[Paper Review]RoboDreamer: Learning Compositional World Models for Robot Imagination!
Paper Review
RoboDreamer: Learning Compositional World Models for Robot Imagination 이라는 논문이다.
읽기 전에 아래 Diffusion model을 이해해야 이 논문을 이해할 수 있다.
https://velog.io/@minnnn/Diffusion-model
INTRODUCTION
RoboDreamer: Learning Compositional World Models for Robot Imagination(ICML 2024)
Siyuan Zhou, Yilun Du, Jiaben Chen, Yandong Li, Dit-Yan Yeung, Chuang Gan
인용수
96회(2025년 12월 기준)
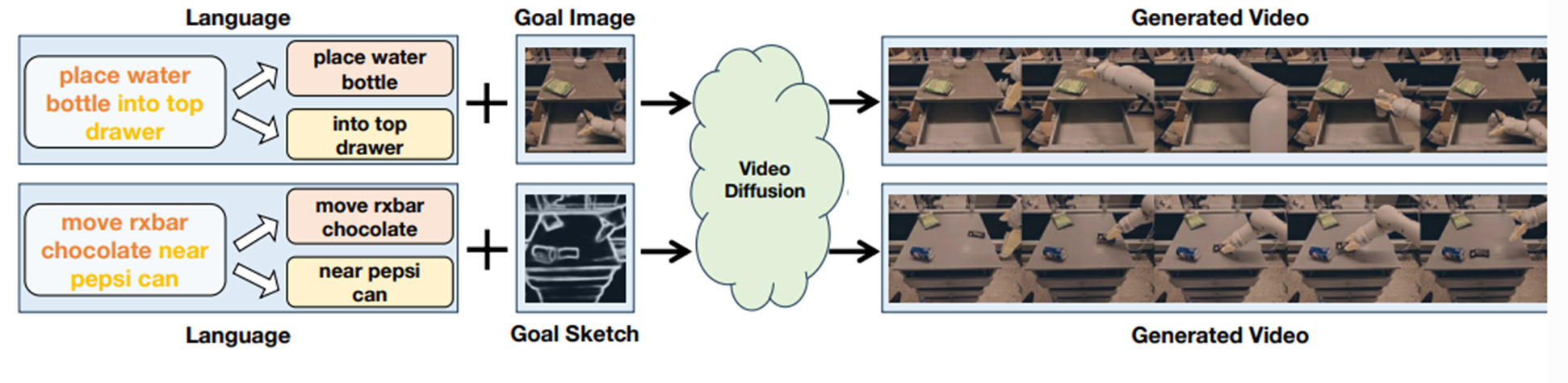
비디오 생성 모델로 비디오를 생성하고 비디오로부터 액션을 예측하는 파이프라인으로 구성되어있다.
텍스트, 목표 이미지(혹은 스케치)로부터 비디오를 생성한다.
그리고 그 비디오로부터 액션을 생성하는 과정이다.

- "Pick pepsi can from bottom drawer"
목표이미지와 텍스트가 주어지면 영상을 생성한다.
비디오 생성 하는 것에 초점을 맞춘 논문이다.
텍스트를 의미론적으로 파싱하고, 목표 이미지와 함께 diffusion model에 주입하는 것이 논문의 핵심 아이디어이다.
텍스트를 파싱하여 학습하기 때문에 새로운 텍스트 조합에 대해 일반화 성능 증가시키낟.
ROBO DREAMER
로봇의 작업 명령어를 Primitives(기본 요소)로 분해한다.
텍스트 행동 지시사항 L이 주어지면, 일련의 동사구와 전치사구 𝑙_𝑖로 분해한다.
사전학습된 텍스트 파서를 이용하여 텍스트 파싱을 진행한다.
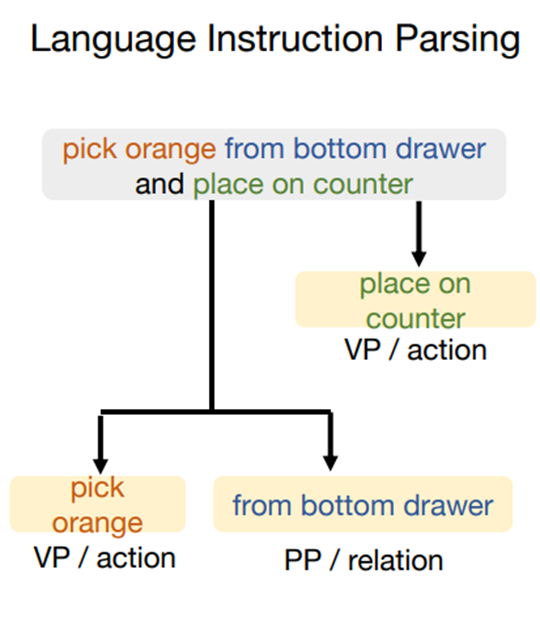
텍스트 파서 모델은 오픈 소스를 사용했다.
https://github.com/nikitakit/self-attentive-parser
분해된 명령을 텍스트-비디오 생성모델에 입력한다.
