https://arxiv.org/pdf/2407.15403 - 논문
https://zhaohengyin.github.io/gsr/ - 사이트(코드 공개는 추후에 한다고 한다)
Robotics: Science and Systems(RSS)
UC Berkeley
Zhao-Heng Yin, Pieter Abbeel
인용수
15회(2025년 11월 기준)
Introduction
기존 모방학습의 문제
모방학습이란?
대표적으로 행동복제(BC)가 존재한다.
ex) MSE 등을 통한 상태에 대한 액션 지도학습
한계
데이터셋에 실패행동이 있으면 그 행동까지 그대로 복제한다.
그렇기 때문에 전문가 수준의 최적 데이터가 필요하다.
준최적(suboptimal) 데이터에서 좋은 행동들을 선택하여 학습할 수 있는 방법이 필요하고 이를 궤적 잇기(trajectory stitching)라고 표현한다.
기존 강화학습의 문제
강화학습이란?
모방학습의 한계를 극복하고 준최적 데이터셋에서 학습하기 위한 대안으로 강화학습이 등장했다.
BC가 데이터의 행동을 맹목적으로 따라 한다면, RL은 가치 함수를 학습한다.
가치함수를 통해 데이터셋에 존재하는 각 행동이 “얼마나 좋은지” 스스로 평가(Q-learning)한다.
이 평가 과정을 통해, RL은 준최적 시연 데이터 속에서도 '좋은' 행동은 강화하고 '나쁜' 행동은 무시하도록 정책을 최적화한다. -> 궤적잇기를 수행
한계
RL은 "deadly triad" 문제로 인해, 학습 과정이 매우 불안정하고 취약하다.
Bootstrapping: 추정값을 사용해 또 추정하여 오류를 누적(ex: Q-러닝에서 추정한 Q(s^′,a^′ )의 값을 가져와서 Q(s,a)업데이트)
offline Learning: 새 데이터 수집(검증) 없이 고정된 데이터로만 학습하여 데이터셋에 존재하지 않는 행동의 가치 추정 오류가 수정되지 않음
Function Approximation: 현실의 복잡한 문제(ex: 픽셀기반)를 풀기 위해, 모든 상태의 가치를 표로 저장하는 Neural Network를 사용해 가치를 '추정'하는 방식
장기적이거나 복잡한(픽셀 기반) 작업에서 어려움을 겪을 수 있음을 시사한다.
GSR(Graph Search and Retrieval)을 제안
오프라인 데이터셋 내에서 부트스트래핑 없이 그래프 표현과 검색을 사용하여 “좋은 행동”을 학습 전 식별한다.
수집된 데이터의 각 Step에 대해 사전 훈련된 표현을 활용하여 그래프 표현을 구축한다.
- 시작~끝 step까지 그래프의 최단 경로를 탐색한다.
- 최단 경로로 식별된 행동을 “좋은 행동“ 으로 정의한다.
- 식별한 “좋은 행동”을 모방학습에 사용한다.
해당 알고리즘은 모방 학습을 위해 데이터셋을 전처리하는 필터링 절차로 볼 수 있으며, 어떤 종류의 모방 학습 모델과도 함께 사용될 수 있다.
전체 전처리 절차는 BC에 비해 일반적으로 10분에서 30분(데이터셋에 따라 다름)의 오버헤드가 발생하므로 실제 적용에 실용적이라고 한다.
고해상도, 다중 시점 카메라 관찰 및 정밀한 로봇-객체 상호작용을 포함하는, 다양한 시각적 및 물리적 복잡성을 가진 시뮬레이션 및 실제 로봇 조작 작업 모두 테스트하였으며, 베이스라인의 성공률을 10%에서 30%, 숙련도를 30% 이상 일관되게 향상되었다고 한다.
PRELIMINARIES
Problem Formulation
오프라인 정책 학습을 기준으로 쓰여졌다.
시연된 행동은 실행 과정에서 수많은 오류와 실수를 포함하는 등 준최적 데이터셋 D가 제공된다고 가정한다.
