Chapter 5: Large and Fast- Exploiting Memory Hierarchy (크고 빠른 - 메모리 계층 구조 활용)
Measuring Cache Performance
-
CPU time의 구성요소
- 프로그램 실행 사이클(program execution cycles)
- cache hit time을 포함
- 메모리 정지 사이클(memory stall cycles)
- 주로 cache misses에서 발생
- 프로그램 실행 사이클(program execution cycles)
-
단순화된 가정 하(simplifying assumptions)에서

Cache Performance Example
주어진 값:
- I-cache 미스율 = 2%
- D-cache 미스율 = 4%
- Miss penalty = 100 사이클
- Base CPI(ideal cache) = 2
- Load & Sotre 명령어 비율 = 36%
명령어당 miss cycle:
I-cache: 0.02 × 100 = 2
D-cache: 0.36 × 0.04 × 100 = 1.44
실제 CPI = 2 + 2 + 1.44 = 5.44
Ideal CPU: 5.44 / 2 = 2.72배 더 빠름
Average Access Time
🚨 숙제에 있는 문제이므로 계산해보기
- Hit time은 성능(performance)에도 중요함
- 평균 메모리 접근 시간(AMAT=Average memory access time)
- AMAT = Hit time + Miss rate * Miss penalty
- ex.
- CPU의 클럭 주기가 1ns, hit time이 1 cycle, miss penalty가 20 사이클, I-cache 미스율이 5%
- AMAT = 1 + 0.05 × 20 = 2ns
- 명령어당 2 사이클
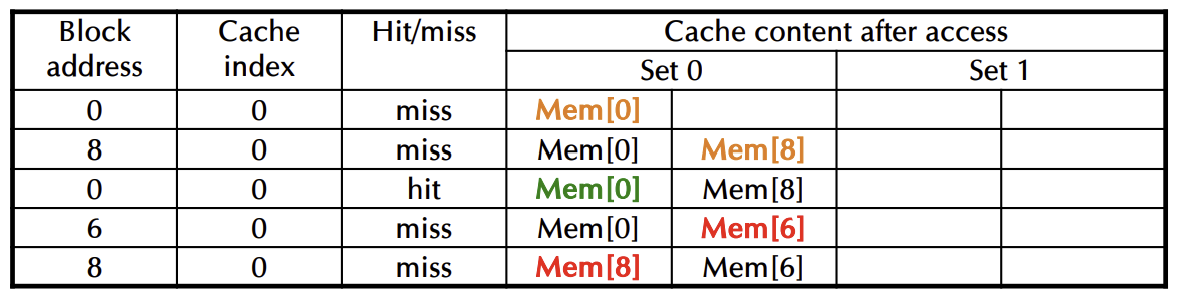
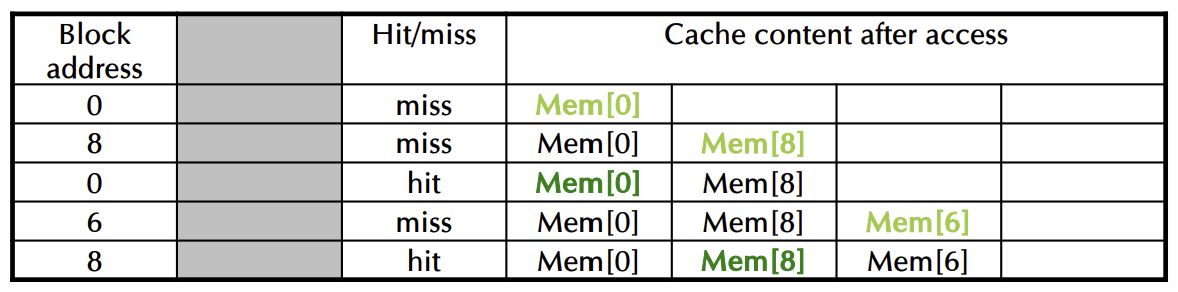
Associativity Example
🚨 direct mapped, 2-way set associative, Fully associative
- 4-block cache 비교
- Direct mapped, 2-way associative, fully associative
- 블록 접근 순서: 0, 8, 0, 6, 8
- Direct mapped

- 2-way associative
