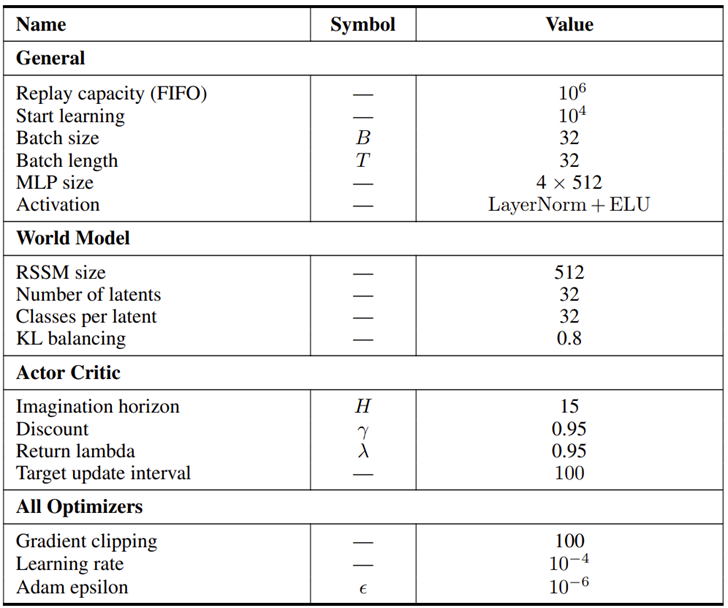
Introduction
https://arxiv.org/abs/2206.14176 - 논문
https://github.com/danijar/daydreamer - 코드 공개
Philipp Wu, Alejandro Escontrela, Danijar Hafner, Ken Goldberg, Pieter Abbeel
University of California, Berkeley
인용수
449회(2025년 11월 기준) 
DayDreamer
시뮬레이터 훈련 없이 실제 환경에서 스크래치 모델 학습을 진행했다.
- 4족 보행 로봇이 뒤집힌 상태에서 일어나 걷기까지 단 1시간 만에 학습했다.
- 3인칭 카메라 이미지만으로 3개의 공을 인식해 집어서 다른 통으로 옮기는 작업
- 8시간의 자율 학습 후, 분당 평균 2.5개의 물체를 집는 속도에 도달
- RGB와 Depth 카메라로 부드러운 물체를 집어 옮기는 작업
- 10시간 이내에 분당 평균 3.1개의 물체를 집는 속도를 달성
- 상단의 카메라 이미지만 보고 목표 지점까지 이동하는 시각적 내비게이션 작업
- 2시간 이내에 목표 지점으로 빠르고 일관되게 이동하는 정책을 학습
 |  |
|---|
Danijar Hafner의 dreamer 시리즈 중 dreamerV2를 현실 로봇에서 실험한 논문이고 해당 글에선 PlaNet부터 DayDreamer의 논문을 소개할 예정이다.
PlaNet(2018) -> Dreamer(2019) -> DreamerV2(2021)-> DayDreamer(2022)
-> DreamerV3(2025)(공개) -> DreamerV4(2025)(미공개)
이어지는 글에서 DayDreamer 설명을 위해 다음과 같은 순서로 논문을 정리해서 설명할 예정이다.
1. Planet
2. Dreamer
3. DreamerV2
4. DayDreamer
PlaNet, Dreamer, DreamerV2, DayDreamer에서 월드모델로는 PlaNet에서 처음 나온 RSSM의 기본 구조를 그대로 가져간다.
이에 따라 다음과 같은 공통점 및 차이점을 가진다.

PlaNet
Learning Latent Dynamics for Planning from Pixels 논문에서 소개된 내용이다.
RSSM을 처음 제안했다.
PlaNet은 계획을 사용하여 반복적으로 데이터를 수집하고, 수집된 데이터를 바탕으로 동역학 모델을 학습시켰다.
액터 크리틱 방식이 아니라, 매 스텝마다 세운 계획들 중 가장 보상이 좋을 액션만 수행하도록 하는 알고리즘을 통해 액션을 선택했다.
월드 모델 RSSM(Recurrent State-Space Model)
추후에 더 자세히 설명하겠지만 여기서 간단하게 RSSM을 설명할 것이다.
동역학을 안다면 원인(로봇액션)에 따른 결과(상태)를 알 수 있다.
미리 계획을 짜는 Planning기법은 동역학이 알려진 제어 작업에서는 성공적이라고 한다.
하지만 동역학을 완벽히 알 수 없는 상황에서는 Planning을 할 수 없다.
로봇이 직접 경험한 실제 데이터(이미지)를 바탕으로 세상에 대한 “시뮬레이터”를 학습하여 동역학을 대신한다.
미래의 상태인 고차원 이미지를 직접 예측하는 것이 아니라, 이를 압축한 ‘잠재 공간(Latent Space)’에서 미래를 예측하여 계산 효율을 높인다.
과거를 기억하는 결정론적 경로(RNN)와 미래의 불확실성을 다루는 확률론적 경로(SSM)를 결합하여, 복잡한 환경을 효율적으로 모델링하는 것이다.
문제추상화
이산 타임스텝 t, 숨겨진 상태(hidden states) , 이미지 관측 , 연속적인 행동 벡터 , 보상 를 정의한다.
월드모델 내에서 각 Step은 로 진행한다.
S를 Latent Space, O를 이미지로 간주하면 이해가 용이하다.
보상 합 을 최대화하는 정책 을 구현하는 것이 목표이다.
그에 따라 필요로 하는 함수 목록 ->

(Observation Function은 학습시에만 이용됨.)
Algolithm
Main Training Algorithm
월드모델 학습 -> 데이터수집 -> 월드모델 학습의 반복으로 전개된다.

