
지난 포스팅은 WWDC 2016 Understanding Swift Performance 영상에서 메모리 영역의 어느 부분에 allocation을 하는지에 따라서 Swift의 어떠한 성능의 차이가 발생하는지에 대해서 알아보았다.
👉🏻 지난 포스팅이 궁금하다면 여기를 클릭해주세요!!!

이번 포스팅에서는 Swift 에서 추상화를 만들고 추상화 기법을 선택할 때 3가지 측면 중에서 2번째인 Reference Counting에 대해서 알아보자!!
Reference Counting
먼저 reference counting에 대해서 알아보기 전에 지난 포스팅에서 heap에 대해서 이야기 할 때, heap에서 객체를 deallocate하는 과정을 다시 한번 살펴보면 다음과 같이 이야기 했었다.
heap에 할당된 객체들의 사용을 마치고 나면 Swift는 다시 heap을 lock하고(integrity;무결성을 유지하기 위해서) 적절한 위치에 해당 block을 다시 가져다 놓으므로써 할당 해제를 하게 된다.
그렇다면 이때 Swift에서는 어떻게 heap에 할당되어 있는 객체들이 사용되는지 tracking할까?
이에 대한 대답은 reference counting과 관련이 있다. 먼저 Reference counting을 단어 그대로 번역해보면 참조 카운팅, 즉 참조되는 횟수를 카운팅한다는 의미인 것 같은데 실제로 reference counting의 사전적인 의미를 찾아보면 다음과 같다.
참조 횟수 계산 방식(reference counting)은 메모리를 제어하는 방법 중 하나로, 쓰레기 수집의 한 방식이다. 구성 방식은 단순하다. 어떤 한 동적 단위(객체, Object)가 참조값을 가지고 이 단위 객체가 참조(참조 복사)되면 참조값을 늘리고 참조한 다음 더이상 사용하지 않게 되면 참조값을 줄이면 된다. 보통 참조값이 0이 되면 더이상 유효한 단위 객체로 보지 않아 메모리에서 제거한다. - wiki 백과
이에 Swift에서는 ARC(Automatic Reference Counting) 을 사용하여 앱의 memory 사용에 대해서 tracking하고 관리(manage)를 하게 된다. 따라서 개발자인 우리가 직접 사용하지 않는 memory에 대해서 신경쓰고 수거할 필요가 없다.
ARC에 대해서는 나중에 다른 포스팅에서 한번 다룰 예정이니 이번 포스팅에서는 Swift는 ARC를 사용하기 때문에 자동으로 메모리를 관리하고 tracking 하는구나~ 그리고 reference counting이란 메모리의 heap 영역에서 참조되고 있는 객체에 대해서 참조되는 횟수를 카운팅 하는 것 이구나 ~ 정도만 알아두면 될 것 같다.
Swift는 어느 시점에 heap에서 memory를 deallocate할까?
그렇다면 Swift는 언제 heap에서 memory를 deallocate하는 것이 "안전(safe)"한 것인지 어떻게 알 수 있을까? 즉, 해당 객체를 누가 reference하는지 안 하는지에 대해서 어떻게 tracking을 할까?
이것에 대한 답은 Swift는 heap에 있는 모든 객체에 대해서 reference되는 전체 횟수를 count하고 있기 때문에 안전한 시기를 알 수 있다. 그리고 이러한 reference count는 각각의 객체 스스로가 가지고 있으며, 이 count가 0이 되면 Swift는 이제 어떠한 것도 heap에 할당 되어있는 이 객체를 pointing(참조)하지 않는 것을 알게 되고 이 시점에 deallocate를 진행하게 된다.
Reference Counting이 일어날 때 진행되는 일
Reference Counting에서 중요한 부분은 바로 위에서 언급한 객체 스스로가 reference counting을 관리하는 operation이 매우 빈번히 발생하는 operation이며, 이것은 단지 정수 값을 increment, decrement하는 것이 아니라 더 많은 일을 진행한다는 것이다.
- Indirection
- Thread safety overhead
heap에 할당되어 있는 어떠한 객체든 multiple threads로 인해서 동시에 add, remove되는 reference가 발생할 수 있기 때문에, reference count를 atomically하게 increment하거나 decrement해야 한다. 그리고 이러한 reference counting는 매우 빈번히 일어나기 때문에 이를 관리해주는 cost는 더 많이 들게 될 것이다.
❗️여기서 atomically라는 것은 사전적인 의미로는 원자적으로라는 뜻인데, 이는 computer science에서는 원자와 같이 분할할 수 없다는 것을 비유한다. 즉, 원자 조작은 끼어들기가 불가능하며, 만일 중간에 끼어들어서 중지가 된다고 하면 동작을 하기 직전 상태로 시스템을 복귀하는 것을 보증한다는 의미이다.
따라서 atomically하게 increment, decrement를 한다는 것은 하나의 thread에서 reference count를 변경하는 도중에는 다른 thread가 reference count를 건들이지 못하게 보증한다는 것이며, 만일 건들이게 된다면 그 전의 상태로 되돌려 놓는다는 것을 보장한다는 것이다.