Compositional Generation
각 파싱된 언어 하위 구성 요소 {𝑖=1:𝑁}에 대해 개별 생성 모델들의 곱(product)으로 예측할 것을 제안한다.
이러한 방식은 자연어 지시사항 L의 보지 못한 조합이 주어졌을 때 일반화를 가능하게 한다고 한다.
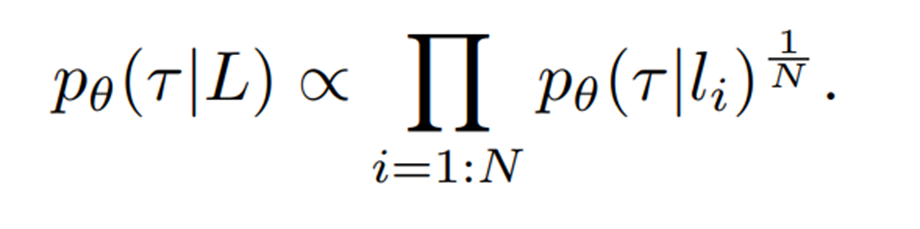
Noise Prediction
- 앞서 Reverse Process에서 노이즈를 예측한 것 처럼 파싱된 모든 명령어로 각각 노이즈들을 예측 후 평균낸다.
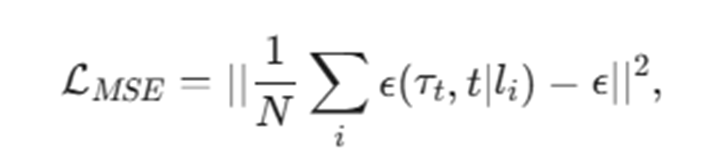
하지만 위 방식은 텍스트 L이 주어졌을 때 노이즈 예측을 하도록 학습하지만 구성요소 𝑙_𝑖 만이 주여졌을 때 올바른 예측을 하도록 학습되진 않는다.
-
하여, 단일 구성요소만 주어졌을 때 노이즈를 예측하게 끔 훈련시키는 식은 다음과 같다.
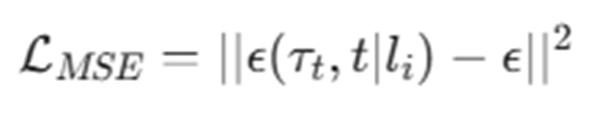
하지만 이러한 방식은 여러 𝑙_𝑖 를 조합하였을 때, 동작한다는 보장이 없다. -
Hybrid
앞선 두 방식을 결합하여, 무작위 부분집합이 주어졌을 때 노이즈를 예측하게 끔하여 일반화 성능을 보장하도록 한다.
M: Subset의 구성요소 수
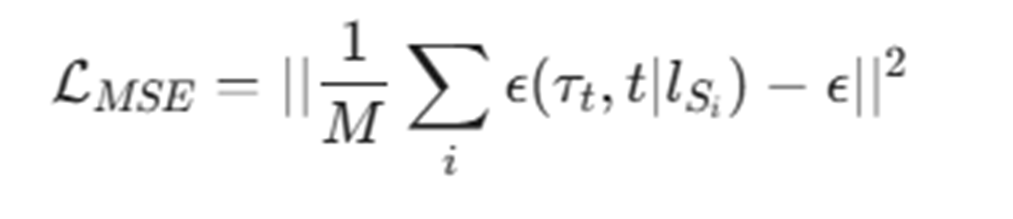
Training Process
앞서 설명한 Hybrid 방식을 사용하여 Diffusion Model 기존 학습 방법대로 학습을 진행한다.

Inference Process
Unconditional Prediction: 어떠한 조건(텍스트, 목표 이미지)의 주입 없이 노이즈 를 예측한다.
Final Noise Calculation: 각 조건별 예측을 통합하여 가중치 를 곱해 최종 노이즈()를 생성한다.
Denoising: 위에서 계산된 최종 노이즈를 바탕으로 디노이징을 적용하여, 노이즈가 걷혀진 비디오를 생성한다.
Loop: 노이즈가 완전히 걷혀질 때까지 이 과정을 반복한다.

Multi-modal Composition
- 언어 지시사항 ()을 조건화하는 것에 더해,
- 멀티모달(목표 이미지 등) 지시사항 ()을 조건화할 수도 있음.
