동기
내가 아는 embedding의 개념은 자연어 혹은 entity들을 사용자가 원하는 의미적 유사도대로 임베딩 space에 수치화 해서 배치하는것으로 알고 있다.
근데 자연어인 lyrics를 바로 nn.Embedding에 통과 시키는것이 아닌 Lyrics가 이미 vector화 되어있는 텐서 상태로 통과 시키는것일까?
lexical embedding 방법
embedding의 과정 - Embedding layer 방식의 embedding
Background
Embedding이란
tokenization이란
nn.Embedding의 작동원리
- "인덱스"에 대해서 lookup table로 만들어주는것
- 토큰들(수치화가 되었든 안되었든)에 대해서 인덱스에 대해 아무무 tensor 수치로 L
Lyrics 는 토크나이저 -> 일반적인게 아닌 g2p 포니밈용 토크나이저
f0 는 128개의 level이고
Frame -> 시간
128개의 Level은 음의 높낮이로 embedding
애초에 시간으로 하는게 아님 잘못된 접근
임베딩과정
[멜로디]
1. 프레임(시간)별로 descrete하게 나뉘어진 128 종류의 Level(음의 높낮이)를 토큰화 시킴
ex) 20ms로 나뉘어진 f0
| 단계 | 설명 |
|---|---|
| 원본 시퀀스 | 도 레 미 미 시 파 도 |
| 토큰화 | 0 1 2 2 4 5 0 → 정수 인덱스로 변환됨 |
| 임베딩 통과 | 각 토큰 인덱스가 임베딩 벡터로 변환됨 (예: vec1, vec2, ..., vecN) |
| 임베딩 결과 | vec0 vec1 vec2 vec2 vec4 vec5 vec0 → 각 토큰별 의미 벡터 |
| Mean Pooling | 전체 시퀀스의 임베딩 벡터 평균을 계산하여 길이 1의 벡터로 축소됨 |
| 최종 출력 | 평균 임베딩 벡터 (예: mean(vec0, vec1, vec2, vec2, vec4, vec5, vec0)) |
- 결과물은 도 레 미 미 시 파 도의 representation이 만들어짐
- 각각의 Vector들로 나오는것은 수치화된 도, 레, 미, 미, 시, 파, 도와 매핑이 되어있음.
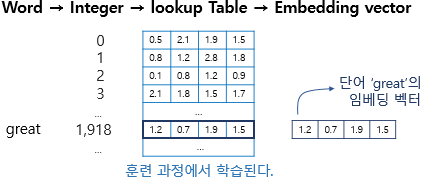
Lookup table이란
- token들의 "인덱스"별 vector representation
CONTEXT_SIZE = 2
EMBEDDING_DIM = 10
# 셰익스피어 소네트(Sonnet) 2를 사용하겠습니다.
test_sentence = """When forty winters shall besiege thy brow,
And dig deep trenches in thy beauty's field,
Thy youth's proud livery so gazed on now,
Will be a totter'd weed of small worth held:
Then being asked, where all thy beauty lies,
Where all the treasure of thy lusty days;
To say, within thine own deep sunken eyes,
Were an all-eating shame, and thriftless praise.
How much more praise deserv'd thy beauty's use,
If thou couldst answer 'This fair child of mine
Shall sum my count, and make my old excuse,'
Proving his beauty by succession thine!
This were to be new made when thou art old,
And see thy blood warm when thou feel'st it cold.""".split()
# 원래는 입력을 제대로 토큰화(tokenize) 해야하지만 이번엔 간소화하여 진행하겠습니다.
# 튜플로 이루어진 리스트를 만들겠습니다. 각 튜플은 ([ i-CONTEXT_SIZE 번째 단어, ..., i-1 번째 단어 ], 목표 단어)입니다.
ngrams = [
(
[test_sentence[i - j - 1] for j in range(CONTEXT_SIZE)],
test_sentence[i]
)
for i in range(CONTEXT_SIZE, len(test_sentence))
]
# 첫 3개의 튜플을 출력하여 데이터가 어떻게 생겼는지 보겠습니다.
print(ngrams[:3])
vocab = set(test_sentence)
word_to_ix = {word: i for i, word in enumerate(vocab)}
class NGramLanguageModeler(nn.Module):
def __init__(self, vocab_size, embedding_dim, context_size):
super(NGramLanguageModeler, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.linear1 = nn.Linear(context_size * embedding_dim, 128)
self.linear2 = nn.Linear(128, vocab_size)
def forward(self, inputs):
embeds = self.embeddings(inputs).view((1, -1))
out = F.relu(self.linear1(embeds))
out = self.linear2(out)
log_probs = F.log_softmax(out, dim=1)
return log_probs
losses = []
loss_function = nn.NLLLoss()
model = NGramLanguageModeler(len(vocab), EMBEDDING_DIM, CONTEXT_SIZE)
optimizer = optim.SGD(model.parameters(), lr=0.001)
for epoch in range(10):
total_loss = 0
for context, target in ngrams:
# 첫번째. 모델에 넣어줄 입력값을 준비합니다. (i.e, 단어를 정수 인덱스로
# 바꾸고 파이토치 텐서로 감싸줍시다.)
context_idxs = torch.tensor([word_to_ix[w] for w in context], dtype=torch.long)
# 두번째. 토치는 기울기가 *누적* 됩니다. 새 인스턴스를 넣어주기 전에
# 기울기를 초기화합니다.
model.zero_grad()
# 세번째. 순전파를 통해 다음에 올 단어에 대한 로그 확률을 구합니다.
log_probs = model(context_idxs)
# 네번째. 손실함수를 계산합니다. (파이토치에서는 목표 단어를 텐서로 감싸줘야 합니다.)
loss = loss_function(log_probs, torch.tensor([word_to_ix[target]], dtype=torch.long))
# 다섯번째. 역전파를 통해 기울기를 업데이트 해줍니다.
loss.backward()
optimizer.step()
# tensor.item()을 호출하여 단일원소 텐서에서 숫자를 반환받습니다.
total_loss += loss.item()
losses.append(total_loss)
print(losses) # 반복할 때마다 손실이 줄어드는 것을 봅시다!
# "beauty"와 같이 특정 단어에 대한 임베딩을 확인하려면,
print(model.embeddings.weight[word_to_ix["beauty"]])
존나 재밌는것을 맨듭니다.