
지금까지 Swift 내에서의 Struct와 Class의 차이라고 하면 상속을 할 수 있고 없고의 차이와 값 타입 그리고 참조 타입인 것으로만 알고 있었다. 그리고 어디선가 구글링하다가 읽었던 성능의 차이가 어느정도 있고 Struct가 Class보다는 빠르다?!라는 것을 주워 들은 적이 있었다.
하지만 성능 차이에 대한 이유나 정확히 어떠한 점이 다른지에 대해서는 찾아 볼 생각은 했지만 미루고 있었다가 이번 계산기 프로젝트를 진행하면서 또 한 번 Class를 써야할까 Struct를 써야할까 고민을 하게 되었다. 그리고 이번에는 꽤 오래전에 붱이와 다흰이 추천해 준 전부터 봐야지 봐야지 했던 WWDC2016 Understanding Swift Performance를 드디어 보게 되었다!!
물론 아직 다 본것은 아니고 Struct와 Class를 비교하는 부분까지 우선 보고 정리를 하게 되었다. 이번 포스팅에서는 일부분인 allocation에 대해서 다뤄 볼 예정이다.
UnderStanding Swift Performance
영상의 제목 자체가 Swift의 성능을 이해하자!! 인 만큼 Swift의 abstraction(추상화) 기법들이 미치는 성능을 이해해 볼 예정이다. 그러기 위해서는 먼저 Swift의 기본 구현을 이해해봐야할 것 같다.
Swift 에서 추상화를 만들고 추상화 기법을 선택할 때 3가지 측면을 고려해야 한다고 영상에서는 말하고 있다.

3가지 측면은 다음과 같다.
- allocation : 객체가 memory에 allocation될 때, heap에 저장이 될 것인가 아니면 stack에 저장이 될 것인가?
- Reference Counting : 객체를 주고 받을 때, 얼마나 많은 reference counting overhead가 발생하는가?
- Method dispatch : 객체 내 method를 호출할 때 static dispatch인가 dynamic dispatch 인가?
그리고 미리 결론을 살짝 말하자면
if we want to write fast Swfit code, we're going to avoid paying for dynamism and runtime that we're not taking advantage of. - WWDC2016
이득이 없는 dynamism과 runtime에 비용을 내는 것을 피해야지 빠른 Swift code 를 작성할 수 있다고 한다.
자 그럼 이제 본격적으로 3가지 측면 중에 첫 번째인 allocation에 대해서 알아보자.
Allocation
Allocation이란 할당이란 뜻으로 이번 포스팅에서 다룰 내용은 우리가 생성하는 추상화 객체들이 메모리의 어디에 할당될 것인가에 대한 내용이다.
먼저 Swift는 자동으로 메모리를 할당하고 해제해주는데 메모리 중 일부는 Stack에 할당이되기도 하고 Heap이라는 데이터 구조에 할당이 되기도 한다. 따라서 메모리의 Heap과 Stack 중 어디에 할당이 되느냐에 대해서 어떠한 성능차이가 있는지 알아보도록 하자.
Stack
- decrement stack pointer to allocate
- increment stack pointer to deallocate
스택은 정말 간단한 자료구조이다. 스택은 LIFO(LastInFirstOut)구조로 push, pop 연산이 한 곳에서만 일어난다. 즉, 우리는 단지 stack top을 가르키는 stack pointer만 알고있다면 언제든지 push 하고 pop을 할 수 있다.
따라서 스택에 메모리를 할당한다는 것은 decrement stack pointer, 즉 stack pointer를 감소시켜주면 된다. 반대로 할 일이 끝나고 스택에서 메모리를 할당 해제하는 것은 increment stack pointer, 즉 다시 기존의 stack에 할당하기 전으로 stack pointer를 증가시켜주면 된다.
이때 발생하는 비용은 모두 O(1), 즉 상수 시간 내에 해결이 가능합니다.
Heap
- Advanced data structure
- Search for unused block of memory to allocate
- Reinsert block of memory to deallocate
- Thread safety overhead
반면에 Heap이라는 데이터 구조는 Stack에 비해서는 덜 efficient(효율적)이긴 하지만 더 dynamic 하다. 즉, Heap은 stack이 dynamic life time에 메모리에 할당되지 못하는 것을 할당할 수 있다.
그러나 이러한 dynamic한 heap을 사용하기 위해서는 비용이 사용되게 된다.
- stack에 비해서 더 향상된 자료구조가 필요하다.
- heap에서 아직 사용되지 않은 적절한 사이즈의 block을 search 해야만 한다.
- 할 일이 다 끝나서 할당 해제를 해주기 위해서는, 그 메모리를 heap의 적절한 위치에 reinsert 해주어야한다.
위의 세 가지만 해도 Stack에 비해서 많은 시간이 걸린다고 생각할 수 있겠지만 heap을 사용하는데에 있어서 가장 큰 시간(비용)이 드는 것은 바로 thread safety overhead이다. 이것은 multiple threads가 동시에 heap에 메모리를 할당할 수 있으므로 heap은 integrity(통일성) 를 지키기 위해서 locking이나 다른 synchronization(동기화) 방법들을 사용해야만 하기 때문에 발생하게 된다.
그렇다면 이제 간단한 코드 예시를 통해서 실제로 Struct와 Class가 어떠한 형태로 메모리의 stack과 heap에 할당되는지 알아보도록 하자.
Allocation Code - Struct
// Allocation
// Struct
struct Point {
var x, y: Double
func draw() { ...}
}
let point1 = Point(x: 0, y: 0)
var point2 = point1
point2.x = 5
// use `point1`
// use `point2`다음과 같은 Point라는 struct 타입과 이를 x,y 를 (0,0)으로 초기화하면서 객체를 construct(생성)하는 point1과 이러한 point1을 할당받는 point2가 있다고 하자.
