
https://arxiv.org/abs/2110.06169
공식깃헙(flax): https://github.com/ikostrikov/implicit_q_learning
사설깃헙(pytorch): https://github.com/gwthomas/IQL-PyTorch
사전지식
On-policy: 정책(policy)을 평가하거나 개선할 때, 현재 학습 중인 정책 자체를 사용하여 데이터를 수집하는 방법.
-
학습 중인 정책으로 행동을 하고, 그 데이터를 사용해 그 정책을 업데이트함.
-
안정적이지만, 탐험(exploration)과 학습 사이 균형이 어려움.
off-policy: 현재 학습 중인 정책이 아닌 다른 정책(예: 과거 정책, 행동 정책)으로 수집된 데이터를 사용해 학습하는 방법.
-
과거 경험(Replay Buffer)을 재사용할 수 있어 데이터 효율이 높음.
-
다른 정책의 행동으로부터 학습할 수 있기 때문에 정책 개선이 유연함.
online Learning: 데이터를 실시간으로 관찰하고, 바로 학습에 사용하는 방식.
- 에이전트는 환경과 계속 상호작용하면서 모델을 점진적으로 업데이트함.
- On, off-policy 둘 다 가능하다.
offline Learning: 이미 수집된 고정된 데이터셋을 가지고 학습하는 방식 (환경과의 상호작용 없이).
- 실시간으로 환경과 상호작용하기 어렵거나, 비용이 많이 발생할 때 주로 쓰인다.
- off-policy만 가능하다.
문제정의
오프라인 강화학습을 위한 논문이다.(추후에 offline to online 도 가능)
온라인 상호작용 없이, 오직 사전에 수집된 데이터만을 기반으로 효과적인 정책을 학습하는 문제를 다룬다.
IQL이 해결하려는 오프라인 강화학습의 핵심 도전 과제는 다음 두 가지다:
-
정책 개선 (Policy Improvement):
더 나은 정책을 만들기 위해선, 기존 데이터에 없는 행동(out-of-distribution action)에 대해서도 Q값을 추정해야 한다.
→ 즉, 행동 정책(데이터를 수집한 정책)보다 더 나은 결정을 내리기 위해선 새로운 행동들을 평가하고 선택해야 함. -
분포 이동 (Distributional Shift):
하지만 데이터셋에 없는 행동에 대해 Q값을 추정하면, 그 값은 정확하지 않을 가능성이 크다.
→ 특히 학습된 Q함수는 본 적 없는 행동에 대해 Q값을 과도하게 높게 추정(overestimation) 하는 경향이 있다.
→ 이로 인해 잘못된 행동이 선택될 수 있으며, 전체 정책 성능이 크게 악화될 수 있다.
즉, "더 나은 정책을 만들려면 분포를 벗어나야 하지만, 벗어나면 정확성이 무너진다"는 딜레마가 존재하는 것이다.
요약
기존 오프라인 RL에서 actor는 policy를 직접 업데이트하지만, IQL은 좋은 Q를 강조하는 V를 먼저 만든 뒤, 마지막에 policy를 추출하는 "implicit" 방식이다.
간단하게 말하자면 핵심 아이디어는 다음과 같다.
1. "데이터 없던 액션은 실행하지 않는다.
-
OOD 액션(데이터셋에 없는 행동)을 아예 Q에 넣지 않음
-
target value도 전부 (데이터 모을 때 사용한 정책)에서 나온 행동들만 사용
-
⇒ distributional shift를 원천 차단
2. "기대절단 회귀(expectile regression)는 V(s)를 학습할 때 사용되며, 큰 Q(s,a)를 더 많이 반영하여, 좋은 행동 위주로 V(s)를 추정하게 만든다."
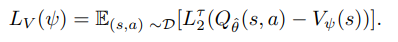
3. "transition에 의한 랜덤한 Q값의 상승을 방지하기 위해, target에 V(s')를 사용함으로써 lucky한 action의 영향을 줄인다."
