🚨ppt에서 나오는 설명 문제 15개 숙제에서 나오는 문제 2개
Chapter4: The Processor
파이프라인 레지스터(pipeline registers)
- 단계들(stages) 사이에 레지스터 필요 <- 이전 cycle에서 생성된 정보를 저장(hold)하기 위해
🚨datapath 그림 속 명칭들을 기억하기!!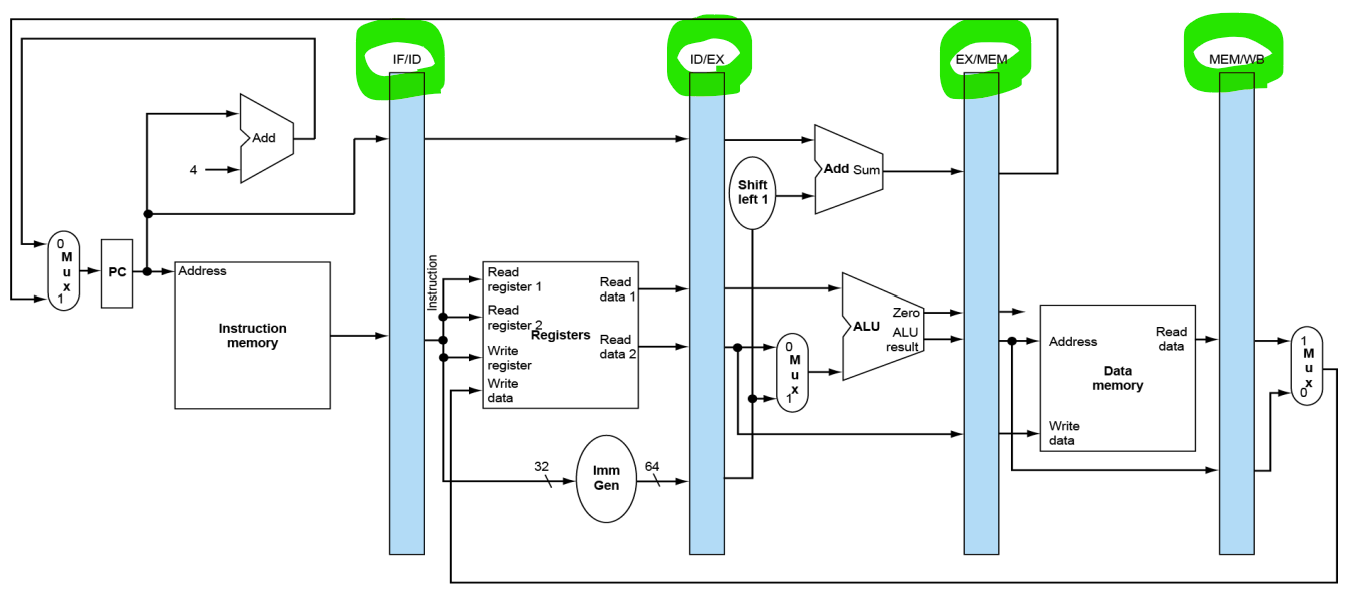 - 초록 동그라미: stage 사이에 stay하기 위한 버퍼
- 초록 동그라미: stage 사이에 stay하기 위한 버퍼
파이프라인 컨트롤 로직(pipelined control)
- hazard 피할 수 있는 파이프라인 설계
🚨숙제로도 나온 것으로 한 문제 출제 가능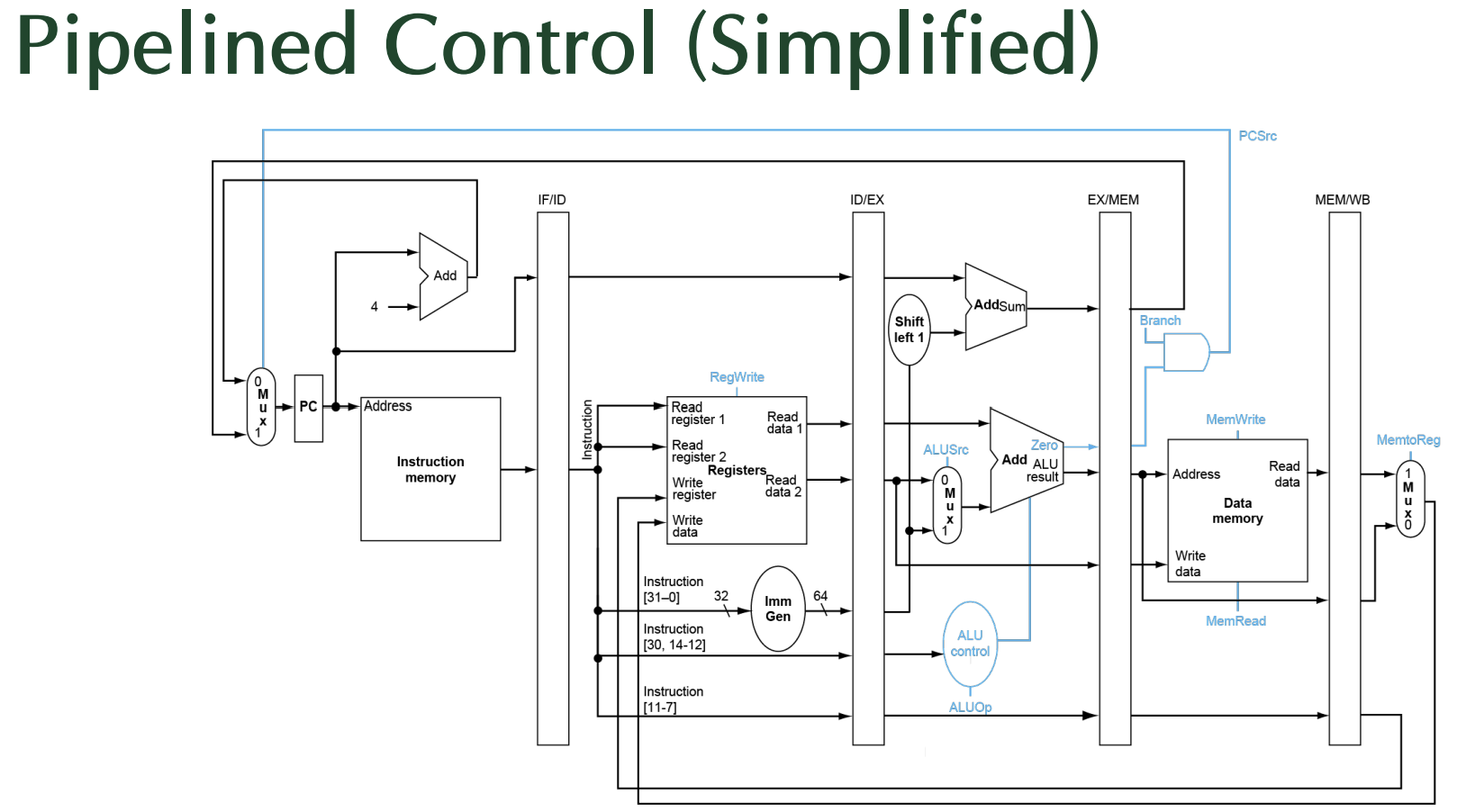
Data Hazards in ALU Instructions
< data hazard 발생하는 상황>