데이터에서 인간 원격 조작자는 로봇을 제어하여 작업을 해결하고 성공 달성을 가정한다.
데이터셋 D의 각 에피소드 τ는 상태(o)와 액션(a)의 시퀀스 집합이다.
τ = (o0, a0, o1, a1, ..., oT , aT )
τ ∈ D
Offline Policy Learning
많은 offline policy learning alorithms이 다음의 목적함수를 최대화 시키기 위해 policy network πθ(a|o) 훈련시키며 BC, IQL도 다음식으로서 설명할 수 있다.
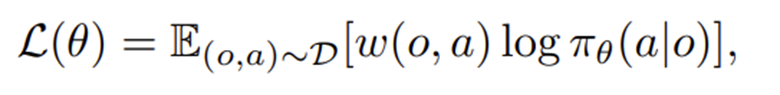
여기서 다음 식은 모방점수로 데이터셋의 (o, a)가 주어졌을 때, 정책 네트워크가 그 행동 a를 선택할 확률을 높이는 방향이다.
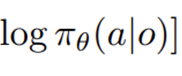
다음식은 가중치로 어떤 학습이냐에 따라 달라지며 얼마나 강하게' 모방할지를 결정한다.
ex)
예를 들어 BC에서는 W가 1이라는 상수함수이고, IQL에서는 exp(A)가 된다.
BC: w(o,a) = 1
IQL: w = exp(A)
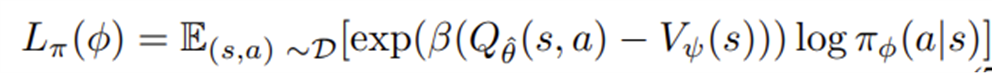
POLICY LEARNING BY GRAPH SEARCH AND RETRIEVAL
이 논문이 제안하는 GSR은 "그래프 탐색"을 통해 “가중치 w”를 계산하는 새로운 제3의 방식을 제시한다.
이때, 이상적인 상황에서의 아이디어를 제시하고 이를 현실상황에서 적용하는 방식으로 전개가 된다.
이상적인 아이디어
-
모든 상태가 명확한 표 형태의 경우(tabular case), 상태 사이의 행동을 다 알고 있다고 가정한다.
-
비용함수는 목표 에 도달하는데 걸린 스텝수로 가정한다.
-
각 상태들을 그래프로 연결할 수 있고, 출발점 부터 도착지까지 최단 경로를 구할 수 있다고 가정한다.
-
최단 경로에서의 행동들을 최적행동 로 가정한다.
에 가중치 1을 주고, 나머지 경로에는 가중치 0을 준다. w=1[a=a*]
를 식으로 표현하면 다음과 같다.
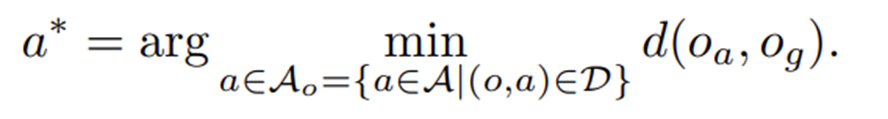
현실적 문제
로봇의 시연데이터(카메라영상)은 모든 프레임이 고유하다는 현실적인 문제에 직면한다.
그로 인해 다음과 같은 문제가 발생한다.
문제1: 부정확한 거리
같은 위치에서 영상을 찍었어도 해당 프레임이 완전히 같은 프레임이 될 수 없고, 다른 프레임 간의 거리를 계산할 방법이 없다.
즉, 최적거리를 계산할 수 없다.
A가 찍은 영상 10초 지점 와 B가 찍은 영상 5초 지점 가 같은 위치라 가정해도 별개의 데이터로 존재한다.
문제2: 정책 개선 불가
모든 프레임이 고유하니 해당 프레임에서 수집된 액션 데이터도 단 하나이며 결국 이 액션만이 해당 프레임에서 최적 행동이 될 것이다.
즉, 이 모든 곳에서 성립하게 된다. (w=1[a=a*]에 의해)
한 상태에 대해서 하나의 액션만이 학습되고, 이는 개선 불가능하다.