Reference Counting - Class Code
지난 포스팅에서 다뤘던 Point 클래스를 다시 한번 보자.
// Reference Counting
// Class (generated code)
class Point {
var refCount: Int
var x, y: Double
func draw() { ...}
}
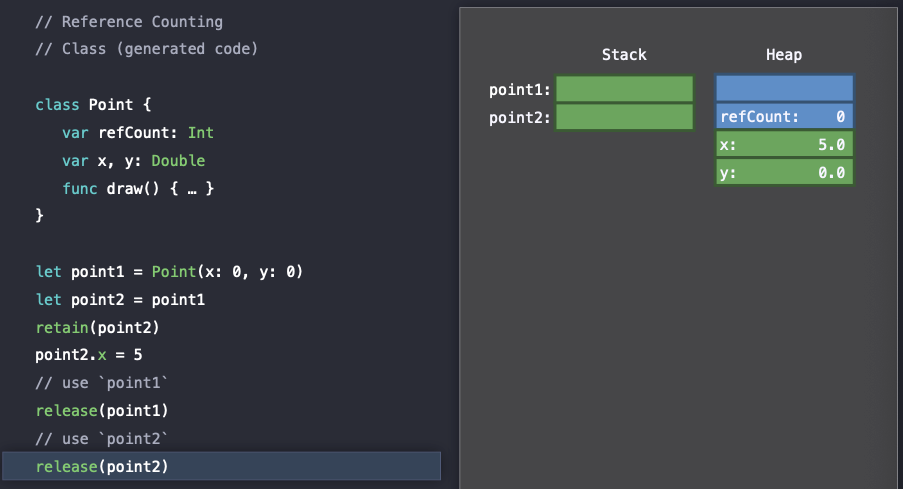
let point1 = Point(x: 0, y: 0)
var point2 = point1
retain(point)
point2.x = 5
// use `point1`
release(point1)
// use `point2`
release(point2)여기서 refCount 라는 property를 생성해주고 retain() , release() 라는 메소드를 실행해 줄 것이다. 이때 retain() 은 atomically하게 referenceCount를 증가시켜 주는 메소드이고, release() 는 atomically하게 referenceCount를 감소시켜주는 메소드이다.
이를 통해서 Swift는 이제 heap에 할당되어 있는 Point 클래스에 대해서 alive reference의 횟수를 tracking 할 수 있을 것이다.
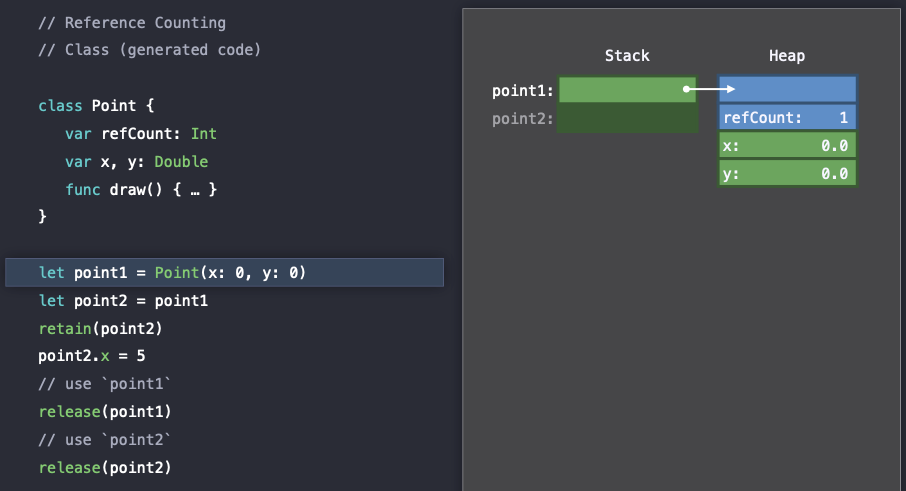 point1 객체가 생성(construct)될 때, refCount가 하나 증가하는 것을 확인해 볼 수 있다.
point1 객체가 생성(construct)될 때, refCount가 하나 증가하는 것을 확인해 볼 수 있다.
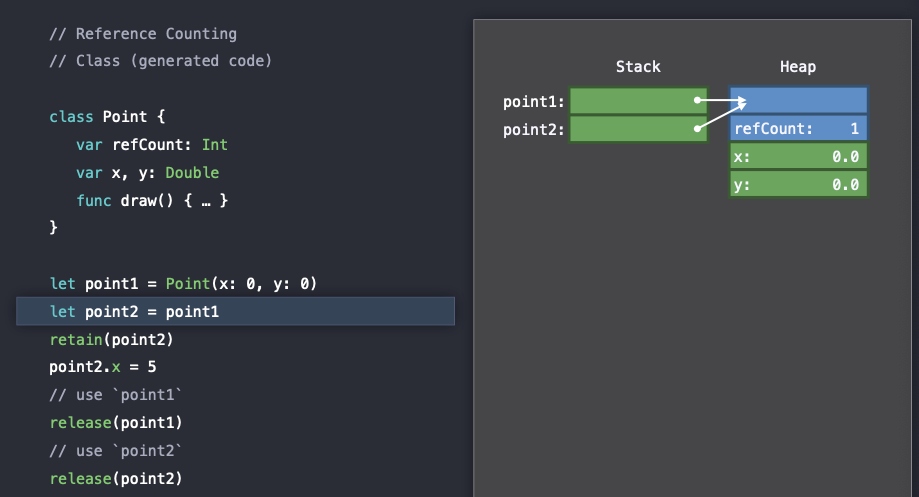 그리고 point2에 point1을 할당함으로써 stack에 있는 reference를 복사하게 된다.