output이 input으로 바로 들어올 때 data hazard 발생
중요 -> hazard를 우회하는 방법!
- Dependencies & Forwarding
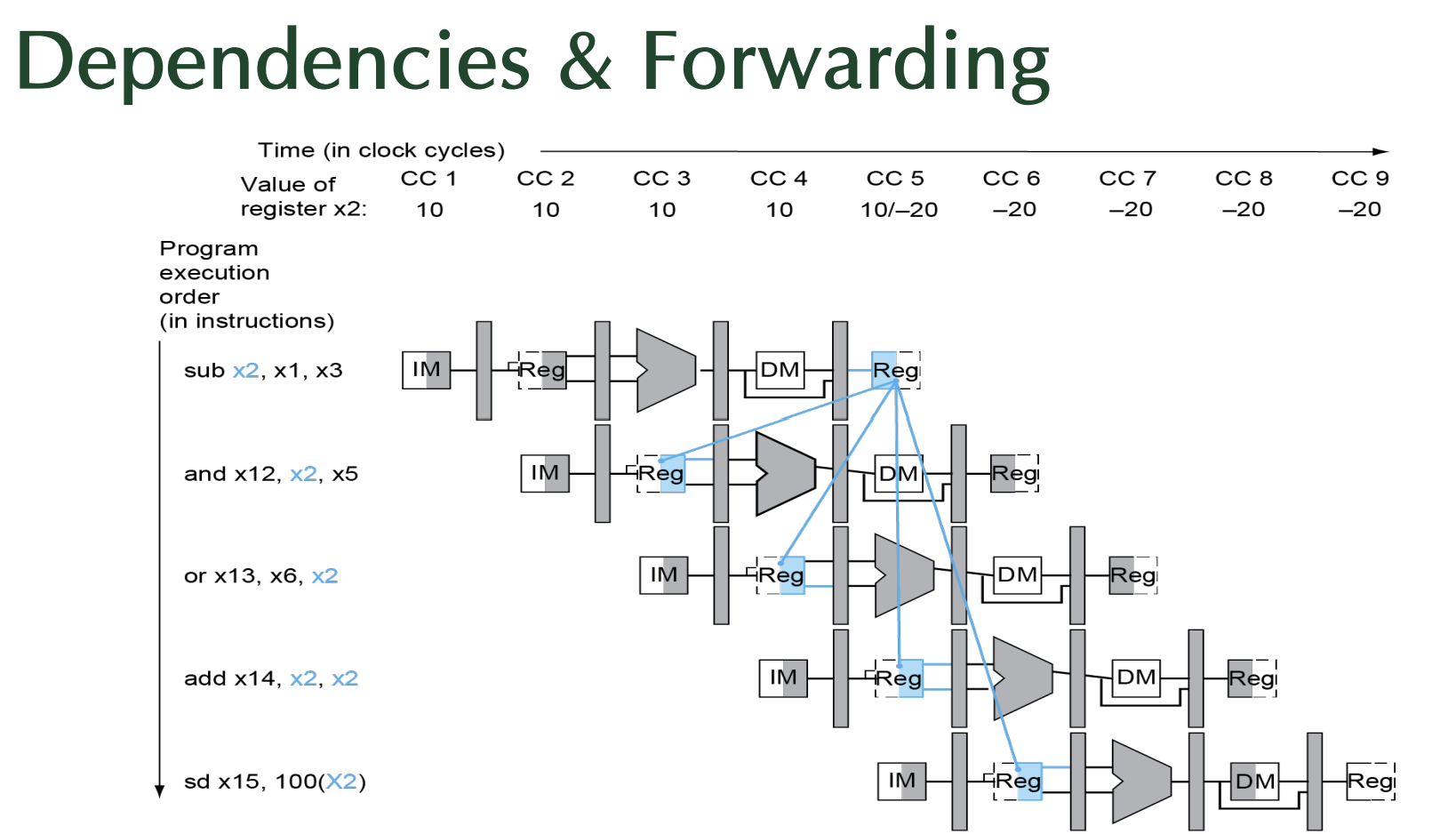
- 포워딩 필요 여부 감지
- 레지스터 번호를 파이프라인을 따라 전달 (Pass register numbers along the pipeline)
- ex. ID/EX.RegisterRs1 = ID/EX 파이프라인 레지스터에 있는 Rs1의 레지스터 번호
- EX 단계에서 ALU 피연산자(operand) 레지스터 번호:
- ID/EX.RegisterRs1, ID/EX.RegisterRs2
- Data Hazard가 발생하는 경우
- 1a. EX/MEM.RegisterRd = ID/EX.RegisterRs1
- 1b. EX/MEM.RegisterRd = ID/EX.RegisterRs2
- 2a. MEM/WB.RegisterRd = ID/EX.RegisterRs1
- 2b. MEM/WB.RegisterRd = ID/EX.RegisterRs2
=> 1a, 1b는 EX/MEM 파이프라인 레지스터에서 포워딩 발생(Forward from EX/MEM pipeline register)
=> 2a, 2b는 MEM/WB 파이프라인 레지스터에서 포워딩 발생 (Forward from MEM/WB pipeline register) - 포워딩 필요 여부 조건
- 포워딩 명령어(forwarding instruction이 register에서 write(쓰기)를 수행하는 경우에만!!!
- 그리고 해당하는 명령어의 Rd가 x0이 아닌 경우에만!!
-> ex. EX/MEM.RegisterRd ≠ 0, MEM/WB.RegisterRd ≠ 0
- 그리고 해당하는 명령어의 Rd가 x0이 아닌 경우에만!!