무작위 행동으로 수집된 S개의 시드 에피소드로 시작한다.
데이터셋에서 데이터 시퀀스를 꺼내어 월드모델을 업데이트(목적함수에 대해선 후술)한다.
데이터셋에 하나의 에피소드 추가한다.
매 스텝마다 과거 데이터를 보며 현재 상태(𝑠_𝑡)를 추측한다.
액션 결정 알고리즘(후술)을 통해 액션을 선택 및 실행한다.
액션에 작은 가우시안 탐험 노이즈 추가한다.
계획 범위를 줄이고 모델에 더 명확한 학습 신호를 제공하기 위해, 강화 학습에서 일반적이듯이 액션을 R번 반복한다.
Action decision algorithm
Cross Entropy Method(CEM)를 사용하여 액션을 결정한다.
현재 스텝 t부터 t+H스텝 까지의 미래를 계획하는 알고리즘이다.
하지만 계획한 H길이 스텝의 액션 중 맨 앞 액션만을 실행한다.
다음과 같은 흐름으로 알고리즘이 전개된다.
행동분포(평균, 편차) 초기화 N(0, 1)
I번 반복
-
현재 행동분포를 기준으로 길이 H의 행동시퀀스 J개 샘플링
- 현재상태를 시작으로 전이모델을 사용하여 H+1까지의 상태 예측
- 각 상태에 대해 R에 대해서도 예측 -
J개의 모든 R기준 TOP K의 인덱스 저장
-
K개 행동에 대해 평균 및 분산 평균
-
행동분포 N업데이트
해당 스텝에 대한 평균 행동만을 반환

Training objective
목적함수를 알아보자
행동 a만이 주어졌을 때 O가 어떻게 될 것인지 정확히 예측하는 것이 목표이다.
=>ln𝑝 (𝑜(1:𝑇)│𝑎(1:𝑇) )
하지만 해당 식을 직접 계산할 순 없으니 하한을 최대화하는 식으로 전개된다.

하한식의 각 항에 대해 알아보자
첫 번째 항: 재구성 손실 (Reconstruction Loss)
에이전트가 추론한 상태(𝑠𝑡)를 가지고 실제 관측(𝑜𝑡)을 복원할 확률을 최대화한다.
이는 𝑠_𝑡가 이미지 정보를 놓치지 않도록 필수 정보를 담도록 강제한다.
훈련시에만 쓰이고, 실제 추론시에는 쓰이지 않는다.
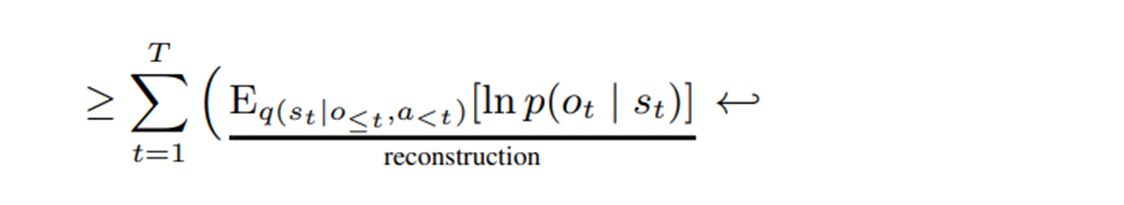
두 번째 항: 복잡도 손실 (Complexity Loss / KL-Divergence)
역할: 동역학 예측력을 높인다.
𝑞(…)(사후 확률): 현재 관측 𝑜𝑡까지 보고 추론한 정답에 가까운 𝑠𝑡(실제 추론시에는 𝑜_𝑡 를 보지 못함)
𝑝(…)(사전 확률): 예측 결과. 이전 상태 𝑠(𝑡−1)과 행동 𝑎(𝑡−1)만 보고 전이 모델이 예측한 상태
목적: 사전 확률(p)가 정답에 가까운 사후 확률(q)과 같아지도록 차이를 줄여서, 잠재 공간에서 한 단계 앞을 예측하는 동역학 예측력을 학습한다.
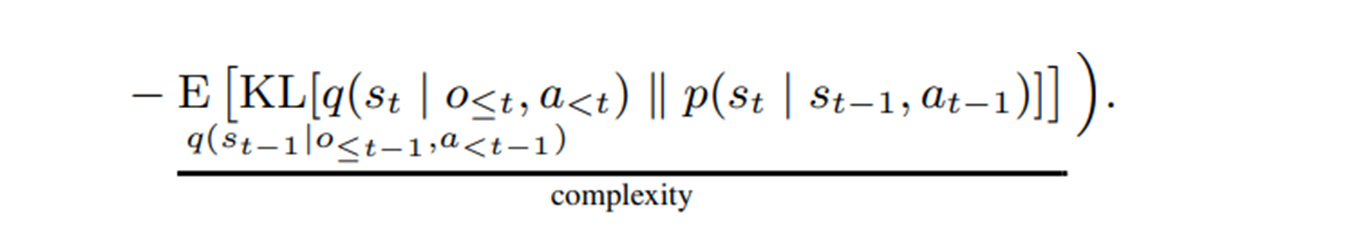
이제 식을 다음과 같이 표현할 수 있다.