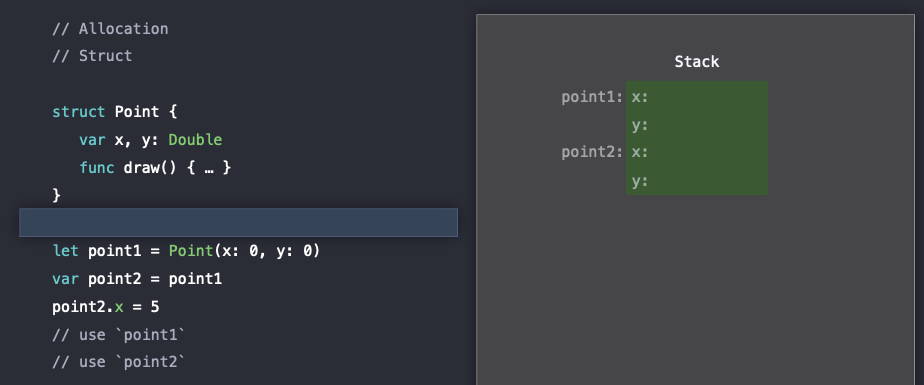
그리고 Point라는 struct 안에는 draw라는 method가 있다고 하자.
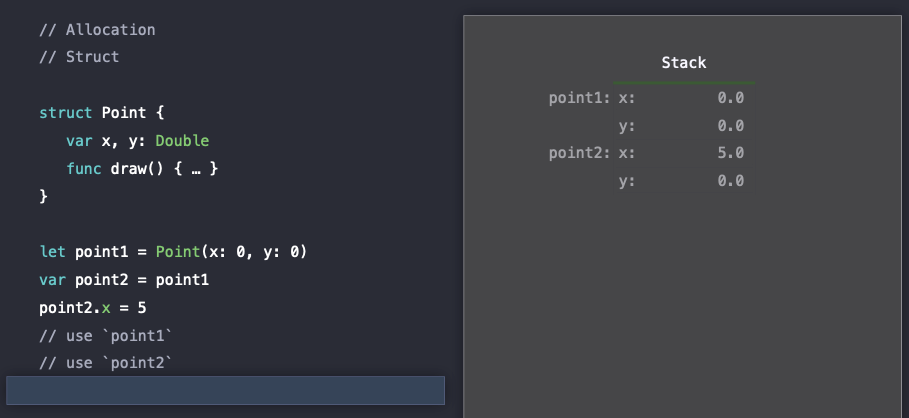
이때 코드를 실행하기 전부터 stack에는 point1과 point2의 객체는 이미 line 형태로 저장이 되어있다.
(x and y properties are stored in line on the stack)
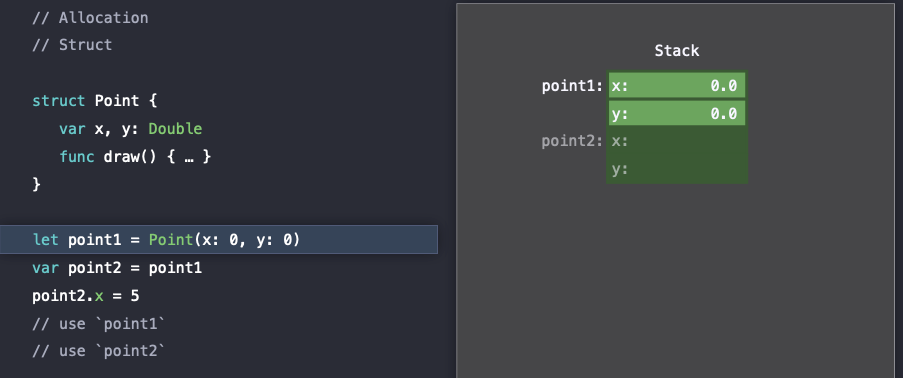
그리고 실제로 초기화를 하면 stack안에 있는 point1에 x, y값이 저장된다.
이때는 이미 메모리 stack 부분에 할당되어 있는 부분을 초기화 하는 것 뿐이다.
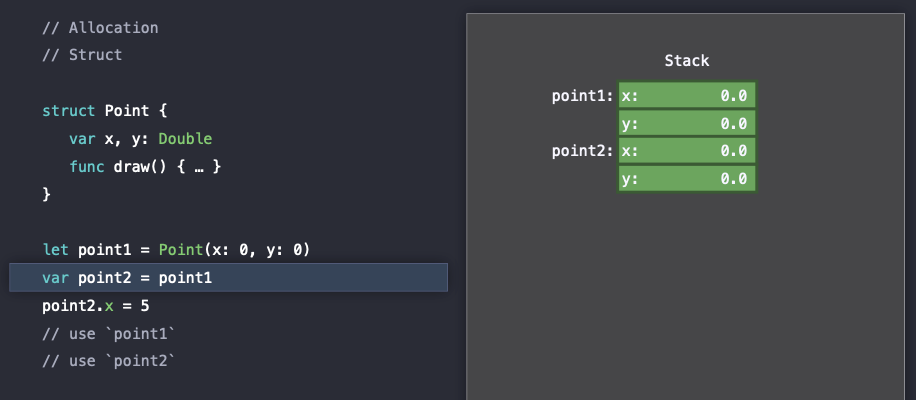
그리고 이제 point1을 point2에 할당을 해줄 때, struct 타입이므로 단지 copy를 하고 이미 메모리에 할당되어 있는 point2를 초기화해주는 것이다.
즉, 여기서 point1과 point2는 independent(독립적인) 객체이며 그렇기 때문에 아래의 그림에서 poin2.x에 5를 할당해도 point1.x는 여전히 0인 것을 확인할 수 있다.
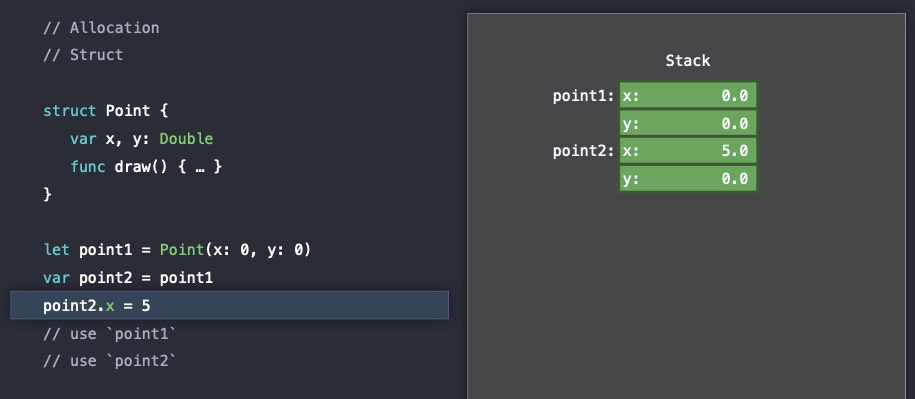
이러한 것은 value semantics로 알려져 있다.