그리고 point2에 point1을 할당함으로써 stack에 있는 reference를 복사하게 된다.
따라서 point1, point2 객체는 heap에서 정확히 같은 객체를 가르키고 있다.
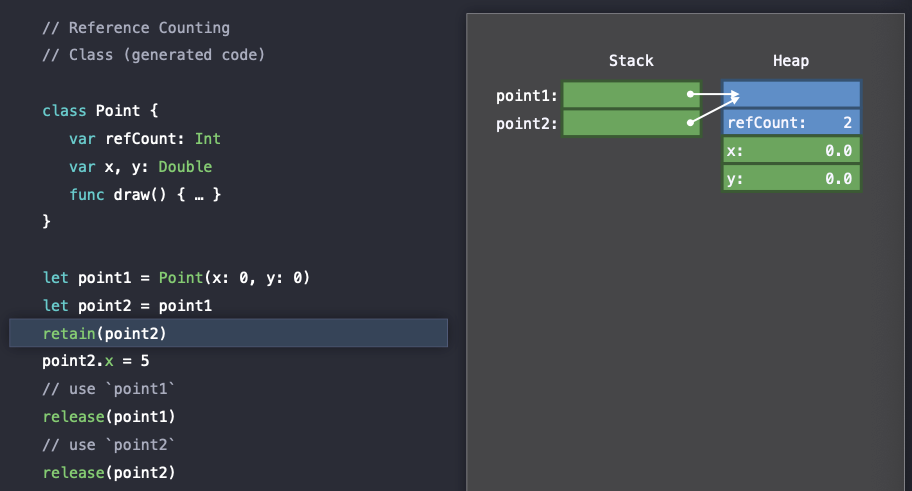 이후에
이후에 retain() 에 의해서 refCount가 atomically하게 하나 더 증가되는 것을 확인할 수 있다.
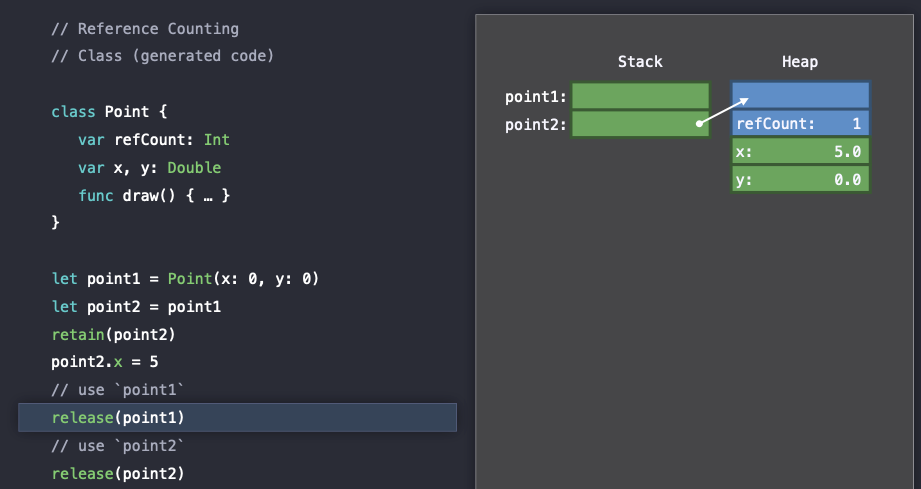 point1의 사용을 마친 뒤에 Swift는
point1의 사용을 마친 뒤에 Swift는 release() 를 호출하여 atomically하게 refCount를 decrement해주게 된다.
 마찬가지로 point2의 사용을 마친 뒤 Swift는
마찬가지로 point2의 사용을 마친 뒤 Swift는 release() 를 호출하여 atomically하게 refCount를 decrement 해준다. 이 시점에서는 더 이상 heap에 있는 point 객체를 reference하는 것이 없기 때문에 Swift는 이제 heap을 lock하고 deallocate, 즉 block of memory를 다시 반납하는 해줘도 안전하다는 것을 알게 된다.
Reference Counting - Struct Code
그렇다면 struct의 경우에는 reference count가 발생할까?
