
Soft Actor-Critic
: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
International Conference on Machine Learning (ICML), 2018
저자: Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, Sergey Levine
인용수: 약 10,894회 (2025년 4월 기준)
https://arxiv.org/abs/1801.01290
사실 제목에 모든 정보가 나와있다.
1. Actor-Critic
2. Off-Policy(Replay-Buffer)
3. Maximum Entroyp
4. Deep Reinforcement Learning
5. Stochastic Actor(policy)
Introduction
기존에는 다음과 같은 문제가 있었다.
1. On-Policy의 샘플 효율성 부족
2. 결정론적 정책 사용으로 인한 탐험부족
Q러닝의 경우 가장 큰 Q값만을 정책으로 결정하는 등 탐험이 부족해지는 문제가 있음.
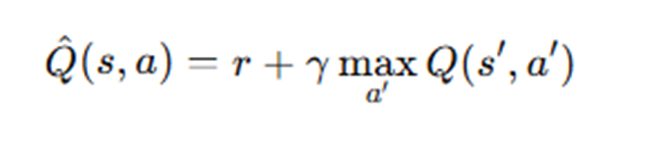
3. 외부 노이즈 사용으로 인한 하이퍼파리미터 민감성(DDPG)
결정론적 정책에 탐험을 주기 위해 DDPG에서는 가우시안 노이즈를 택했지만, 외부 노이즈이기 때문에 매우 민감해진다.
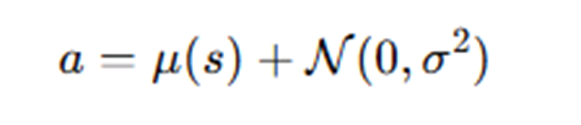
4. Q-러닝의 과대추정 문제
가장 큰 Q값만 고려하는 방식은 아웃라이어에 의해 Q값의 과대평가에 대처할 수 있는 방안이 없어서 학습이 불안정하다.
Entropy
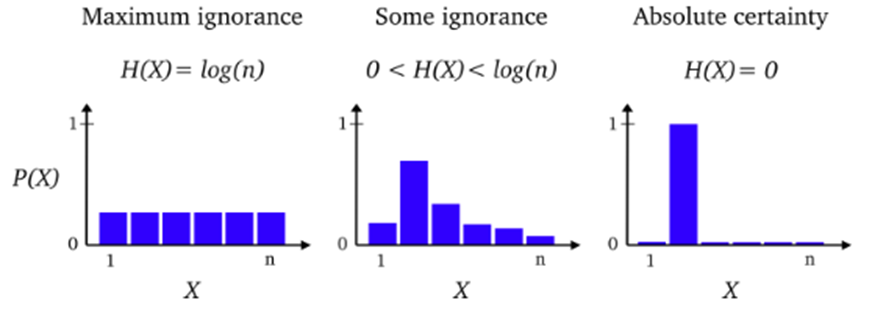
불확실성을 나타내는 지표로 사용되는 엔트로피
엔트로피가 높다: 균등분포(왼)
엔트로피가 낮다: 편향된 분포(오)
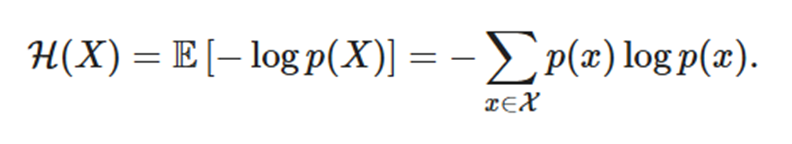 |  |
|---|
Entropy maximization
엔트로피를 보상함수에 추가함.
정책이 엔트로피가 높아지도록 유도되어 다양한 액션을 선택한다.
외부 노이즈가 아닌 정책 자체의 엔트로피를 조정하는 것이어서 안정성이 높다.
