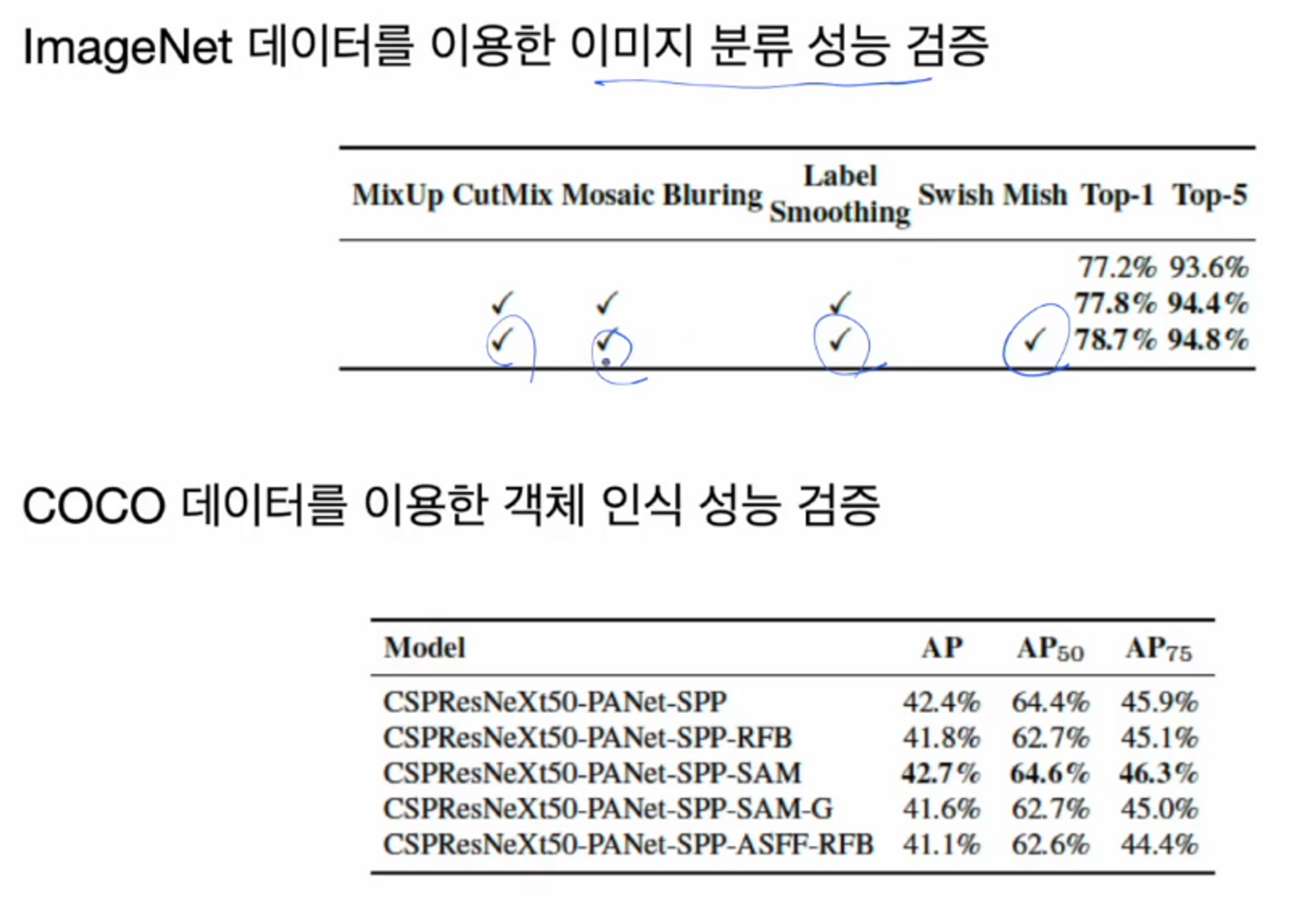
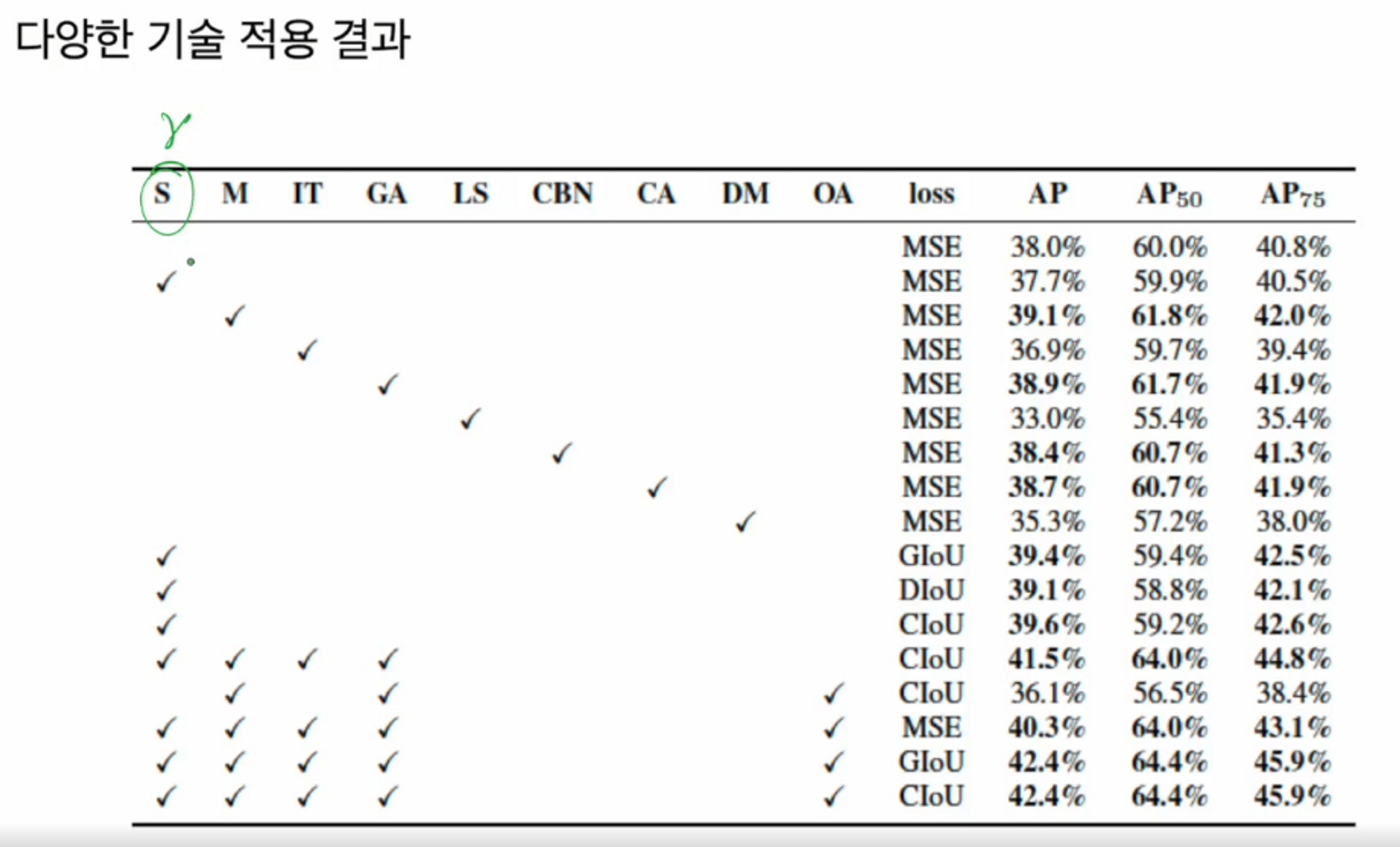
성능 향상 ( BoF for backbone )
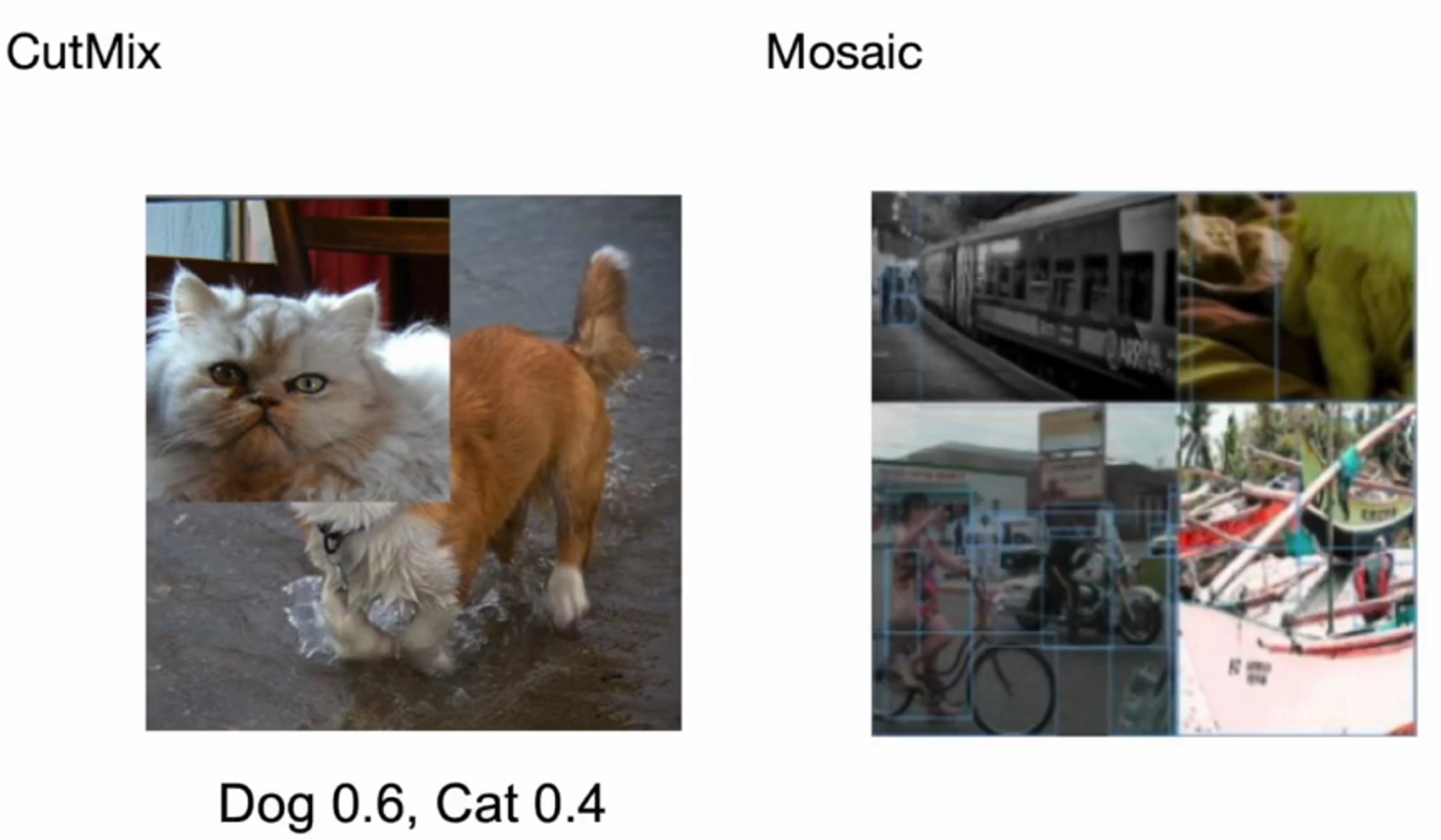
이미지 데이터 augmentation은 기본적으로 색조 변환이나 crop, 회전, 뒤집기 등이 사용됩니다.
mosaic과 cutmix 기술도 적용이 되었네요.
mosaic을 먼저 살펴보겠습니다. 특정 이미지 사이즈 내에 다수의 이미지를 붙여서 하나의 이미지를 만든게 mosaic입니다. 이 mosaic의 장점은 한 번 학습시에 다양한 이미지를 볼 수 있다는 것입니다.
