Line Plot
시간의 흐름, 순서에 따른 관측값의 변화, 추세를 시각화 하는데 유용한 선 그래프
import pandas as pd
import matplotlib.pyplot as plt
data = '/content/drive/MyDrive/Colab Notebooks/DataSet/Iris/Iris.csv'
df = pd.read_csv(data)
df = df.drop(['Id'], axis=1)
df.plot.line(title='Iris Dataset')
plt.show()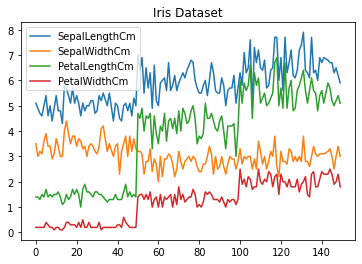
df['SepalLengthCm'].plot();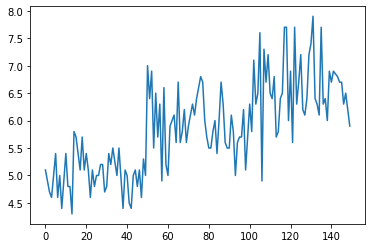
📌 Lineplot 참고:
Histogram
데이터의 분포를 확인 할 수 있다. 이를 토대로 어느 부분에 자료가 많이 집중되어 있는지와 이상치를 살펴볼 수 있고, 데이터의 좌우 대칭성을 설명할 수 있다. 주의할 점은 계급 폭을 다르게 하면 해석이 달라 질 수 있다는 점이다.
plt.hist(df['SepalWidthCm'], bins=10)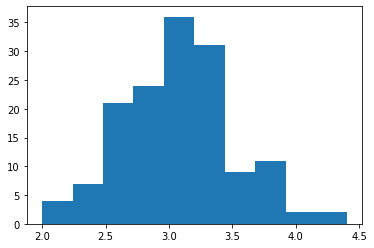
Scatter Plot
두 변수 간의 방향, 트렌드, 밀집도와 이상치를 확인 할 수 있다. 또한, 명목형 변수의 군집별로 색을 다르게 하여 구분할 수도 있다.
groups = df.groupby('Species')
fig, ax = plt.subplots()
for name, group in groups:
ax.plot(group.PetalLengthCm,
group.PetalWidthCm,
marker='o',
linestyle='',
label=name)
ax.legend(fontsize=12, loc='upper left')
plt.title('Scatter Plot of iris by matplotlib', fontsize=20)
plt.xlabel('Petal Length', fontsize=14)
plt.ylabel('Petal Width', fontsize=14)
plt.show()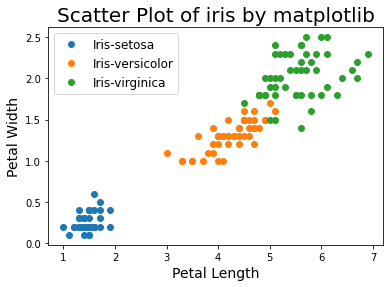
Box Plot
하나의 연속형 변수에 대해서 분포 형태, 퍼짐정도, 이상치 여부등을 시각화하고, 하나의 그룹 혹은 여러개의 그룹 간 비교하는데 유용한 상자그림이다.
연속형 변수에 대해서 최소값(min), 제 1사분위수(Q1), 중앙값(Q2, median), 제 3사분위수(Q3), 최대값(max) 의 요약통계량을 계산하는 것에서 시작한다.
🏷️ BoxPlot 그리는 순서 및 방법
- 주어진 데이터에서 각 사분위수를 계산한다.
- 그래프에서 제1 사분위와 제3 사분위를 밑변으로 하는 직사각형을 그리고, 제 2사분위에 해당하는 위치에 선분을 긋는다.
- 사분위수 범위(IQR, Interquartile range, )를 계산한다.
- 과 차이가 이내인 값 중에서 최댓값을 과 직선으로 연결하고, 마찬가지로 과 차이가 이내인 값 중에서 최솟값을 과 연결한다.
- 보다 이상 초과하는 값과 보다 이상 미달하는 값은 점이나, 원, 별표등으로 따로 표시한다(이상치 점).