본 논문의 해결책
문제1: 부정확한 거리 -> Graph Construction & Search
A영상 10초와 B영상 5초가 "유사하다"는 것을 식별하여, 두 지점 사이를 "연결”한다.
이렇게 모든 상태에 대하여 “연결“하여 그래프를 만든다.
그렇게 연결된 그래프를 통해 각 상태의 가치(비용)을 계산한다.
문제2: 정책 개선 불가 -> Retrieval
지점에서 행동을 결정할 때 의 데이터만 보지 않는다.
의 유사한 이웃들 k개를 검색한다.
다양한 행동이 포함된 K+1개의 후보군 중에서 최선의 행동을 골라 가중치를 높인다.
Graph Construction
1단계: 정점 집합 V 구축
0.1초 차이의 연속된 두 프레임은 거의 같듯이 시연영상의 모든 프레임을 정점으로 한다면 너무 빽빽하고, 비효율적이다.
하여, 서브샘플링을 진행하여 n 프레임마다 하나씩 지점을 찍는다. (ex: )
작업 목표를 편리하게 지정하기 위해, 가상의 목표 정점 g를 V에 추가한다.
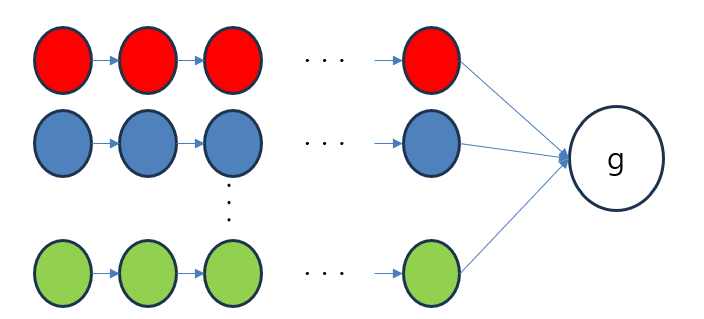
2단계: 간선 집합 E 구축
간선 집합을 두가지로 구분한다.
데이터셋 간선: 한 에피소드 내에서 각 정점을 시간순으로 연결, 단방향 간선이다.
작업 성공에 해당하는 각 궤적의 마지막 정점은 가상 목표 정점 g와 연결한다.
증강 간선: 서로 다른 에피소드 내에서 유사도가 높은 정점들을 연결, 양방향 간선
사전 훈련된 비전 모델(R3M)을 사용하여 정점별 이미지 특징 벡터를 계산
간선 연결 Threshold로 사용될 “이웃허용범위(Tol)”을 구한다.
에 대한 “이웃허용범위(Tol)”을 구하는 과정
유사도(sim)는 두 이미지 특징 벡터 간의 L2 norm의 음수 값으로 정의한다.
->
- 1단계: 계산
데이터셋의 모든 정점 에 대해, 각자의 1스텝 기준점인 를 미리 계산한다.
이는 한 정점 에 대하여 같은 에피소드의 바로 앞 지점()과 뒤 지점()과의 유사도를 각각 측정한 후, 그중 더 작은 값(유사도가 더 낮은 값)을 선택하는 것이다.
- 2단계: M개의 이웃 탐색
데이터셋 전체를 둘러보며 와 유사도가 높은 개의 이웃을 찾는다. 이 이웃의 집합을 라고 표기한다.
- 3단계: 계산
2단계에서 찾은 개의 이웃 정점 ()들의 값을 모두 가져와 평균을 낸다.
즉, 의 최종 이웃허용범위()는 와 가까운 이웃()들이 가진 의 평균값으로 결정된다.