- 레지스터 번호를 파이프라인을 따라 전달 (Pass register numbers along the pipeline)
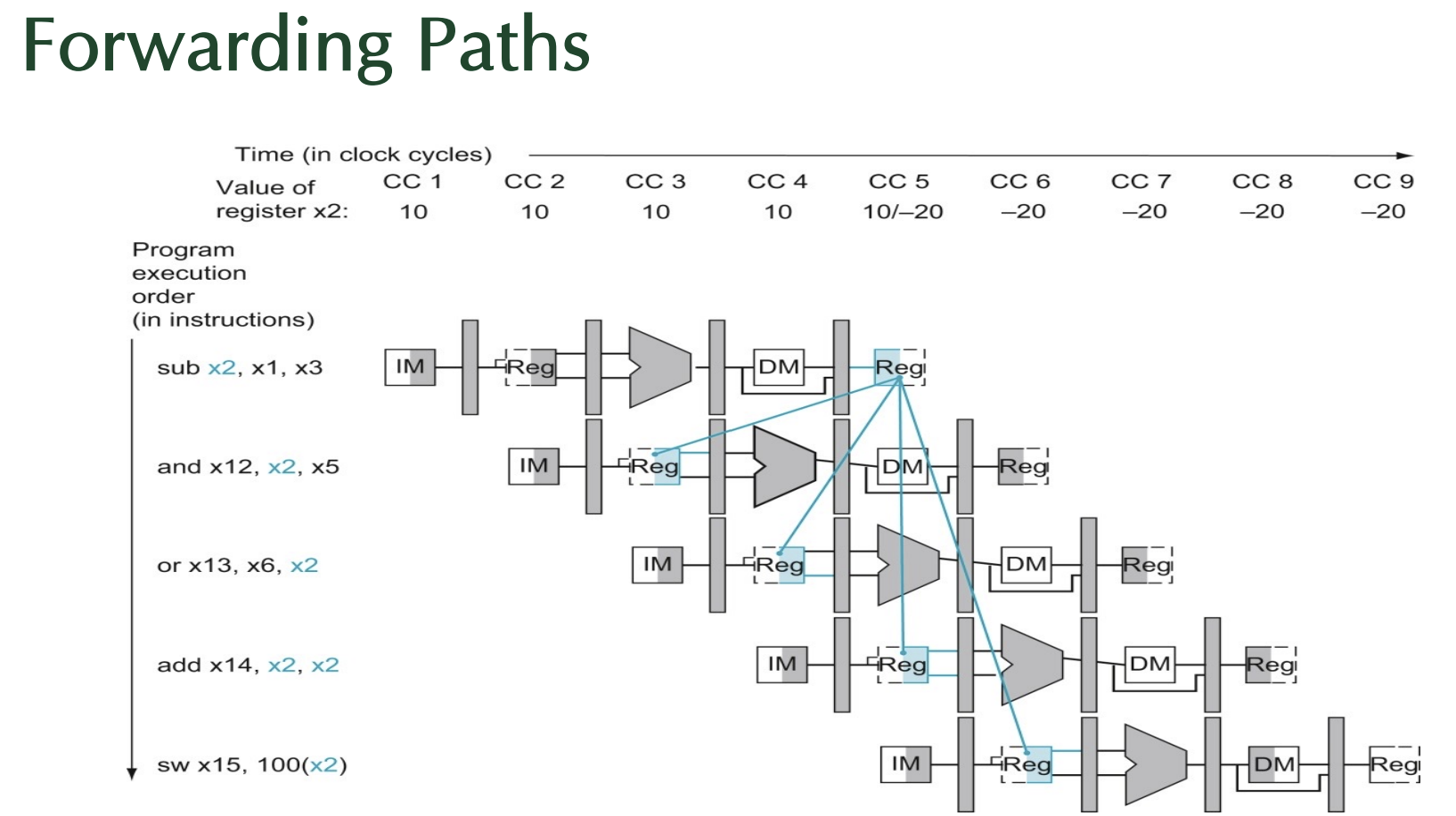
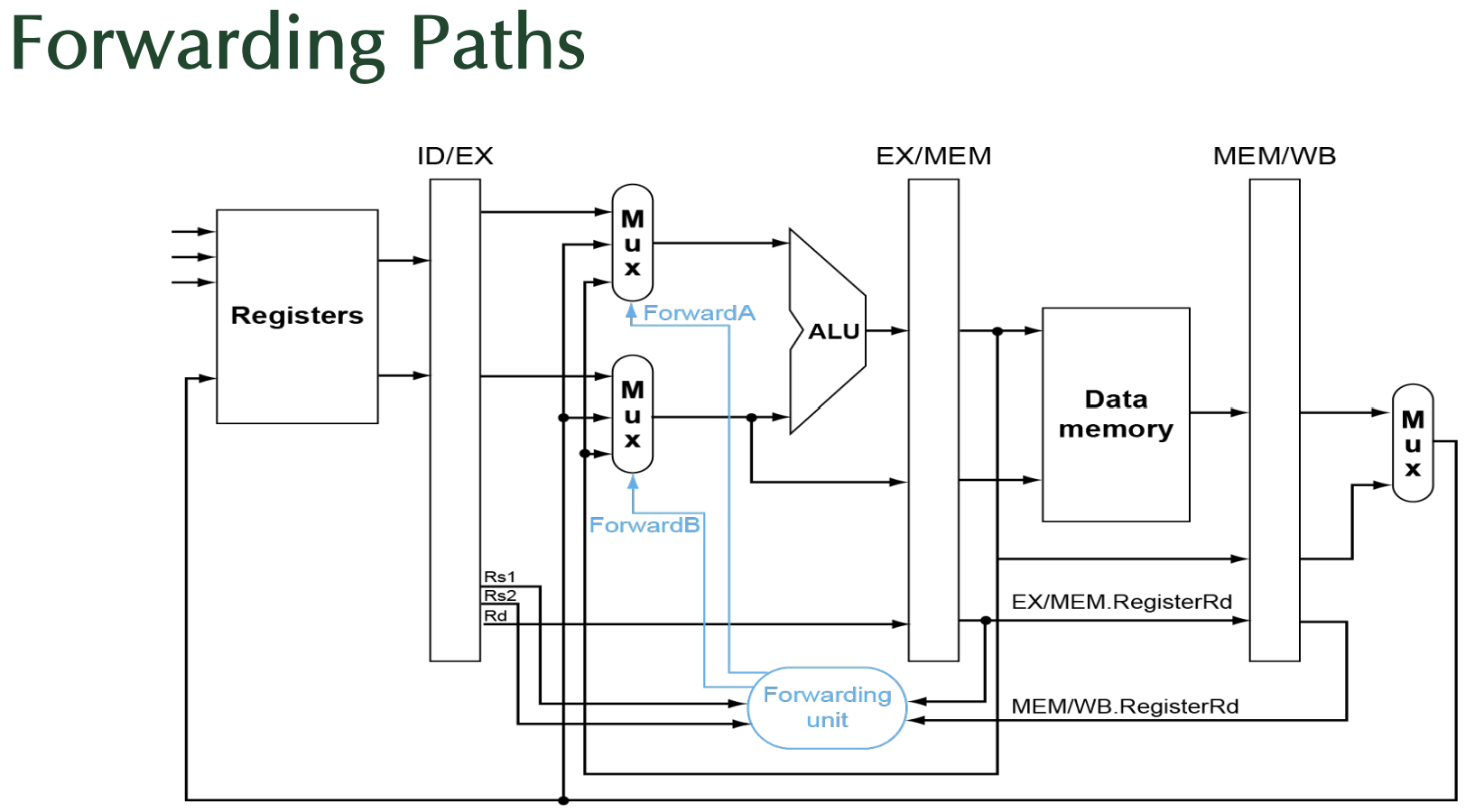
< Data Hazard 해결 위해 필요한 데이터를 올바른 소스에서 가져오는 방법을 정의하는 조건>
| Mux control(제어 신호) | source | 설명 |
|---|---|---|
| ForwardA = 00 | ID/EX | 첫 번째 ALU 피연산자가 레지스터 파일에서 가져옴 |
| ForwardA = 10 | EX/MEM | 첫 번째 ALU 피연산자가 이전 ALU 결과에서 포워딩됨 |
| ForwardA = 01 | MEM/WB | 첫 번째 ALU 피연산자가 데이터 메모리 또는 이전 ALU 결과에서 포워딩됨 |
| ForwardB = 00 | ID/EX | 두 번째 ALU 피연산자가 레지스터 파일에서 가져옴 |
| ForwardB = 10 | EX/MEM | 두 번째 ALU 피연산자가 이전 ALU 결과에서 포워딩됨 |
| ForwardB = 01 | MEM/WB | 두 번째 ALU 피연산자가 데이터 메모리 또는 이전 ALU 결과에서 포워딩됨 |
- Forward A, B: A= 첫 번째 ALU 피연산자 제어, B= 두 번째 ALU 피연산자 제어
- 00 (ID/EX): 데이터를 새로 읽는 경우
- 10 (EX/MEM): 바로 전 단계에서 연산된 결과를 사용하는 경우
- 01 (MEM/WB): 이미 메모리에 저장된 데이터나 더 오래된 연산 결과를 사용하는 경우
파이프라인 멈추는 방법(How to Stall the Pipeline)
🚨stall을 다루는 2가지 방법!!