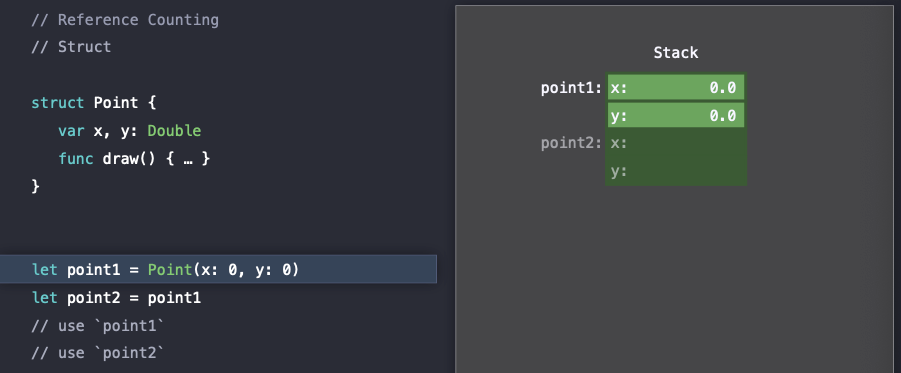 point1 struct를 생성(construct)할 때는 heap allocation은 발생하지 않는다.
point1 struct를 생성(construct)할 때는 heap allocation은 발생하지 않는다.
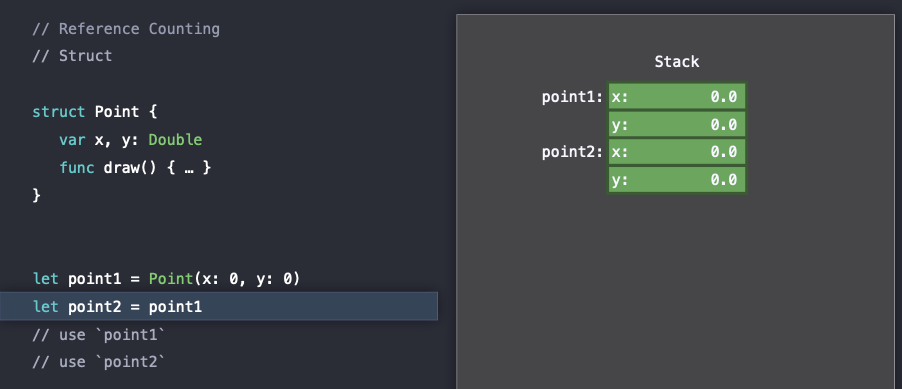 또한 point2에 point1을 할당하여 값을 복사할 때에도 heap allocation은 발생하지 않는다.
또한 point2에 point1을 할당하여 값을 복사할 때에도 heap allocation은 발생하지 않는다.
즉, point struct에서는 reference counting overhead가 발생하지 않게 된다.
Reference Counting - Complex Struct Code
하지만 좀 더 복잡한 struct의 경우에는 어떠할까?
다음과 같은 예시를 보자
// Reference Counting
// Struct containing references
class Label {
var text: String
var font: UIFont
func draw() { ...}
}
let label1 = Label(text:"Hi", font: font)
let label2 = label1
// use `label1`
// use `label2`text라는 String 타입과 font라는 UIFont 타입을 포함하고 있는 Label이라는 struct가 있다.
String 은 저번 포스팅에서도 언급했듯이 내용의 character들을 heap에 저장하게 된다.
따라서 이 경우에는 reference count가 발생하게 된다.
또한 font는 UIFont 라는 class 타입이므로 이 또한 reference count가 필요하다.
❗️ 즉, String 은 내용이 heap에 저장되므로 reference count 계산 필요
❗️ UIFont 는 class이므로 heap에 allocate 되므로 reference count 계산 필요
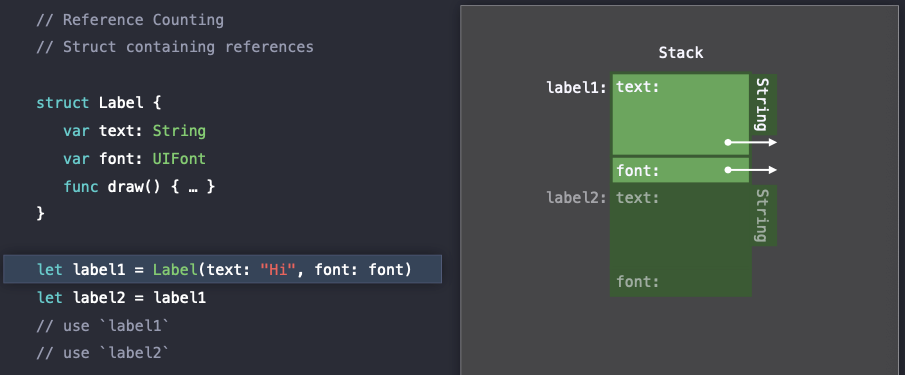 따라서 label1은 메모리에서 2개의 reference를 가지게 된다.
따라서 label1은 메모리에서 2개의 reference를 가지게 된다.
