앞서 소개해 드린대로 2편에서는 관계형 DB와 테이블 간의 관계성에 대해 알아보겠다.

사람마다 관계가 중요하듯, DB도 역시 관계가 중요하다. 물론 DB의 종류에는 크게 2가지가 있다. 관계형과 비 관계형. 하지만, 사실상 실제 db로는 비관계형 보다는 관계형 데이터가 많이 사용된다고 한다. 그래서 이번에는 일단, 관계형만 먼저 알아보는데 주목했다.
1) 관계형 데이터란?
관계형 데이터 란 말 그대로, 데이터들 간의 유기적인 관계를 맺는 것을 말합니다. 그래서 어떻게 데이터들 간의 관계를 맺는 것이냐고 반문할 수 있다.
여기서 관계란 앞에서 본 표들 사이의 관계를 얘기한다.
대부분의 경우 데이터는 여러 개의 테이블에 걸쳐서 나누어져 있고, 그 테이블들은 서로 어떤 방식으로든 "관계" 되어있다.
예를 들어, 학생들이 시험을 얼마나 잘 보았는지 알려주는 테이블이 있고, 성적이 잘 안 나올 경우 부모에게 통보하기 위한 이메일 주소도 포함 되어있다.
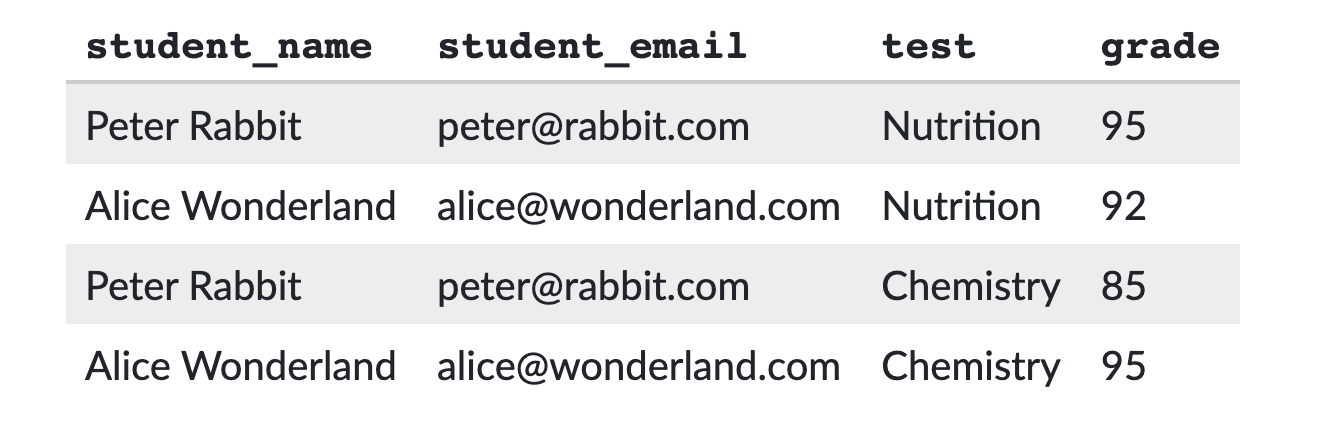
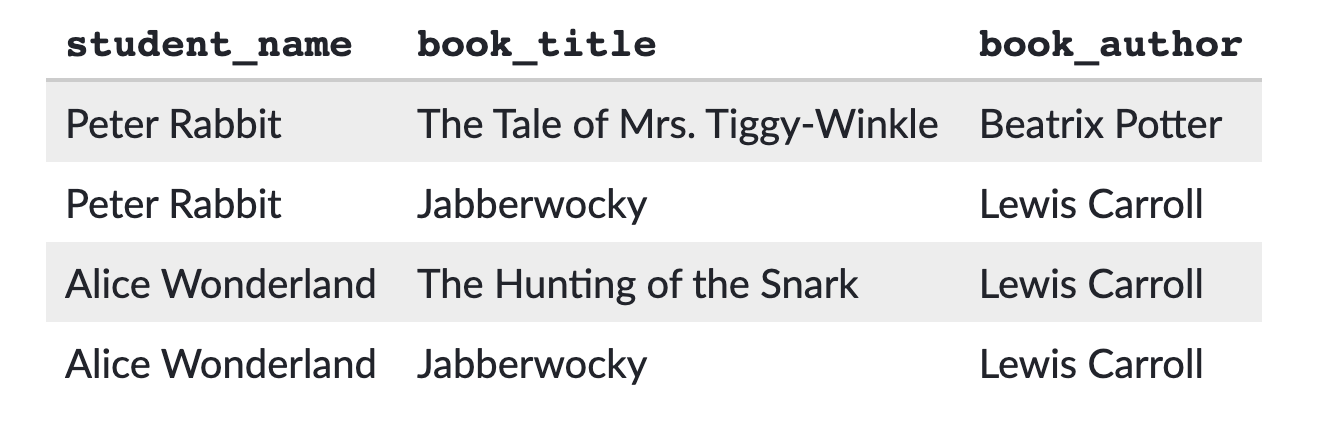
또한 각 학생이 어떤 책을 읽는지 저장하는 테이블도 있다. 이처럼 우리는 테이블을 칼럼과 로우를 통해 모든 데이터 값을 저장하고 관리할 수 있다.