- Fully associative
Replacement Policy(교체 정책)
- Direct Mapped: 선택할 수 없음
- Set Associative(집합 연관)
- 비어있는(유효하지 않은) 항목이 있으면 그것을 선택
- 그렇지않으면, 집합(set)내의 항목들 중에서 선택
- Least Recently Used(LRU):
- 가장 오랫동안 사용되지 않은 항목들을 선택
- 2-way에서는 간단하고, 4-way에서도 관리할 수 있지만 그 이상에서는 너무 복잡함
- Random:
- 고연관성 캐시에서 LRU와 비슷한 성능
Multilevel Caches
🚨그림 혹은 글이 시험 출제
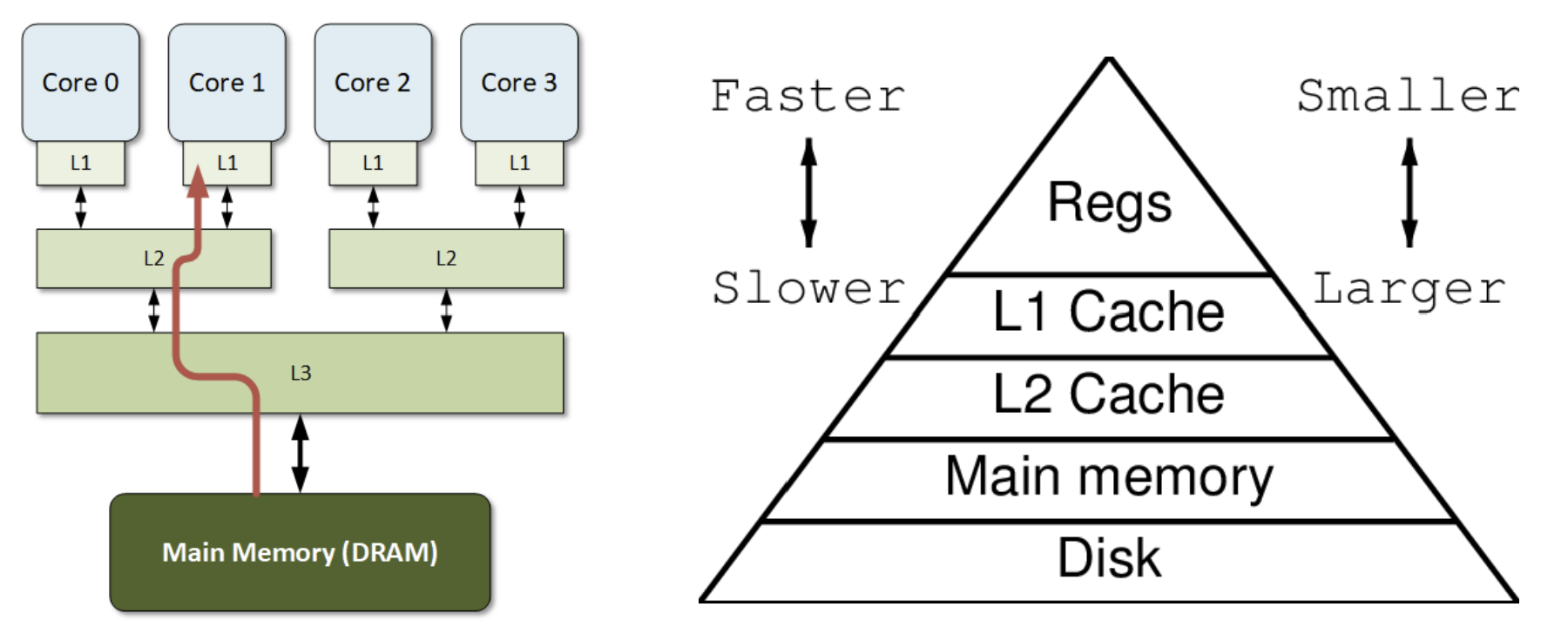
- CPU에 연결된 기본 캐시(Primary cache)
- small, but fast
- Level-2 cache는 primary cache에서 발생한 miss를 처리함
- 더 크고 느리지만 여전히 main memory(주기억장치)보다는 빠름
- 주기억장치(Main memory seervices)는 L-2 cache misses를 처리함
- 일부 고급 시스템(high-end system)에는 L-3 cache가 포함됨
➡️Multilevel Cache Example
주어진 값:
- CPU base CPI = 1, clock rate = 4GHz
- 명령어당 미스율(Miss rate/instruction) = 2%
- 주기억장치 접근 시간(Main memory access time) = 100ns
기본 캐시(primary cache)만 있을 때:
- Miss penalty = 100ns / 0.25ns = 400 사이클
- Effective CPI = 1 + 0.02 × 400 = 9
이제 L-2 캐시 추가:
- Access time = 5ns
- 주기억장치에 대한 전역 미스율(Global miss rate to main memory) = 0.5%
기본 캐시 미스(primary miss) 후 L-2 hit:
- penalty = 5ns / 0.25ns = 20 사이클
기본 캐시 미스(primary miss) 후 L-2 miss:
- Extra penalty = 500 사이클
CPI = 1 + 0.02 × 20 + 0.005 × 400 = 3.4
Performance ratio = 9/3.4 = 2.6
Dependability Measures
🚨말로 출제됨!!
