Diffusion model
Diffusion model
Diffusion model 에 대해 간략하게 설명하겠다.
노이즈로부터 이미지를 생성하는 모델이다.
Forward process와 Reverse process를 활용하여 학습한다.
Forward Process
Data()로부터 표준정규분포() 방향으로 Noise를 조금씩 더해가는 과정이다.
표준정규분포 방향으로 노이즈를 만큼 섞어간다.
Reverse Process
완전한 노이즈()에서 시작하여 노이즈를 걷어내며, 다시 이미지()로 돌아가는 과정이다.
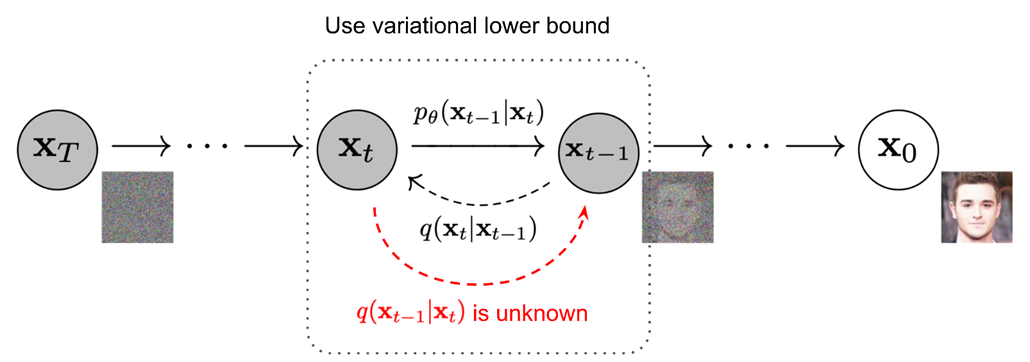
Training
특정 시점()을 랜덤 샘플링 하여 원본()과 단계 노이즈 이미지() 사이의 노이즈()를 예측하도록 학습한다.
- Random Sampling: 단계부터 단계 중 아무 숫자나 하나(예: 단계)를 무작위로 뽑는다.
- Forward Process: 가우시안 분포의 성질을 이용해, 원본()에서 곧바로 단계 노이즈 이미지()를 만들어 낸다.
- Prediction: 모델에게 를 보여주고 노이즈를 예측하도록 시킨다.
- Loss Calculation: 모델이 예측한 노이즈()와 실제로 넣은 노이즈()를 비교해서 오차를 줄인다.
Inference
학습된 모델을 사용하여 완전한 노이즈(단계)부터 단계까지 순차적으로 노이즈를 제거한다.
- 랜덤 노이즈(예: 단계)에서 시작한다.
- 모델: 단계 노이즈 예측 및 제거 단계 된다. (실제 모델 예측은 예측)
- 모델: 단계 노이즈 예측 및 제거 단계 된다.
... - 모델: 단계 노이즈 예측 및 제거 원본() 완성한다.
실제 모델 예측은 0단계로부터 섞인 n단계의 노이즈를 예측한다.
하지만, 한 번에 노이즈를 제거하는 것보다 단계별로 한 단계씩만 이동하는게 더 정밀한 결과를 낼 수 있어서 여러 단계에 걸쳐 노이즈를 제거한다.
Model Architecture
-
Reverse Process를 위한 모델 구조
-
기본적으로는 UNet 구조를 쓰며, 본 논문에서도 UNet 구조를 사용한다.
- 입력 (Input): 노이즈 낀 이미지 ()
- 출력 (Output): 예측된 노이즈 ()
Image Prompt Adapter
- 이미지와 텍스트를 입력하여 생성되는 이미지를 조정할 수 있다.
- 이미지와 텍스트들은 UNet 중간중간 Cross Attention을 통해 주입되어 이미지 생성에 관여할 수 있다.
- 아래는 예시 구조로 Frozen, Trainable은 무시해도 된다.
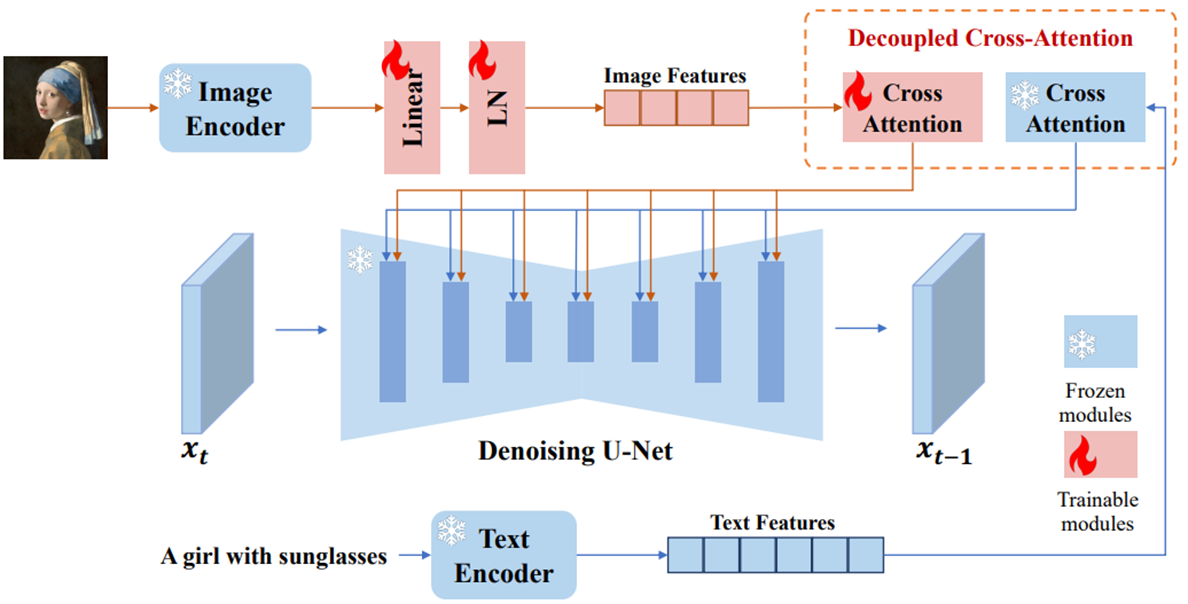
Cross Attention
- Input을 제외하면 Self Attention과 차이가 나지 않는 동일한 계산 방법이다.
- 서로 다른 Input 에 대해 Attention 연산 시 에서 생성된 를 사용하고, 에서 생성된 를 사용하여 연산하는 방법이다.
- Query (): 이미지의 특징 (UNet 내부 Feature)
- Key () & Value (): 프롬프트(텍스트) 임베딩 또는 이미지 임베딩
Video Diffusion
-
원론적으로는 이미지 생성 때와 같지만, 시간 축을 하나 더하여 이미지 한 장의 노이즈가 아니라 장의 전체 프레임 노이즈를 예측하도록 한다.
- 이미지: (채널, 높이, 너비)
- 비디오: (프레임 수, 채널, 높이, 너비)
-
이렇게 되면 기본 UNet 구조에서의 2D Convolution이 3D Convolution이 되어야 하지만, 이것은 계산 복잡도가 급격히 늘어나 비효율적이다.
-
하여 시공간을 분리한 Convolution 연산을 따로 진행한다.
- Spatial Convolution (2D): 각 프레임을 독립적인 이미지로 보고 특징을 추출
- Temporal Convolution (1D): 공간 정보()는 고정한 채, 시간 축()으로만 연산을 수행
