Chapter 4: The Processor
Pitfalls(함정)
- Poor ISA design은 파이프라이닝을 더 어렵게 만들 수 있음
- ex. 복잡한 명령어 집합(VAX, IA-32)
- 파이프라인을 작동시키기 위해 상당한 overhead가 필요함
- IA-32 마이크로-옵 접근 방식(IA-32 micro-op approach)
- 파이프라인을 작동시키기 위해 상당한 overhead가 필요함
- ex. 복잡한 주소 지정 방식(complex addressing modes)
- 레지스터 업데이트의 부작용(side effects), 메모리 간접 참조(indirection)
- ex. 지연된 분기(delayed branches)
- 고급 파이프라인에서는 긴 지연 슬롯(delay slots)이 존재함 (명령어 실행 후, 결과가 도달하기까지 기다려야 하는 지연 슬롯)
- ex. 복잡한 명령어 집합(VAX, IA-32)
Chapter 5: Large and Fast- Exploiting Memory Hierarchy (크고 빠른 - 메모리 계층 구조 활용)
Principle Locality
🚨 뭐가 locality고, temporal과 spatial이 있다는 것 암기
- 프로그램은 항상 주소 공간의 일부(small proportion)만 접근함
- Temporal locality(시간 지역성)
- 최근에 접근한 항목은 곧 다시 접근될 가능성이 높음
- ex. instructions in a loop(루프 내 명령어), induction variables(유도 변수들)
- Spatial locality(공간 지역성)
- 최근에 접근한 항목 근처의 항목들도 곧 접근될 가능성이 높음
- ex. sequential instruction access(순차적인 명령어 접근), array data(배열 데이터)
Memory Hierarchy Levels
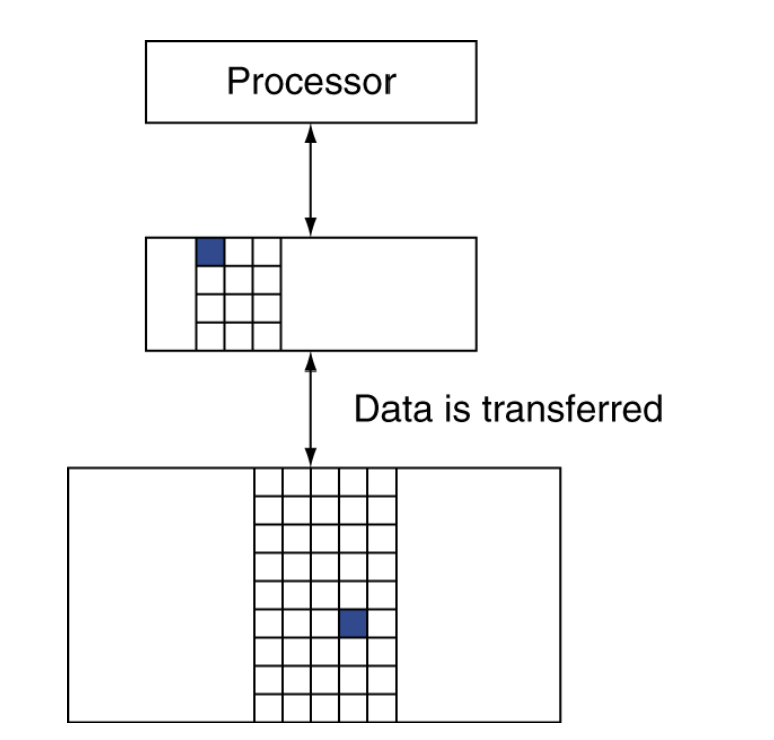
- Block (aka line): unit of copying (복사되는 단위)
- 여러 워드(multiple words)일 수 있음
- 만약 접근한 데이터가 상위(upper level)에 존재하면
- Hit: 상위 레벨에서 접근이 만족됨(satisfied)
- Hit ratio: hits/accesses
- Hit: 상위 레벨에서 접근이 만족됨(satisfied)
- 만약 접근한 데이터가 없으면(absent)
- Miss: 하위 레벨(low level)에서 block이 복사됨
- Time taken(소요시간): miss penalty
- Miss ratio: misses/accesses = 1 - hit ratio - 이후 상위 레벨에서 접근한 데이터를 공급함
Cache Memory
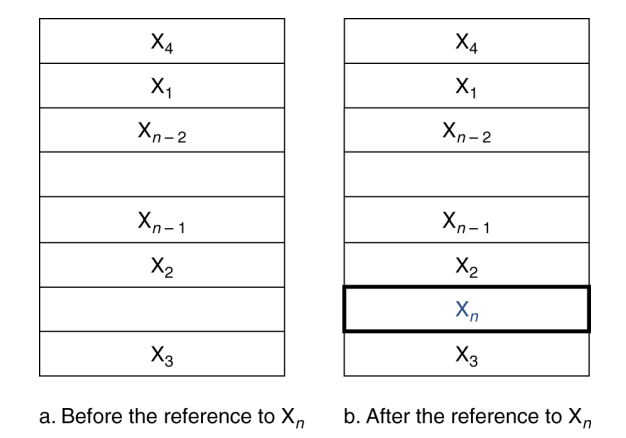
- CPU에 가장 가까운 메모리 계층 (The level of the memory hierarchy closest to the CPU)
- 주어진 접근 X1, …, Xn-1, Xn
- Q. 데이터가 존재하는지 어떻게 알 수 있을까?