하지만 기존 방법들은 대부분 이산 행동 공간 가정
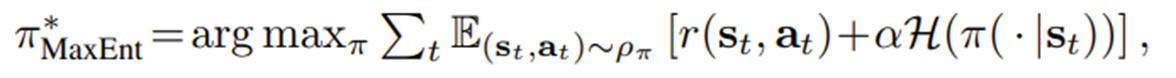
Reinforcement Learning with Deep Energy-Based Policies(2017)
Soft Actor-Critic
MDP = (𝒮, 𝒜, p, r)
𝒮: 상태 공간 (continuous)
𝒜: 행동 공간 (continuous)
p(s’|s, a): 상태 전이 확률 밀도
r(s, a): 보상 함수(엔트로피 포함) (유한 범위)
ρπ: 정책 π에 의해 유도된 상태(또는 상태-행동)의 확률분포
D: 리플레이 버퍼
𝛼: 온도 파라미터, 엔트로피항의 중요도를 조절한다.(𝛼=0이면 기존 강화학습)
보상함수에 엔트로피항을 추가하여 목적함수를 나타냄.
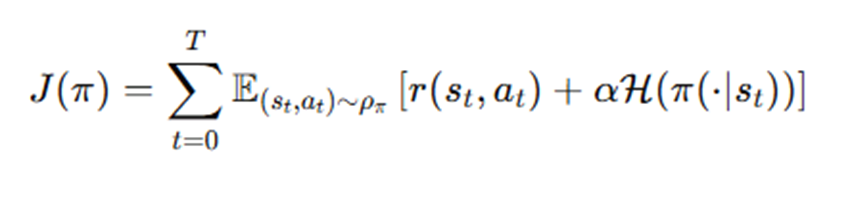
결국 정책이터레이션을 기초로하는 Actor-Critic을 훈련시키기위해선 Actor와 Critic이 정의되어야한다.
크게 V, Q, π가 모두 필요하다.
V는 Q를 훈련시키기 위한 보조 역할로서 동작한다.
π가 액터, Q가 크리틱으로 동작한다.
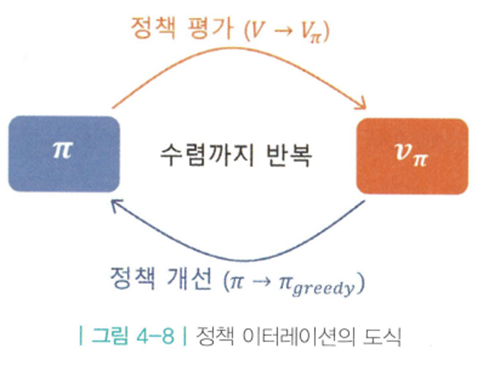
정책 평가
"벨만 백업(기대)연산자 T를 재귀적으로 적용하면, 결국 수렴한다."라는 정리를 통해 Q를 V로부터 학습시킨다.
V는 Q로부터 학습한다. 이때 V에 엔트로피 항을 추가하는 형식으로 엔트로피가 추가된다.
지금 정의된 V와 Q가 후속될 수식에서 많이 등장하므로 기억해두자
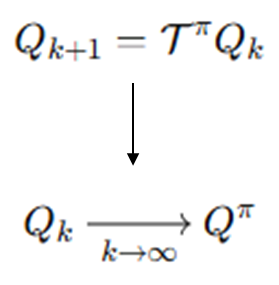 | 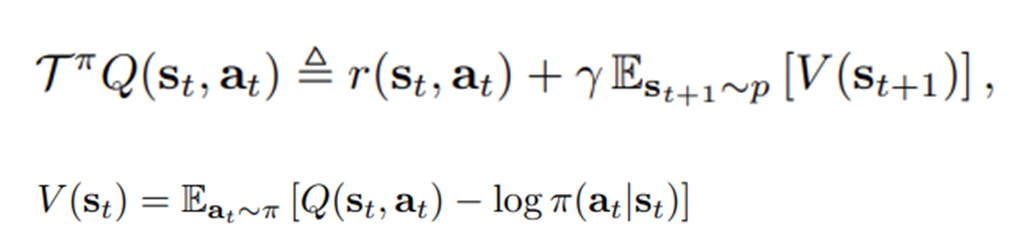 |
|---|
정책 개선
SAC 이전에는 높은 Q값만이 선택되는 정책을 펼쳤다면, 정책에 대해 Q벨류의 Softmax 분포를 기준으로 학습한다.(KL Divergence)
 | 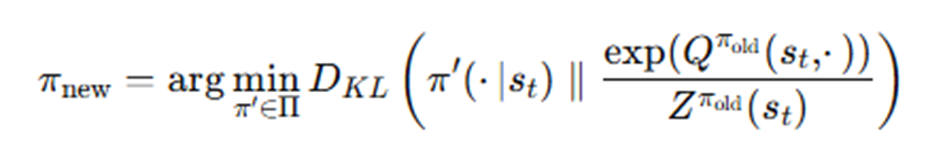 |
|---|
정책이 Q벨류의 Softmax분포를 닮아가는것이 학습의 목표이다.