( 정규화에 도움 )
그리고 큰 이미지가 하나 있다면 항상 그 이미지가 있는 위치로 학습이 되는데, 이게 mosaic이 되면서 들어가게 되면서 size도 달라지고 위치도 달라집니다.
cutmix는 두 이미지를 잘라서 붙이는 것입니다. 고양이를 xa, 개를 xb라고 하고 둘을 붙인 이미지를 xt라고 해보겠습니다.
0과 1로만 구성된 Masking vector 를 xa에 곱해주고 , 1-M 값을 xb에 곱해서 더해줍니다.
0을 곱한 부분은 없어지고 1을 곱한 부분은 그대로 값이 보존되겠죠?
그리고 1-M을 하면 xa와 반대의 1과 0 값을 xb에 곱해주게 됩니다. 따라서 사진처럼 나오게 되는 것이죠. 위치는 랜덤하게 적용됩니다.
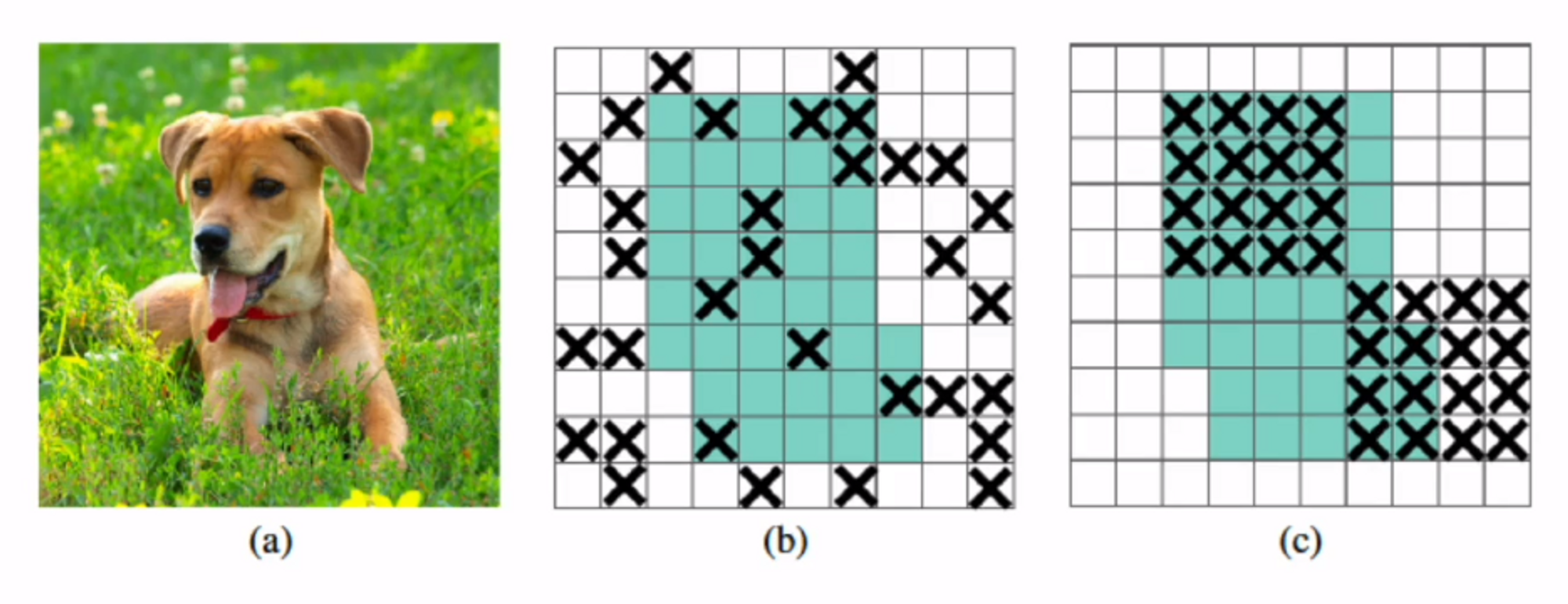
(b)는 Dropout 기법입니다. 랜덤한 feature들을 0으로 만들어주는 기법이죠 ?
(c)가 DropBlock입니다. 랜덤하긴한데 한 덩어리를 가지고 특정 지역을 0으로 만들어줍니다.
Label smoothing

input값이 있고 모델을 거쳐서 output( = prediction )이 나오면 target이랑 비교를 해주는데, 이 target lable은 원래 원 핫 벡터 ( 1, 0 ,0) 으로 이루어져 있죠?
