https://arxiv.org/pdf/2406.14239
CVPR 2025
최근 YOLO 계열이 효율성보다 고성능 GPU에서의 실제 FPS를 더 중시하고 있다.
=> flops가 늘어나도 gpu최적화가 잘되면 속도는 빠르게 보이기 때문
MCU에선 먹히지 않음.
STM32 계열에서 640*640 기준 1초 이상 걸릴 수 있음.
SSDLite의 한계
임베디드에서는 보통
- MobileNetV2/V3
- MNASNet
- EfficientNet
같은 경량 classifier backbone에 SSDLite detection head 를 붙이는 방식이 많이 쓰임.
문제는 이 조합이 속도는 괜찮은데 정확도가 낮음.
파라미터와 FLOPs를 적극적으로 줄이면서도, YOLO급 정확도에 근접할 수 있는 객체탐지기를 설계할 수 있는가?
논문은
- LeNeck: SSDLite보다 정확하고 거의 비슷한 속도의 detection neck
- LeYOLO: backbone부터 neck까지 객체탐지에 맞게 재설계한 경량 YOLO 계열 모델
을 제안함.
Architecture
- Backbone의 채널 확장 구조
- Neck의 feature fusion 경로
- 높은 해상도 feature에서의 불필요한 pointwise conv 제거
1. Optimized Inverted Bottleneck
MobileNetV2 :
- 1×1 pointwise conv로 채널 확장
- depthwise conv로 공간 정보 처리
- 1×1 pointwise conv로 채널 축소
LeYOLO : 채널이 안 바뀌면 첫 번째 PWConv를 삭제
만약 입력 채널 C와 확장 채널 d가 같다면,
첫 번째 1×1 conv는 실질적으로 채널 수를 바꾸지도 않는데 연산만 많이 먹는 층이 된다.
이 경우 첫 번째 pointwise convolution을 완전히 제거.
pointwise conv는
고해상도 feature에서 특히 비싸다. (yolov8n 기준 p3 = 80*80 map)
- backbone 초반부
- neck의 P3 fusion 위치
에서 첫 번째 pointwise convolution을 제거하면 속도 이득이 크고 정확도 손실은 작다
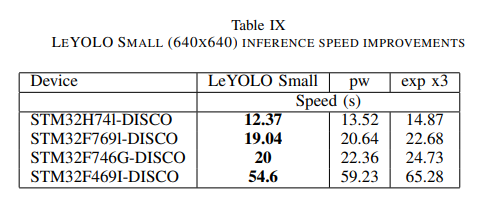
기존 inverted bottleneck에 비해 pointwise 제거 구조가 STM32 벤치마크에서 약 8.5% inference speed 개선됨
2. Expansion Ratio를 3 → 2로 줄임
MobileNetV2 계열 inverted bottleneck은 흔히 expansion ratio를 6까지도 사용.
LeNeck 은 expansion ratio 3 대신 2를 채택함.
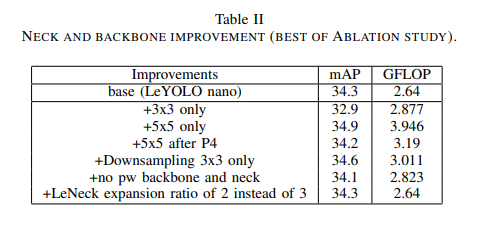
→ mAP 유지, 약 17% 속도 개선
3. LeYOLO Backbone
이 구조를 보면 P4 구간에 깊이를 많이 배분하고, 5×5 depthwise conv를 적극 활용하는 것이 보인다.
=연산 효율 대비 semantic refinement 효율이 좋은 지점이 P4
4. LeNeck — P4 중심의 경량 feature fusion
YOLOv8 계열은 보통 PAN-FPN 스타일 neck을 쓴다.
- P5 upsample → P4 merge
- P4 upsample → P3 merge
- P3 downsample → P4 merge
- P4 downsample → P5 merge
즉, 다중 스케일 feature를 양방향으로 충분히 섞는다.
장점 : 정확도
단점 :
- P3에서 고해상도 convolution 반복
- 여러 concat과 후속 conv
- neck 연산량 증가
P4를 중심 허브로 쓰자
- P3 정보를 P4로 보냄
- P5 정보를 P4로 보냄
- P4 중심에서 semantic fusion
- P3와 P5는 한 번만 처리
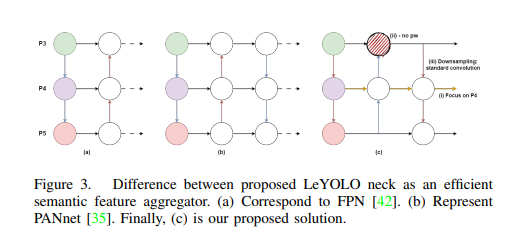
(a) FPN
(b) PANet
(c) LeNeck
- P4를 중심으로 위아래 feature를 모음
- P3에서 불필요한 pointwise conv 제거
- Downsampling을 위한 standard conv를 별도로 둠
- P4에서 연산 초점을 맞춤
경량 backbone에 SSDLite 말고 LeNeck을 붙이면,
속도는 비슷하거나 더 빠르고 정확도는 훨씬 좋아진다.
MobileNetV2-1.0:
| Detector | Speed | mAP |
|---|---|---|
| SSDLite | 259.2 ms | 22.1 |
| LeNeck | 256.3 ms | 28.6 |
MNASNet:
| Detector | Speed | mAP |
|---|---|---|
| SSDLite | 306.2 ms | 23.0 |
| LeNeck | 262.3 ms | 28.9 |
WOW
작은 객체 성능
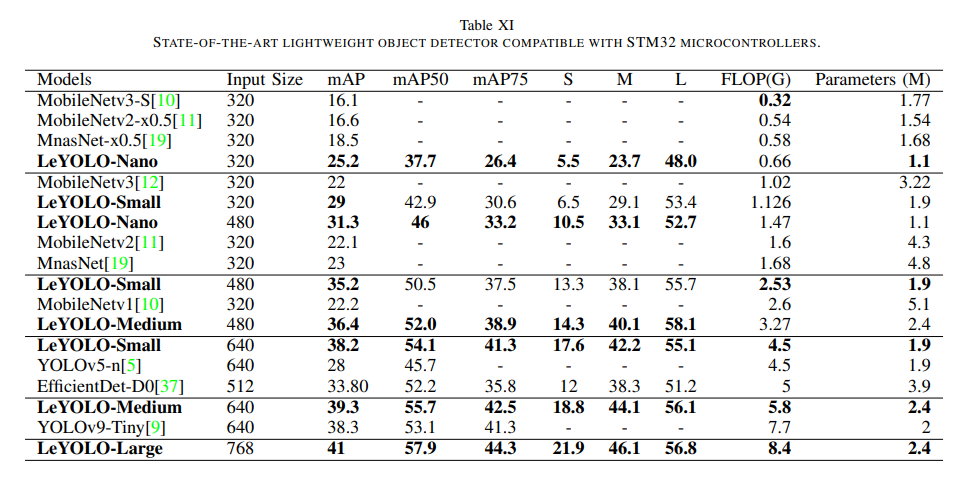
LeYOLO-Small 640의 COCO small-object mAP는:
- S: 17.6
- M: 42.2
- L: 55.1
P.S.
- P3 pointwise conv 제거
- P4 중심 feature fusion
- Expansion ratio 2 기반 inverted bottleneck