개선된 정책πnew은 πold보다 Soft-Q를 향상시킴이 보장된다.
확률적으로 액션을 선택하기 떄문에 탐험 보장
Soft Policy Evaluation과 Soft Policy Improvement를 반복하면 결국 최적의 최대 엔트로피 정책에 수렴한다
V학습
MSE를 통해 V를 학습
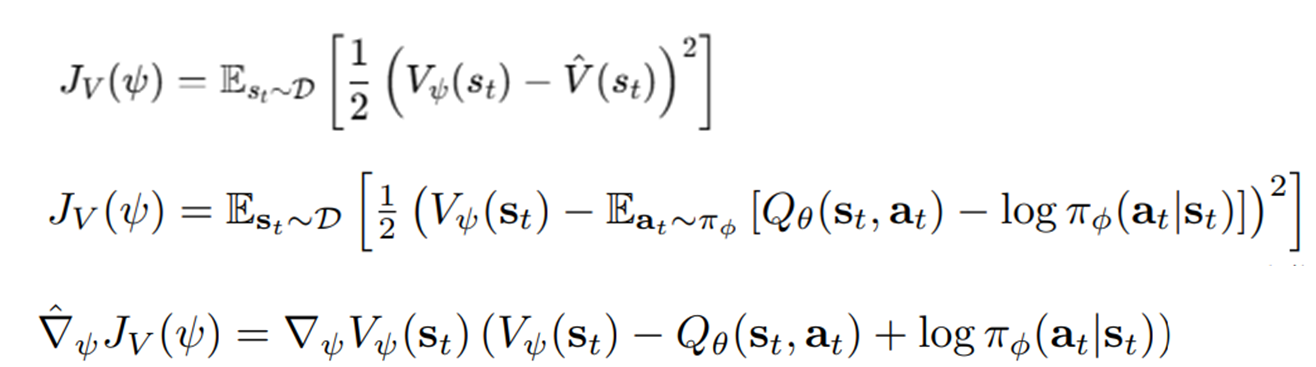
V는 Q와 정책으로부터 유도되므로, 이론상은 필요 없다.(후속에서 Q만 사용함)
하지만 훈련 안정화를 위해 V를 둔다.
Q학습
MSE를 통해 Q 학습
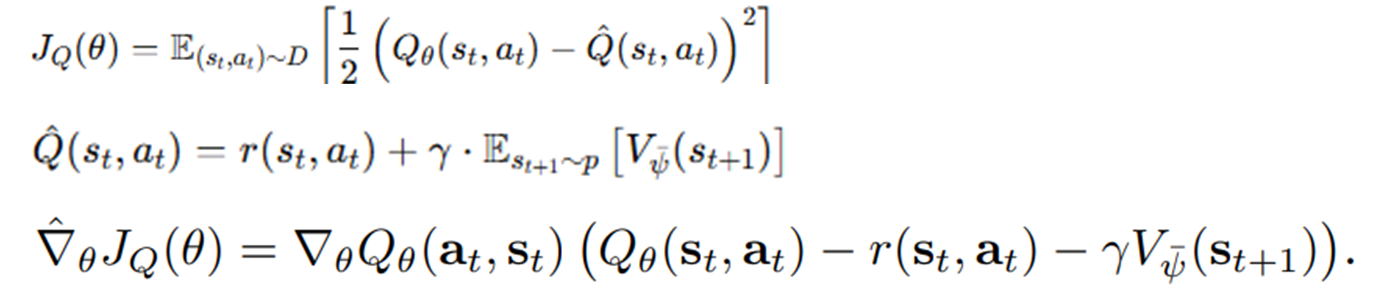
Q업데이트시에는 안정성을 위해 학습중인 V대신 타겟네트워크를 사용한다.