그런데 이 target label을 위의 그림처럼 0.93, 0.03, 0.03으로 바꿔주는 것입니다.
원 핫 벡터를 기준으로 학습을 한다면 prediction 값은 ( 0.999 , 0.1, 0 ) 이렇게 예측될 가능성이 높겠죠. 그런데 저렇게 label이 나온다면 0.999에 해당하는 첫 번째 클래스로 예측을 하고 (0.85, 0.05, 0.1)도 첫 번째 클래스로 예측을 하게 됩니다.
즉, (1,0,0)으로 학습을 하는 것은 너무 강한 제약 조건이라는 것이죠.
그래서 이 부분을 완화하기 위해서 클래스에 해당하는 1값은 줄여주고 나머지 값은 전체 1을 만들어주기 위해서 올려주는 그런 방법이라고 보시면 됩니다.
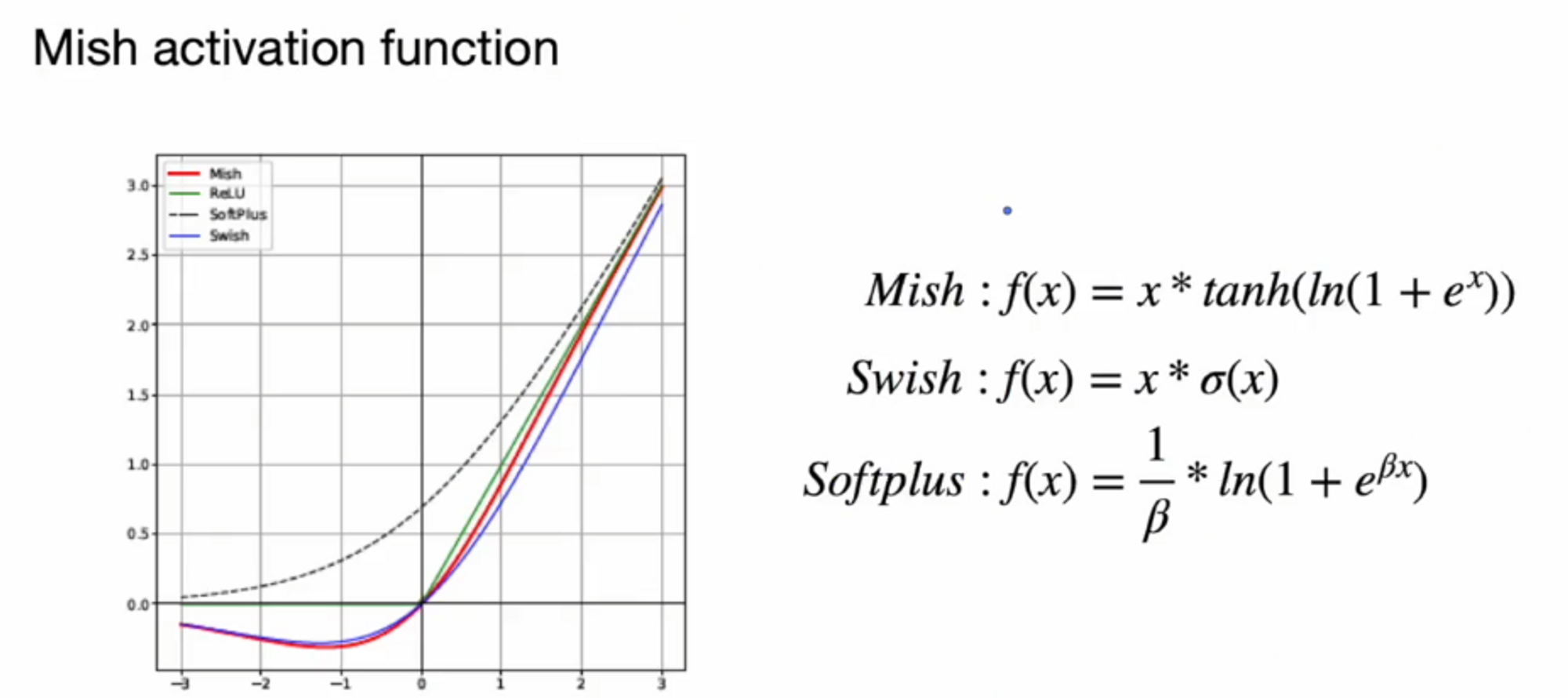
Mish activation function
우리가 모델을 만들 때 비선형으로 만들기 위해서 활성화 함수를 사용하죠
활성화 함수는 어떤 것을 써야한다는 정답은 없습니다.
이 논문에서는 Mish 활성화 함수가 가장 성능이 좋다고하네요.
성능개선 + DenseNet , CSP, BiFPN, MiWRC
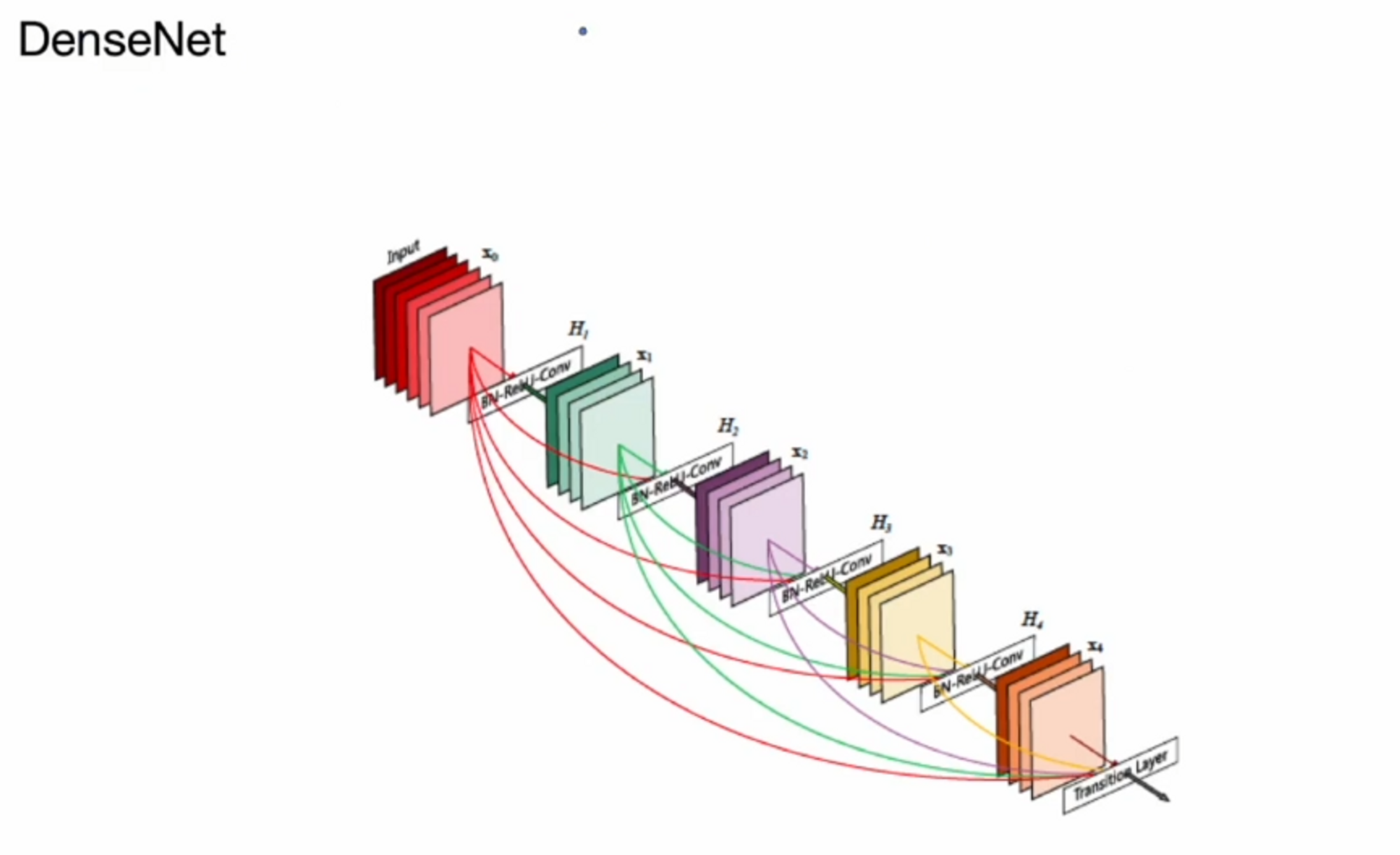
ResNet과 같이 Skip connection이 있는데 ResNet에서는 이전 layer들을 더하는 방식으로 진행했었죠?
