[Simple Paper Review]Adversarial Skill Chaining for Long-Horizon Robot Manipulation via Terminal State Regularization
Paper Review
목록 보기
7/9
Skill-based RL에서 종료상태 정규화를 구현해 가구조립 성능을 높였다.
단순히 스킬을 나열하는 방식은 스킬을 연속적으로 시행할 때 다음 이슈들이 존재한다.
정책이 학습 중에 본 적 없는 시작 상태를 만나면 실패하게 된다.
한 스킬이 끝났을 때의 종료상태 분포(빨간색)가 다음 스킬의 초기상태 분포(초록색)에 포함 되어야 한다.
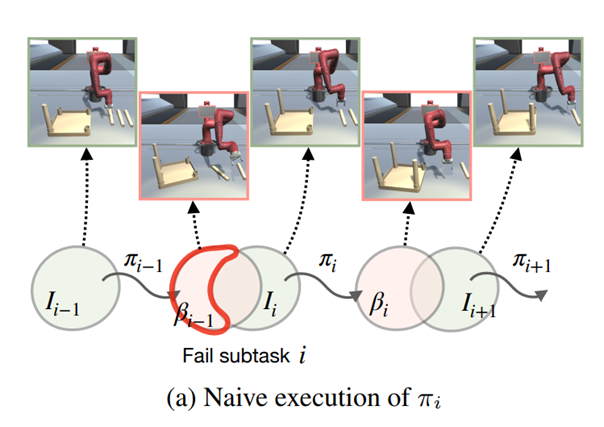
1번째: 기존 방식
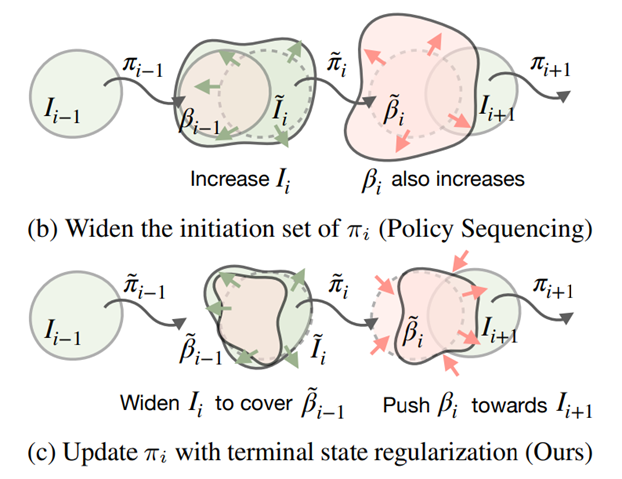
이전 정책의 종료상태 분포를 포함하도록 시작상태 분포를 강제로 넓힌다.
하지만 단순히 초기상태 분포를 넓히기만 해서는 자연스럽게 종료상태 분포 또한 늘어난다.
2번째: Adversarial Skill Chaining
종료 상태 분포를 정규화(제한)한다.
스킬(πᵢ) 파인튜닝 과정에서 종료상태가 다음상태의 초기상태가 되도록 학습한다.
초기 상태 판별기와 정책의 적대적 학습 프레임워크를 제안한다.
-
판별기 학습 시 이전 정책의 종료상태인지, 해당 정책의 초기 상태인지를 구분하도록 학습한다.
-
정책 학습 시 종료 상태가 판별기에서 "다음 정책의 시작 상태처럼 보이도록" 학습한다.
-
판별기의 출력을 보상으로 활용하여 정책 학습한다.