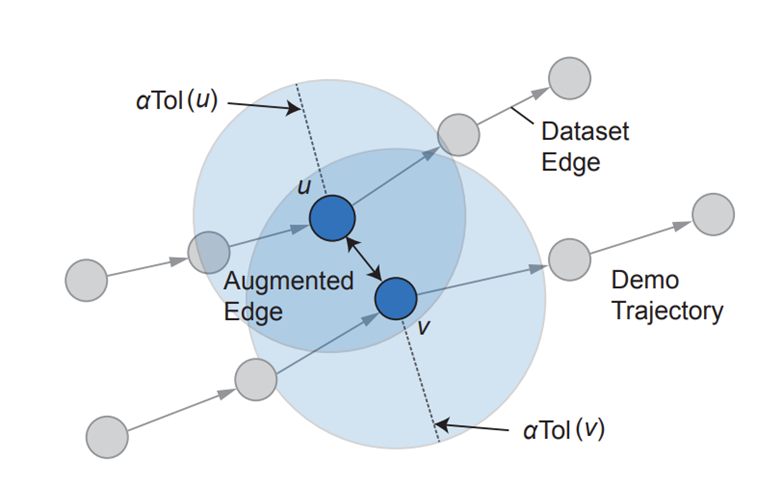
증강간선을 구축한다.
다음과 같은 조건을 만족하는 두 노드를 양방향 간선으로 연결한다.
하이퍼파라미터 𝛼는 1 근처의 값으로 설정된다.
연결된 정점들은 대략 서로의 관점에서 "1스텝 기준점" 내에 존재하여야한다.
즉, 한 정점만의 1스텝 기준()은 이상치일 수 있으니, 시각적으로 유사한 이웃들의 1스텝 기준을 평균내어, 안정적인 연결 기준점(𝑇𝑜𝑙)을 만든다. 연결 기준점보다 유사도가 높은 정점끼리는 연결한다.
아래 그림과 같이 한 에피소드내의 정점들은 단방향 "데이터셋 간선"으로 연결되고
각자의 Tol범위안에 들어오는 정점들은 양방향 " 증강간선"으로 연결된다.
Graph Search&Retrieval
정책 개선
그래프를 만들었으니, 이걸로 어떻게 좋은 행동만 골라낼 것인가?
1단계: 모든 지점의 가치 계산하기(Search)
목표: 지도 위의 모든 지점에 대해서 얼마나 좋은 위치인지 점수를 매긴다.
“좋은 위치”란? 최종 목적지(g)까지 가까운 위치이다.
전체 그래프를 통해, 이제 최단 경로 탐색(d)이 가능하다.
2단계: 유사 후보 검색하기(Retrieval)
문제: 기존엔 ”각 상태(지점 v)가 고유하여 데이터상 행동이 하나뿐이라 비교가 불가능하다”는 문제가 존재하였다.
해결책: v와 유사한 k개의 정점을 검색
3단계: 가중치 재할당
기본(BC): 원래대로라면 모든 행동에 가중치 1을 준다.
GSR 방식: 기준 노드 V의 1점을 k개의 이웃과 가중치 재할당을 함. => Softmax
“좋은 후보”에게 1점의 더 많은 지분을 주어야한다.
“좋은 후보”의 기준은 다음과 같다.
유사성(S): v와 얼마나 유사한지 정규화 하여 판단한다.
가치(Q): 그 정점(u)에서 행동이 최종 목적지(g)로 가는 빠른 길(높은 가치 𝑄 ̃)이어야 한다.
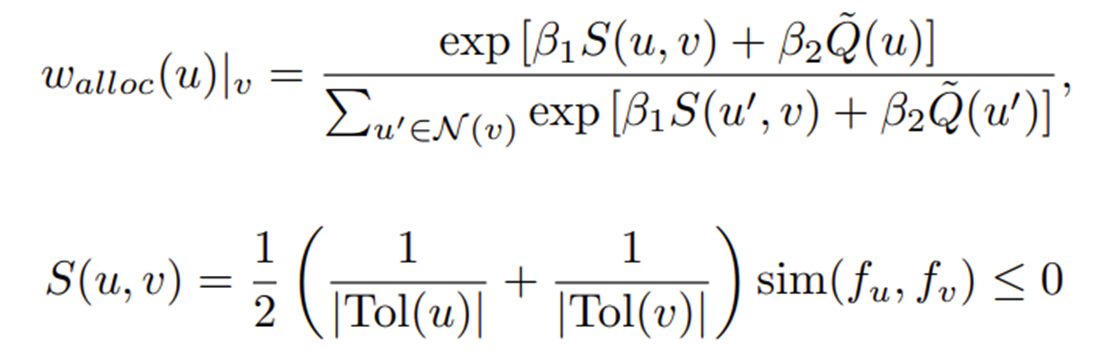
전체적인 Flow는 다음과 같다.