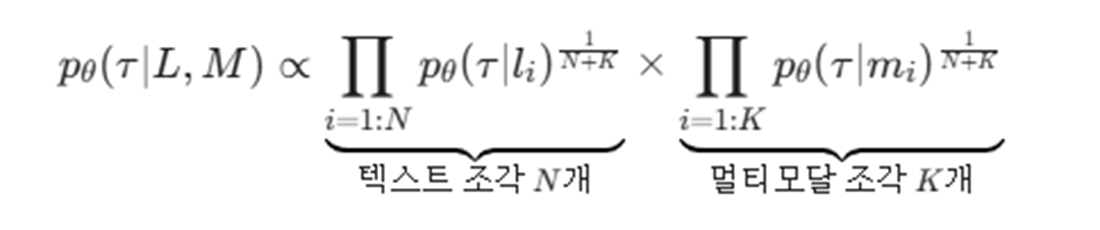
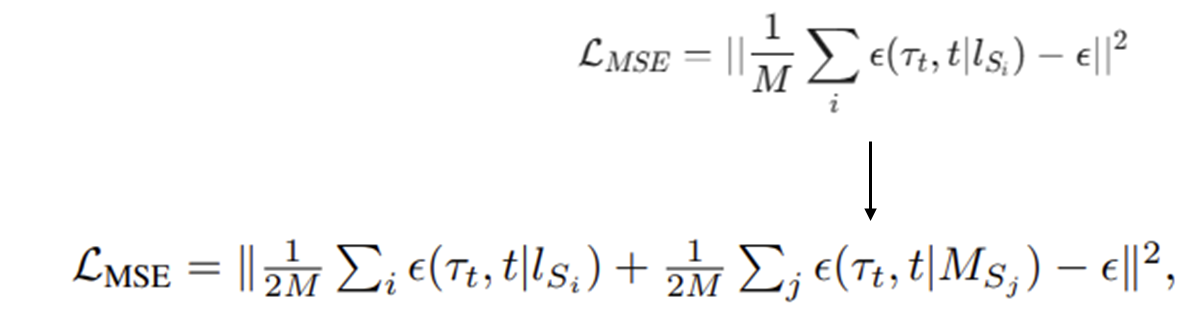
Implementation Details
-
AVDC와 Imagen을 기반으로 구축되었으며, super-resolution를 위해 3단계 cascaded diffusion model 활용
-
U-Net 내에 4개의 ResNetBlock을 사용하며, 각 블록은 시공간 컨볼루션 레이어와 지시사항이 조건화된 cross-attention레이어로 구성
-
U-Net 인코더의 마지막 블록과 디코더의 첫 번째 블록에 temporal-attention 레이어를 도입
시간 단위 Frame들을 묶어서 attention연산 -
한 비디오 내의 모든 프레임의 배경은 일관되어야 하므로, 첫 프레임을 U-Net에 입력하기 전에 모든 노이즈 프레임에 Concat
(기존 노이즈 3채널) + (첫 장면 이미지 3채널) = 6채널 -
목표 이미지와 스케치를 위해서는 Stable Diffusion의 VQVAE에서 사전 학습된 이미지 인코더 사용
-
모든 modality의 임베딩은 일반적인 입출력을 위해 설계된 아키텍처인 PerceiverSampler에 입력
PerceiverSampler: 어떤 크기의 입력이 들어오든, 항상 고정된 개수(N개)의 토큰으로 변환해 주는 어댑터 -
텍스트 인코더로는 사전 학습된 T5-XXL
-
역동역학 모델(Inverse Dynamics Model):
- 역동역학 모델은 인접한 두 프레임과 현재 상태가 주어졌을 때 action을 예측하도록 훈련
- 백본으로 ResNet18을 사용하고 그 뒤에 MLP 레이어를 사용
EXPERIMENTS
실험은 다음 질문들에 답할 수 있도록 구성되어 있다.
RQ1: RoboDreamer는 보지 못한 작업 지시사항에 직면했을 때 제로샷 일반화 비디오 생성 능력을 갖추고 있는가?
RQ2: 멀티모달 지시사항의 구성적 생성이 비디오 생성의 공간적 추론과 객체 관계를 향상시키는가?
RQ3: RoboDreamer를 로봇 조작 작업에 배포할 수 있는가?
Evaluation on Video Generation
비디오 생성 평가한다.
실험 설정
- 실제 로봇 데이터셋인 RT-1을 사용하여 비디오 생성을 평가
- 다양한 로봇 조작 작업들(예: “갈색 칩 봉지를 중간 서랍에서 꺼내라”)로 구성되어 있음
- 약 70,000개의 데모와 500개의 서로 다른 작업에 대해 훈련
- unseen 테스트 케이스로서 언어 지시사항을 무작위로 선택
- 공정한 비교를 위해, 언어 지시사항만을 제공하여 실험
- 텍스트 인코더로는 사전 학습된 T5-XXL로 통일
베이스라인
- AVDC(Ko et al., 2023): 로봇 공학을 위한 비디오 생성 모델
- HiP(Ajay et al., 2023): 로봇 공학을 위한 latent video diffusion 모델
- RoboDreamer w/o: 텍스트 파싱 접근 방식이 없는 본 논문 모델
Metrics
일부 연구들은 비디오 생성과 작업 지시사항 사이의 매칭을 평가하기 위한 적절한 지표가 여전히 없음을 시사한다고 한다.