- Q. 어디에서 찾아야 할까?
Direct Mapped Cache

- address(주소)에 의해 위치가 결정됨
- 직접 매핑(Direct mapped): 하나의 선택만 가능
- (Block address) modulo (#Blocks in cache 캐시 내 블록 수)
- 블록 수는 2의 거듭제곱(power of 2)
- 낮은 순서의 주소 비트 사용(Use low-order address bits)
Cache Example
🚨 숙제에서 hit, tag, miss하던 거 기억!
8개의 블록, 블록당 1개의 워드, 직접 매핑(direct mapped) 초기의 상태
 🖼️첫 번째 이미지
- 단어 주소 22는 이진수로 10 110
- 이진 주소는 hit or miss를 나타냄 <- hit일때, 캐시 내에 이미 데이터가 존재함을 의미
- 캐시에서 접근된 블록은 110
🖼️첫 번째 이미지
- 단어 주소 22는 이진수로 10 110
- 이진 주소는 hit or miss를 나타냄 <- hit일때, 캐시 내에 이미 데이터가 존재함을 의미
- 캐시에서 접근된 블록은 110
🌳<캐시 구조>
index: 주소의 하위 3비트가 index로 사용됨
V(유효 비트 = valid bit): 캐시 항목이 유효한지 나타냄 -> Y/N
Tag: 주소의 나머지 높은 비트는 태그로 사용됨
Data: 해당 index에 저장된 data
+) hit과 miss는 각각 캐시 접근의 성공과 캐시 접근의 실패
Hit: 캐시에서 데이터를 바로 찾을 수 있음 → 빠르고 효율적.
Miss: 캐시에 데이터가 없음 → 메모리에서 데이터를 가져오므로 시간이 더 걸림
Cache Misses
🚨캐시 미스때 일어난 일 알기
- cache가 hit하면, CPU는 정상적으로 진행됨(proceed)
- cache miss이면,
- CPU 파이프라인을 stall시킴
- 계층(hierarchy)의 다음 레벨에서 block을 fetch(가져옴)
- 명령어 캐시 미스(instruction cache miss)
- 명령어 패치 재시작
- 데이터 캐시 미스(data cache miss)
- 데이터 접근 완료
Write-Through과 Write-Back
🚨두 개 구분해서 알아두기
- Write-Through
- data-write hit시, 캐시의 block 업데이트하면 됨
- 하지만 그러면 캐시와 메모리가 일치하지않음(inconsistent)
- data-write hit시, 캐시의 block 업데이트하면 됨
- 메모리도 함께 업데이트 but 쓰기 작업이 더 오래걸림
- ex. 만약 기본 CPI(base CPI) = 1이고 10%의 명령어가 저장 명령이라면, 메모리 쓰는데 100 cycle이 걸림
- Effective CPI = 1 + 0.1 × 100 = 11
- ex. 만약 기본 CPI(base CPI) = 1이고 10%의 명령어가 저장 명령이라면, 메모리 쓰는데 100 cycle이 걸림
- 해결책: write buffer(쓰기 버퍼)
- 메모리에 쓰기 전에 데이터를 대기시킴(hold)
- CPU는 즉시 계속 진행
- 쓰기 버퍼가 가득 차지 않은 한 쓰기에서만 stall(정지)됨
- Write-Back
- 대안(alternative): data-write hit시, 캐시의 block만 업데이트하면 됨
- 각 블록이 더러운지(dirty) 여부를 추적
- 더러운 블록(dirty block)이 교체될 때
- 이를 메모리에 다시 씀(Write it back to memory)
- 블록을 먼저 읽을 수 있도록 쓰기 버퍼를 사용할 수 있음
- 이를 메모리에 다시 씀(Write it back to memory)
- 대안(alternative): data-write hit시, 캐시의 block만 업데이트하면 됨
