SQL vs NoSQL
SQL (관계형 데이터베이스)
SQL을 사용하면 RDBMS(Relational 관계형 DataBase 데이터베이스 Management 관리 System 시스템)에서 데이터를 저장, 수정, 삭제 및 검색 할 수 있다.
관계형 데이터베이스에는 핵심적인 두 가지 특징이 있다.
- 데이터는 정해진 데이터 스키마에 따라 테이블에 저장
- 데이터는 관계를 통해 여러 테이블에 분산된다.
데이터는 테이블에 레코드로 저장되는데, 각 테이블마다 '명확하게 정의된 구조'가 있다.
해당 구조는 필드의 이름과 데이터의 유형으로 정의된다
스키마(Sechema)를 준수하지 않는 레코드는 테이블에 추가할수 없다.
즉, 스키마를 수정하지 않는 이상은 정해진 구조에 맞는 레코드만 추가가 가능한것이 관계형 데이터베이스의 특징 중 하나
데이터의 중복을 피하기위해 '관계'를 이용한다
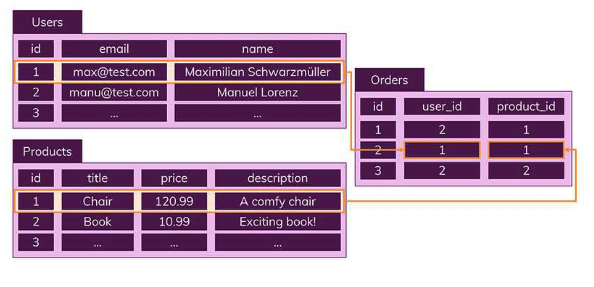
하나의 테이블에서 중복 없이 하나의 데이터만을 관리하기 때문에 다른 테이블에서 부정확한 데이터를 다룰 위험이 없어지는 장점이 있다.
대표적인 SQL은 MySQL, Oracle, SQLite, PostgresSQL, MariaDB 있다.
NoSQL (비관계형 데이터베이스)
관계형 데이터베이스의 반대 개념
스키마도 없으며, 관계도 없다.
NoSQL에선 레코드를 문서(Documents)라고 부른다.
여기서 SQL과 핵심적인 차이가 보이는데, SQL은 정해진 스키마를 따르지 않으면 데이터 추가가 불가능했다.
하지만 NoSQL에선 다른 구조의 데이터를 같은 컬렉션에 추가가 가능하다.
문서는 JSON과 비슷한 형태를 가지고 있다.
관계형 데이터베이스처럼 여러 테이블에 나누어담지 않고, 관련 데이터를 동일한 '컬렉션'에 넣는다.
따라서 위 사진에서 SQL에서 진행한 Orders, Users, Products 테이블로 나눈 것을 NoSQL에선 Orders에 한꺼번에 포함해 저장한다.
🙋🏻♂️ JOIN 하고싶을 땐 NoSQL은?
컬렉션을 통해 데이터를 복제하여 각 컬렉션 일부분에 속하는 데이터를 정확하게 산출하도록 한다.
하지만 이러면 데이터가 중복되어 서로 영향을 줄 위험이 있다.
따라서 조인을 잘 사용하지 않고, 자주 변경되지 않는 데이터 일땐 NoSQL을 쓰면 상당히 효율적이다.
알아두자
물론 늘 그렇듯 NoSQL에 스키마가 반드시 없는건 아니다.
NoSQL에서 데이터를 읽어올 때 스키마에 따라 데이터를 읽어 온다.
이런 방식을 'Schema on read'라고 한다.
읽어올 때만 데이터 스키마가 사용된다고 하여서, 데이터를 쓸 때 정해진 방식이 없다는 의미는 아니다.
데이터를 입력하는 방식에 따라, 데이터를 읽어올 때 영향을 미친다.
대표적인 NoSQL은 MongoDB, Casandra 등이 있다.
확장 개념
두 데이터베이스를 비교할 땐 중요한 Scaling 개념도 존재한다
데이터베이스 서버의 확장성은 '수직적' 확장과 '수평적' 확장으로 나뉜다.
- 수직적 확장: 단순히 DB서버의 성능을 향상시키는 것 (ex. CPU upgrade)
- 수평적 확장: 더 많은 서버가 추가되고 데이터베이스가 전체적으로 분산됨을 의미 (하나의 DB에선 작동하지만 여러 호스트에서 작동)
💡 데이터 저장 방식으로 인해 SQL DB는 일반적으로 수직적 확장만 지원
수평적 확장은 NoSQL DB에서만 가능
SQL 장•단점
👍
- 명확하게 정의된 스키마, 데이터 무결성 보장
- 관계는 각 데이터를 중복없이 한번만 저장
👎
- 덜 유연하다, 데이터 스키마를 사전에 계획하고 알려야 한다(추후 수정이 힘들다)
- 관계를 맺고 있어서 JOIN문이 많은 복잡한 query가 만들어질수 있다.
- 대체로 수직적 확장만 가능하다
NoSQL 장•단점
👍
- 스키마가 없어 유연하며, 언제든지 저장된 데이터를 조정하고 새로운 필드 추가가 가능하다
- 데이터는 애플리케이션이 필요로 하는 형식으로 저장되어, 데이터 읽어오는 속도가 빨라진다.