Model architecture
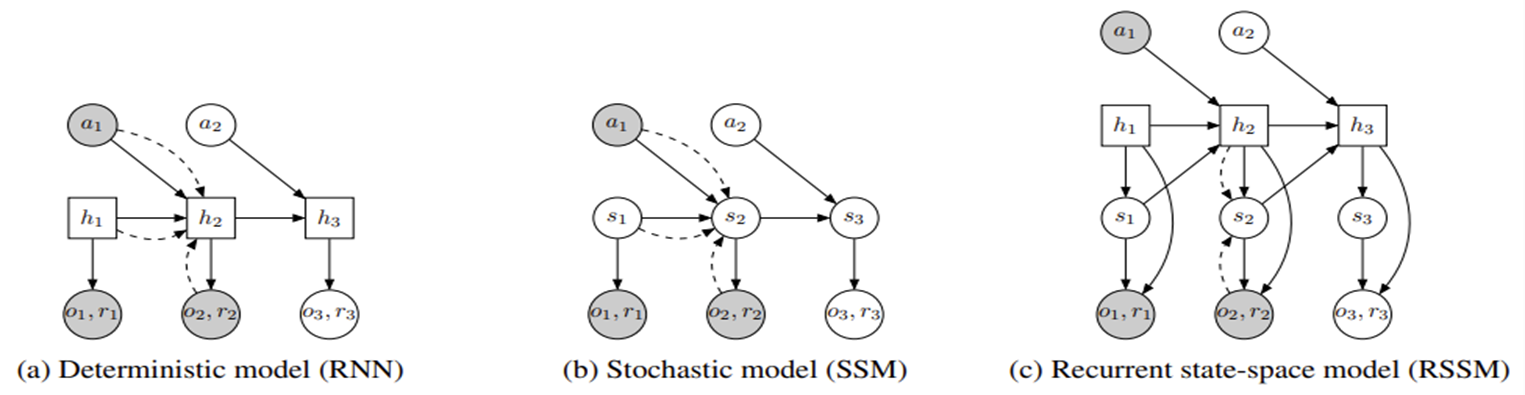
위의 그림은 RSSM의 최종 형태가 아니다.
밑의 C를 RSSM의 최종형태로 한다.
(a) RNN에서의 전이는 결정론적, 이는 모델이 여러 미래를 포착하는 것을 방해한다.
(b) 상태 공간 모델(SSM)에서의 전이는 확률론적, 이는 여러 스텝에 걸쳐 정보를 기억하기 어렵게 만든다.
(c) 상태를 확률론적 부분과 결정론적 부분으로 분할하여, 모델이 이전 스텝을 잘 기억하면서 여러 미래를 예측하는 법을 학습할 수 있도록 한다.
Dreamer
앞선 PlaNet을 발전시킨 논문인 "DREAM TO CONTROL: LEARNING BEHAVIORS BY LATENT IMAGINATION"에서 등장한 Dreamer에 대해 소개하겠다.
월드모델은 앞선 PlaNet방식을 그대로 차용하였다.
액션 결정 시 CEM이 아닌 액터&크리틱 방식을 차용하여 학습을 효율적으로 진행한 것이 특징이다.
모델 구조는 월드모델(RSSM) + Actor + Critic이다. 기존 RSSM에 Actor와 Critic이 추가된 것을 확인할 수 있다.

Overview
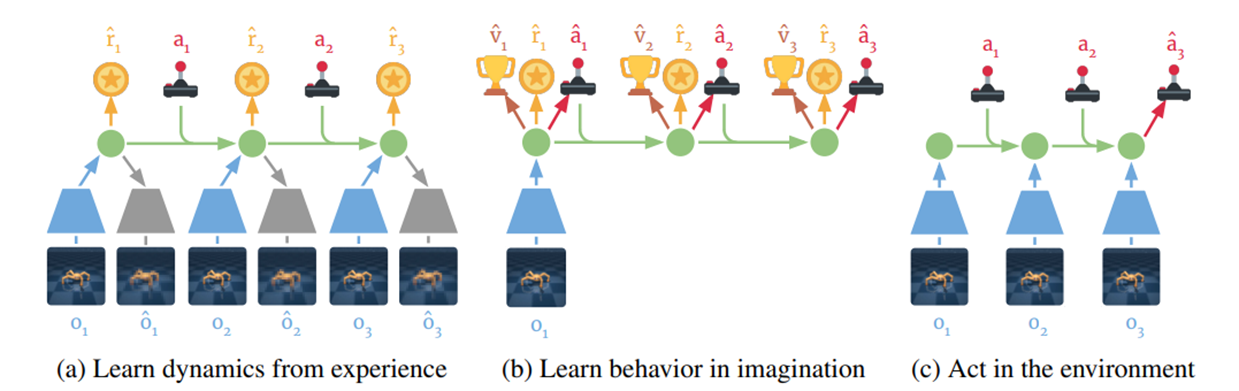
다음과 같은 과정으로 학습이 진행된다.
(a) 경험으로부터 동역학학습 (Learn dynamics from experience)
과거 경험 데이터셋(𝑜𝑡,𝑎𝑡 )으로부터, 에이전트는 관측과 행동을 압축된 잠재 상태(𝑠𝑡)로 인코딩, 환경 보상(𝑟𝑡 )을 예측하는 법을 배운다.
(b) 상상 속에서 행동 학습 (Learn behavior in imagination)
압축된 잠재 공간에서, Dreamer는 상태 가치(𝑣𝜓)와 행동(𝑎𝜙)을 예측한다.
상상된 궤적을 통해 그라디언트를 역전파하여 미래 가치 예측을 최대화하는 방향으로 학습한다.
(c) 환경 상호작용 (Act in the environment)
에이전트는 실제 환경에서 에피소드를 수행하며 기록을 인코딩하여 현재의 모델 상태를 계산하고, 실행할 다음 행동을 예측한다.
Algorithm
동역학학습, 행동학습, 환경 상호작용 세단계를 거쳐 학습이 진행되며 설명과 수도 코드는 다음과 같다.
동역학 학습 (Dynamics learning):
데이터셋 𝒟에서 시퀀스 배치를 추출 월드모델로 데이터의 각 상태 를 계산한다.
앞선 RSSM 학습 방법으로 𝜃를 업데이트한다.
행동 학습 (Behavior learning):
각 로부터 길이 H의 궤적 을 상상한다.
액터와 동역할 모델을 통해 보상과 가치를 예측한다.
수식(6)을 통해 정답으로 쓰일 가치 추정치 를 계산(후술)한다.
가치 추정치의 합을 최대화하도록 액터 파라미터 𝜙를 업데이트한다.
가치 추정치와의 가치의 차이를 최소화하도록 크리틱 파라미터 𝜓를 업데이트한다.
환경 상호작용 (Environment interaction):
RSSM에서와 마찬가지로 과거 기록과 현재 관찰을 통해 현재 𝑠_𝑡를 계산한다.
액터를 통해 를 계산하고 탐험 노이즈를 추가한다.
환경에서 행동 을 실행하고 보상과 다음 관측을 획득한다.
이를 에피소드 종료까지 반복한다.
새로운 경험을 데이터셋 𝒟에 추가한다.

