
만약 동일한 점들이 주어지고 이점을 대표할 수 있는 함수를 추정하는 경우, 가운데가 optimize하다고 한다면
- 왼쪽은 지나친 단순화로 인해 에러가 많이 발생해 underfitting이라고 한다.
- 오른쪽은 trianing sample에 대해서 너무 정확하게 표현하여 새로운 test sample에 대해서는 에러가 나는걸 확인할 수 있다.
내용 및 사진 출처: https://22-22.tistory.com/35
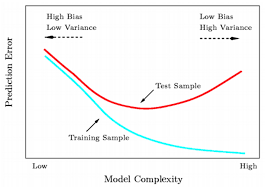
-> trianing sample에 대한 과도한 학습/ 모델이 복잡해지면서 새로운 test sample에 대해서는 loss가 낮아지다가 점점 높아지는걸 확인할 수 있다.
overfitting이란 무엇인가?
multiple linear regression에서 train data에 대한 과도한 학습으로 인해서 train data에 대한 prediction의 정확도가 너무 높아져 새로운 data에 대한 정확도가 낮아지는 현상 / 모델의 일반성이 낮아진다.
모델의 complexity가 높아져도 발생
어떻게 인지하는가?
과거 데이터를 학습한 multiple linear regression에서 새로운 data에 대한 prediction 정확성이 매우 낮을때
해결
1) cross-validation(k-fold국룰)
2) Regularization
- 모델의 복잡성을 줄여 일반화된 모델을 구현하기 위한 방법 -> 모델의 weight에 대해서 패널티를 부여(L1, L2 정규화)
- L1 정규화 -> 불필요한 feature에 대응되는 weight를 정확히 0으로 만듬
- L2 정규화 -> 아주 큰 값이나 작은 값을 가지는 이상치에 대한 weight를 0에 가까운 값으로 만듦
- 정규화 방법을 적용한 Regression 알고리즘에 Regularization을 적용한 방식에 따라 Lasso, Ridge,Elasticnet Regression으로 분류
3) data augmentation(학습 데이터 늘리기)
4) dropout: 학습할때 뉴런을 끄고 학습
5) Model capacity 낮추기: 모델이 학습 데이터에 비해 과하게 복잡하지 않도록, hidden layer 크기를 줄이거나 layer 개수를 줄이는 등 모델을 간단하게 만듦.
Test Set Accuracy가 증가하다가 감소하면 학습 데이터가 부족한 경우로 볼 수 있다. 학습 데이터를 늘릴 필요가 있다. 이미지 같은 경우 이미지의 비율을 바꾸거나, 일부분을 가리거나, 회전하는 것으로 데이터를 늘릴 수 있다.
Training Set Accuracy가 100%에 가깝지만 Test Set Accuracy가 상당히 낮은 경우가 있다. 학습 데이터가 편향되어 있지 않은지 확인할 필요가 있다. 특수한 경우의 데이터를 가지고 일반적 문제를 해결하는 경우가 해당될 수 있다.
내용 참조: https://22-22.tistory.com/35
Underfitting이란 무엇인가?
이미 있는 train set에 대해서도 학습을 하지 못한 상태.
왜 발생?
- 학습 반복 횟수가 너무 적음
- 데이터 특성에 비해 모델이 너무 간단함
- 데이터 양이 너무 적음
정리
오버피팅은 train set에 대해서 과도하게 맞춰져서 새로운 데이터에 대한 예측 정확도가 떨어지면서 일반성이 떨어지는 현상
심화 내용 링크
http://sanghyukchun.github.io/59/
출처:
1.앨리스 머신러닝 중급과정 내용참조
2.overfitting사진 & 3가지 예측 유형 사진:https://22-22.tistory.com/35