- 신뢰성(Reliability): 평균 고장(failure) 시간 (MTTF)
- 서비스 중단(Service intteruption): 평균 수리(repair) 시간 (MTTR)
- 고장 사이의 평균 시간(Mean time between failures=MTBF):
- MTBF = MTTF + MTTR
- Availability(가용성)
- Availability = MTTF / (MTTF + MTTR)
- 가용성 향상(Improving Availabilty)
- MTTF 증가: 결함 회피(fault avoidance), 결함 허용(fault tolerance), 결함 예측(fault forecasting)
- MTTR 감소: 진단(diagnosis) 및 수리(repair)를 위한 도구와 프로세스 개선
Virtual Machines(가상 머신)
🚨이게 뭔지 정의
- Host computer가 guest operating system(게스트 운영 체제)와 machine resources(머신 리소스)를 emulate(에뮬레이션)
- 여러 guest간의 격리(isolation) 강화
- 보안(security)와 신뢰성(reliability) 문제 회피
- 리소스 공유 지원
- 가상화(Virtualization)는 성능에 일부 영향을 미침
- 현대의 고성능 컴퓨터로 실현 가능(feasible)
- Examples
- IBM VM/370(1970s technology)
- VMWare
- Microsoft Virtual PC
Virtual Machine Monitor = VMM(가상 머신 모니터)
🚨원리 알기
- 가상 리소스(virtual resources)를 물리적 리소스(physical resources)에 매핑
- Memory, I/O devices, CPUs
- Guest code는 사용자 모드에서 native machine위에서 실행
- 특권 명령어(privileged instructions) 또는 보호된 리소스(protected resources) 접근 시 VMM으로 제어가 전환됨(traps to VMM)
- 게스트 OS는 호스트 OS와 다를 수 있음
- VMM은 실제 I/O 장치를 관리함
- guest를 위해 일반적인 가상 I/O 장치를 에뮬레이션
+) 에뮬레이션(Emulation)이란 어떤 시스템이나 장치의 기능을 다른 시스템에서 흉내 내거나 재현하는 것
Virtual Memory(가상 메모리)
- 주 메모리(main memory)를 보조(디스크) 저장장치(secondary(disk) sotrage)의 cache로 이용
- CPU 하드웨어와 운영 체제(OS)가 공동으로 관리
- 프로그램은 주 메모리를 공유함
- 각 프로그램은 자주 사용하는 코드와 데이터를 담는 개인적인 가상 주소(private virtual address) 공간을 가짐
- 다른 프로그램으로부터 보호됨
- CPU와 OS는 가상 주소와 물리적 주소를 변환함
- VM(가상메모리)의 block == page
- VM의 translation miss == page fault
Page Fault Penalty
- page fault가 발생하면, 해당 page에서 disk를 fetch(가져와야함)
- 수백만 클럭 사이클(milions of clock cycles) 소요
- OS code에 의해 관리됨
- page fault rate를 최소화하기 위해 노력
- 완전 연결 배치(fully associative placement)
- 스마트 대체 알고리즘(smart replacement algorithms)
Page Tables
- 배치 정보(placement information) 저장
- page table entries의 배열, 가상 페이지 번호로 index
- CPU의 페이지 테이블 레지스터는 물리 메모리(physical memory)의 페이지 테이블을 가리킴
- 만약 page가 memory에 존재하면:
- PTE(Page Table Entries)는 물리 페이지 번호를 저장
- 추가 상태 비트(other status bits)를 포함함 -> ex. 참조여부(referenced, dirty ...)