Actor&Critic
액터 크리틱의 목적함수에 대해 알아보자.
크리틱 먼저 알아보겠다.
Critic
액터&크리틱 모델을 학습하기 위해, 상상된 궤적의 상태 가치를 추정해야 한다.
액터에서 샘플링한 행동을 사용하여 H만큼 예측을 진행한다.
위 알고리즘에서 등장한 6번식은 다음과 같이 5번식의 응용으로 만들어졌따.
(5) :𝑘단계 이후의 보상을 학습된 크리틱로 추정, k이전 단계는 상상한 보상의 합으로 계산한다.
(6): Dreamer가 사용하는 방식으로, 서로 다른 k에 대한 추정치들의 지수 가중 평균( 𝜆−𝑟𝑒𝑡𝑢𝑟𝑛)을 사용한다.
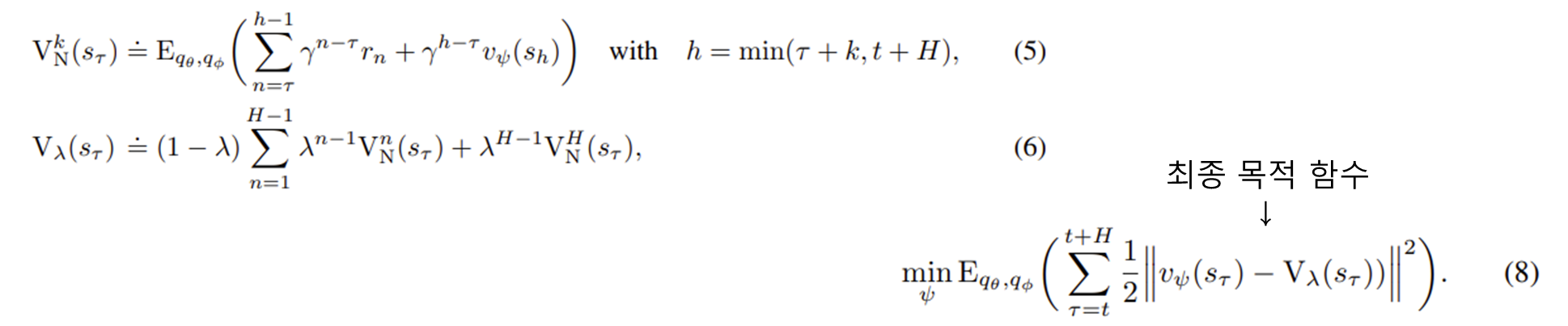
Actor
행동 모델은 가치 추정치를 최대화하려 학습한다.
tanh로 변환된 통계량 예측이 목표이다.
재매개변수화를 통해 미분 가능하게 만든다.
- 재매개변수화: 샘플링을 하면 미분이 불가능하니 평균과 분산을 구하여 덧셈과 곱셈으로 액션을 출력하여 미분 가능하게끔 만든다.
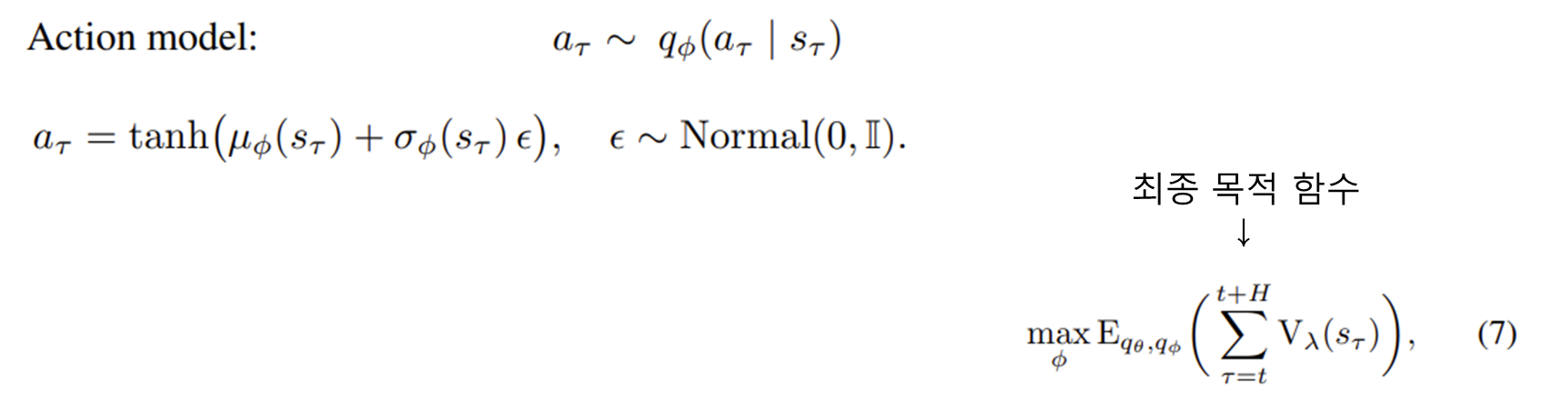
DreamerV2
앞선 Dreamer를 발전시킨 모델로 "MASTERING ATARI WITH DISCRETE WORLD MODELS" 이란 논문에서 등장하였다.
DreamerV2는 Dreamer에 약간의 변화를 주어서 성능을 끌어올렸다.
가장 큰 변화는 모델 크기증가와 잠재상태 표현 방식의 변화이다.
Atari 등 시뮬레이션에서 높은 성능을 이끌어내었다.
아래 그림과 같이 잠재표현을 가우시안 표현에서 범주형 표현(원핫벡터)로 바꾸었다.
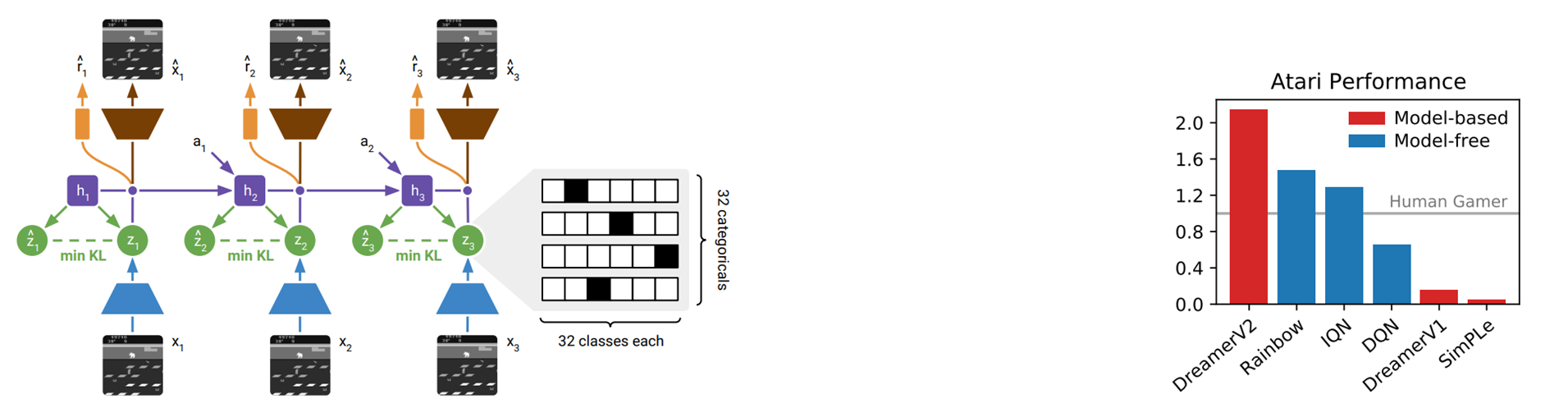
변화점들에 대해 자세히 설명하겠다.
Changes
범주형 잠재 변수 (Categorical latents)사용
월드 모델에서 가우시안 잠재 상태 대신, 범주형 잠재 상태를 사용하였다.
범주형 변수에선 원핫백터를 통해 잠재상태를 표현한다.
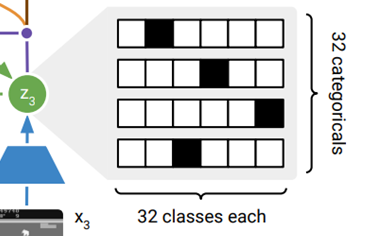
이산적인 샘플링 과정에서도 역전파가 가능하도록 Straight-Through Gradients 방식을 적용하였다.
Straight-Through Gradients은 순전파 시에는 샘플링의 결과(원핫)만 보내고 역전파 미분 시 확률의 기울기를 사용하도록 한다.

