https://arxiv.org/pdf/1911.09070
CVPR 2020
Intro
Object detection 에서 다양한 크기의 객체를 잘 탐지하기 위해서는 multi-scale feature를 잘 활용하는 것이 중요함. (수용영역 관점)
기존 object detection 모델들은 정확도를 높이기 위해 보통 다음 중 하나를 했다.
- Backbone을 키움
- 입력해상도를 키움
- FPN/Neck을 복잡하게 구성함
- Head를 깊게 구성
but 이렇게 하면 정확도는 오르지만 params, FLOPs, Latency가 급격히 증가하는 Trade Off.
- 어떻게 하면 다양한 크기의 객체를 잘 탐지하면서도 Feature Fusion을 효율적으로 할 수 있을까?
- 어떻게 하면 detector 전체를 균형있게 키우거나 줄일 수 있을까?
논문에서는 이를 위해 BiFPN과 compound scaling을 제안함.
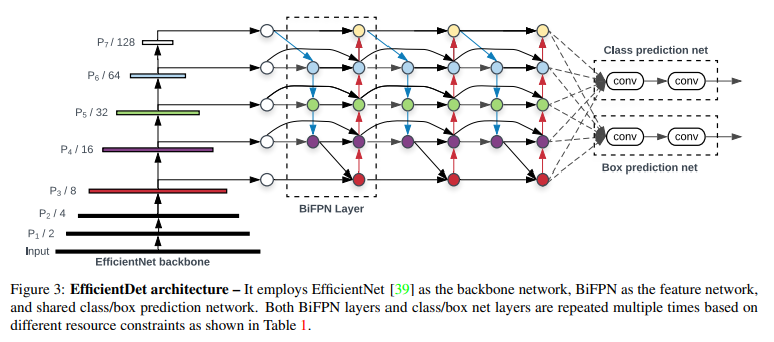
EfficientDet Architecture
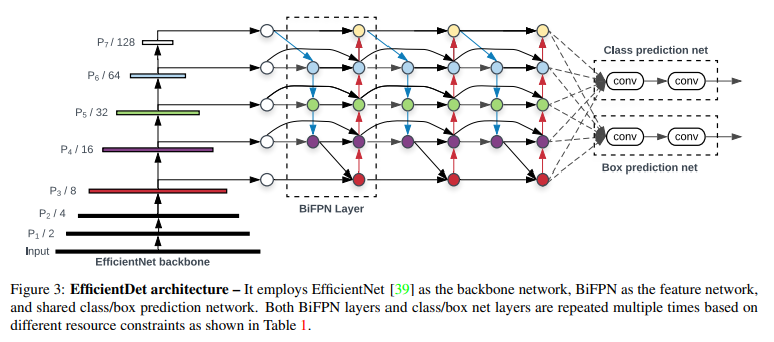
Input Image
↓
EfficientNet Backbone
↓
P3, P4, P5, P6, P7 multi-scale features
↓
BiFPN 반복
↓
Class prediction network
Box prediction network
EfficientDet은 YOLO와 마찬가지로 one-stage detector 기반.
(RPN 같은 proposal 단계 없이, feature map에서 바로 class와 box를 예측함.
BiFPN (Bidirectional Feature Pyramid Network)
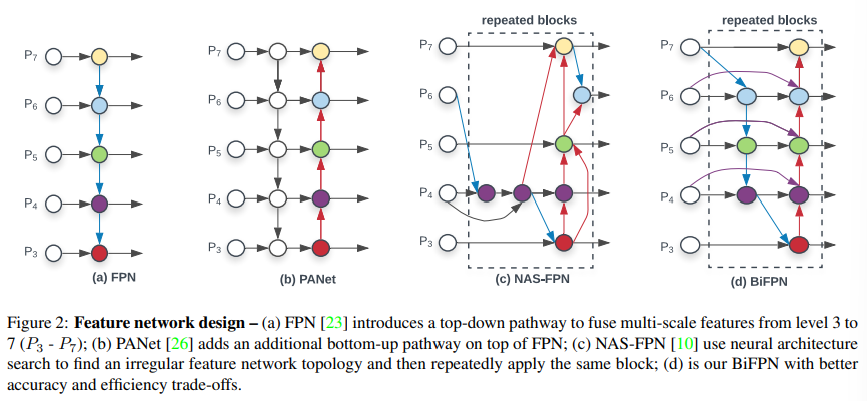
기존 FPN은 top-down 방향으로만 정보를 전달함.
P7 → P6 → P5 → P4 → P3
상위 feature는 semantic 정보가 강하고, 하위 feature는 spatial detail이 강함.
FPN은 상위 feature를 아래로 내려보내며 multi-scale 정보를 합친다. 그런데 이 방식은 정보 흐름이 한 방향이라는 한계가 있음.
PANet은 여기에 bottom-up path를 추가하여 정보가 양방향으로 흐른다. 하지만 PANet은 계산량이 커짐.
EfficientDet은 이 문제를 보고 BiFPN을 제안함.
- 입력이 하나뿐인 노드는 제거한다.
feature fusion이 목적이라면, 입력이 하나뿐인 노드는 fusion을 하지 않는다. 그러면 큰 기여 없이 연산만 늘릴 수 있다. - 같은 level의 input과 output을 직접 연결하는 shortcut edge를 추가한다.
예를 들어 P4 input이 최종 P4 output에도 직접 연결되도록 한다. 이렇게 하면 원래 scale의 정보를 더 잘 보존하면서도 비용은 크게 늘지 않는다. - top-down + bottom-up path를 하나의 BiFPN layer로 보고 반복한다.
한 번만 fusion하지 않고 여러 번 반복해서 multi-scale feature를 더 깊게 섞는다.