- 수직 및 수평 확장이 가능해 어플리케이션이 발생시키는 모든 읽기/쓰기 요청 처리가 가능하다
👎
- 유연성으로 인해 데이터 구조 결정을 미루게 될 수 있다.
- 데이터 중복을 계속 업데이트 해야한다
- 데이터가 여러 컬렉션에 중복되어 있기 때문에 수정 시 모든 컬렉션에서 수행해야한다. (SQL에선 중복 데이터가 없어 한번만 수행이 가능)
🙋🏻♂️ 언제 어떤걸 써야하나?
SQL
-> 관계를 맺고 있는 데이터가 자주 변경되는 어플리케이션의 경우
-> 변경될 여지가 없고, 명확한 스키마가 사용자와 데이터에게 중요한 경우
NoSQL
-> 정확한 데이터 구조를 알 수 없거나 변경/확장 될 수 있는 경우
-> 읽기를 자주 하지만, 데이터 변경은 자주 없을 경우
-> 데이터베이스를 수평으로 확장해야 하는 경우 (막대한 양의 데이터를 다뤄야하는 경우)
데이터베이스 간단한 용어정리
예시)
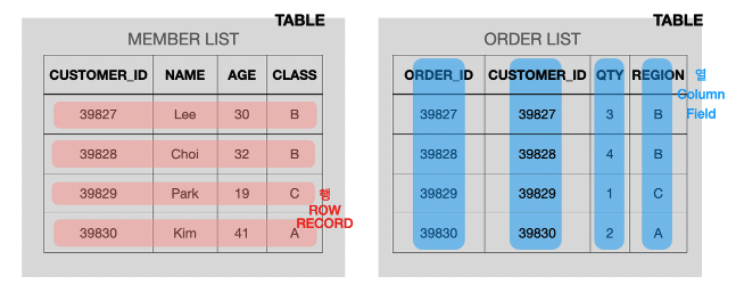
필드(Fields)
필드는 엑셀에선 열에 해당하는 가장 작은 단위의 데이터를 의미한다
이 필드는 엔티티의 속성을 표현한다.
위 MEMBER_LIST 에선 각 열은 고객 정보(ID, 이름, 나이, 클래스)를 나타낸다.
레코드(Records 혹은 튜플 Tuple)
레코드는 논리적으로 연관된 필드의 집합을 의미하며, 엑셀의 행(row)에 해당되며, 튜플이라고도 불리고있다.
여기서 각각의 필드는 특정한 데이터 타입과 크기가 지정되어 있고, 여러 행이 모여 한 열을 이루듯이 여러 필드가 모여 하나의 레코드를 이룬다.
위 멤버 테이블에서 고객들의 정보들이 모여있다.
고객의 ID, 이름, 나이, 클래스 데이터가 모여 하나의 레코드를 구성하며, 한 고객 레코드는 4개의 필드 (CUSTOMER_ID, NAME, AGE, CLASS)로 이루어져 있다고 할 수 있다.
테이블(Table 혹은 파일Files)
서로 연관된 레코드의 집합을 테이블 또는 파일이라고 한다.
엔티티(Entity)
엔티티는 현실 세계에 존재하는 것을 데이터베이스 상에서 표현하기 위해 사용하는 추상적인 개념, 일종의 비유라 할 수 있다.
고객을 관리하기 위해 사용하는 위의 데이터베이스 예제에선 ID, 나이, 클래스 라는 정보들을 통해 '고객'이라는 엔티티(객체)를 표현할 수 있고, 동시에 구분할 수 있다.
1행의 고객과 2행의 고객을 구분하기 위해선 해당 고객의 이름이나 ID를 비교할 수 있고, 현실 세계에선 사람들(엔티티)를 구분하기 위해 이름, 주민등록번호, 출신지, 성별 등의 특성을 이용한 것과 마찬가지이다.
- ##속성(Attribute)
엔티티를 설명하는 특성을 Attribute라 한다.
이런 특성들은 각각의 엔티티마다 다를 수 있고, 이를 통해 엔티티를 구별할 수 있다.
필드와 특성의 차이는 뭘까?
데이터베이스에서 필드와 특성은 본질적으로 같은 것으 이야기한다.(엔티티의 특수한 성질을 의미)
고객 엔티티에서 customer_Id, name, age, class는 고객이라는 엔티티의 고유한 특성들이다.
이 특성들은 다른 테이블/엔티티와의 관계에 대해 이야기할 때, 필드라 불려질수 있다.
스키마(Sechema)
스키마는 전체적인 데이터베이스의 골격 구조를 나타내는 일종의 도면이다.
스키마는 데이터베이스의 엔티티와 그 엔티티들 간의 관계를 정의하는데, 어떤 타입의 데이터가 어느 위치에 적재되어야 하는지, 다른 테이블이나 엔티티와 어떤 관계를 맺는지 정의한다.
레퍼런스
'What is the difference between a field and an attribute in context of storing data?' - Quora
https://doorbw.tistory.com/227
https://93jpark.tistory.com/23
https://gyoogle.dev/blog/computer-science/data-base/SQL%20&%20NOSQL.html