모델 크기 증가
모든 모델 구성 요소의 size나 필터 채널 수를 늘려 파라미터 수가 약 1,300만 개에서 2,000~2,200만 개로 증가시켰다.
KL 밸런싱 (KL Balancing) 도입
학습 시 사전확률을 예측하는 사전모델(Prior)과 사후 확률을 예측하는 사후모델(Posterior)에 서로 다른 Learning rate을 적용하였다.
Posterior()와 Prior()가 서로를 닮아가는 것이 아닌 Prior이 Posterior을 따라가도록 유도하였다.
Alpha= 0.8을 적용하였다.

Actor Loss 변경
Reinforce 항을 추가하였다.
이때, Actor loss로 Critic이 같이 훈련되지 않게 sg(stop gradient)적용하였다.
Atari같은 이산제어에서는 Reinforce, 연속제어에서는 Dynamics가 적용되었다.
탐험을 Entropy Regularizer로 유도하였다.
Actor을 뽑을 확률이 고르게 분포되게 만들었다.
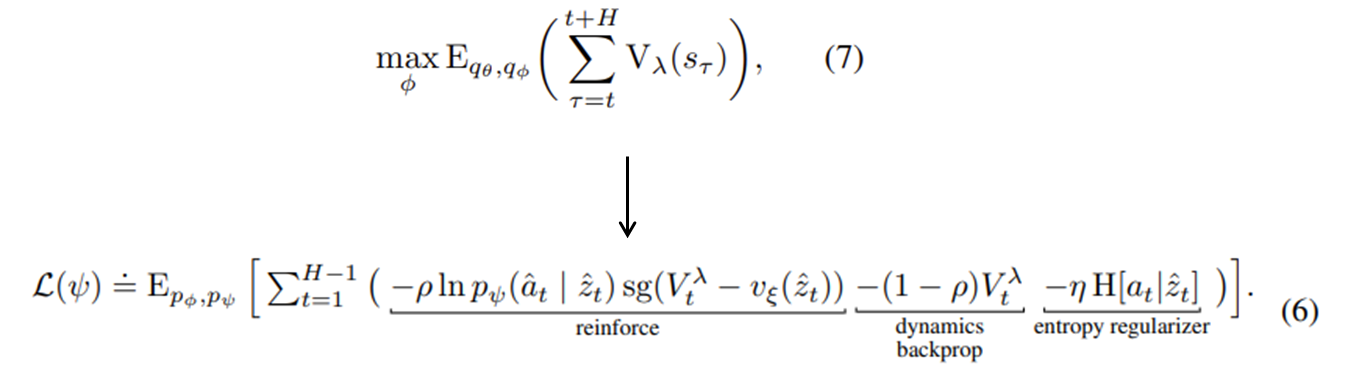
DayDreamer
앞선 DreamerV2를 실제 로봇에 적용한 논문이다.
DreamerV2를 실시간성을 요구하는 로봇 환경에 맞춰 약간의 변화를 주어 실험 결과를 정리한 논문이다.
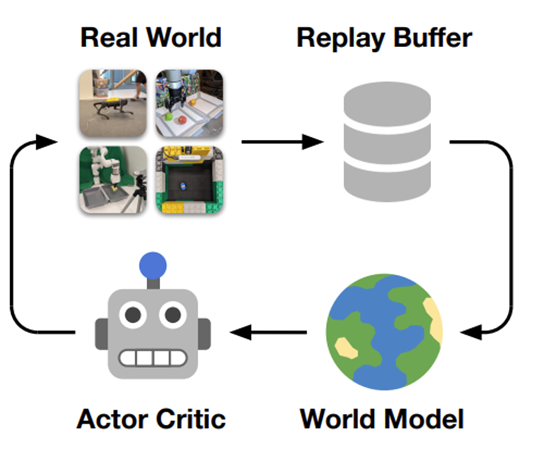
앞선 DreamerV2와 같은 모델 구조및 학습루틴을 따른다.
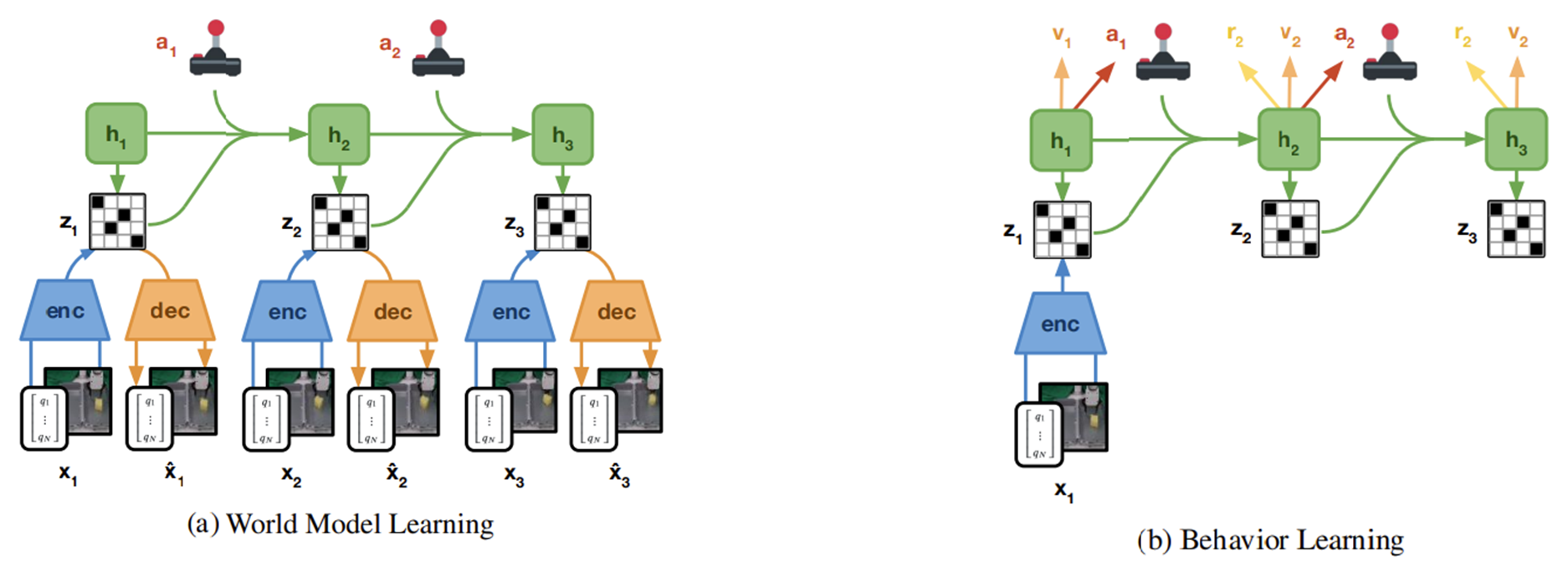