*Weighted Feature Fusion
문제는 서로 다른 scale의 feature를 그냥 단순히 concat/add 할 순 없다.
예를 들어 작은 객체 탐지에는 P3/P4가 더 중요할 수 있고, 큰 객체 탐지에는 P5/P6/P7이 더 중요할 수 있기 때문.
Output = w1 × Feature A + w2 × Feature B단순히 더하지 않고, 네트워크가 각 feature의 중요도를 학습하게 만든다.
EfficientDet은 fast normalized fusion을 사용한다.
wi는 ReLU를 거쳐 0 이상이 되고, ε는 numerical instability를 막기 위한 작은 값이다.
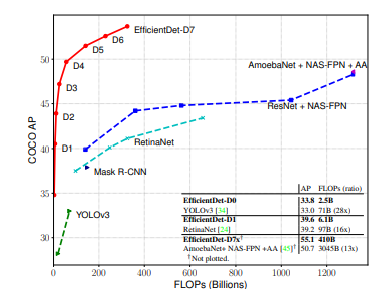
논문은 이 방식이 softmax fusion과 유사한 정확도를 내면서 GPU에서 최대 약 30% 빠르다고 함.
*Depthwise Separable Convolution
EfficientDet은 BiFPN 내부 feature fusion 이후의 convolution에 depthwise separable convolution을 사용함.
논문은 feature fusion에 depthwise separable convolution을 사용하고, 각 convolution 뒤에 batch normalization과 activation을 추가했다고 함.
일반 conv 계산량 : H × W × Cin × Cout × K × K
DWconv 계산량 :
Depthwise Conv: H × W × Cin × K × K
Pointwise Conv: H × W × Cin × Cout
*즉, 3×3 spatial filtering은 채널별로 따로 하고, 채널 혼합은 1×1 conv가 담당
하지만 중요한건, EfficientDet이 모든 conv를 무작정 depthwise로 바꾼 게 아님. 주로 BiFPN과 prediction network에서 사용한다.
Compound Scaling
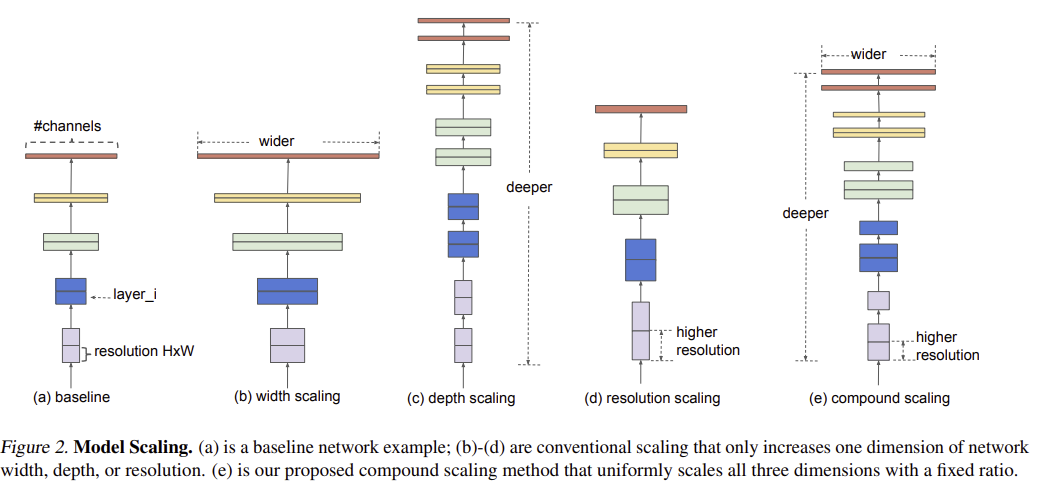
기존 detector scaling은 보통 하나만 키웠다.
- backbone만 키움
- input resolution만 키움
- feature channel만 키움
- head depth만 키움
EfficientDet은 이것이 비효율적이라고 본다. detector는 backbone, neck, head, input resolution이 함께 작동하기 때문에 하나만 키우면 병목이 생긴다.
그래서 EfficientDet은 compound coefficient φ를 두고 다음 요소를 함께 scale한다.
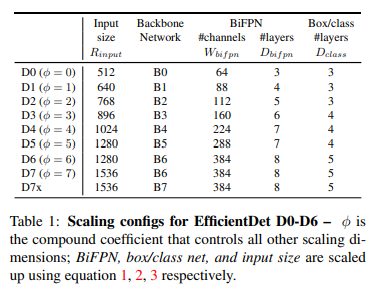
| element | scaling |
|---|---|
| Backbone | EfficientNet-B0 ~ B6 사용 |
| BiFPN width | 64 × 1.35^φ |
| BiFPN depth | 3 + φ |
| Box/Class head depth | 3 + floor(φ/3) |
| Input resolution | 512 + 128φ |
⇒ 정확도를 높이고 싶을 때 무작정 backbone만 키우지 말고, neck과 head와 resolution도 함께 균형 있게 조절해야 한다.
p.s.
- Neck~Head 개선방향 (BiFPN 관점)
- Weighted Fusion (단일 위성이 탐지 범위 내에 있고, class X, bbox ROI localization에 유리한 scale feature를 잘 고르눈 게 중요)
- DWconv는 성능 향상이라기보단 연산 절감
- EfficientDet은 TPU/GPU, 나는 FPGA/Polarfire C-portable 구조이므로, BiFPN의 반복연산이 실제 FPGA 메모리 버퍼에서 부담이 될 수 있음.
- EfficientDet은 anchor 기반 RetinaNet류 구조인 반면, 나는 anchor free+DFL Head