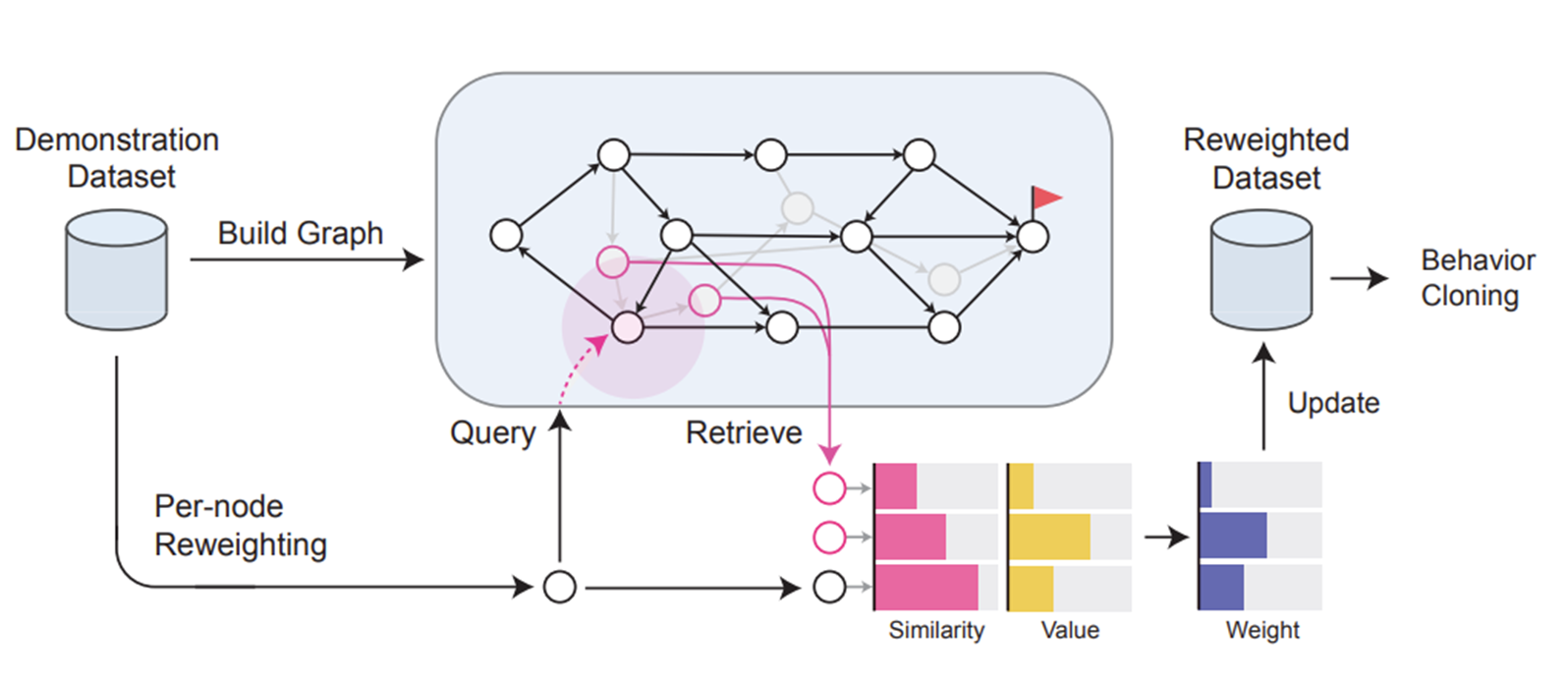

구현
유사도 검색을 위한 특징추출기로 R3M(ResNet-18 기반 로봇전용 인코더)을 사용
시간복잡도
R3M을 Finetuning하지 않으면 해당 논문 실험에서는 10분 미만 소요된다.