- 만약 page가 존재하지 않으면:
- PTE는 disk의 swap 공간 위치를 참조 가능(refer)
Fast Translation Using a TLB(TLB(Translation Look-aside Buffer)를 이용한 빠른 번역)
🚨원리와 뒷장의 그림 같이 알기
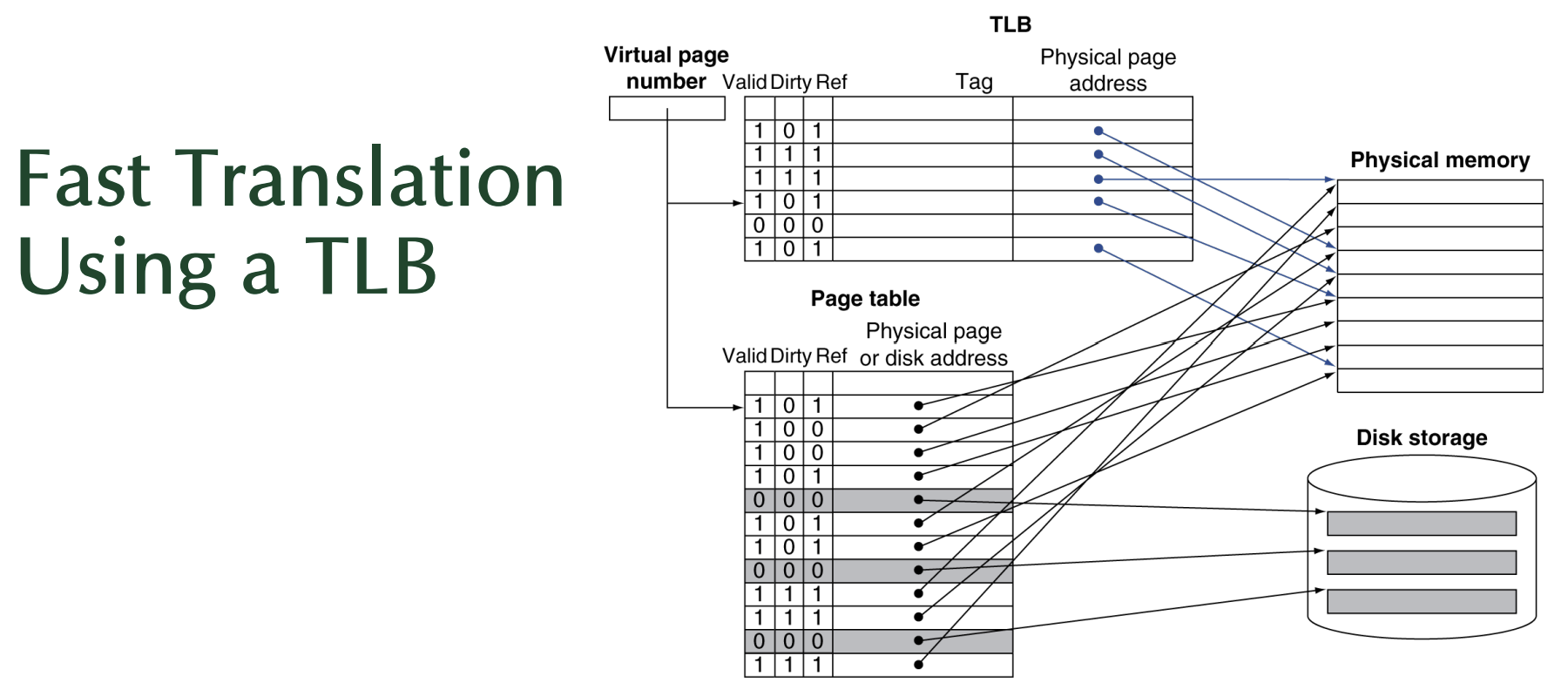
- TLB(Translation Look-aside Buffer)
TLB는 CPU 내부의 작은 캐시로, 자주 사용되는 페이지 테이블 항목(Page Table Entries, PTE)을 저장함- Page Table (페이지 테이블)
페이지 테이블은 메모리 상에 존재하며 가상 페이지 번호를 물리적 페이지 번호 또는 디스크 주소로 변환함- Disk Storage (디스크 저장소)
메인 메모리가 없는 페이지가 저장되는 곳으로, page table에 유효하지 않은 항목이 디스크의 위치를 가르킴/ OS가 디스크에서 페이지를 읽어오고 메모리에 적재한 후 페이지 테이블을 업데이트함
전체 과정 요약
가상 페이지 번호가 TLB에 들어가면, 태그와 비교하여 TLB 히트 여부를 확인
TLB 조회 → TLB 히트 시 빠른 변환 완료(물리적 페이지 주소가 즉시 제공됨)
TLB 미스 → 페이지 테이블로 넘어감
page table에서 유효한 page라면 -> 물리적 메모리에서 페이지를 가져옴
page table에서 유효x page라면 -> 디스크에서 페이지를 가져와 메모리에 적재➡️"페이지 폴트(Page Fault)" 발생
Page Fault 발생 -> Disk Storage에서 페이지를 가져와 메모리에 적재
=> 결과: TLB를 사용하면 page table 조회 횟수를 줄여 주소 변환 속도를 크게 높을 수 있음 & 캐시 히트율이 높을수록 성능 개선됨
-
주소 변환(address translation)은 추가 메모리 참조를 필요로 하는 것으로 보일 수 있음
- 하나는 PTE(Page Table Entry)에 접근하기 위해
- 그 다음은 실제 메모리 접근을 위해
-
그러나 page table에 대한 접근은 좋은 지역성(locality)를 가짐
- 따라서 CPU 내부의 PTE의 빠른 cache를 이용
- => 이것을 TLB(Translation Look-aside Buffer)라고 부름
- 일반적으로(typical): 16-512 PTEs, 0.5-1 cycle for hit(히트 시 사이클), 10-100 cycles for miss(미스 시 사이클), 0.01%-1% miss rate(미스율)
- 미스는 하드웨어 또는 소프트웨어에 의해 처리될 수 있음
Memory Protection
🚨어떻게 메모리 보호하는지 알기
-
여러 작업이 가상 주소 공간의 일부를 공유할 수 있음
- 하지만 잘못된 접근(errant access)으로부터 보호가 필요함
- 운영체제(OS)의 지원(assistance)이 필요함
-
Hardware support(하드웨어 지원)을 통한 OS(운영체제) 보호
- 권한이 있는 슈퍼바이저 모드(Privileged supervisor mode == kernel mode)