사용을 마치고 나면 이제 Stack은 위에서 언급한 것처럼 increment stack pointer(stack pointer의 위치 증가) 해주어서 deallocate를 해주게 된다.
Allocation Code - Heap
// Allocation
// Class
class Point {
var x, y: Double
func draw() { ...}
}
let point1 = Point(x: 0, y: 0)
var point2 = point1
point2.x = 5
// use `point1`
// use `point2`위의 코드에서 그대로 struct만 class로 변경을 해주었다.
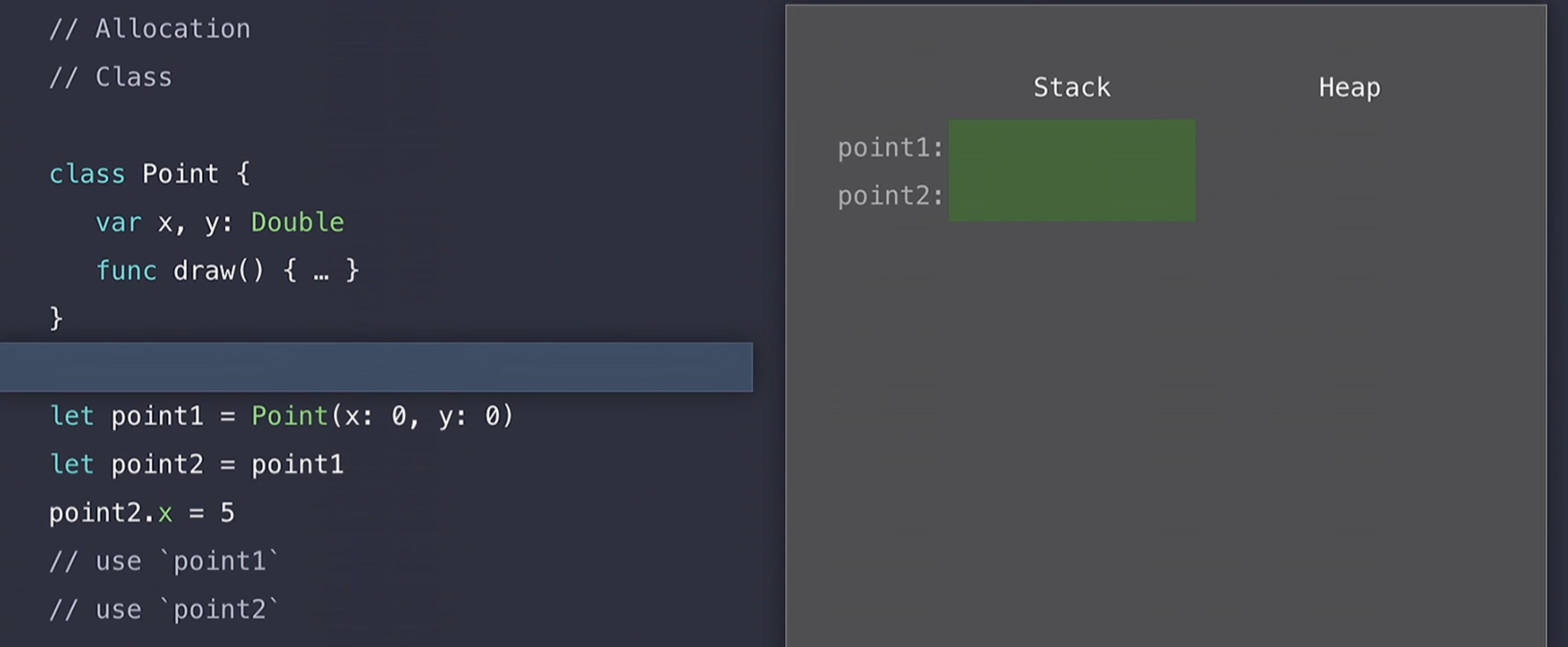
이전의 struct와는 다르게 코드가 실행되기 전에 메모리의 stack에는 단지 point1, point2 객체의 reference를 저장할 block만 할당되어 있다.