DenseNet은 더하는게 아니라 concatenate합니다. 그래서 더 적은 conv operator로 더 많은 featrue map을 활용할 수 있게 되고 ResNet과 마찬가지로 low level에 있는 정보를 high level에서도 사용할 수 있습니다.
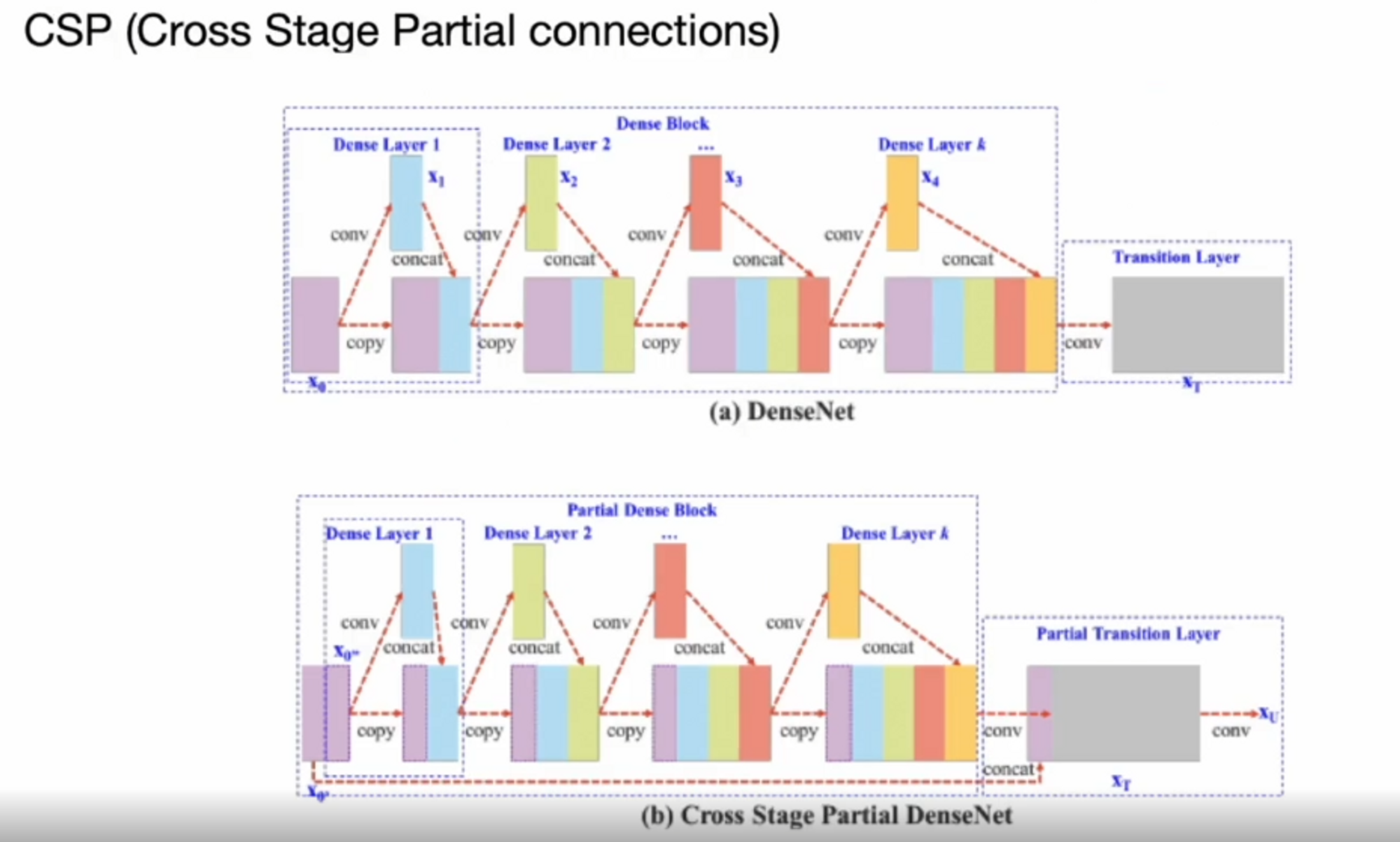
그런데 한 가지 단점이 있습니다. DenseNet을 살펴보면 입력값과 출력값이 같이 concatenate 되므로 backpropagation을 할 때 gradient information이 중복되서 chain rule이 들어갑니다.