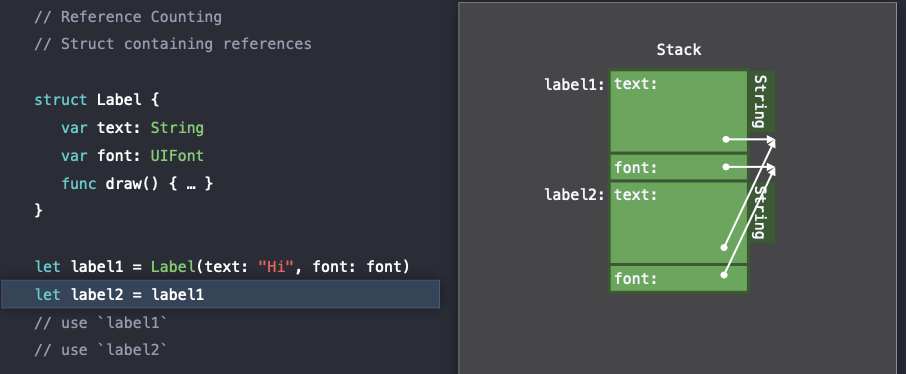 그리고 label2에 label1을 할당하게 되면 값을 복사하게 되는데, label1이 가르키는 reference를 같이 가르키게 된다. 이때 Swift에서 여기서 발생하는 reference들을 tracking하기 위해서
그리고 label2에 label1을 할당하게 되면 값을 복사하게 되는데, label1이 가르키는 reference를 같이 가르키게 된다. 이때 Swift에서 여기서 발생하는 reference들을 tracking하기 위해서 retain() 과 release() 를 사용하게 된다.
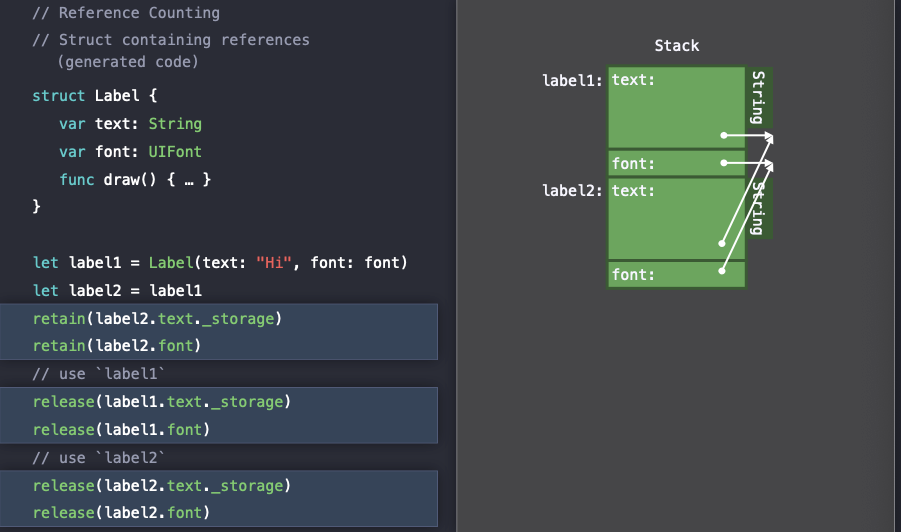 따라서 위의 그림처럼 label 객체들은 struct 타입임에도 불구하고 2번의
따라서 위의 그림처럼 label 객체들은 struct 타입임에도 불구하고 2번의 retain() , release() 를 해주어야하는 reference counting overhead를 발생시키는 것을 확인할 수 있다.
 정리를 하자면 class는 heap에 allocate 되기 때문에 Swift는 heap에 allocate 된 객체들의 lifetime을 관리해 주어야만 하는데, 이때 reference counting도 함께 관리된다.
정리를 하자면 class는 heap에 allocate 되기 때문에 Swift는 heap에 allocate 된 객체들의 lifetime을 관리해 주어야만 하는데, 이때 reference counting도 함께 관리된다.
이러한 과정은 매우 중요한데 왜냐하면 reference counting operation은 매우 빈번히 일어나며 atomically하게 관리되어야하기 때문이다.
 따라서 위와 같은 이유로 우리는 class 보다는 struct를 사용해야 할 이유가 하나 더 추가되었다.
따라서 위와 같은 이유로 우리는 class 보다는 struct를 사용해야 할 이유가 하나 더 추가되었다.
 그러나 만약 struct가 위의 예시처럼 reference를 포함한다면 위의 사진과 같이 struct내에서 reference를 하는 개수만큼 referece counting overhead에 대해서 비용을 지불해야할 것이다.
그러나 만약 struct가 위의 예시처럼 reference를 포함한다면 위의 사진과 같이 struct내에서 reference를 하는 개수만큼 referece counting overhead에 대해서 비용을 지불해야할 것이다.
 그리고 만약 struct에 reference가 1개 보다 많다면 이러한 struct는 위의 그림처럼 class보다 더 많은 reference counting overhead를 가지게 될 것이다.
그리고 만약 struct에 reference가 1개 보다 많다면 이러한 struct는 위의 그림처럼 class보다 더 많은 reference counting overhead를 가지게 될 것이다.
Modeling Techniques: Reference Counting
WWDC2016 영상에서는 다른 예시를 더 보여주었는데 같이 살펴보자.
// Modeling Techniques: Reference Counting
struct Attachment {
let fileURL: URL
let uuid: String
let mimeType: String
init?(fileURL: URL, uuid: String, mimeType: String) {
guard mimeType.isMimeType
else { return nil }
self.fileURL = fileURL
self.uuid = uuid
self.mimeType = mimeType
}
}지난 포스팅에서 예시로 들었던 문자 메시지에 이어서 다음과 같은 Attachment라는 struct 타입이 있다고 하자. 사용자들이 text message만 보내는 것에 만족하지 못하고 이미지와 같은 첨부파일을 보내길 희망해서 다음과 같은 Attachmemt는 타입을 만들게 되었다고 하자.