Changes
비동기 학습 구조 도입
이 전까진 “학습 -> 행동 -> 학습”이 순차적으로 진행됐다면 Actor와 Learner 두개의 스레드가 동시에 돌아가는 비동기 방식을 채택하여 학습을 가속화하였다.
- Actor스레드는 로봇을 위한 온라인 행동을 계산하고 128 타임스텝의 궤적을 리플레이 버퍼로 전송한다.
- Learner스레드는 리플레이 버퍼에서 데이터를 샘플링하고, 월드 모델을 업데이트하며, 'imagination rollouts'을 사용하여 정책을 최적화한다.
Sensor Fusion 인코더
DreamerV2까지는 오직 이미지 입력만 처리하였다.
하지만 실제 로봇을 사용하니만큼 로봇의 상태정보도 입력으로 사용한다.
RGB이미지, 로봇 정보 혹은 그 둘을 결합하여 잠재상태(𝑧_𝑡)로 압축하도록 인코더 설계하였다.
Ex) UR5의 경우 로봇 정보로 관절 각도, 그리퍼 위치, 엔드 이펙터의 좌표사용
모델 크기 축소
RSSM size 600 -> 256
월드 모델 사이즈를 축소시켰다.
Experiments
보행, 조작(manipulation), 내비게이션과 같은 일반적인 로봇 공학 작업들을 대표하는 4대의 로봇에서 평가를 진행하였다.
알고리즘들 및 인간 베이스라인과 비교를 진행하였다.
모든 실험에서 동일한 하이퍼파라미터를 사용하여, 서로 다른 로봇 에서도 별도 수정 없이 훈련이 가능하게 하였다.
로봇팔 뿐 아니라 4개의 다리를 조정하는 로봇, 바퀴를 조정하는 로봇 등 다양한 로봇에도 적용하였다.