EMA로 업데이트, 혹은 일정주기마다 동기화 시켜준다.
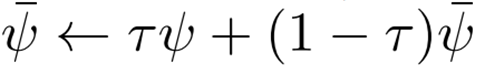
정책학습
정책은 Q값 Softmax 분포와의 KL Divergence로 학습한다.
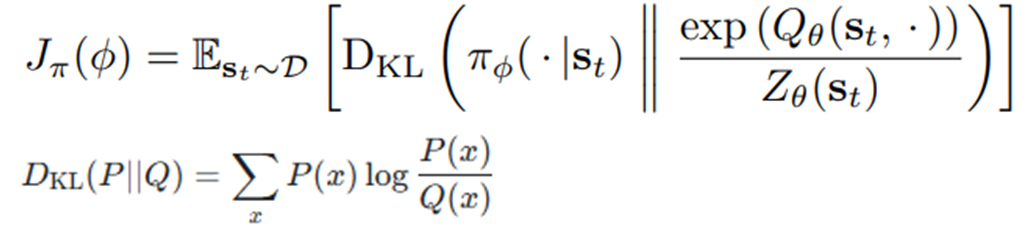
Z는 정규화 상수이므로 생략할 수 있다.
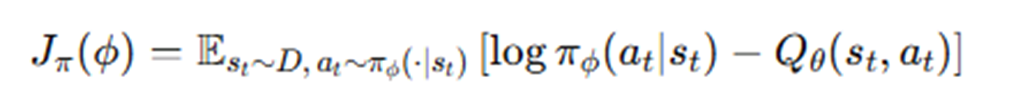
연속 환경에서 샘플을 뽑는 행위를 Ø식으로 표현하기 어려움 -> 미분이 어려워짐
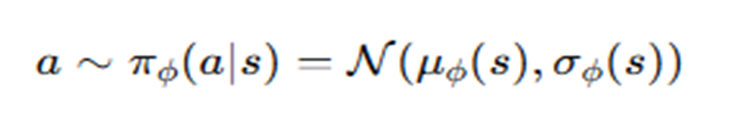
이를 해결하기위해 reparameterization trick 사용하여 a를 Ø에 대한 함수로 정의
정규분포에 분산을 곱하고 평균을 더해 원래 분포를 유사시킴
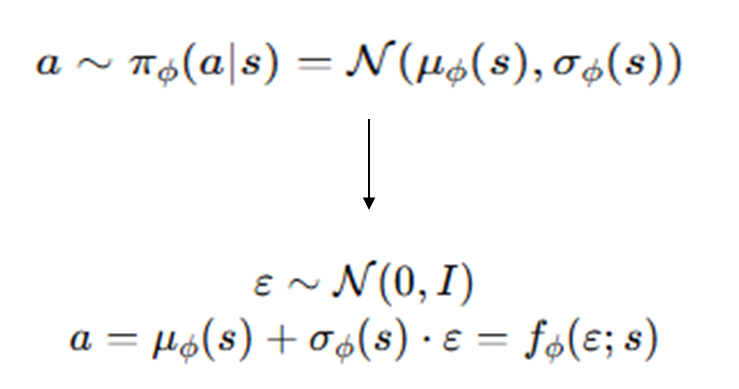
Ø에 대한 함수이니 미분이 손쉽게 가능함.
