
Spark Installation
Apple Silicon 환경에서 스파크 설치를 진행합니다.
각 섹션의 이미지를 클릭하면 설치 페이지 또는 관련 문서로 이동합니다.
Spark 설치
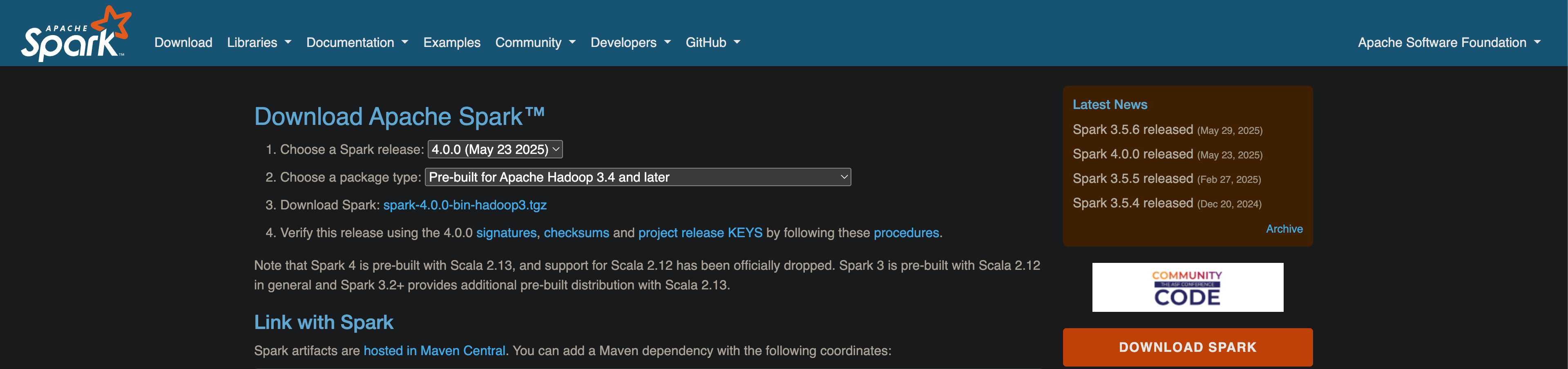
아파치 스파크 다운로드 페이지로 가서 최신 버전 4.0.0 및 "Pre-built for Apache Hadoop" 옵션을 선택하면 해당 버전의 다운로드 링크 spark-4.0.0-bin-hadoop3.tgz 가 나타난다. 해당 링크로 이동하면 아래와 같이 Hadoop 관련 바이너리 파일이 포함된 압축 파일의 설치 경로를 확인할 수 있다.
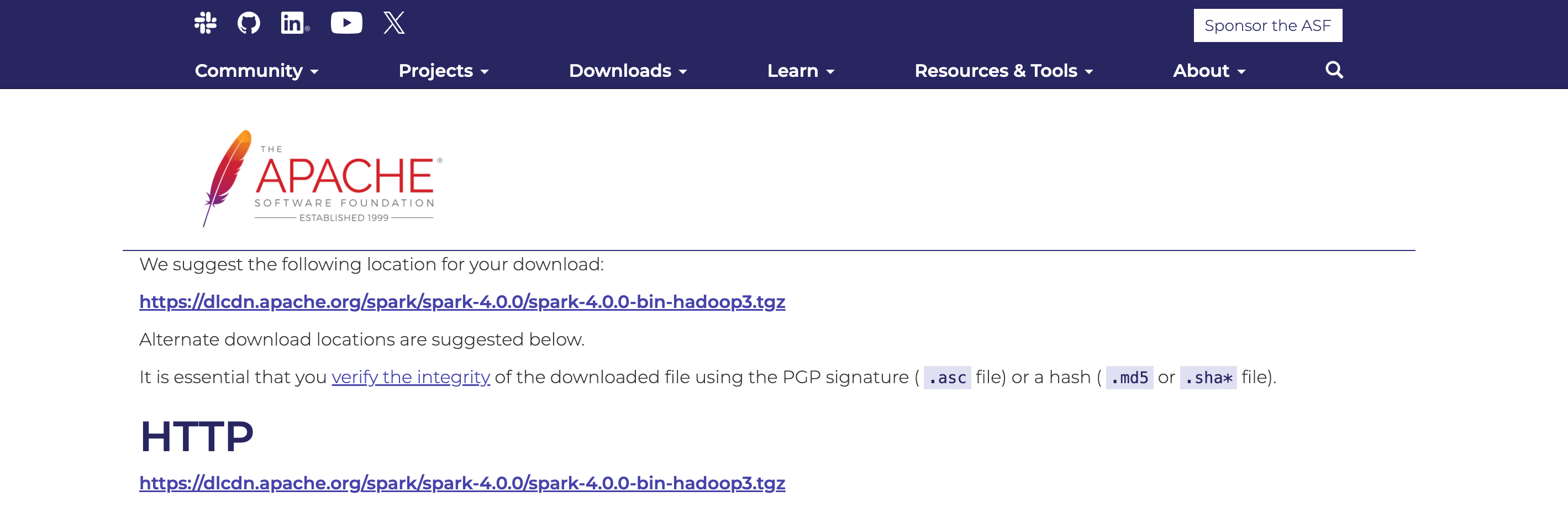
- 브라우저 또는
curl,wget등 명령어를 통해 압축 파일을 내려받을 수 있다.