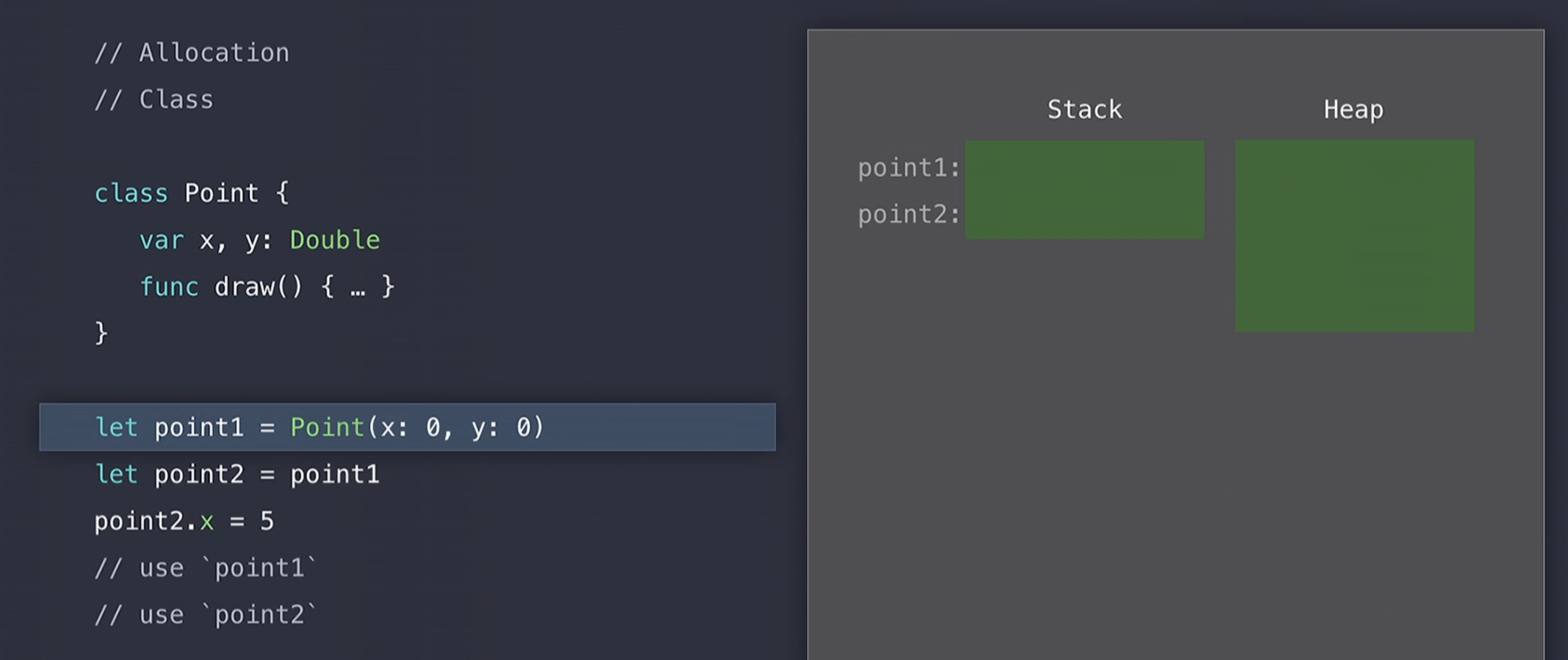
그리고 point1 객체에 0, 0으로 생성(construct)하려고 할 때 , Swift는 heap을 lock하고(integrity;무결성을 유지하기 위해서) 해당 데이터 구조에서 적절한 크기의 아직 사용되지 않은 메모리 블럭을 검색(search) 하게된다.
그러다가 사용할 수 있는 크기의 메모리 블럭을 발견하게 되면 아래의 그림처럼 이제 해당 메모리에 x, y를 0, 0으로 넣어주게되고 stack에서 point1의 reference를 heap에서 해당 memory address로 초기화 시켜주게 된다.
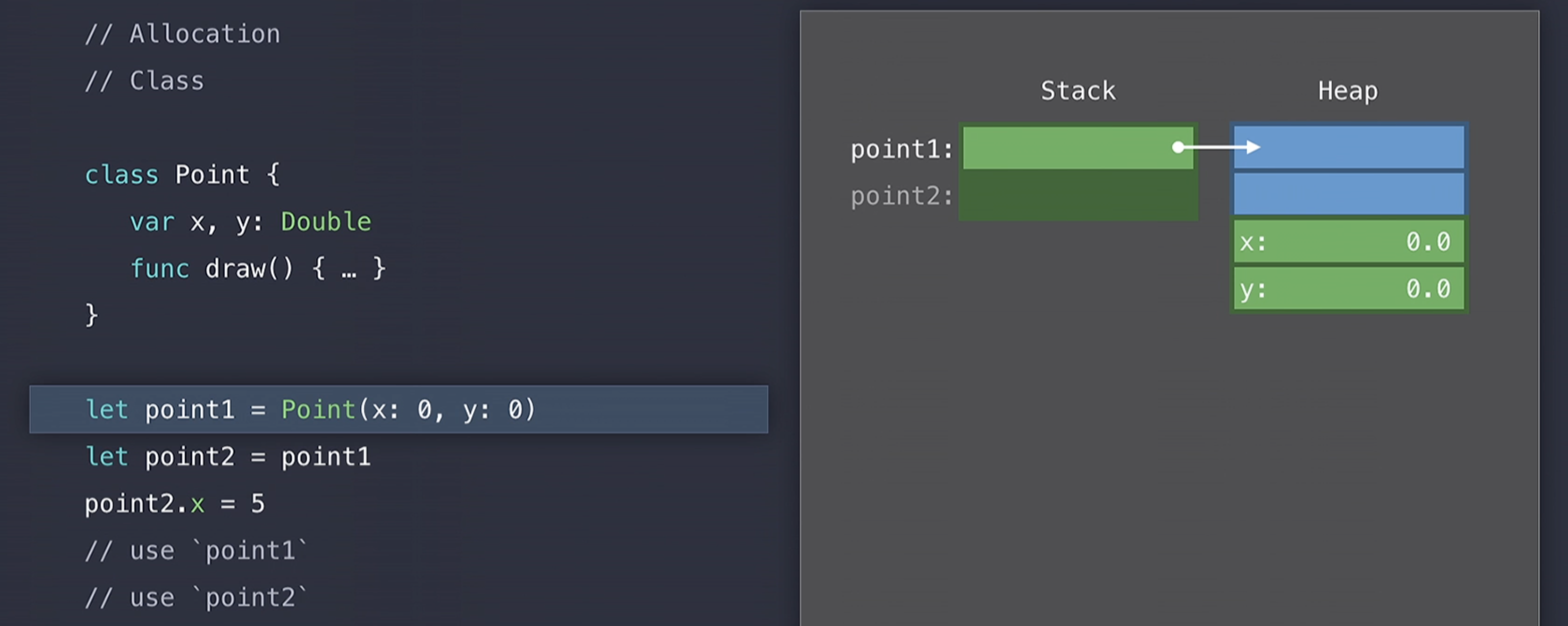
Heap에 allocate가 된 경우에는, Swift가 현재 Point 클래스에 대해서 4개의 공간을 차지한 것을 볼 수 있는데 이것은 struct일때 2개만 차지한 것과 차이가 있다.
Class일 때 x, y property의 개수보다 더 많은 공간을 차지하는 이유는 Swift가 이제 해당 Point Class를 우리를 대신하여 manage하기 위해서이다. 이러한 관리 공간은 위의 사진에서 파란색 박스 나와있는 부분이다.