이 Attachment struct는 fileURL, uuid, mimeType이라는 프로퍼티를 가진다.
fileURL은 디스크에서 첨부파일 data의 저장 경로를 저장하는URL 타입이며 uuid는 랜덤하게 생성되는 unique한 식별자로 서버나 client에서 식별할 수 있는String 타입을 가진다. 마지막으로 mimeType은 해당 첨부파일이 JPG, PNG, GIF와 같이 어떠한 확장자를 가지는지에 대한 String 타입을 가진다.
그리고 여기서는 실패할 수 있는 init?() 을 사용하였는데 이는 만약 초기화 될 때 들어오는 mimeType이 자신의 앱에서 사용가능한 mimeType 형식이 아니라면 초기화를 하지 않고 nil값을 반환해주는 생성자이다. 그렇지 않고 만약 mimeType이 지원되는 타입이라면 정상적으로 초기화를 진행할 것이다.
여기서 URL 타입은 아래 그림에서 확인할 수 있듯이 struct 타입이지만 init()을 보면 String 타입을 받아서 하므로 결국 heap에 저장되게 된다.
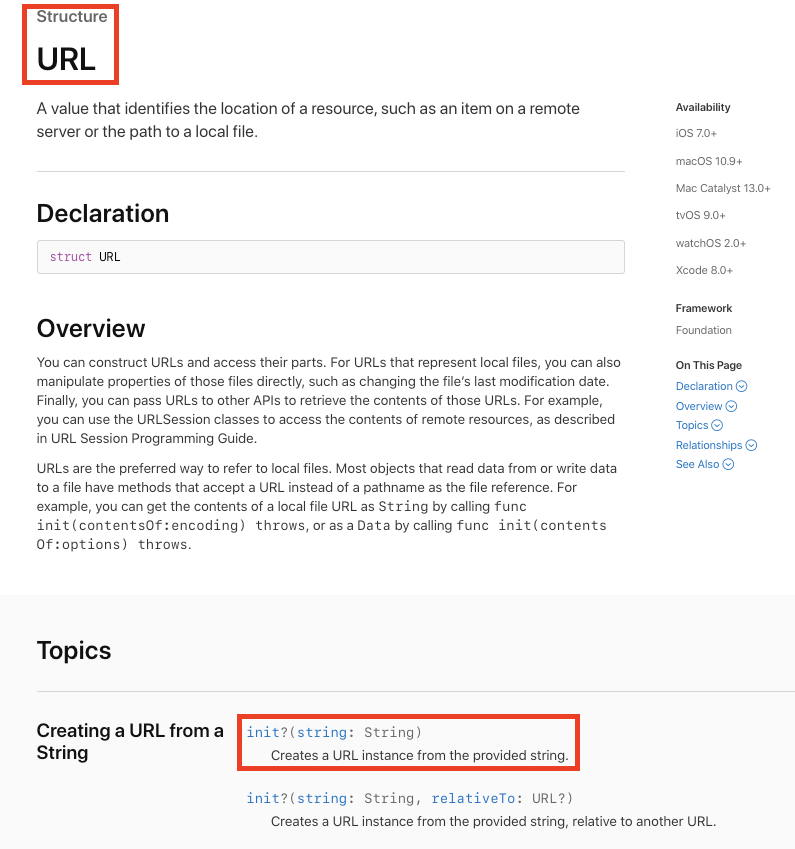 또한 uuid, mimeType도
또한 uuid, mimeType도 String 타입이므로 Attachment는 구조체임에도 불구하고 무려 3개의 property가 heap에 저장이 되고, reference count overhead가 발생하게 되겠네요... ㄷㄷ
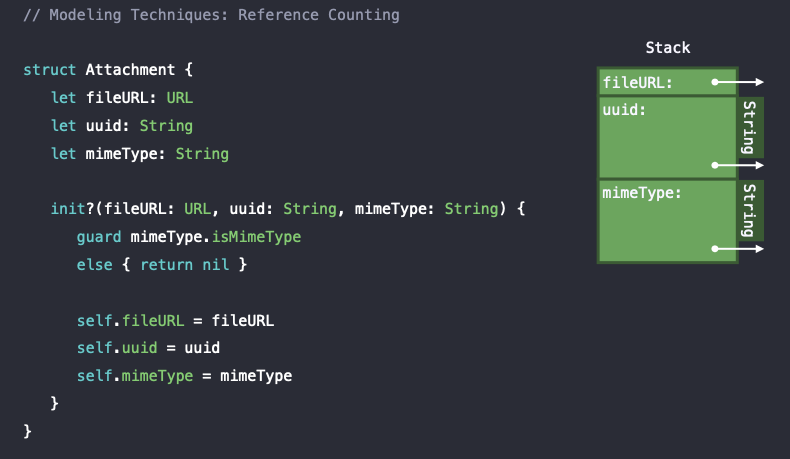 따라서 다음과 같이 Attachment 구조체는 3개의 reference가 생기게 되고 이를 줄일 수 있는 방법에 대해서 이제 알아보도록 하자.