-
Q(s,a)←r+γV(s')
-
어떤 transition에서 Q(s', a')가 높았던 게 운 좋게 좋은 s' 때문인지, a' 때문인지 구분이 안 됨
-
그래서 Q(s', a') 대신, V(s')로 평균화해서 안정적으로 업데이트
4. Policy 학습 방식
정책은 직접 Q를 최대화하지 않고, 학습된 Q와 V로부터 advantage 계산:
⇒ A가 클수록 해당 행동을 더 강하게 따라함
본문
기존의 오프라인 강화학습의 Loss는 다음과 같이 정의되었다.
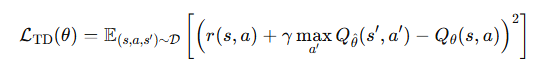
위 손실 함수에서 등장하는 분포 밖 행동(out-of-distribution action) 인 a'는 의 값을 부정확하게 추정하게 만들 수 있으며,
특히 정책이 Q값을 최대화하려고 할 때, 이는 과대추정(overestimation) 으로 이어질 수 있기 때문이다.
그렇기에 OOD에 대해 전혀 질의하지 않는 것을 목표로 하여 손실함수를 다음과 같이한다.
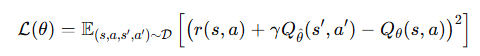
이 방식은 TD 손실이 오직 데이터셋 내 행동만을 사용하기 때문에 분포 밖 행동 문제를 완전히 회피할 수 있다.
하지만 이 방식은 복잡한 작업에서 성능이 저하된다.
기본적으로 위 식과 유사한 Q함수 업데이트를 수행하지만, 데이터 분포 내에 존재하는 행동들 중 최대 Q값을 추정하는 것을 목표로 한다.
형식적으론 다음과 같은 가치함수가 정의된다.
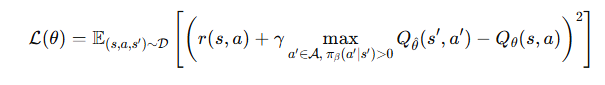
기대절단 회귀 (Expectile Regression)
u(오차)= x(샘플) - (예측한 기대절단값)로 정의 될 때.
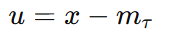
L2가 다음과 같이 정의될 때 손실함수가 다음과 같다.
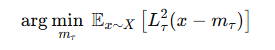 | 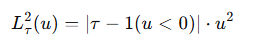 |
|---|
즉, τ > 0.5인 경우, 이 비대칭 손실 함수는 작은 값(x < mτ)에 대한 기여를 줄이고, 큰 값(x > mτ)에 더 많은 가중치를 부여한다.
ex)
u를 제곱하는데 τ=0.9이면,
x < mτ인 경우엔 → 작은 가중치 (1−τ) = 0.1
x > mτ인 경우엔 → 큰 가중치 τ = 0.9
평균보다 큰 애들이 오차를 0.9배로 반영
평균보다 작은 애들은 오차를 0.1배만 반영
기대절단 회귀로 가치 함수 학습
단순한 TD 방식에 기대절단 회귀를 반영하면 다음과 같은 손실함수를 얻을 수 있다.
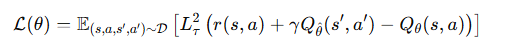
하지만, 이러한 방법은 액션만 평가하는 것이 아니라 transition에 의한 randomness도 함께 반영된다.
그렇기에 상태가치함수 V를 도입하여 전이에서 발생하는 확률성의 평균을 취함으로써 "운좋은샘플" 문제를 회피한다.
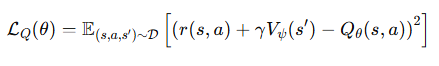
그리고 V를 학습할 때 위에서 본 기대절단 회귀를 사용한다. 큰 Q가 커질 때 학습 가중치가 커지고, Q가 작아질 때 학습가중치가 작아진다.
즉, 높은 Q값을 따라가도록 V를 유도하고 있으며 이로인해 정책 없이도 implicit하게 잘된 행동만 따라가다록 학습가능하다.
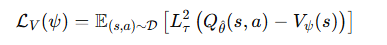
이 두 학습과정 모두 정책을 사용하지 않고, 오직 데이터셋 내에서만 행동한다.
정책 추출
이렇게 수정된 TD학습 절차를 거쳐 최적 Q함수의 근삿값을 얻어 내었으니 정책을 추출하는 단계가 필요하다.