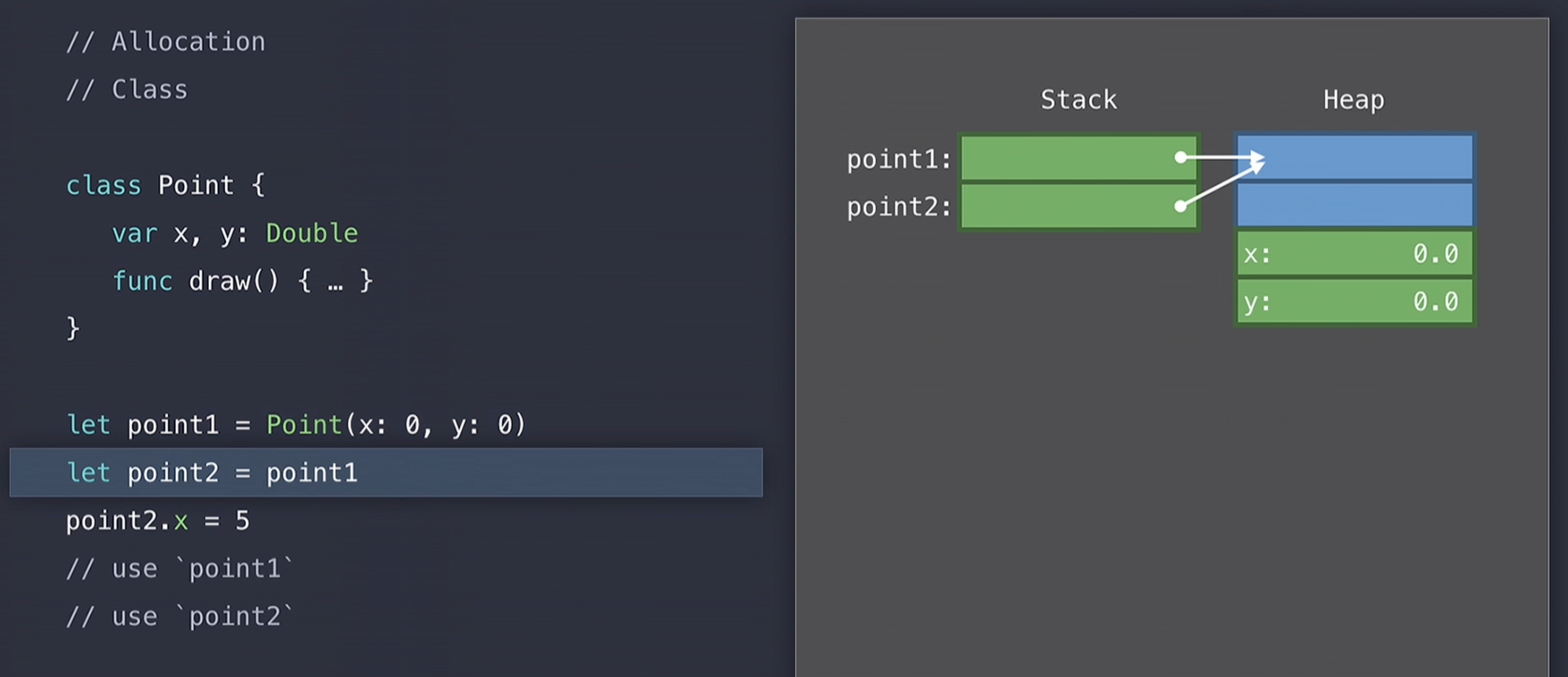
point2에 point1을 할당해 줄 때, struct일 때 처럼 값을 복사 해주는 것이 아니라 대신에 위의 사진처럼 reference를 복사하게 된다. 따라서 point1, point2 객체는 heap에서 정확히 같은 객체를 가르키게 된다.
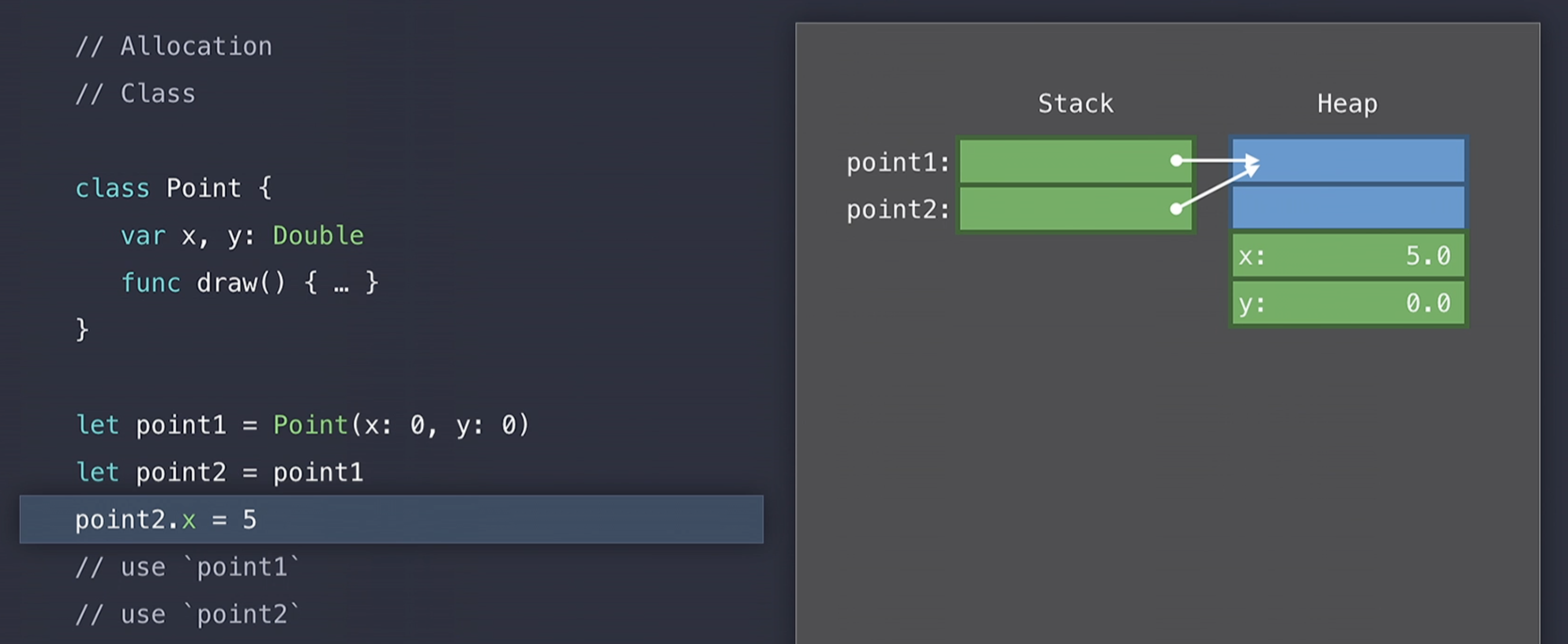
그렇기 때문에 point2.x에 5를 할당하게 되면 point1, point2 객체 모두 5라는 값을 가지게 된다. 이것은 reference semantics로 알려져 있고, reference semantics는 사용자의 의도와는 다르게 객체들의 값의 상태(값)를 공유하도록 이끌 수 있다.