𝑂(𝑁 log𝑁+|ℰ|) <= 최단경로(다익스트라, 𝑂(𝑁 log𝑁+|ℰ|) ) + 최근접 이웃(𝑂(𝑁 log𝑁 ) )
(N은 데이터셋 크기 ℰ는 간선 수)
실험
시뮬레이션과 실제 환경 모두에서 실험을 진행하였다.
준최적 데이터를 사용하였다.
Metric
-
Success rate(SR, 성공률): 평가 시도 횟수 대비 작업 성공 횟수로 정의
-
Time-to-success(TTS, 성공까지 걸린 시간): 실제환경에서 사용하는 지표, 방법이 작업을 완료하는 데 걸리는 평균 시간이며, 성공한 시도에 대해서만 계산
-
Normalized Proficiency(NP, 정규화된 숙련도): 시뮬레이션에서 사용하는 지표, 최고 인간 조작자의 평균 TTS (NP=1.0)와 최악 인간 조작자의 평균 TTS (NP=0.0)를 기준으로 TTS를 정규화하여 계산
Baseline

시뮬레이션
시뮬레이션 테스트베드로는 이미지 기반의 Robomimic 벤치마크를 사용하였다.
시뮬레이션에서의 Task:
- Can pick and place: 캔을 집어 슬롯에 넣기
- Nut Assembly: 너트를 집어 페그에 끼우기
- Transport: 한 팔이 케이스의 망치를 집어 다른 팔에 전달하여 목표 위치에 두기

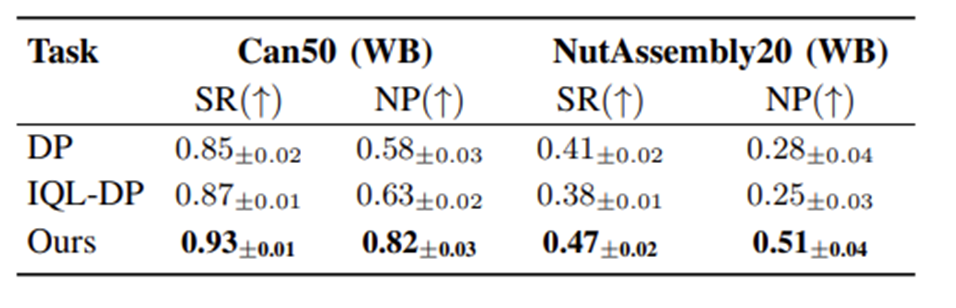
실험결과

데이터셋 변경실험
실제환경
실제환경에서의 Task:
- Pushing: 파란색 원기둥을 녹색 정육면체 쪽으로 밀기
- Spoon Scooping: 숟가락으로 그릇에서 물체 떠내기
- Rubber Band: 고물줄을 바퀴에 묶기
- Tweezer Manipulation : 선반에서 족집게를 집은 다음 족집게로 너트를 집어 목표 위치에 놓기

실험결과

CONCLUSION
그래프 탐색 및 검색을 통해 준최적(suboptimal) 데이터셋으로부터 학습할 수 있는 간단한 오프라인 모방 학습 방법인 GSR을 제시한 논문이다.
기준선의 성공률을 10%에서 30%, 숙련도를 30% 이상 일관되게 향상하였다.
FURTHER
알고리즘을 더욱 강력하게 만들기 위해 표현(representation)의 품질을 어떻게 향상시킬 수 있을지?
서로 다른 컨텍스트(배경)의 경험을 연결할 수 있는 작업 불변적인(task-invariant) 표현을 갖는 것이 더 바람직하다고 한다.
본 논문의 1-스텝 연결 대신, 사전 훈련된 예측 모델을 사용하여 더 장기적인 연결을 생성하는 것도 흥미로울 것이라고 한다. (시각적으로만 비슷한 것이 아닌 행동의 결과를 예측해서 연결한다는 뜻?)