각 샘플은 최소 3명 이상의 사람들에게 작업 완료 여부를 판단한다.
점수는 0 또는 1이며, 0은 생성된 비디오의 로봇 계획이 작업 해결에 실패했음을 의미하고, 1은 로봇 계획이 실행 가능하며 작업 완료에 성공했음을 의미한다.
Zero-shot Generalization(Q1)
Unseen 작업 지시사항이 주어졌을때 제로샷 일반화 능력을 가져오는지 평가했다.

Multi-modal Generation(Q2)
멀티모달 조건화 비디오 생성 능력을 평가한다.
마지막 프레임을 목표 이미지로 사용한다.
ControlNet를 통해 목표 스케치를 생성한다.
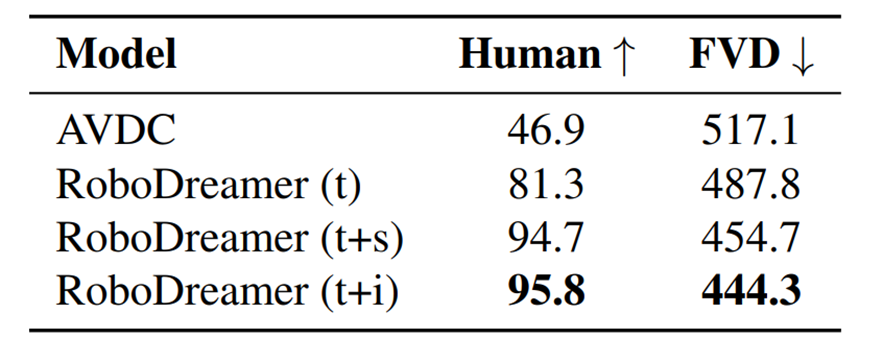
RoboDreamer (t+s)와 (t+i)는 인간 평가(Human)에서 강력한 성능을, 비디오 품질(FVD)에서 좋은 결과를 달성했다.
- RoboDreamer(t): 언어 설명만 제공됨.
- RoboDreamer(t+i): 언어 설명과 목표 이미지가 제공됨.
- RoboDreamer(t+s): 언어 설명과 목표 스케치가 제공됨.
RoboDreamer가 합성한 비디오가 로봇 계획을 수행할 수 있는지(Q3)
비디오 생성 평가한다.
실험 설정
- RLBench 시뮬레이션 환경에서 실험을 수행
- Franka Panda 제어
- 총 74개의 도전적인 비전 기반 로봇 학습 Tool-using, Pick-and-Place, Long-term planning 등 태스크
- 오직 전면 카메라 이미지만 관측
- 공정한 비교를 위해 목표 이미지 없이 텍스트 지시사항만 제공
베이스라인
- Image-BC: 관측, 상태, 목표 설명이 주어지는 모방 학습 접근 방식
- Hiveformer: 자연어, 다중 시점 관측, 행동 이력을 통합하는 트랜스포머 기반 모델
- UniPi: 텍스트-비디오 모델로 비디오를 생성하고, 역동역학 정책으로 행동을 예측하는 방식 (RoboDreamer와 가장 유사한 비교군)

Conclusion
비디오 생성 분야에서 이전 연구들보다 훨씬 잘 일반화되는 비디오 생성에 대한 구성적 접근 방식인 RoboDreamer를 소개했다.
RoboDreamer는 복잡한 공간 관계와 객체 상호작용을 정확하게 포착하는 비디오 생성에 있어 상당한 진전이 있었다고 한다.
한계점:
- 많은 로봇 작업이 다중 카메라 정보를 자주 사용함에도 RoboDreamer는 단일 카메라 뷰로 제한되어 있어 다중 카메라 정보를 고려할 수 없다.
- RoboDreamer는 테스트한 많은 real-world 이미지에 대해 일반화 성능이 좋지 않다.
- 기존 로봇 데이터셋의 다양성이 여전히 제한적이라고 생각한다.
- 일반화를 개선하기 위해 로봇 데이터와 YouTube의 기존 비디오 전반에 걸친 구성적 모델의 co-training을 탐구하는 것이 흥미로울 수 있다.
- 본 모델을 포함한 비디오 생성 모델들의 능력은 이동식 카메라 설정에서 제한된다.