-
- ID/EX 레지스터의 제어 값(control values)을 0으로 강제 설정
- EX, MEM, WB 단계에서 nop(no-operation)을 실행
-
- PC(Program Counter)와 IF/ID 레지스터의 업데이트를 방지
- 사용 중인 명령어가 다시 decode
- 이후의 명령어(Following instruction)가 다시 fetcch
- 1-cycle stall은 MEM이 ld(load)를 위해 데이터를 읽을 수 있도록 함
- 이후에 해당 데이터를 EX 단계로 stage할 수 있음
control hazard를 막는 방법
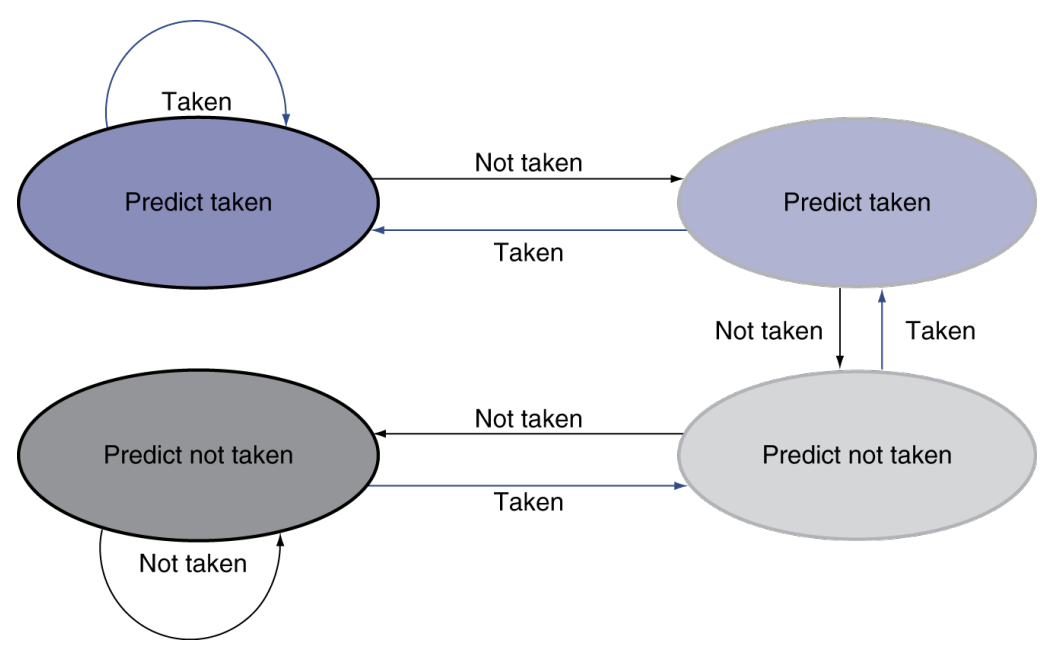
2-Bit Predictor
- 2번 연속으로 예측이 실패했을 때만 예측을 변경 (2번 물어보는 process)
Exception Properties(예외 처리)
-
재시작 가능한 예외(Restartable exceptions)
- 파이프라인이 해당 명령어를 flush할 수 있음
- Handler가 실행된 후, 해당 명령어로 돌아감
- 명령어를 다시 가져와(refetch) -> 처음부터 다시 실행(executed from scratch)
-
PC가 SEPC 레지스터에 저장됨
-예외를 일으킨 명령어를 식별함(identifiy)
Multiple Issue
🚨2개(static/dynamic 뭐가 다른지 알기!)