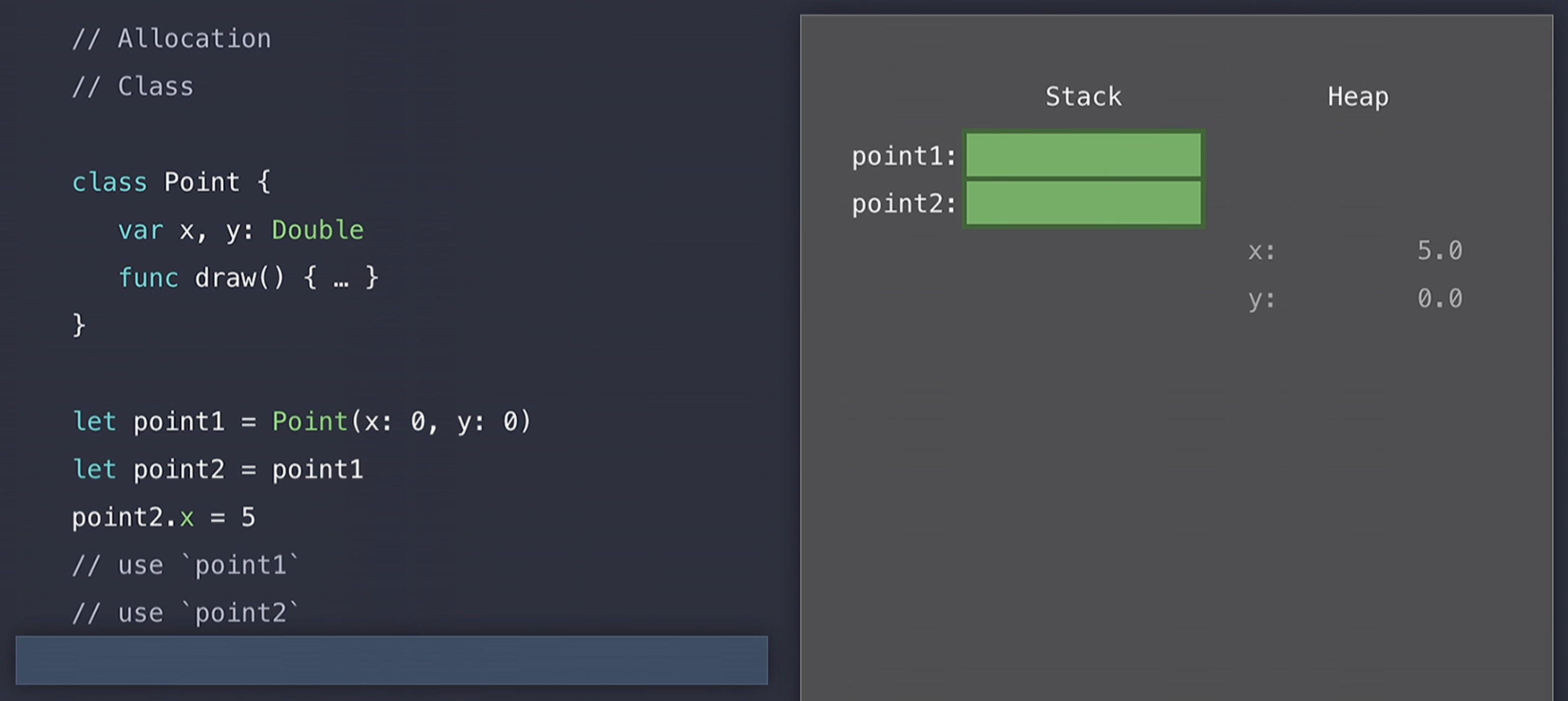
사용을 마치고 나면 Swift는 다시 heap을 lock하고(integrity;무결성을 유지하기 위해서) 적절한 위치에 해당 block을 다시 가져다 놓으므로써 할당 해제를 하게된다. 그리고 나서 그 이후에 아래의 그림처럼 Stack에서 pop을 할 수 있게 된다.