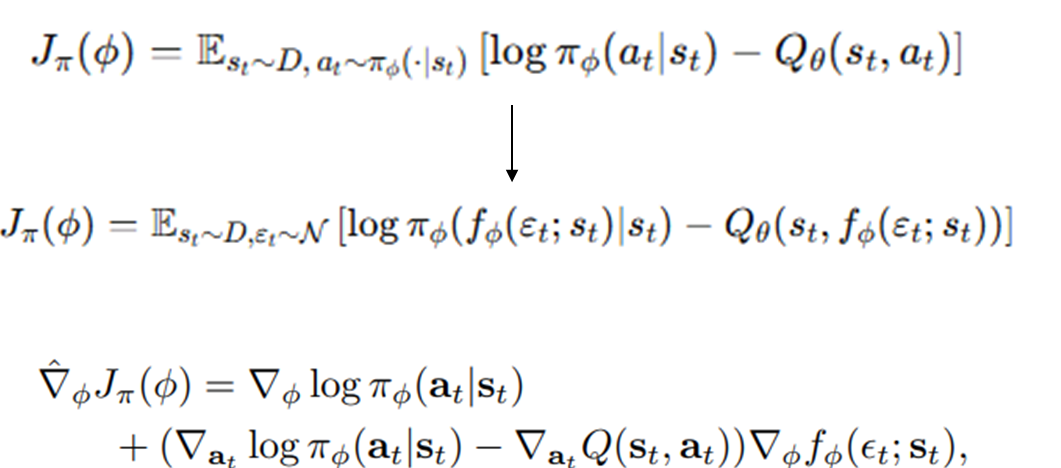
etc.
두 개의 Q 함수 사용, 독립적으로 학습한다.
V, π학습 시 두 Q 중 작은 값을 채택하여 노이즈로 인해 Q값이 높게 예측되었을 때 안정성을 제공함.
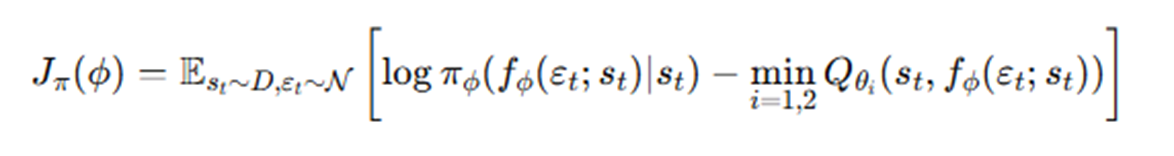
리플레이버퍼 사용(V, π는 s / Q는 s, a)
Summation
- 총 5개의 네트워크가 사용됨.(정책, Q 2개, V 1개, 타겟V 1개)
- 현재 정책으로 환경에서 데이터를 수집 → 버퍼에 저장
- 버퍼에서 샘플링하여 Q, V, π를 각각 업데이트
- V는 π 엔트로피와 Q의 기대값, Q는 V의 타겟을 사용하여 학습
- π는 Q로부터 유도되어 업데이트
- 타겟 네트워크는 EMA를 통해 업데이트