wget https://dlcdn.apache.org/spark/spark-4.0.0/spark-4.0.0-bin-hadoop3.tgz- 압축 해제 프로그램을 사용하거나, 터미널에서 아래 명령어를 입력하여 압축 해제한다.
tar zxvf spark-4.0.0-bin-hadoop3.tgz- Spark 경로에 접근하기 위해 환경변수를 설정한다.
vi ~/.zshrc- vi 편집기로 .zshrc 파일에 Spark 경로를 등록한다.
SPARK_HOME은 압축 해제한 Spark 경로를 입력한다.
export SPARK_HOME=/Users/{username}/spark-4.0.0
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin- 변경 사항을 적용하기 위해 터미널을 재시작하거나 아래 명령어를 실행한다.
source ~/.zshrc주의할 점은 Spark를 실행하기 전에 Java와 Hadoop이 설치되어 있어야 한다. 보통은 Java 또는 Hadoop 버전에 맞춰서 Spark를 설치하지만, 어떤 것도 설치되어 있지 않기 때문에 스파크 버전에 맞춰서 Java와 Hadoop을 설치한다.
Hadoop은 다운로드할 때 지정한 것과 같은 3.4 버전을 설치하고, Java는 Spark 4.0.0에서 요구하는 최소 버전인 OpenJDK 17 버전을 설치한다. 이미 설치되어 있다면 Spark 실행 섹션으로 넘어간다.
Spark runs on Java 17/21, Scala 2.13, Python 3.9+, and R 3.5+ (Deprecated)
Java 설치

- Homebrew가 설치되었다는 전제 하에 OpenJDK 17 버전을 설치한다.
brew install openjdk@17- 설치가 완료되면, 시스템에서 JDK를 찾을 수 있도록 심볼릭 링크로 연결한다.
sudo ln -sfn /opt/homebrew/opt/openjdk@17/libexec/openjdk.jdk /Library/Java/JavaVirtualMachines/openjdk-17.jdk- 환경변수에 OpenJDK 11의
bin디렉터리를 추가한다. vi 편집기 등으로 직접 수정할 수도 있다.
echo 'export PATH=/opt/homebrew/opt/openjdk@17/bin:$PATH' >> ~/.zshrc- 변경 사항을 적용하기 위해 터미널을 재시작하거나 아래 명령어를 실행한다.
source ~/.zshrc- OpenJDK 11 버전이 정상적으로 설치되었는지 확인하기 위해 아래 명령어를 입력한다.