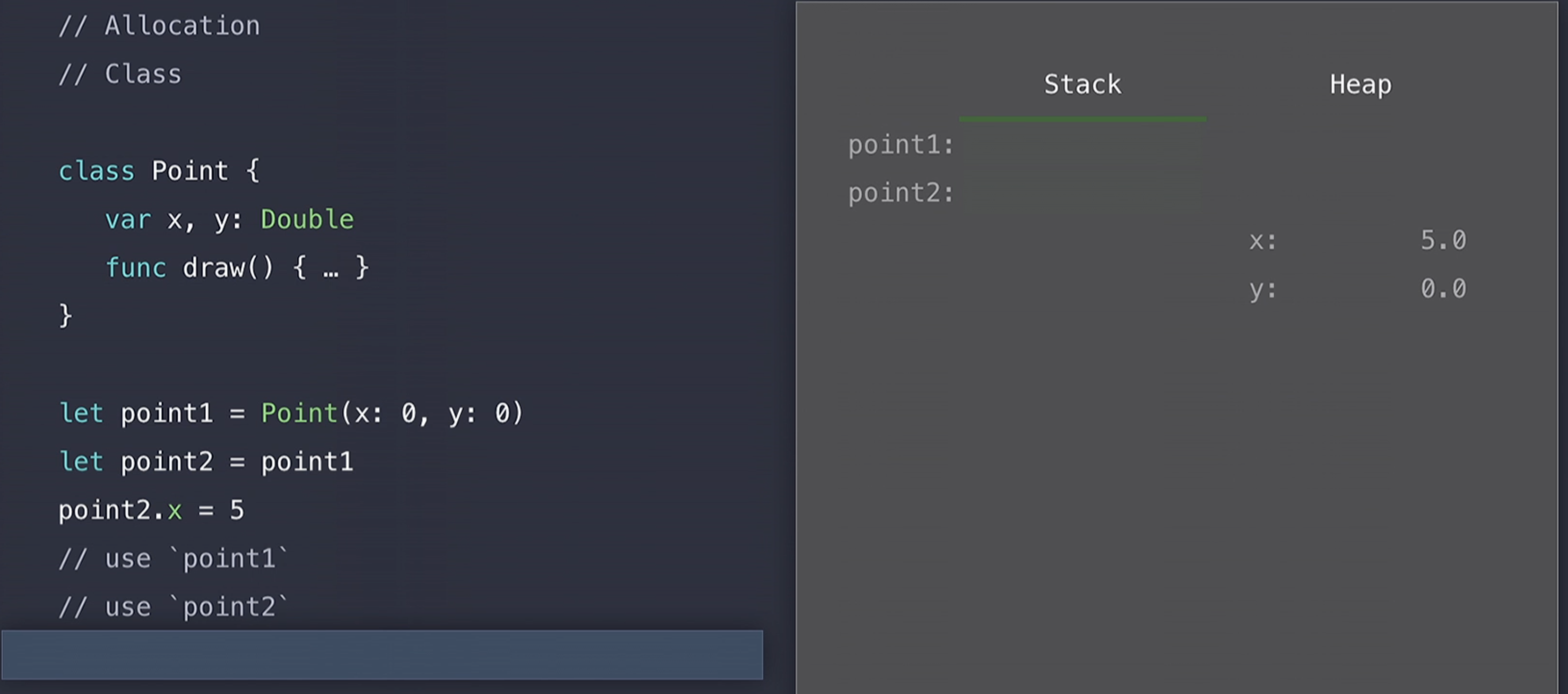
위에서 2개 코드 예시를 보았듯이 struct보다 class가 생성(construct)하는데 더 많은 비용이 드는 것을 확인할 수 있었다. 왜냐하면 class는 heap에 allocation되기 때문이다.
class는 heap에 할당되고 reference semantics를 가지기 때문에 ID(identity)와 간접저장소(indirect storage)라는 강력한 특징들을 가지게 된다. 그러나 만약 이러한 특징이 필요가 없다면 class보다는 struct를 사용하는 것이 성능적인 측면에서는 더 좋을 것이다.
Modeling Techniques: Allocation
영상에서는 또 다른 예시를 하나 들어주고 있는데 한 번 같이 알아보도록 하죠.
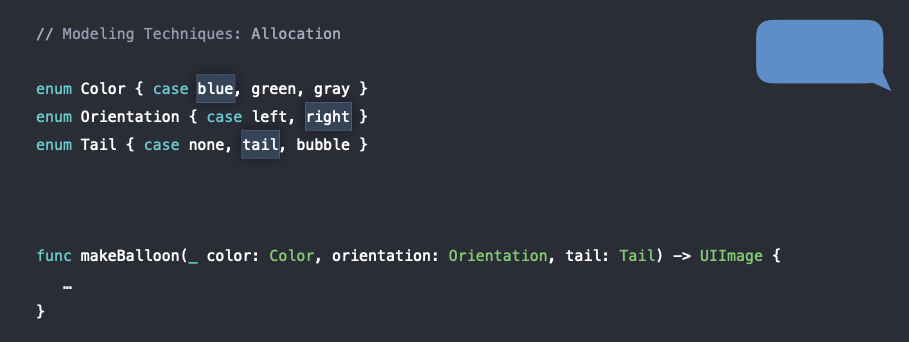
다음과 같이 말풍선을 구현해주는 makeBalloon이라는 함수가 있고 말풍선의 색깔, 방향 그리고 꼬리 모양을 enum 타입으로 설정해 놓은 코드가 있다고 합시다.
이때 이 makeBalloon()이라는 메소드는 애플리케이션 lauch와 user가 scrolling할 때마다 빈번히 호출되기 때문에 매우 빠르게 실행이 되어야한다고 합니다. 그렇기 때문에 아래의 코드와 같이 cache 역할을 할 수 있는 코드를 추가했다고 합니다.
여기서 잠깐❗️cache란 주기억장치와 CPU사이에 위치하며, 자주 사용하는 프로그램과 데이터를 기억한다. 즉, 자주 사용하는 프로그램과 데이터를 매번 주기억장치에서 load 해오는 것은 비효율적이기 때문에 주기억장치보다 훨씬 빠른 cache에 해당 프로그램과 데이터를 넣어두고 빠르게 사용하는 것을 의미합니다. 이때 cache안에 찾는 데이터가 있는 경우는 Hit 했다고 하고, 데이터가 없는 경우에는 miss 했다고 한다.
// Modeling Techniques: Allocation
enum Color { case blue, green, gray }
enum Orientation { case left, right }
enum Tail { case none, tail, bubble }
var cache = [String: UIImage]()
func makeBallon(_ color: Color, orientation: Orientation, tail: Tail) -> UIImage {
let key = "\(color):\(orientation):\(tail)"
if let image = cache[key] {
return image
}
...
}그래서 위의 코드에서 cache의 역할은 한 번 생성된 말풍선에 대해서는 절대로 다시 만들 필요가 없도록 dictionary 타입으로 구현을 해놓았다. (Dictionary 타입은 중복된 key 값을 가질 수 없으므로 중복된 말풍선은 있을 수 없다) 따라서 한 번 저장을 해놓으면 다음 번에 다시 말풍선을 만들 필요가 없이 cache안에 해당 말풍선이 있다면 key로 접근하여 꺼내서 사용하면 된다.
그러나 여기서 key를 String타입으로 만든 것은 그리 강력한 타입이 될 수 없다. 왜냐하면 key 안에 들어가는 것이 나 자신의 이름인 Jake가 되어도 전혀 이상할 것이 없기 때문이다. 즉, 안전성 측면에서의 문제가 발생할 수 있다.