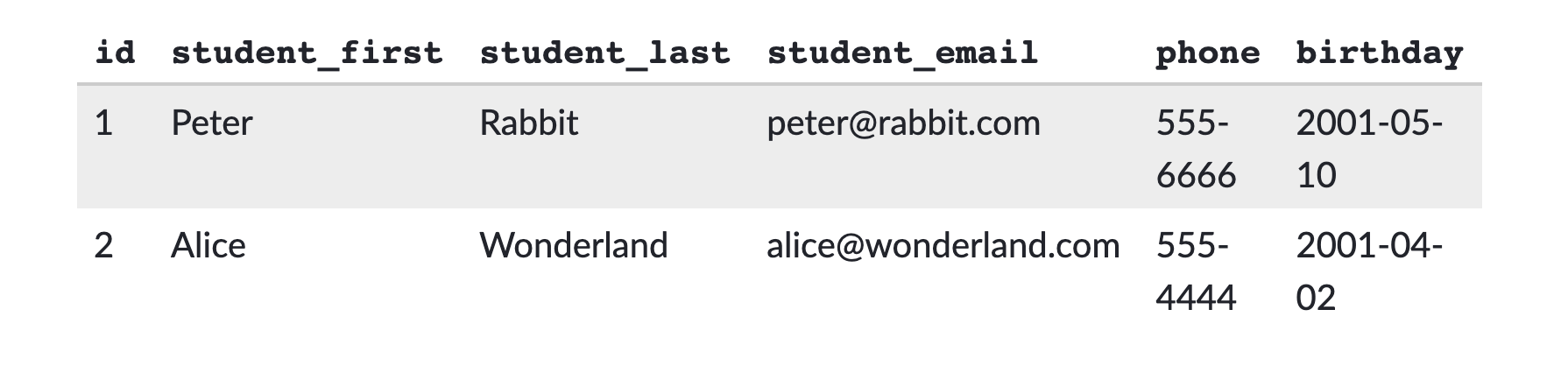
또한 학생들의 자세한 정보를 담고 있는 테이블도 있다.

여기서 의문점이 들지 않는가? 저기 표를 보면 말이다. 뭔가 중복되는 것이 보이지 않는가? 그렇다. 일단, 학생들의 이름이 중복된다. 그리고 또! 메일도 중복된다! 뭔가 합치고 싶은 생각이 들지 않는가?
그렇다면 당신은 벌써 관계에 대해 절반 이상 감이 온 것이 맞다~
02) 데이터 테이블의 구성
행(row)과 열(column)으로 구성되어 있는 2차원 테이블이다.
- Column (열) : 컬럼은 테이블의 각 항목 (
id,student_email,test,grade)을 의미합니다. - Row (행) : 로우는 각 항목들의 실제 값. 3번 행을 보면,
Nutrition,Nutrition,Chemistry,Chemistry이라는 실제 값이 있다.
📍 각 로우는 저만의 고유 키(Primary Key)다.
테이블의 가장 첫 컬럼은 언제나 id 다. 엑셀이나 스프레드 시트를 떠올려보면, 제일 첫 컬럼은 언제나 변하지 않는 번호(index)가 매겨져 있는 것이 떠올려지는가? 각 로우는 언제나 고유한 번호를 갖고 있다. 이를 고유 키(Primary Key)라고 한다.
따라서 우리 위의 테이블 가운데 alice@wonderland.com 라는 이메일은 id가 2인 데이터 라고 표현할 수 있다. 해당 메일의 primary key가 2번인 것.
이 Primary Key를 통해서 특정 로우를 찾거나, 인용(reference)할 수 있다. 이에 대해서는 뒤에 더 자세히 다루겠다.