앞선 DreamerV2에서 그랬듯이 Actor 훈련 시 액션 공간에 따라 다른 Loss항 사용하였다.
- 연속적 액션 -> Dynamics 항 사용
- 이산적 액션 -> Reinforce 항 사용

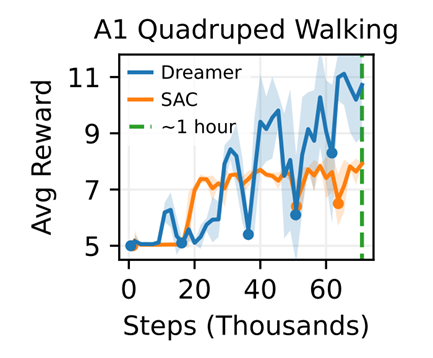
A1 Quadruped Walking

SAC와 비교
훈련 첫 5분 이내에 로봇은 등을 대고 누운 상태에서 벗어나 발로 착지하는 데 성공하였다.
20분이 지나자, 발로 일어서는 방법을 배웠다.
훈련 시작 약 1시간 후, 로봇은 원하는 속도로 앞으로 걷는 것을 학습하였다.
훈련 1시간 이후, 로봇을 밀기 시작했고 그 결과 10분 이내에 행동을 수정하여 가벼운 밀림은 견뎌내고 강한 밀림에는 빠르게 뒤집어 일어나는 것을 확인하였다.
그래프에서 채워진 원은 로봇이 넘어진 시점을 나타냈다.
SAC는 빠르게 뒤집는 법은 배웠지만, 일어서거나 걷는 법을 배우지 못했다.
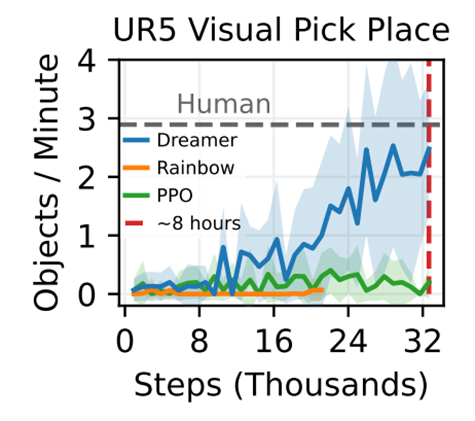
UR5 Multi-Object Visual Pick and Place