또한 String은 다양한 것들을 나타낼 수 있는데 이는 String contents의 character들은 간접적으로(indirectly하게) heap에 저장이 되기 때문이다. 즉, 이 말은 비록 해당 풍선이 cache에 있어서 Hit 했다고 하더라도, key가 String 타입이기 때문에 결국 String의 내용들을 가져오기 위해서는 heap allocation이 발생하게 된다.
따라서 이러한 부분을 아래의 그림과 같이 heap을 참조하지 않는 타입들로 변경해 줄 수 있다.
key에 해당하는 color, orientation, tail을 하나의 struct로 만들어주고 이러한 struct를 dictionary의 key 값으로 사용하는 것이다.
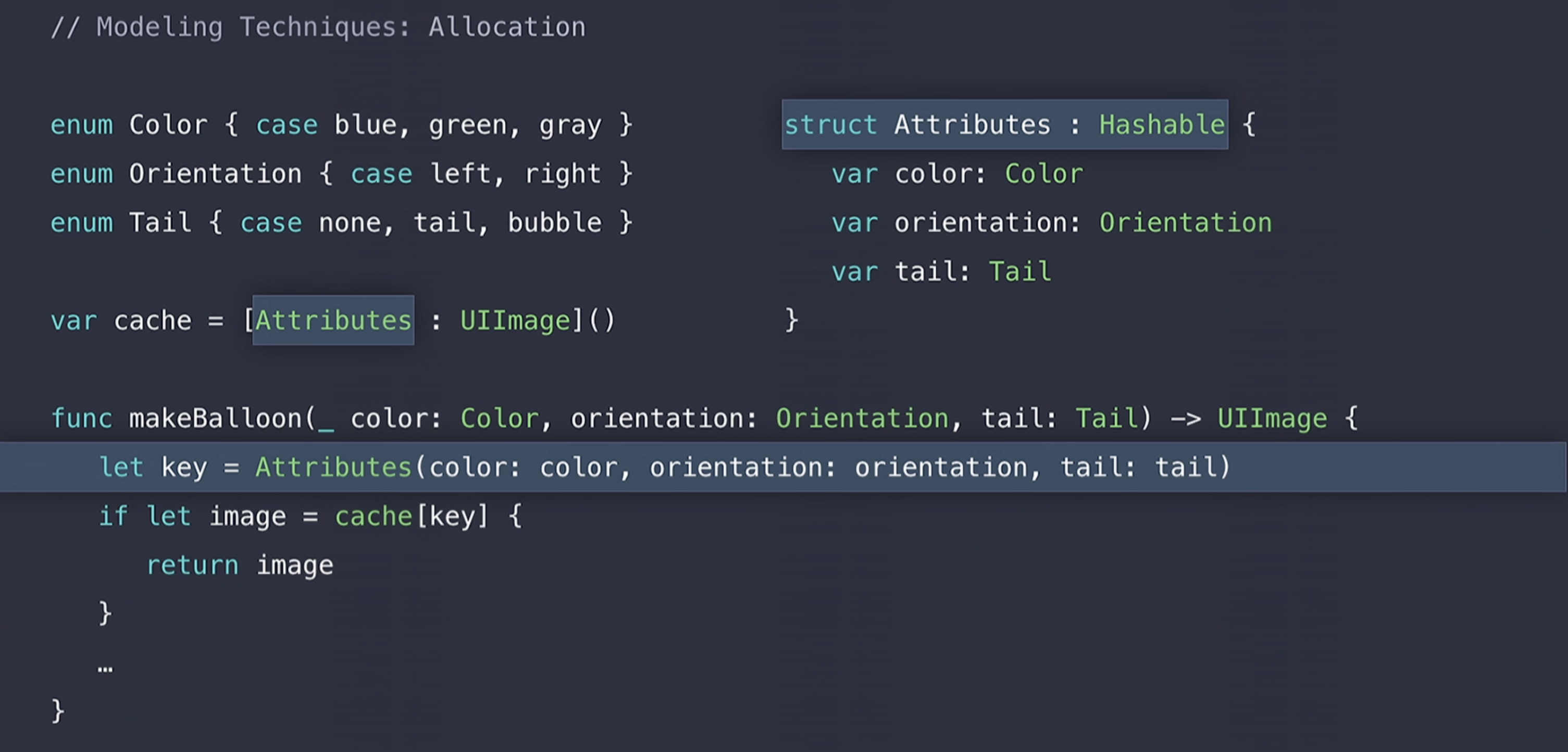
이렇게 하면 이제는 makeBalloon() 메소드 내에서 만약 cache에 hit을 하게 된다면 더 이상 heap allocation overhead는 발생하지 않게 된다. 왜냐하면 Attributes struct를 생성(construct)하는 것은 memory의 stack에 할당 되기 때문에 heap allocation이 될 일이 없다. 따라서 위의 코드는 이전보다 훨씬 빨라지고 안전해 지는 것을 확인해 볼 수 있다.
이번 포스팅에서는 추상화 객체들이 메모리의 어디에 allocation 되는 지에 따라서 성능의 차이를 알아보았고 다음 포스팅에서는 이제 두 번째 측면인 reference counting에 대해서 알아보도록 하겠습니다!!
👉🏻 다음포스팅으로 이동하려면 여기를 눌러주세요!!!
중요❗️❗️❗️
WWDC2016 Understanding Swift Performance를 보면 String 타입은 contents가 heap에 저장이 되기 때문에 heap allocation이 발생할 수 있다라고 나오게 된다. 그러나 실제로 여기 들어가서 확인해보면 string은 value의 크기나 종류에 따라서 stack에 쪼개져서 저장될 수도 있고 heap에 저장될 수도 있다고 한다. 링크에서 다음과 같은 부분을 확인해 볼 수 있다.
Whether this string can provide access to contiguous UTF-8 code units:
- Small strings can by spilling to the stack
- Large native strings can through an offset
- Shared strings can:
- Cocoa strings which respond to e.g. CFStringGetCStringPtr()
- Non-Cocoa shared strings
따라서 String의 contents가 항상 heap에 저장된다고 보장할 수는 없을 것 같다!!
참고