따라서 backpropagation을 할 때 비효율적인 연산이 나타납니다.
그래서 이 부분을 개선하고자 하는게 CSP(Cross Stage Partial Connection)입니다.
baseline layer에서 나온 feature map을 반으로 나눠서 한 쪽만 보내고 나머지 한 쪽은 그대로 보내는 것입니다. 반 쪽만 보내서 연산을 하니 성능이 매우 좋아졌다고 합니다.
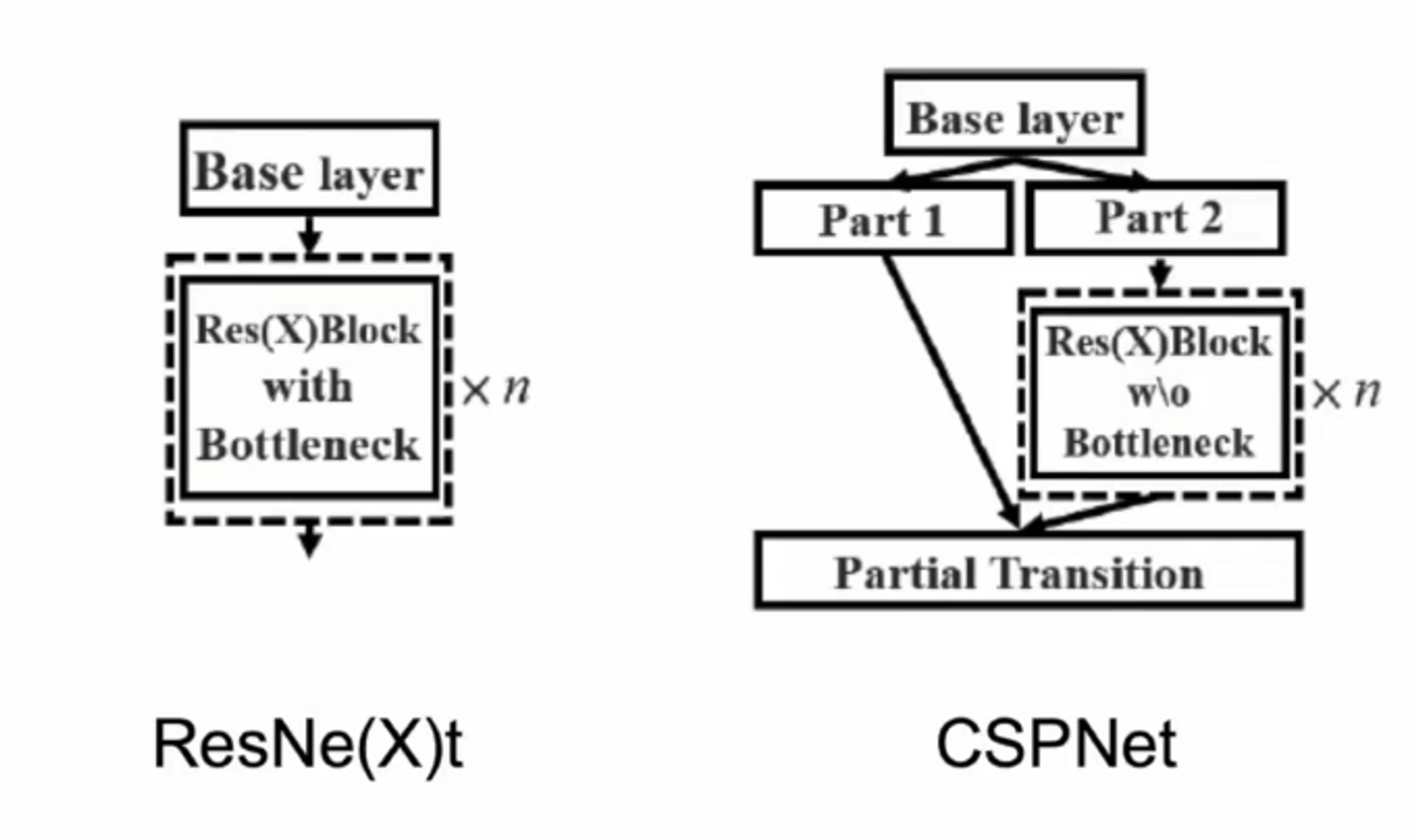
Base layer에서 part를 2가지로 나눠서 part2는 residual block으로 흘려보내고 한 쪽은 block에서 나온 결과와 concat해서 사용을 했더니 더 성능이 좋다고 합니다 !