Rainbow DQN, PPO, 그리고 인간 베이스라인과 비교
3명의 시연자가 조이스틱으로 UR5를 20분씩 제어하는 것을 인간의 원격 조작 성능을 추정했다.
8시간 이내에 분당 평균 2.5개의 물체를 집는 속도에 도달했다.
로봇은 처음에는 보상 신호가 매우 희소하기 때문에 학습에 어려움을 겪지만, 훈련 2시간 후부터 점진적으로 개선되기 시작했다.
로봇은 먼저 물체의 위치를 파악하고 물체 근처에 있을 때 그리퍼를 토글하는 법을 배웠다.
시간이 지남에 따라 잡기 동작이 정밀해지고 로봇은 구석에 있는 물체를 밀어내는 법을 배웠다.
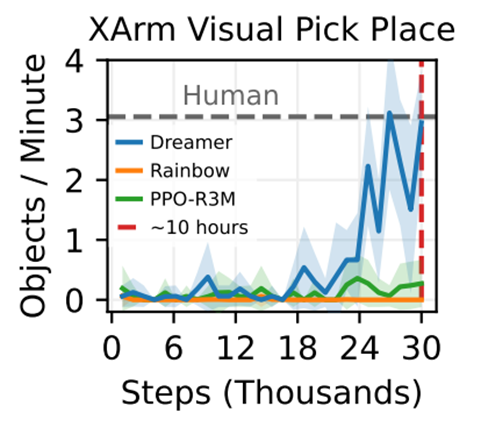
XArm Visual Pick and Place

10시간 만에 XArm이 분당 평균 3.1개의 물체를 집는 속도를 달성하는 정책을 학습했으며, 이는 이 작업에서 인간의 성능과 비슷한 수준이다.
픽셀로부터 이산적인 제어를 하는 최고 수준의 알고리즘인 Rainbow는 학습에 실패했다.
R3M 사전 훈련된 시각적 임베딩을 상태로 활용하는 PPO 베이스라인과 Dreamer를 추가로 비교했지만 성능향상을 발견하지 못했다.
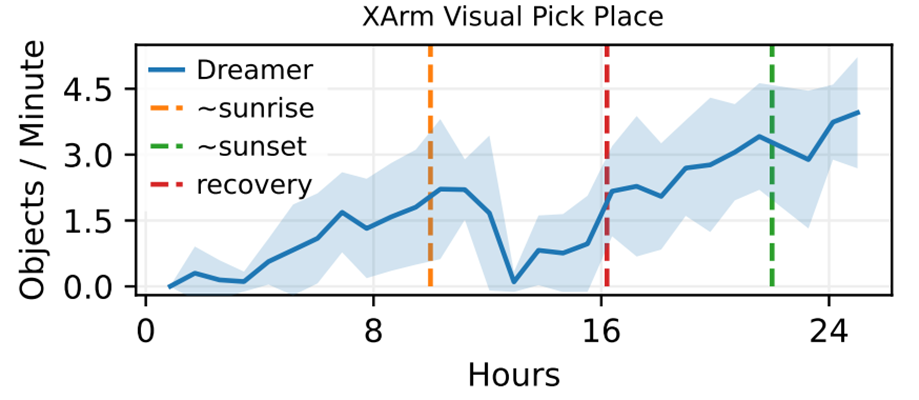
조명 조건이 급격하게 변할 때(예: 일출 시의 그림자 변화), 성능이 초기에 무너지지만 Dreamer가 곧 변화하는 조건에 적응하고 몇 시간의 추가 훈련 후에 이전 성능을 능가하는 것을 관찰했다.
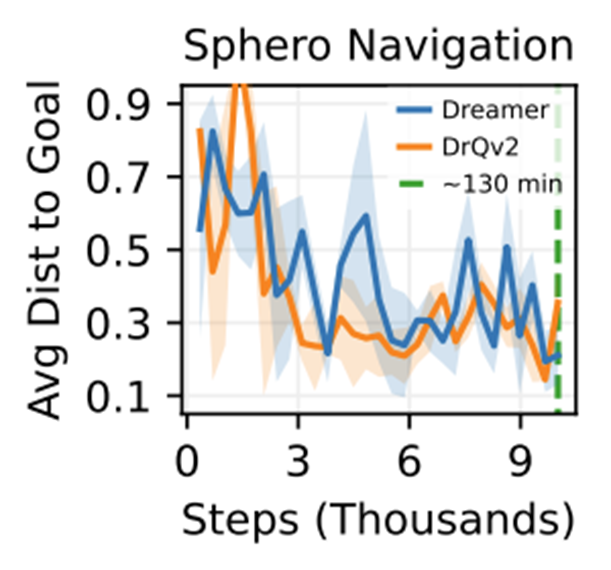
Sphero Navigation

Sphero의 위치를 감지하는 비전 파이프라인을 사용하여 계산된 L2 거리의 dense reward 사용하였다.
목표 지점이 고정되어 있으므로, 100 환경 스텝 후에 에피소드를 종료하고 로봇의 위치를 무작위화한다.
2시간 만에 Dreamer는 목표 지점으로 빠르고 일관되게 이동하고 에피소드의 남은 시간 동안 목표 지점 근처에 머무는 법을 학습하였다.
픽셀로부터 연속적인 제어를 하도록 특별히 설계된 모델-프리 알고리즘인 DrQv2가 유사한 성능을 달성하는 것을 발견하였다.
Hyperparmeters