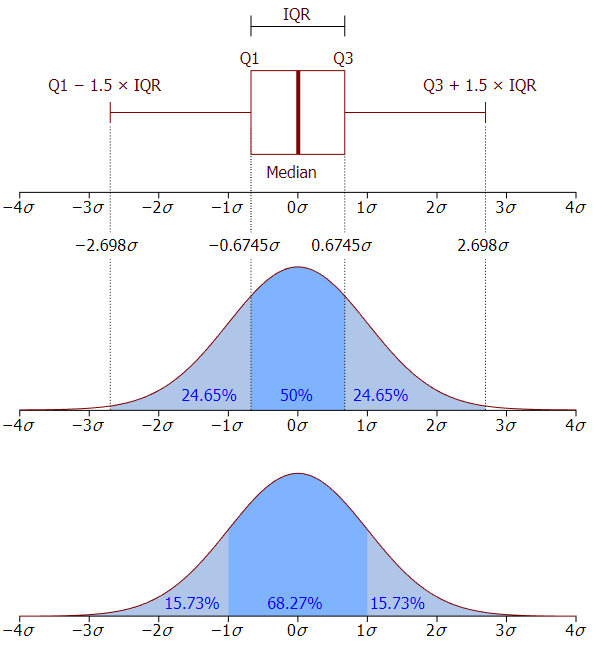
source: https://en.wikipedia.org/wiki/Box_plot
import seaborn as sns
import matplotlib.pyplot as plt
## boxplot
figure = plt.figure(figsize=(10, 8))
plt.rcParams.update({'font.size': 22})
plt.ylim(0, 10)
sns.boxplot(x="Species", y="SepalLengthCm", data=df, showmeans=True,
meanprops={"marker":"s","markerfacecolor":"black", "markeredgecolor":"black"})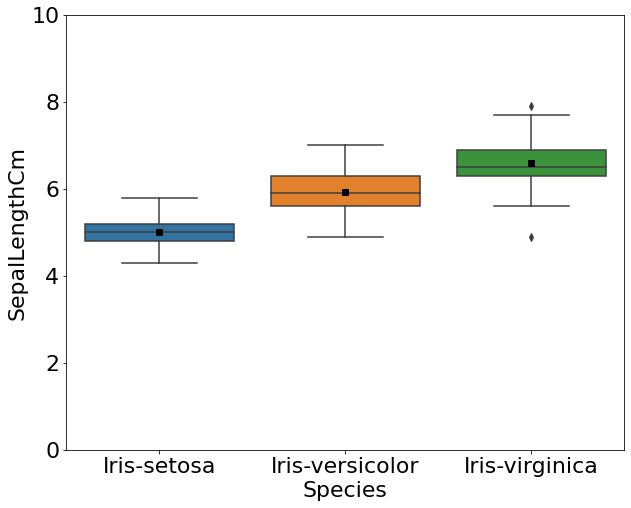
📌 boxplot 참고:
- https://rfriend.tistory.com/410
- https://blog.naver.com/qbxlvnf11/221351657248
https://wikidocs.net/141959
HeatMap
상관계수를 통하여 두 속성 간의 연관성을 나타낼 수 있다. -1에 가까우면 음의 상관관계, 0이면 상관관계가 없고, 1에 가까울수록 양의 상관관계를 나타낸다.
plt.figure(figsize=(7, 4))
sns.heatmap(df.corr(), annot=True)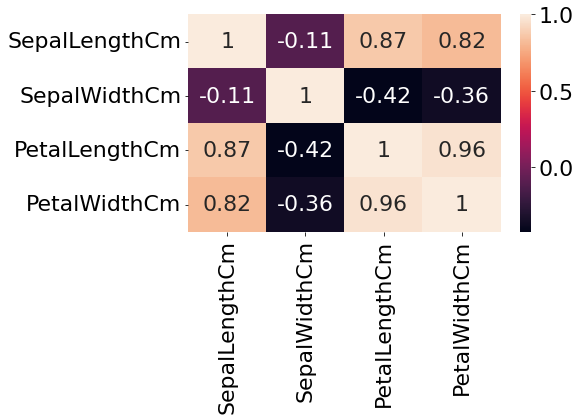
Pair Plot
데이터의 모든 컬럼들의 변수의 상관관계를 histogram과 Scatterplot으로 출력한다. 전체 데이터의 상관관계를 한눈에 볼 수 있다.
sns.pairplot(df, hue='Species')
plt.show()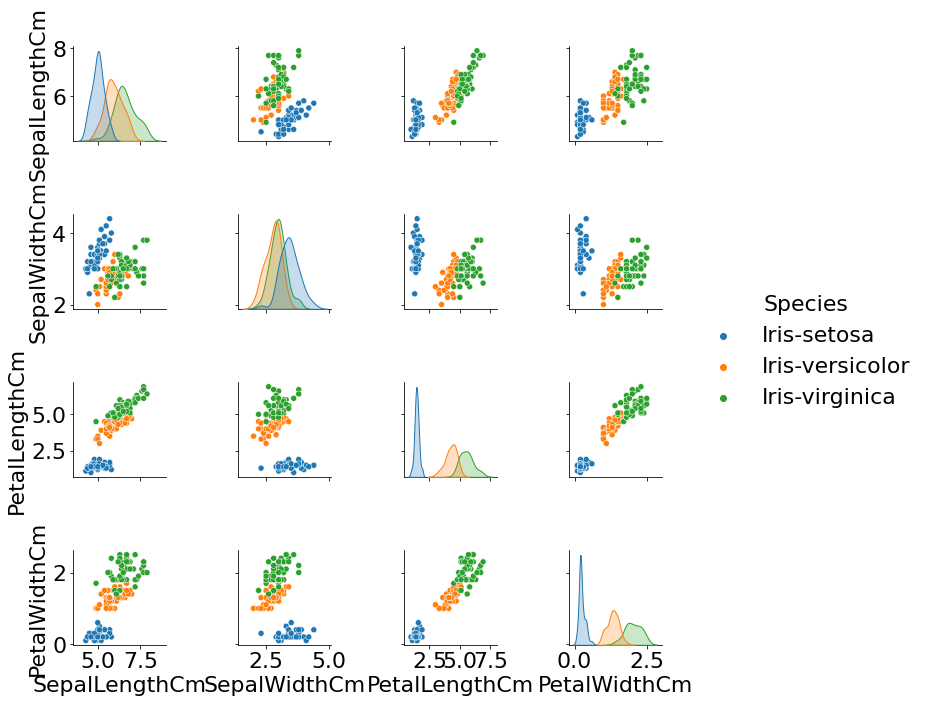
📌 참고:

🔥오늘도 노력하고 있지요😁