Skill-based Model-based Reinforcement => 줄여서 SkiMo라고 표현한다.
Skill-based RL과 Model-based RL의 장점을 합쳐 효율적인 장기 행동 계획을 구현하였다.
Skil: 행동을 여러 Step 단위로 묶어 추상화한 것이다.
Ex. 밀기, 집기 등
Model: 동역학에 대한 이해를 담은 함수 혹은 딥러닝 모델이다.
에이전트가 액션을 내뱉었을때, Model이 어떤 결과를 초래할지 알려준다.

Ex) 컵을 잡는 상황
-
Model-Free: 컵을 잘 잡을 때까지 직접 수많은 시행착오를 겪으며 학습한다.
-
Model-Based: 학습된 환경 모델을 이용해 에피소드의 결과를 상상하고, 보상이 높을 것 같은 에피소드만 실제로 시도한다. → 샘플 효율성 향상
-
Skill-Based: “컵을 잡는다”와 같은 고수준 행동 시퀀스(스킬)들을 모델(π_low)에 미리 학습시켜두고, 모델(π_high)이 스킬을 선택하게 하여 정책이 고려할 시계열 길이를 줄여 장기 과제 해결에 효과적이다.
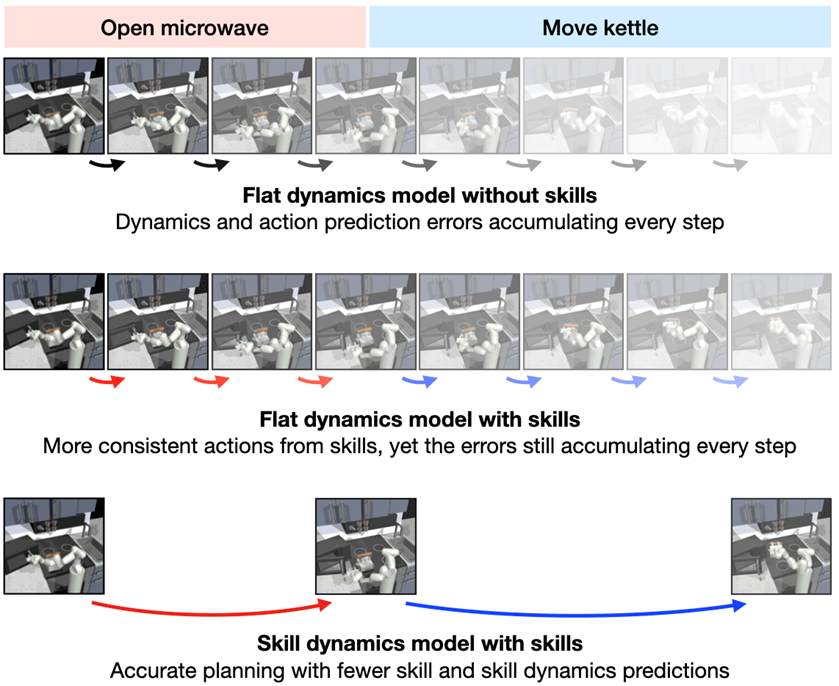
1번째: Flat dynamics model without skills
일반적인 model-based RL 상황이다.
매 스텝의 action → next state 예측한다.
예측 오차가 매 step마다 누적된다.
2번째: Flat dynamics model with skills
스킬을 사용하긴 하지만, 여전히 매 스텝을 예측하는 구조이다.
예측 행동이 스킬 기반이라 좀 더 일관성 있다.
하지만 아직도 1-step 예측을 누적한다.
3번째: Skill dynamics model with skills(SkiMo)
한 번의 스킬로 여러 step의 행동을 생성한다.
skill dynamics 모델은 그 스킬이 끝났을 때의 결과 상태만 예측한다.
예측 횟수 ↓ => 오차 누적 ↓
장기 과제에 특화되어있다.