따라서 다음과 같이 Attachment 구조체는 3개의 reference가 생기게 되고 이를 줄일 수 있는 방법에 대해서 이제 알아보도록 하자.
uuid: String -> UUID
먼저 uuid 프로퍼티는 128bit의 랜덤한 값을 가지게 되는 식별자이다. 그리고 우리는 실제로 uuid field에 아무 값이나 들어가는 것을 원치 않는다. 그러나 String 타입인 경우에는 지난 포스팅에서도 이야기 했듯이 안전성에서의 문제가 발생할 수 있다. 예를 들어 강아지 이름인 Cookie와 같은 값도 uuid로 들어갈 수도 있기 때문이다.
iOS6부터 UUID 라는 128bit 식별자를 struct에 직접 저장하는 새로운 value type이 생겼기 때문에 String -> UUID 타입으로 변경해주면 uuid 프로퍼티를 heap에 할당할 필요가 없어지게 된다. 또한 UUID 타입으로 변경하므로써 uuid만 넣어줄 수 있기 때문에 안정성 문제도 해결이 되게 된다.
mimeType: String -> MimeType(enum)
다음으로는 이제 mimeType으로 넘어가서 이를 개선해보도록 하자.
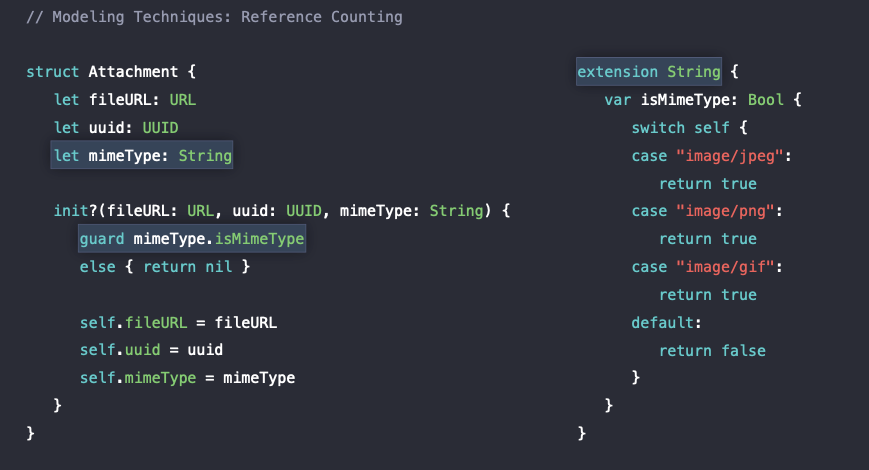 먼저 isMimeType은 jpeg, png, gif인 경우를 체크하여 bool 값을 반환해주는 연산 프로퍼티로
먼저 isMimeType은 jpeg, png, gif인 경우를 체크하여 bool 값을 반환해주는 연산 프로퍼티로 String 타입에 extension 되어있었는데 Swift는 사실 이러한 제약이 있는 값들에 대해서 묶을 수 있는 enum 이라는 타입이 존재한다.
따라서 아래의 그림과 같이 enum 타입으로 변경시켜주고 여기에도 실패가능한 init?()을 사용하여 case로 지정된 타입이나 nil 값을 반환해주도록 하였고 mimeType을 String 타입에서 enum 타입인 MimeType 으로 변경해주었다.
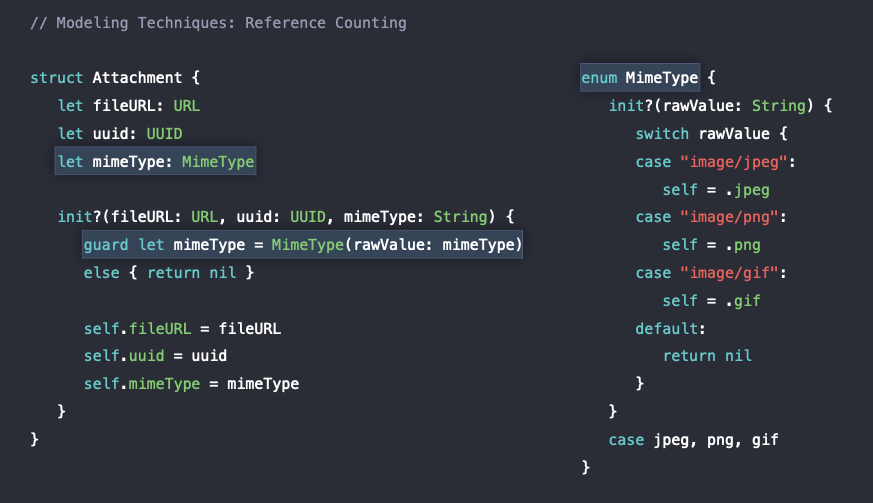 Swift는 이러한 enum 타입 뒤에 String을 붙여줌으로서 다음과 같이 코드를 좀 더 깔끔하게 사용할 수 있다.