- 권한이 있는 명령어(Privileged instructions)
- page table 및 기타 상태 정보는 supervisor mode에서만 접근 가능함
- 시스템 호출 예외(system call exception) -> ex. ecall in RISC-V
The Memory Hierarchy(메모리 계층 구조)
<각 계층(hierarchy)에서의 작업>
- 블록 배치(block placement)
- 블록 찾기(finding a block)
- 미스 시 교체(replacement on a miss)
- 쓰기 정책(write policy)
Block Placement(블록 배치)
- 연관성(associativity)에 의해 결정됨
- 직접 매핑(Direct mapped == 1-way associative)
- 배치할 위치가 하나로 정해짐
- n-way set associative
- 집합(set)내에서 n개의 선택지가 있음
- Fully associative
- 어느 위치든 가능
- 직접 매핑(Direct mapped == 1-way associative)
- 높은 연관성(higher associativity)은 미스율(miss rate)을 감소시킴
- 복잡성, 비용, 접근 시간 증가
Replacement(교체)
- miss 발생 시 replace(교체)할 항목 선택
- Least recently used(LRU)
- 높은 연관성에 대해 복잡하고 비용이 많이 드는 하드웨어 필요
- Random
- LRU에 가까우며 구현이 더 쉬움
- Least recently used(LRU)
- 가상 메모리(virtual memory)
- 하드웨어 지원을 통한 LRU approximation(LRU 근사)
Write Policy(쓰기 정책)
- Write-through
- 상위 및 하위 수준 모두 업데이트
- 교체(replacement)를 단순화되지만 쓰기 버퍼가 필요할 수 있음
- Write-back
- 상위 수준만 업데이트
- block이 교체될 때 하위 수준을 업데이트
- 더 많은 상태 정보(state)를 유지해아함
- Virtual memory(가상 메모리)
- disk wrte latency(디스크 쓰기 지연)을 고려할 때, 오직 write-back만 가능
Sources of Misses(미스의 원인)
- Compulsory misses (aka clod start misses)
- 강제적인 미스 == 차가운 시작 미스
- block에 대한 첫 번째 접근
- Capacity misses
- 한정된(finite) 캐시 사이즈로 인한 miss
- 교체된 블록(replaced block)이 나중에 다시 접근됨
- Conflict misses (aka collision misses)
- 충돌 미스
- 비완전 캐시(non-fully associative cache)에서 발생
- 집합(set) 내 항목(entries)을 놓고 경쟁(competition)에 의해 발생
- 동일한 total size의 fully associative cache(완전 연관 캐시)에서는 발생하지 않음