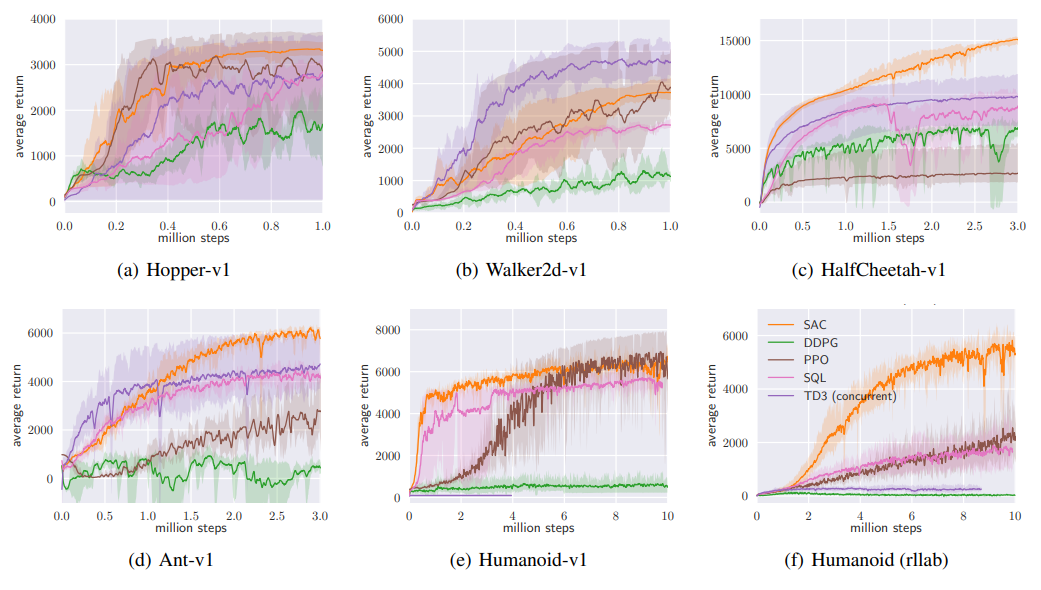
Results
서로 다른 5개의 랜덤시드 실험 진행, 1000스텝마다 평가
음영은 최대·최소, 실선은 평균
쉬운 과제에서 비슷한 성능, 어려운 과제에서 수렴 속도 및 최종 성능 우수
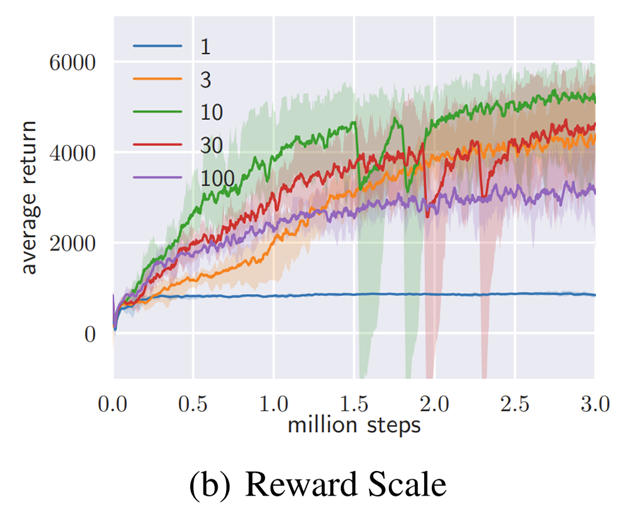
보상스케일 변수를 보상에 곱해 α값 대신 조절
보상스케일이 조정되면 상대적으로 엔트로피도 조정됨
보상스케일이 작으면, Uniform 이동
보상스케일이 크면, 초반 빠른 학습하지만 정책이 결정론적으로 변함.
보상스케일에 따라 성능변화가 크다.
 | 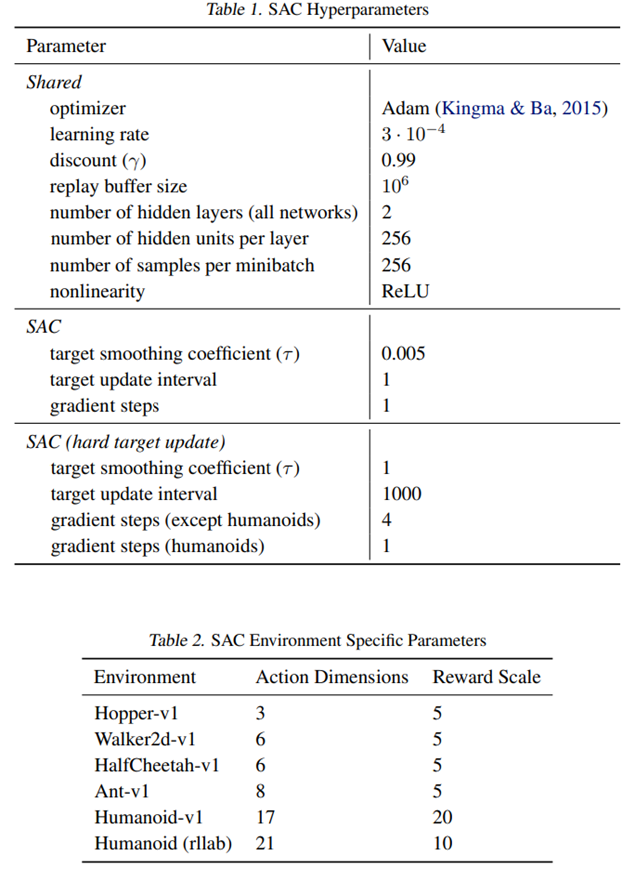 |
|---|
Reward Scale이 거의 유일한 하이퍼파라미터로 동작한다.