- 정적(Static multiple issue)
- 컴파일러가 함께 발생할 명령어를 그룹화
- 이 그룹화된 명령어를 issue slots에 패키징함
- 컴파일러가 hazard를 감지하고 이를 회피함
- 동적(Dynamic multiple issue)
- CPU가 명령어 stream을 분석(examine)하여 매 cycle에 발행할 명령어를 선택
- 컴파일러가 명령어를 재배치(reorder)하여 도움을 줄 수 있음
- CPU가 실행시간(runtime)에 고급 기술을 사용해 hazard를 해결
➡️Static Multiple Issue
- 컴파일러가 명령어를 "이슈 패킷(issue packets)"으로 그룹화함
- 명령어 그룹(Group of instructions): 단일 cycle에 실행될 수 있는 명령어 그룹
- 파이프라인 자원 요구사항에 따라 결정됨
- 이슈 패킷(issue packects)을 매우 긴 명령어로 여김
- 여러 동시 연산(multiple concurrent operations)을 지정함
=> 매우 긴 명령어 워드: VLIW == Very Long Instruction Word
- 여러 동시 연산(multiple concurrent operations)을 지정함
➡️Scheduling Static Multiple Issue
- 컴파일러는 일부 또는 모든 hazard를 제거해야함
- 명령어를 이슈 패킷(issue packets)으로 재배열
- 패킷 내에는 의존성(dependency)이 없어야함
- 패킷 간에는 일부의 의존성이 있을 수 있음
- ISA(Instruction Set Architecture)에 따라 다르며, 컴파일러가 이를 알아야함!
- 필요시 nop로 채워야함(pad)
Loop Unrolling
- loop body를 복제(replicate)하여 더 많은 병렬성(parallelism)을 노출
- loop-control overhead 감소
- "register renaming": replication마다(복제할 때마다) 다른 레지스터를 사용
- "name dependence": loop에 의해 발생하는(loop-carried) 반의존성(anti-dependencies) 회피
- 동일한 레지스터를 로드한 후 저장
- 레지스터 이름 재사용
🌟루프 언롤링: 반복되는 루프를 복제하여 병렬 작업 기회를 증가시키는 최적화 기법
<루프 언롤링이 수행된 방식>
- loop body 복제: loop가 4번 반복될 것을 예상하고, 이를 한번의 루프 내에서 모두 실행되도록 함 (ex. ld, add 명령어가 4번씩 복제됨)
- 병렬성 증가: 복제된 명령어들이 동시에 사용될 수 있도록 별도의 레지스터(x28, x29, x30, x31)을 사용함
- Register Renaming: 복제된 명령어가 동일한 레지스터를 사용하지 않도록 새로운 레지스터 이름이 부여됨
- Nop 추가: 파이프라인에서 공백을 방지하기 위해 필요시 Nop(No Operation) 명령어 추가
- IPC 개선: IPC(Instruction Per Cycle)는 14개의 명령어가 8개의 사이클 동안 실행되므로, IPC는 1.75로 계산
- 병렬성 증가로 IPC가 이상적으로 2에 더 가까워짐, but register와 code size 증가라는 cost 발생
➡️Dynamic Multiple Issue
- 슈퍼스칼라(Superscalar) 프로세서
- CPU가 매 사이클마다 0, 1, 2개 등등등 몇 개의 명령어를 실행할지(issue) 결정
- structural hazard와 data hazard를 피함
- 컴파일러 스케줄링의 필요성을 줄임
- 하지만 여전히 컴파일러 스케줄링이 도움이 될 수 있음
- 코드 의미론(Code semantics)은 CPU에 의해 보장됨
Speculation
-
branch(분기) 예측과 continue issuing(명령어 실행 지속)
- 분기 결과가 결정되기 전까지 commit하지 않음
-
Load Speculation(로드 추측)
- load 및 cache miss delay를 방지
- 유효 주소(effective address)를 예측
- 로드된 값(loaded value)를 예측
- 미해결된 저장(outstanding stores)을 완료하기 전에 로드 실행
- 저장된 값(stored values)을 load unit으로 우회 전달(bypass)
- 유효 주소(effective address)를 예측
- 추측(speculation)이 해결될 때까지 load를 커밋하지 않음
- load 및 cache miss delay를 방지
Why Do Dynamic Scheduling?
- 왜 컴파일러가 코드 스케줄링을 하도록 하지 않는가?
- 모든 stall이 예측가능한 것 x
- ex. cache misses
- 항상 분기(branch)를 중심으로 스케줄링할 수는 없음
- 분기 결과는 동적으로 결정됨
- ISA(명령어 집합 아키텍처)의 다양한 구현은 서로 다른 대기시간(latencies)와 hazards를 가짐
결론: 동적 스케줄링은 실행 시점에서 상황에 맞게 최적화하여 이러한 문제를 해결할 수 있음.
