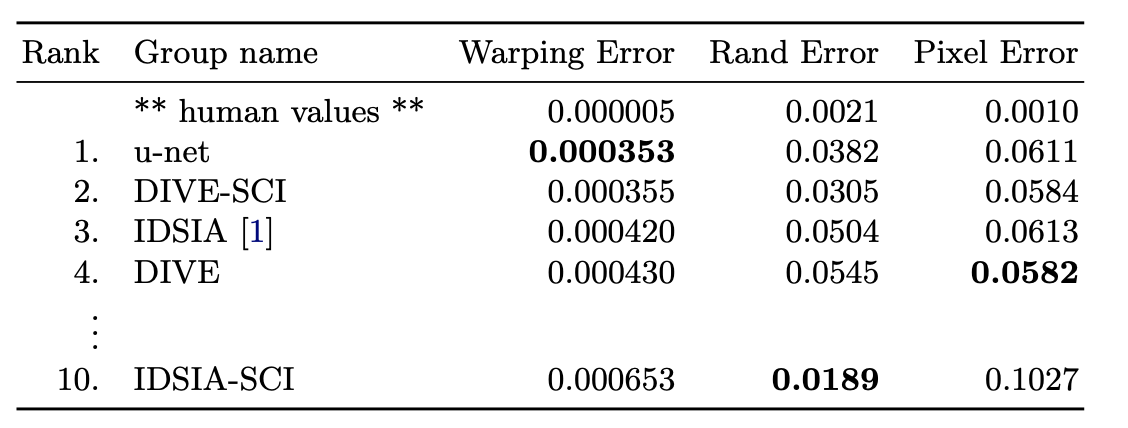
역시 U-Net이 제일 좋은 성적을 거뒀습니다.
ISBI cell tracking challenge
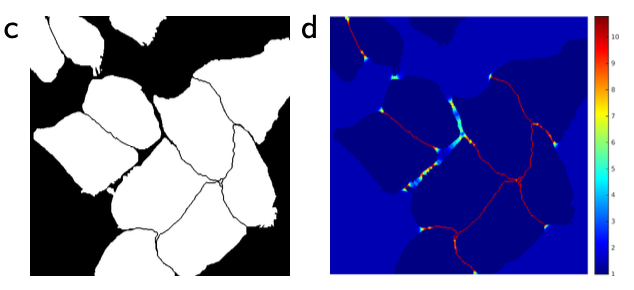
U-Net은 광학 현미경(light microscopic)에서 얻은 이미지로도 cell segmentation task를 수행해봤습니다. 이러한 task는 ISBI cell tracking challenge 2014, 2015에 포함된 task라고 합니다. 의학분야 전공 용어가 마구마구 나오길래 정신을 못차렸으나 그림을 보고 '아~이런거 하구나' 이해했습니다.
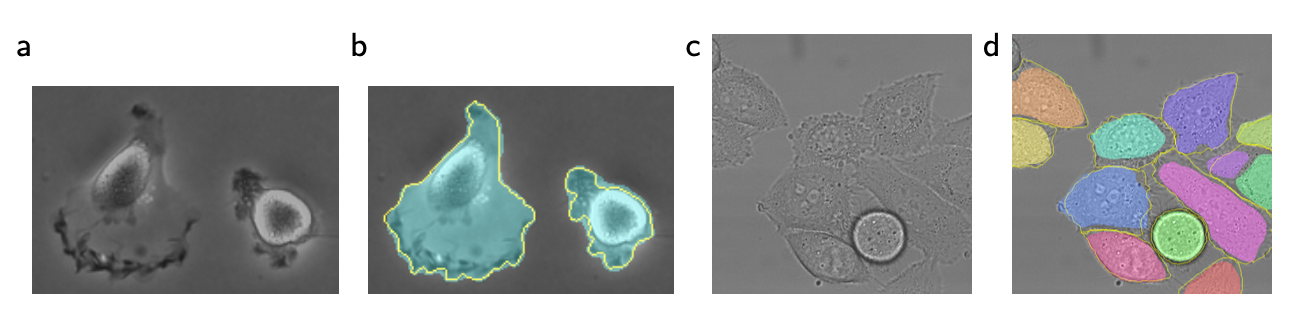
a, c가 입력 이미지고 b, d가 ground truth segmentation map입니다. a, c와 같이 광학 현미경에서 얻은 이미지로 b, d와 같이 세포를 구별하는 task를 U-Net이 얼마나 잘 수행하는지 시험해보는 것이죠.
여기서는 성능을 IoU로 측정했습니다. 세포라고 구분한 영역과 실제 세포의 영역이 곂치는 정도로 성능을 측정한 겁니다. 결과는 다음과 같습니다.
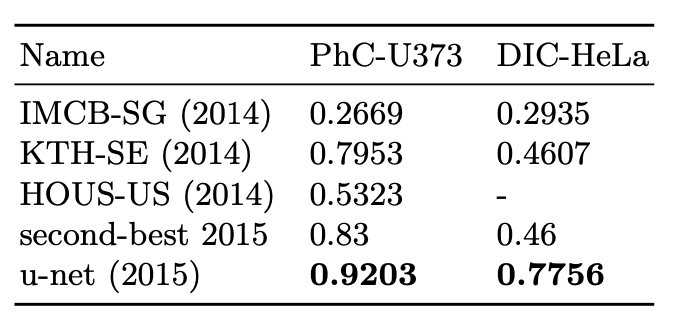
a가 "PhC-U373" 데이터셋에 있던 이미지고 c가 "DIC-HeLa" 데이터셋에 있던 이미지 입니다. c에서 세포 구별하는게 정말 힘들어보이는데 U-Net이 좋은 성적을 거뒀습니다.
Conclusion
U-Net은 다양한 biomedical segmentation applications에서 "아주" 좋은 성능을 보여줬습니다. 저자는 elastic deformation이 포함된 Data augmentation 덕분에 적은 사이즈의 데이터셋만 요구했고 합리적인 학습 시간(NVidia Titan GPU (6 GB)에서 10시간 학습)을 가졌다고 말했습니다.
그리고 마지막으로 U-Net의 구조가 다양한 task에 쉽게 응용될 수 있을거라 확신한다고 말하며 논문을 끝냅니다.
후기
많이 유명한 논문이지만 정작 U-Net의 존재를 알게 된건 CovidCTNet을 읽을 때였습니다. 뭔가 싶어 검색해보니 엄청난 인용수에 놀랐던 기억이 나네요.
아이디어가 정말 좋다는 생각이 든 논문이었습니다. 게다가 논문 분량도 작은 편이고 쉽게 읽혀서 한 번은 읽어볼만한 논문이라 생각됩니다.
다음 논문으로 찾아뵙겠습니다.
