Impala & Hive & Sqoop
Impala 원리
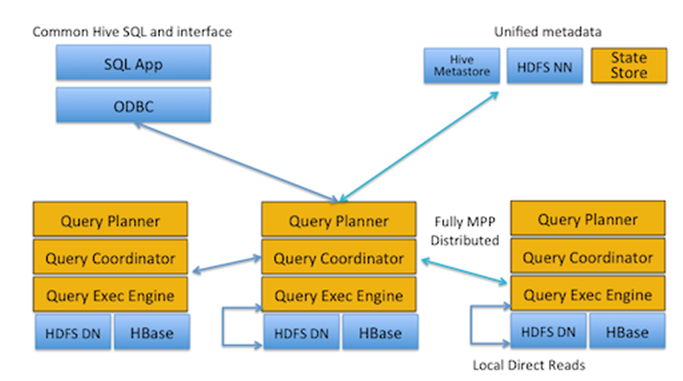
Impala는 크게 Impalad(daemon)과 statestore로 이루어져있다.
Impalad 구성
Query Planner : Query를 구문 분석하고, 메타스토어의 Table 및 Partition 정보를 활용하여 실행플랜을 생성합니다.
Query Coordinator : 다른 node에 요청 보내고, 요청 수집
Query Exec Engine : 질의와 메타데이터를 전달받은 모든 impalad는 각자 처리할 데이터 블록을 로컬 디렉터리에서 읽어와 질의 처리를 수행한다.
각각의 Impalad는 metadata 가지고 있다.
쿼리가 실행될 때, 특정 노드에있는 impalad는 coordinator node로 지정된다.
각 Impalad는 각자의 node에 있는 데이터에 대해 수행하기 때문에 data locality, direct read를 하게된다. n/w부하 최소라는 장점이 있다.
CatalogService : Hive에서 DB 변경 있을 시 Impalad의 metadata 반영위해 statestore에 브로드캐스팅 요청.
Catalog Service가 가지고 있는 Metadate 관리는 실제로 HMS에서 관리하는 데이터를 복사한것
각 impala node는 local에 메타데이터를 cache 해 놓는다.
StateStore :
1) meta의 변경사항을 모든 Impalad에 브로드캐스트
2) Impalad healthcheck, node 하나에서 장애 시 다른 노드들에게 전파해서 더 이상 쿼리가 진행되지 않게 한다.
Memory 부족
MEM_LIMIT 옵션 혹은 CFM 동적 resource pool 할당에서 계정당 memory 할당 제한둔다.
compute stats
테이블 데이터의, 관련된 모든 컬럼과 파티션의 볼륨 및 분포도 정보를 수집한다. 수집한 정보는 메타스토어 데이터베이스에 저장되고, 쿼리 최적화에 사용된다. 파티션된 테이블에 대해 특정 파티션의 정보만 수집하려면 COMPUTE INCREMENTAL STATS PARTITION_NAME 실행한다.
해당 부분처럼 진행하면 얼마나 compute stats때문에 최적화 되었는지 확인 가능하다.
explain 쿼리
compute stats 테이블
explain 쿼리
예제 참고)
https://datalibrary.tistory.com/108
Sqoop
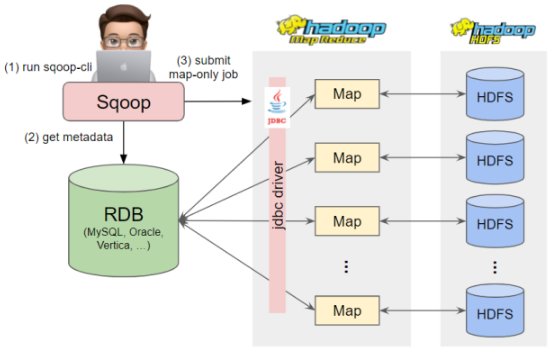
주요 성능 포인트는 병렬성인 num-mappers 옵션이다. deafult는 4개이고, 원리리는 카디널리티가(중복 적은) 기본키를 사용하면 좋다. 기본적으로는 pk기준으로 하게되는데 그게 없다면 split-by옵션으로 지정할 수 있다.
예를 들어 4개의 MAP 태스크로 import 하고, id의 min max가 0,1000이라고 하면
다음과 같은 4개의 쿼리가 나가게된다.
SELECT * FROM sometable WHERE id >= 0 AND id < 250
SELECT * FROM sometable WHERE id >= 250 AND id < 500
SELECT * FROM sometable WHERE id >= 500 AND id < 750
SELECT * FROM sometable WHERE id >= 750 AND id < 1001boundary-query란 min,max 값 기준으로 map task를 나누게 되는데 전체를 dump하면 속도가 느릴 수 있기 때문에 다음과 같이 작성한다.
sqoop import \
--driver "com.mysql.jdbc.Driver" \
--connect "jdbc:mysql://hereis.dbcluster.path:port/a_dbname" \
--table "a_table" \
--delete-target-dir \
--target-dir "hdfs://hereis/hdfs/etl/a_dbname/a_table" \
--as-parquetfile \
--username "XXXX" \
--password "XXXX" \
--split-by "user_id" \
--num-mappers "16" \
--split-by id \
--boundary-query "select min(id), max(id) from table"이슈1
Impala는 쿼리를 빠르게 수행하기 위해서 Hive 테이블의 메타데이터의 카피를 캐시로 가지고 있는 구조. 그렇기 때문에 hive에서 변경사항 있으면 sync를 맞춰주어야한다.
Refresh vs Invalidate
Refresh: 다시 로드하지만 hdfs block 상에서 증분된 만큼만의 데이터를 로드한다
Invalidate : 기존의 캐시를 모두 지우고 새로운 메타데이터 가져오기 때문에 리소스 소모 크다. 특히 파티션이 많은 큰 테이블일 때 비싼 작업. 테이블 생성/삭제할 때 필요
이슈2
빅데이터 플랫폼에서 데이터 저장 시 text파일은 사이즈가 너무 크고, 속도 면에서 느려서 압축률이 좋은 orc, parquet, avro 를 많이 쓴다(바이너리 포맷).
orc : column based, hive 최적화
parquet : column based
avro : row based, 스키마는 json.
column based : 높은 압축률, 선택되지 않은 칼럼에 대해서는 I/O 발생하지 않는다
이슈3
오라클 Big Data SQL(BDSQL)을 이용하면 hive, hdfs 파일 등을 오라클의 external table로 만들어 오라클에서 DW와 빅데이터플랫폼을 연동하여 쿼리를 작성가능하다.
Reference
(impala)
https://geonyeongkim-development.tistory.com/76
https://imp51.tistory.com/entry/Components-of-the-Impala-Server
https://github.com/HomoEfficio/dev-tips/blob/master/Impala%20%EA%B4%80%EB%A0%A8%20%EC%9E%A1%EB%8B%A4.md
https://d2.naver.com/helloworld/246342
https://datalibrary.tistory.com/213
https://brocess.tistory.com/213