따라서 정리를 하자면,
관계형 데이터베이스는 각각의 테이블들이 서로 상호관련성 을 가지고 서로 연결되어 있다. 각각의 테이블들이 완전히 독립적인 대상이 아니라, 테이블 A와 테이블 B가 서로 연관되어 있고, 서로 관련이 있다는 뜻이다.
03) 테이블 사이 관계의 종류
테이블 사이 관계의 종류는 크게 총 3가지로 분류가 된다. One to One, One to Many, Many to Many 한국어로는 일대일, 일대다, 다대다 관계라고 부른다. 아무리 복잡한 데이터 테이블이라고 해도 해당 관계성으로 다 연결되어 있다.
1. 일대일 관계
첫번째 관계 속성으로 일대일 관계를 알아보자. 관련성을 가지는 두 테이블에서, 하나의 테이블의 로우(데이터 객체 하나)가 다른 테이블의 로우 하나와 매칭이 되는 관계를 One-to-One 또는 1:1 관계를 가진다고 말한다. 예를 들어, 전 세계 국가들의 수도를 데이터베이스로 표현한다고 생각해보자. 모든 나라들은 하나의 수도를 가지기 때문에 1:1 관계를 이룬다고 할 수 있다.
데이터 테이블에서 데이터의 고유한 식별자가 되는 요소를 PK(primary key)라고 부르며, 다른 테이블의 pk를 참조하여 관계성을 나타낸 테이블의 데이터는 FK(foreign key, 외래키)라고 부른다. 나라들의 명칭을 담고있는 테이블에서 해당 나라의 수도를 표현하기 위해서 수도 테이블의 PK를 참조하여 FK로 데이터를 저장하고 있다면 두 테이블의 관련성을 나타낼 수 있게 된다.
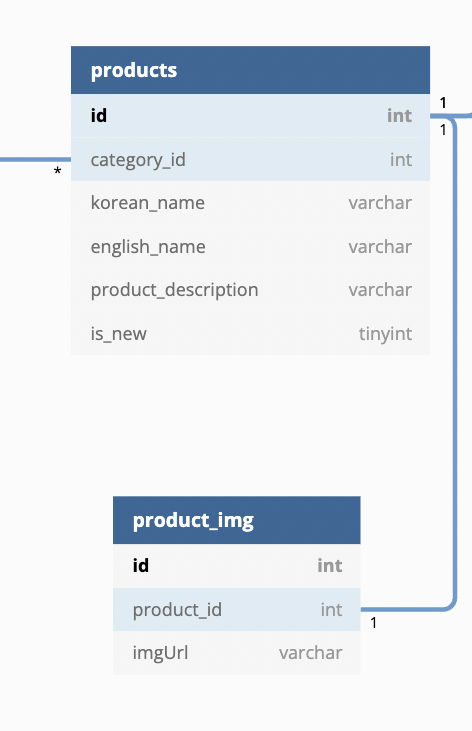
다음은 필자가 팀원들과 함께 데이터 모델링을 한 표다. 아래의 표에서 보면, 현재 프로덕트와 프로덕트 이미지를 1:1관계로 설정하고 있다. 이유는 프로덕트에 해당하는 이미지를 고유한 각각의 이미지로 보았고, 이에 따라 아이디 하나 당 고유한 프로덕트 아이디를 가진다고 봤기 때문이다.
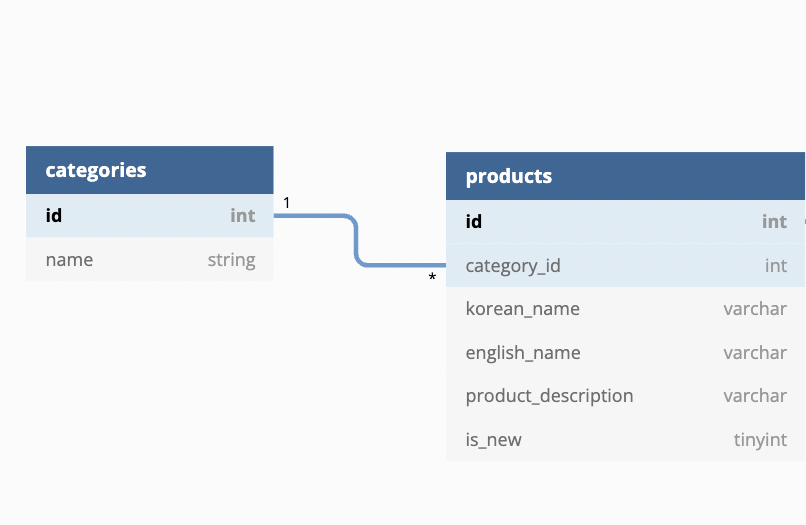
2. 일대 다 관계
일대일에 비해서 일대 다 관계는 약간 다르다. 아래의 표가 1:다 를 나타낸다. 즉, 하나의 카테고리에 다양한 상품들이 연결되어 있는 경우가 대표적이다. 지금과 같은 경우, 유제품이라고 치면, 우유, 저지방우유, 두유, 연유 등등의 것들이 하나의 카테고리로 묶일 수 있다. 따라서 이런 관계성이 있는 것들을 일대 다 관계라고 db 테이블에서도 역시 표현한다. 다만, 이전에 참조값에 대해 말을 하자면, 이처럼 1:다의 관계에서부터 참조값이라는 것을 넣어줘야 한다. 즉, 참조를 통해 지금 현재 내가 다른 테이블의 이 값을 참조하고 있다는 것을 관계성으로 표시해 줘야 한다. 아래 표에서는 category_id라고 표현함으로서 해당 관계를 나타내고 있다.
