https://arxiv.org/pdf/2404.10518
ECCV 2024
엣지용 네트워크를 설계할 때, 단순히 FLOPs만 줄인다고 실제 하드웨어에서 빨라지는 것은 아니다...
어떤 모델은 CPU에서는 빠른데 EdgeTPU에서는 느리고, 어떤 모델은 Apple Neural Engine에서는 좋은데 GPU에서는 비효율적이다. 진짜 좋은 모바일 모델이라면 여러 하드웨어에서 골고루 효율적이어야 한다.
- UIB, Universal Inverted Bottleneck
- Mobile MQA : 모바일 가속기 친화적인 Attention block
- 하드웨어 보편성을 고려한 NAS + Distillation
I. Roofline Model
1. Operational Intensity
- OI가 높다
→ 메모리에서 데이터를 한 번 가져와 많은 연산을 수행
→ compute-heavy - OI가 낮다
→ 데이터를 자주 가져오는데 연산량은 적음
→ memory-heavy
2. Ridge Point
하드웨어마다 “어디부터 메모리 병목이고, 어디부터 연산 병목인가”가 다름.
- CPU: 연산 처리량이 상대적으로 낮음
→ 연산 병목이 쉽게 발생
→ MACs 감소→ latency 감소 - 가속기: 연산 처리량이 매우 큼
→ 오히려 메모리 이동이 병목
→ MACs가 조금 많더라도 메모리 접근이 효율적이면 더 빠를 수 있음
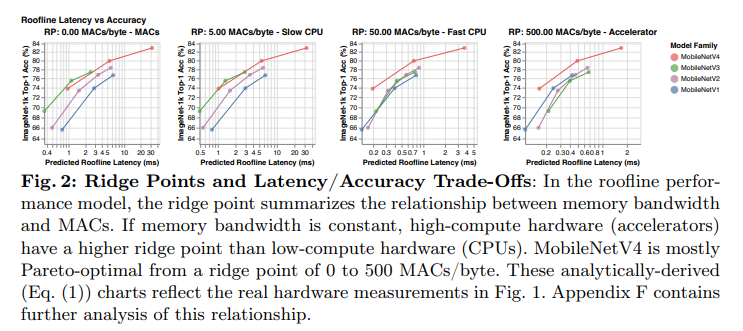
0~500 MACs/byte 범위의 다양한 RP를 훑으며 모델이 여러 하드웨어에서 어떻게 동작하는지에 대한 figure.
DW Conv가 항상 좋은 건 아님
- 큰 Conv2D
- MACs는 많음
- but 메모리 재사용이 잘 돼서 가속기에서 효율이 좋을 수 있음
- Depthwise Conv
- MACs는 적음
- 하지만 채널별 독립 처리라 데이터 재사용이 제한되고, 메모리 접근 대비 연산량이 작음
- 따라서 고성능 가속기에서는 memory-bound가 되어 생각보다 느릴 수 있음….
II. UIB (Universal Inverted Bottleneck)
기존 MobileNetV2의 Inverted Bottleneck을 기반으로, 두 개의 Depthwise Conv를 선택적으로 넣거나 뺄 수 있게 만든 블록
MobileNetV2 :
MobileNetV4 : 선택적인 DW Conv로 조합에 따라 4가지 블록이 됨
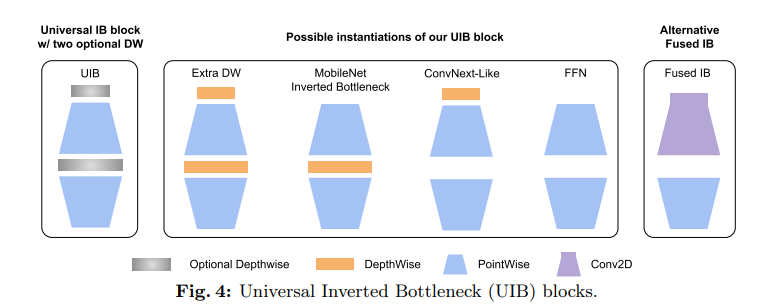
1. FFN-like block
- 공간 mixing 없음
- 채널 mixing만 수행
- 계산 구조가 단순
- 가속기 친화적
2. MobileNet Inverted Bottleneck
= 기존 MobileNetV2의 IB 구조
- 확장된 채널 공간에서 spatial mixing 수행
- 표현력은 좋지만 비용이 커질 수 있음
3. ConvNeXt-like block
- spatial mixing을 채널 확장 이전에 수행
- 그러면 DW Conv가 다루는 채널 수가 적어짐
- 따라서 큰 kernel을 써도 비용을 낮출 수 있음
= 수용영역을 넓히면서 비용 증가를 억제*
4. ExtraDW block (new)
- Expansion 전 DW: 저렴한 공간 mixing
- Expansion 후 DW: 더 표현력 있는 공간 mixing
- 결과적으로
- 네트워크 깊이 증가
- receptive field 확대
- spatial 표현력 강화
- 일반 Conv보다 저렴
MobileNetV4 : 어느 위치에 DW를 넣어야 receptive field 연산 효율의 trade-off가 가장 좋냐
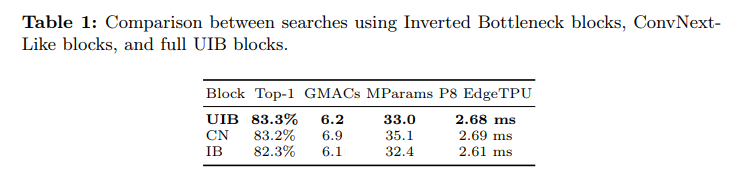
음……….
