Paper Review
1.[Paper Review] DayDreamer: World Models for Physical Robot Learning

Introduction https://arxiv.org/abs/2206.14176 - 논문 https://github.com/danijar/daydreamer - 코드 공개 Philipp Wu, Alejandro Escontrela, Danijar Hafner,
2.[Paper Review] Offline Imitation Learning Through Graph Search and Retrieval

https://arxiv.org/pdf/2407.15403 - 논문 https://zhaohengyin.github.io/gsr/ - 사이트(코드 공개는 추후에 한다고 한다) 개요 Offline Imitation Learning Through Graph Search
3.[Paper Review] OFFLINE REINFORCEMENT LEARNING WITH IMPLICIT Q-LEARNING
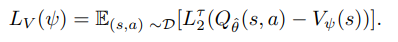
On-policy: 정책(policy)을 평가하거나 개선할 때, 현재 학습 중인 정책 자체를 사용하여 데이터를 수집하는 방법.학습 중인 정책으로 행동을 하고, 그 데이터를 사용해 그 정책을 업데이트함.안정적이지만, 탐험(exploration)과 학습 사이 균형이 어려움
4.[Paper Review] Soft Actor-Critic

: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic ActorInternational Conference on Machine Learning (ICML), 2018저자: Tuomas
5.[Paper Review] FurnitureBench: Reproducible Real-World Benchmark for Long-Horizon Complex Manipulation
FurnitureBench라는 벤치마크에 대해 소개할 예정이다.KAIST / UC BerkeleyMinho Heo, Youngwoon Lee, Doohyun Lee, Joseph J Lim오픈소스: https://github.com/clvrai/furnitur
6.[Simple Paper Review]Skill-based Model-based Reinforcement Learning
Skill-based RL과 Model-based RL의 장점을 합쳐 효율적인 장기 행동 계획을 구현하였다.Skil: 행동을 여러 Step 단위로 묶어 추상화한 것이다.Ex. 밀기, 집기 등Model: 동역학에 대한 이해를 담은 함수 혹은 딥러닝 모델이다.에이전트가 액
7.[Simple Paper Review]Adversarial Skill Chaining for Long-Horizon Robot Manipulation via Terminal State Regularization
8.[Paper Review]LAYER-WISE UPDATE AGGREGATION WITH RECYCLING FOR COMMUNICATION-EFFICIENT FEDERATED LEARNING
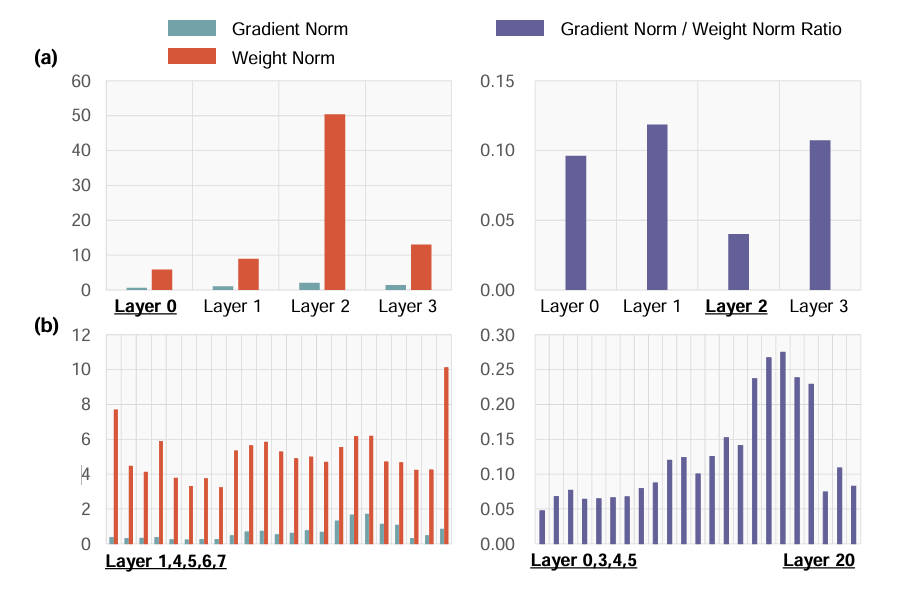
https://arxiv.org/pdf/2503.11146LAYER-WISE UPDATE AGGREGATION WITH RECYCLING FOR COMMUNICATION-EFFICIENT FEDERATED LEARNINGNeurIPS, 2025본 논문에서는 F
9.[Paper Review]RoboDreamer: Learning Compositional World Models for Robot Imagination!
RoboDreamer: Learning Compositional World Models for Robot Imagination 이라는 논문이다.읽기 전에 아래 Diffusion model을 이해해야 이 논문을 이해할 수 있다.https://velog.io/@m