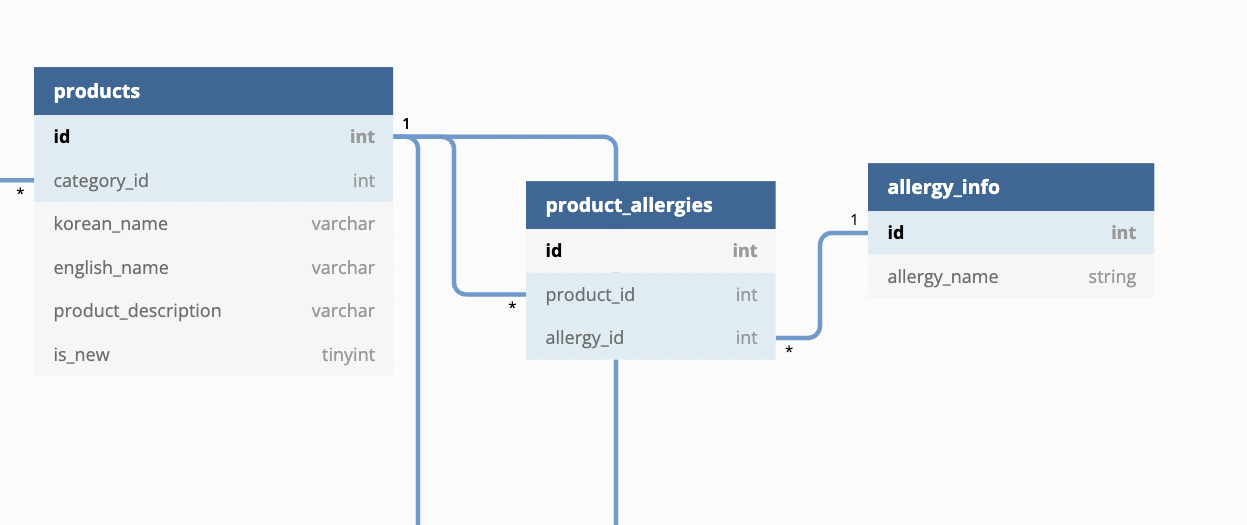
3. 다대다 관계
다음은 아마도 우리가 앞으로 db에서 가장 많이 접하게 될 관계라고 생각해도 좋다. 바로 다대다 관계. 이 관계는 결론적으로 크게 보면 다대다이지만, 뜯어보면, 사실 아래와 같다. 즉, 아래의 테이블에서 보면, product_allergies라는 테이블이 바로 1:다 의 관계에서 '다'에 해당하는 테이블이다. 프로덕트 알러지는 프로덕트 각각과 알러지 정보 각가에 대해서 관계를 맺고 있기 때문이다.
예를 들어, 우유 알러지가 있다고 치자. 하지만 이 알러지는 단순히 하나의 제품에만 있는 것은 아니다. 따라서 우유 알러지에 다양한 제품들이 연결되어 있다. 그래서 이것을 참조값으로 활용한 프로덕트 알러지 테이블이 프로덕트와 알러지 인포의 참조값들을 이용하게 되면서 1:다:1 의 관계를 맺게 된다. 따라서 크게 보면 다대다 관계이고 작게보면, 1:다 *2의 관계라고 볼 수 있다.
자~ 일단 여기까지 관계형 db에 대해 살펴봤다. 이후에는 한 번 이런 db를 사용하는 mysql에 대해 한 번 살펴볼 예정이다.
---------------------to be continued---------------------