% java -version
openjdk version "17.0.15" 2025-04-15
OpenJDK Runtime Environment Homebrew (build 17.0.15+0)
OpenJDK 64-Bit Server VM Homebrew (build 17.0.15+0, mixed mode, sharing)Hadoop 설치
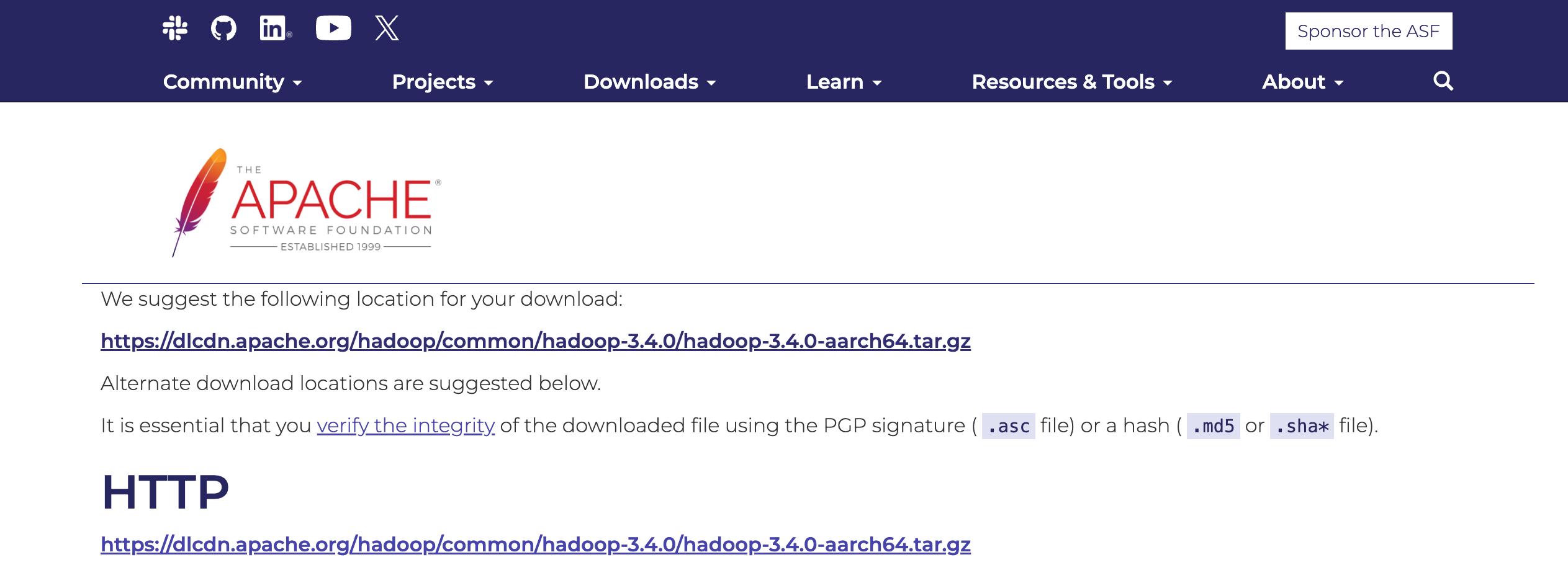
- Homebrew로 설치할 수도 있지만, Hadoop 3.4.0 버전을 맞추기 위해 압축 파일을 직접 내려받는다. 다운로드 버튼을 클릭하거나,
curl,wget등 명령어로 내려받을 수 있다.
(ARM 아키텍처에서 설치할 때는 파일명에aarch64가 포함되어야 한다)
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.4.0/hadoop-3.4.0-aarch64.tar.gz- 압축 해제 프로그램을 사용하거나, 터미널에서 아래 명령어를 입력하여 압축 해제한다.
tar zxvf hadoop-3.4.0-aarch64.tar.gz -C ~/- Hadoop 명령어에 접근하기 위해 환경변수를 설정한다.
vi ~/.zshrc- vi 편집기로 .zshrc 파일에 Hadoop 경로를 등록한다.
HADOOP_HOME은 압축 해제한 Hadoop 경로를 입력한다.
export HADOOP_HOME=/Users/{username}/hadoop-3.4.0
export PATH=$PATH:$HADOOP_HOME/bin- 변경 사항을 적용하기 위해 터미널을 재시작하거나 아래 명령어를 실행한다.
source ~/.zshrc- Hadoop 환경 설정 파일을 수정한다. 파일들은
$HADOOP_HOME/etc/hadoop/경로에 있다.
hadoop-env.sh
export JAVA_HOME=/Library/Java/JavaVirtualMachines/openjdk-17.jdk/Contents/Homecore-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>- HDFS은 자체적으로 SSH를 사용한다. SSH 키를 생성하고 본인 계정에 인증한다.
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
ssh localhostHDFS 실행
네임노드를 포맷하고 HDFS을 구성하는 모든 데몬을 실행한다.
hdfs namenode -format
$HADOOP_HOME/sbin/start-dfs.sh먼저, 네임노드를 포맷하면 아래와 같은 로그가 발생한다.
호스트명으로 localhost 대신 다른 명칭을 사용하는데, 이로 인해 오류가 발생했다.
% sudo hdfs namenode -format
Password:
2025-06-28 18:33:03,038 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = minyeamer/127.0.0.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 3.4.0
STARTUP_MSG: classpath = /Users...정상적으로 HDFS이 실행된다면 아래와 같은 메시지를 조회할 수 있다.
% $HADOOP_HOME/sbin/start-dfs.sh
Starting namenodes on [minyeamer]
Starting datanodes
minyeamer: datanode is running as process 21771. Stop it first and ensure /tmp/hadoop-cuz-datanode.pid file is empty before retry.
Starting secondary namenodes [minyeamer]
minyeamer: secondarynamenode is running as process 21906. Stop it first and ensure /tmp/hadoop-cuz-secondarynamenode.pid file is empty before retry.