III. Mobile MQA
: attention을 모바일 가속기에 맞게 고친 것
모바일 환경의 후반부 stage에서는
- token 수는 작고
- channel dimension은 큼
- batch size는 1
인 경우가 많다
이때 Multi-Head Self-Attention는 K, V를 head별로 따로 들고 다녀야 해서 메모리 접근 비용이 커짐.
Multi-Query Attention(MQA)는 :
- Query는 여러 head로 유지
- Key와 Value는 모든 head가 공유
- 메모리 접근량 감소
- 파라미터 감소
- MACs 감소
- 실제 accelerator latency 감소
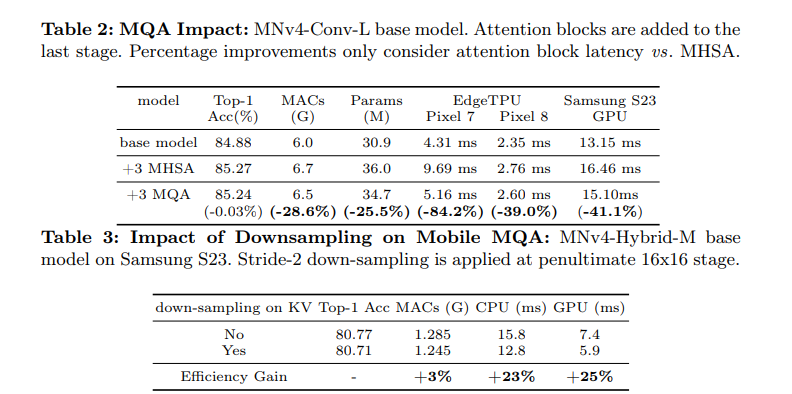
정확도는 거의 동일한데,
attention block 기준으로
- Pixel 7 EdgeTPU: 84.2% latency 감소
- Pixel 8 EdgeTPU: 39.0% 감소
- S23 GPU: 41.1% 감소
attentipon 쓰려면 MHSA보다 MQA!!!!!***
긜고..
K,V만 다운샘플링하는 비대칭 Spatial Reduction
일반 attention에서 Q, K, V의 spatial resolution이 같으면 비용이 커짐.
MobileNetV4는:
- Q는 고해상도 유지
- K, V만 stride-2 depthwise convolution으로 다운샘플링
정확도 손실은 -0.06%p에 불과한데,
- CPU latency 23% 개선
- GPU latency 25% 개선
Group convolution, 복잡한 multi-path branch 구조가 FLOPs는 낮아도 메모리 접근과 커널 실행 오버헤드 때문 실제론 느릴 수 있다.
일부 고급 연산은 하드웨어 지원성이 낮다 :
- SE
- GELU
- LayerNorm
MobileNetV4이 택한 연산 :
- Depthwise Conv
- Pointwise Conv
- ReLU
- BatchNorm
- 단순 attention
실제 배포 가능한 단순 모듈을 우선함.
P.S.
- DW를 어디서 어떤 형태로 spatial mixing을 할 것인가
- P3에서 MobileNetV4식으로 expansion 이전 DW를 넣는 ConvNeXt-like 구조?
- 작은 타겟 bbox 정밀도 향상 - ExtraDW?
- MACs 감소 ≠ 배포 성능 향상!!!!!