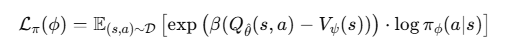
여기서: 𝛽 ∈ [0,∞) 역온도 파라미터(inverse temperature)
이 손실함수는 일반적인 behavioral cloning의 확장으로, Advantage(Q-V)가 높은 행동일수록 더 강하게 학습되도록 유도한다.
-
작을수록 행동 복제(behavioral cloning)에 가까운 형태
-
클수록 Q값이 최대가 되는 행동을 추출하는 쪽으로 작동
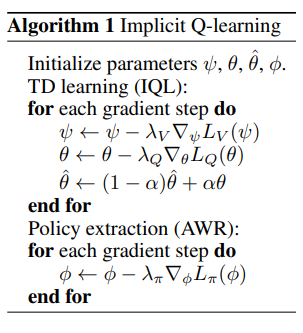
전체 알고리즘 요약
최종 알고리즘은 다음 두 단계로 구성된다:
- 가치 함수와 Q함수 학습
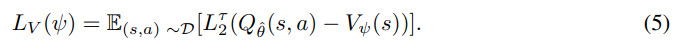
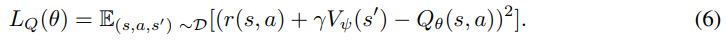
식 (5)와 (6)을 번갈아 사용하여 여러 번의 그래디언트 업데이트 수행
V와 Q 학습에는 Clipped Double Q-Learning을 사용 → 두 Q함수 중 최솟값을 사용하여 과대추정 방지
- 정책 학습 (Policy Extraction)
정책 추출식 에 대해 확률적 경사 하강법(SGD) 수행
실험
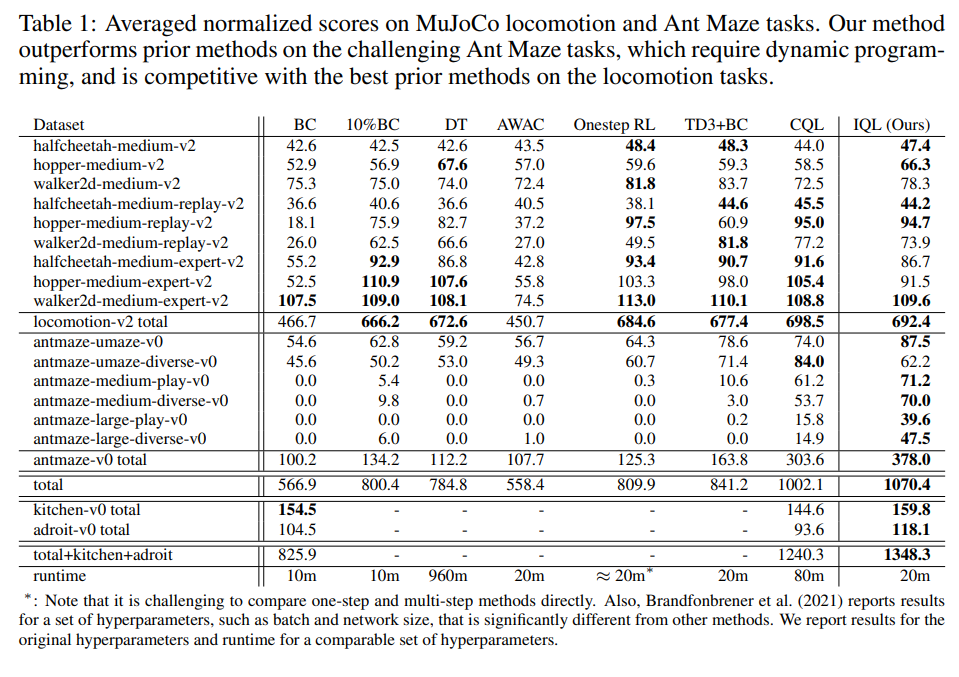
MuJoCo benchmark에서는 기존의 오프라인 RL 알고리즘을 상회하며, 특히 high-data regime에서의 일반화 성능이 뛰어났다.
IQL은 기존의 actor-critic 구조 없이도 policy를 간접적으로 추출함으로써, 오프라인 데이터만으로 안정적인 학습이 가능하다는 점에서 기존 CQL이나 BCQ와 차별화된다.