2025-06-28 18:51:34,493 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicablejps 명령어를 입력하면 실행중인 노드를 확인할 수 있다.
% jps
21906 SecondaryNameNode
23016 Jps
22216 NameNode
21771 DataNodeHDFS을 종료하고 싶다면 start-dfs.sh 와 동일한 경로에서 stop-all.sh 스크립트를 실행하면 된다.
% $HADOOP_HOME/sbin/stop-all.sh
WARNING: Stopping all Apache Hadoop daemons as cuz in 10 seconds.
WARNING: Use CTRL-C to abort.
Stopping namenodes on [minyeamer]
Stopping datanodes
Stopping secondary namenodes [minyeamer]
Stopping nodemanagers
Stopping resourcemanagerHDFS 실행 중 오류 처리
localhost 가 아닌 minyeamer 라는 호스트명을 사용하는데, start-dfs.sh 실행 시 아래와 같은 에러 메시지가 발생했다. localhost 명칭을 사용한다면 해당 과정은 무시하고 Spark 실행 섹션으로 넘어간다.
minyeamer: ssh: Could not resolve hostname minyeamer: nodename nor servname provided, or not known첫 번째 에러는 SSH 연결 시 호스트명을 인식할 수 없다는 문제로, /etc/hosts 에 minyeamer 호스트명과 127.0.0.1 IP 주소가 매칭되지 않아서 발생한 문제다. 아래와 같이 추가할 수 있다.
127.0.0.1 localhost minyeamer
255.255.255.255 broadcasthost
::1 localhost minyeamer해당 호스트명으로 SSH 접속을 시도하면 정상적으로 접속할 수 있다.
ssh minyeamer또한, Hadoop 설정 파일도 일부 수정해주어야 한다. $HADOOP_HOME/etc/hadoop/ 경로의 workers 파일에는 localhost 한줄만 적혀있을 건데, minyeamer 호스트명으로 변경한다. 또한, 동일한 경로의 core-site.xml 파일의 hdfs://localhost:9000 부분도 변경해야 한다.
그리고 나서 다시 start-dfs.sh 를 실행했는데 다른 에러가 발생했다.
minyeamer: ERROR: Cannot set priority of namenode process 19072이것만으로는 오류를 파악하기 어려워서 $HADOOP_HOME/logs/ 경로 아래 hadoop-*-namenode-*.log 형식의 로그 파일을 확인했다.
로그 파일에서 에러가 발생한 부분에 아래와 같은 에러 메시지를 확인할 수 있었다.
2025-06-28 18:44:47,867 ERROR org.apache.hadoop.hdfs.server.namenode.NameNode: Failed to start namenode.
java.net.BindException: Problem binding to [minyeamer:9000] java.net.BindException: Address already in use; For more details see: http://wiki.apache.org/hadoop/BindException9000번 포트가 사용되고 있다는 건데, 확인해보니 localhost:cslistener 라는 이름의 프로세스가 실행 중에 있었다.
% lsof -i :9000
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
python3.1 1943 ...아마 localhost 호스트명으로 HDFS을 실행시켰을 때 프로세스가 중지되지 않고 남아있는 것 같아 강제로 중지했다.
kill -9 1943다시 네임노드를 포맷하고 HDFS을 실행하니 앞에서 보았던 정상적인 메시지를 확인할 수 있었다.
hdfs namenode -format
$HADOOP_HOME/sbin/start-dfs.shSpark 실행
spark-shell 을 실행하면 정상적으로 동작하는 것을 확인할 수 있다.
(main) cuz@minyeamer ~ % spark-shell
WARNING: Using incubator modules: jdk.incubator.vector
Using Spark's default log4j profile: org/apache/spark/log4j2-defaults.properties
25/06/28 19:45:07 WARN Utils: Your hostname, minyeamer, resolves to a loopback address: 127.0.0.1; using 192.168.x.x instead (on interface en0)
25/06/28 19:45:07 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
Using Spark's default log4j profile: org/apache/spark/log4j2-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 4.0.0
/_/
Using Scala version 2.13.16 (OpenJDK 64-Bit Server VM, Java 17.0.15)
Type in expressions to have them evaluated.
Type :help for more information.
Spark context Web UI available at http://minyeobimacmini:4040
Spark context available as 'sc' (master = local[*], app id = local-1751107510852).
Spark session available as 'spark'.
scala> 메시지에서 알려주는대로 http://minyeobimacmini:4040 경로에 접근하니까 아래와 같은 웹 UI 화면을 조회할 수 있었다.