Swift는 이러한 enum 타입 뒤에 String을 붙여줌으로서 다음과 같이 코드를 좀 더 깔끔하게 사용할 수 있다.
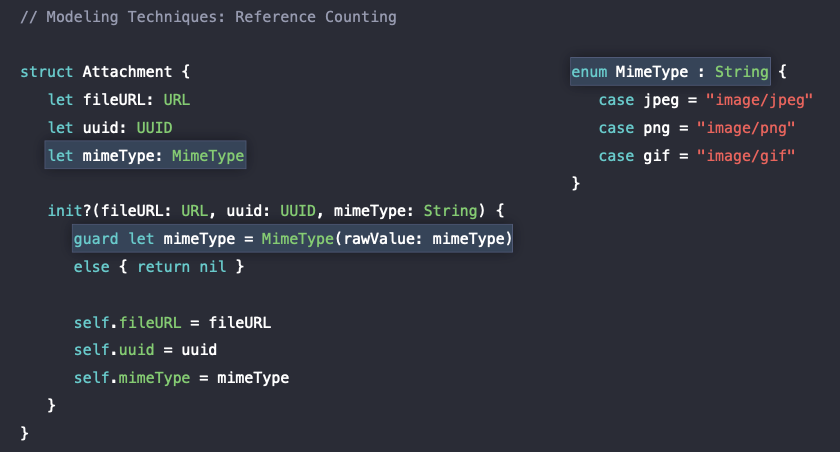 이렇게 변경된
이렇게 변경된 enum 타입은 struct와 마찬가지로 값 타입이며 case들은 heap에 저장이 되지 않게 된다. 즉,String 에서 enum 타입으로 변경되면서 heap allocation이 발생하지 않게 된다.
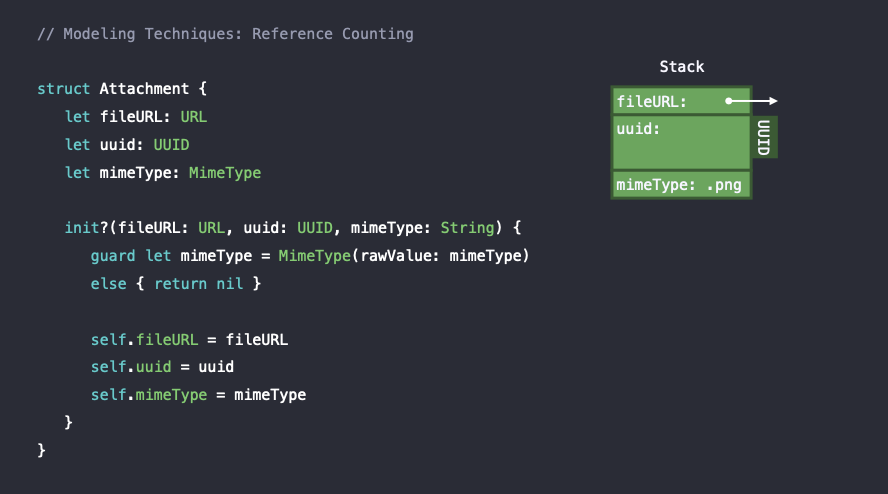 따라서 기존의 코드에서는 uuid와 mimeType도 String이었기 때문에 heap allocation이 필요했었다면 개선된 코드에서는 fileURL 하나만 heap allocation을 하게 된다.
따라서 기존의 코드에서는 uuid와 mimeType도 String이었기 때문에 heap allocation이 필요했었다면 개선된 코드에서는 fileURL 하나만 heap allocation을 하게 된다.
이런 식의 코드 개선을 통해서 Attachment는 struct 타입으로 사용해도 될 이유가 생기는 것이다.
이번 포스팅에서는 reference counting은 무엇이며, struct와 class일 때 발생하는 reference count 그리고 struct에서 reference count를 줄이도록 코드를 개선하는 방법에 대해서 포스팅하였고 다음 포스팅에서는 이제 마지막 측면인 method dispatch 에 대해서 알아보도록 하겠습니다!!
👉🏻 다음 포스팅이 궁금하시면 여기를 눌러주세요!
중요❗️❗️❗️
지난 포스팅을 보지 않고 이번 포스팅만 보시는 분들도 있을까봐 다시 한번 작성해요:)
WWDC2016 Understanding Swift Performance를 보면 String 타입은 contents가 heap에 저장이 되기 때문에 heap allocation이 발생할 수 있다라고 나오게 된다. 그러나 실제로 여기 들어가서 확인해보면 string은 value의 크기나 종류에 따라서 stack에 쪼개져서 저장될 수도 있고 heap에 저장될 수도 있다고 한다. 링크에서 다음과 같은 부분을 확인해 볼 수 있다.
Whether this string can provide access to contiguous UTF-8 code units:
- Small strings can by spilling to the stack
- Large native strings can through an offset
- Shared strings can:
- Cocoa strings which respond to e.g. CFStringGetCStringPtr()
- Non-Cocoa shared strings
따라서 String의 contents가 항상 heap에 저장된다고 보장할 수는 없을 것 같다!!
참고