Spark 디렉터리 구조
Spark 경로 아래에는 다음과 같은 디렉터리 또는 파일이 존재한다.
% ls ~/spark-4.0.0
bin/ conf/ data/ examples/ hive-jackson/ jars/ kubernetes/ licenses/
python/ R/ sbin/ yarn/ LICENSE NOTICE README.md RELEASE-
READMD.md
스파크 셸을 어떻게 사용하는지에 대한 안내 및 스파크 문서의 링크와 설정 가이드 등이 기록되어 있다. -
bin
spark-shell을 포함한 대부분의 스크립트가 위치한다. -
sbin
다양한 배포 모드에서 클러스터의 스파크 컴포넌트들을 시작하고 중지하기 위한 관리 목적이다. -
kubernetes
쿠버네티스 클러스터에서 쓰는 스파크를 위해, 도커 이미지 제작을 위한 Dockerfile들을 담고 있다. -
data
MLlib, 정형화 프로그래밍, GraphX 등에서 입력으로 사용되는.txt파일이 있다. -
examples
Java, Python, R, Scala에 대한 예제들을 제공한다.
PySpark Installation
PyPi 설치

pip install pyspark명령어를 입력해 PyPi 저장소에서 PySpark 라이브러리를 설치할 수 있다. 다운로드한 파일과 동일하게 25년 5월 23일 릴리즈된 4.0.0 버전을 설치한다. 다른 버전을 설치하고 싶다면 pip install pyspark=3.0.0 과 같이 입력할 수 있다.
SQL, ML, MLlib 등 추가적인 라이브러리를 같이 설치하려면 pip install pyspark[sql,ml,mllib] 와 같이 입력할 수 있다.
별도의 가상환경에서 PySpark를 설치하는 것을 추천한다. 4.0.0 버전 기준으로 Python 3.9 버전부터 지원한다. 개인적으로는 Python 3.10 버전을 사용한다.
(spark) % pip install pyspark
Collecting pyspark
Downloading pyspark-4.0.0.tar.gz (434.1 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 434.1/434.1 MB 3.9 MB/s eta 0:00:00
...
Successfully built pyspark
Installing collected packages: py4j, pyspark
Successfully installed py4j-0.10.9.9 pyspark-4.0.0pyspark 실행
spark-shell 은 Scala 쉘을 실행한다.
Scala가 아닌 Python을 사용하고 싶다면 pyspark 쉘을 실행할 수 있다.
(spark) % pyspark
Python 3.10.18 | packaged by conda-forge | (main, Jun 4 2025, 14:46:00) [Clang 18.1.8 ] on darwin
Type "help", "copyright", "credits" or "license" for more information.
WARNING: Using incubator modules: jdk.incubator.vector
Using Spark's default log4j profile: org/apache/spark/log4j2-defaults.properties
25/06/28 21:35:50 WARN Utils: Your hostname, minyeamer, resolves to a loopback address: 127.0.0.1; using 192.168.x.x instead (on interface en0)
25/06/28 21:35:50 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
Using Spark's default log4j profile: org/apache/spark/log4j2-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
25/06/28 21:35:50 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 4.0.0
/_/
Using Python version 3.10.18 (main, Jun 4 2025 14:46:00)
Spark context Web UI available at http://minyeobimacmini:4040
Spark context available as 'sc' (master = local[*], app id = local-1751114150819).
SparkSession available as 'spark'.
>>> Python 쉘에서는 대화형으로 Python API를 사용할 수 있다.
현재 경로에 있는 README.md 파일을 첫 번째 10줄만 읽어보았다.
>>> strings = spark.read.text("README.md")
>>> strings.show(10, truncate=False)
+--------------------------------------------------------------------------------------------------+
|value |
+--------------------------------------------------------------------------------------------------+
|# Apache Spark |
| |
|Spark is a unified analytics engine for large-scale data processing. It provides |
|high-level APIs in Scala, Java, Python, and R (Deprecated), and an optimized engine that |
|supports general computation graphs for data analysis. It also supports a |
|rich set of higher-level tools including Spark SQL for SQL and DataFrames, |
|pandas API on Spark for pandas workloads, MLlib for machine learning, GraphX for graph processing,|
|and Structured Streaming for stream processing. |
| |
|- Official version: <https://spark.apache.org/> |
+--------------------------------------------------------------------------------------------------+
only showing top 10 rows
>>>
>>> strings.count()
125쉘을 나가고 싶다면 Ctrl+D 를 눌러 나갈 수도 있고, quit() 함수를 실행해 종료할 수도 있다.
>>> quit()