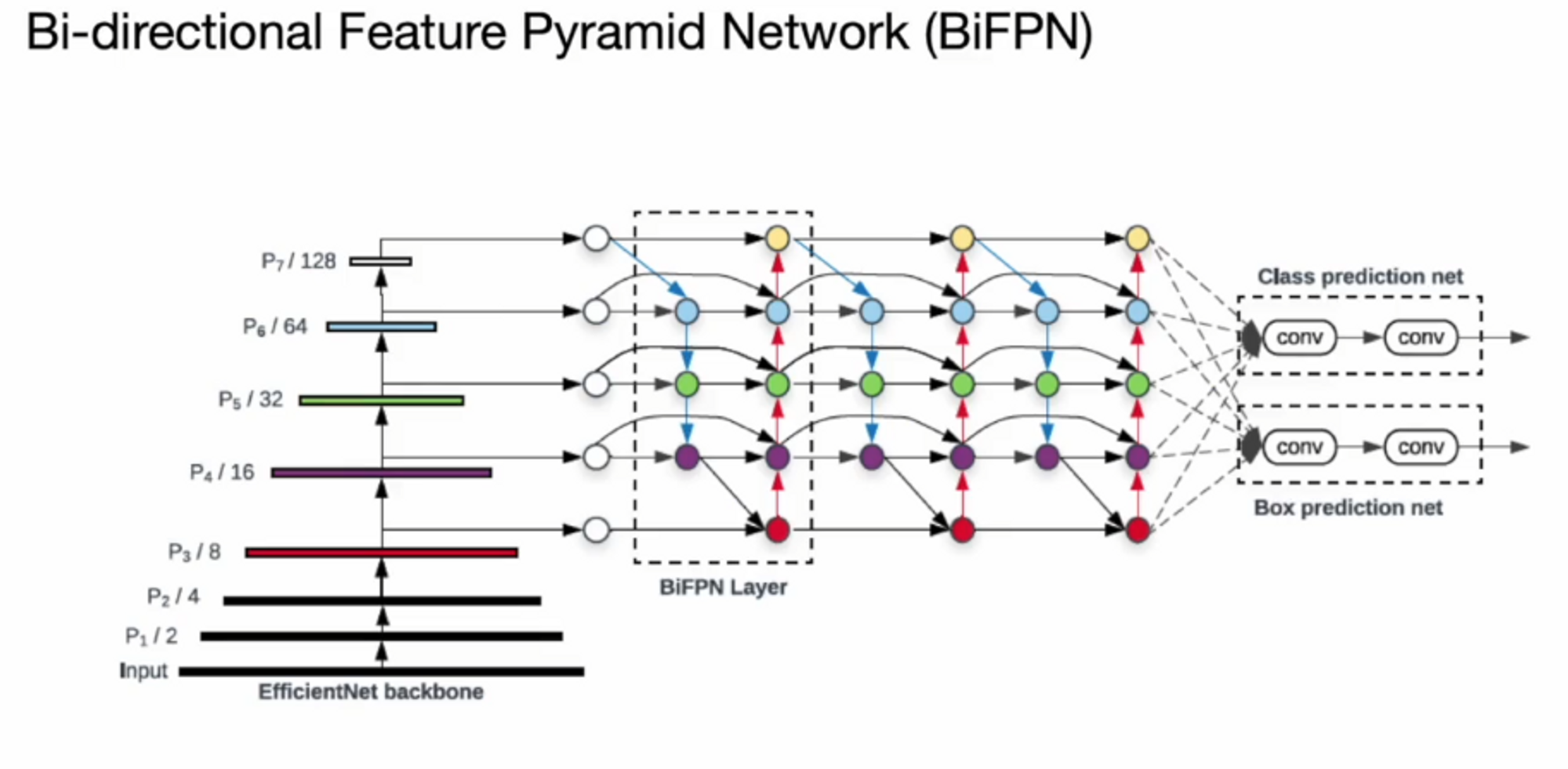
Neck에 해당하는 부분입니다.
이전 버전에서는 Backbone network에서 얻은 feature map들을 Pyramid Network를 통해 위에서 아래로 내려서 feature map들을 공유하는 형태로 예측을 했습니다.
위에서 아래로 내려오는 단방향이었죠.
Bi-directional Feautre Pytramid Network는 양방향으로 ( 아래 ,위 ) feature map들을 공유하고 싶다는 것입니다.
BiFPN에서 위에서 아래로, 아래에서 위로 정보들을 공유하게 되는데 이런 식으로 연산을 하면 scale들이 섞이게 됩니다. 그래서 이 부분을 cross scale connection 이라고 합니다.
그래서 기본적으로 cross scale connection은 BiFPN에서 연산이 됩니다.
이 부분에 대해서 EfficientDet의 저자가 이렇게 말합니다.
scale들이 전부 다른데 그냥 더하거나 concat을 시키면 성능이 좋게 나오지 않을까?
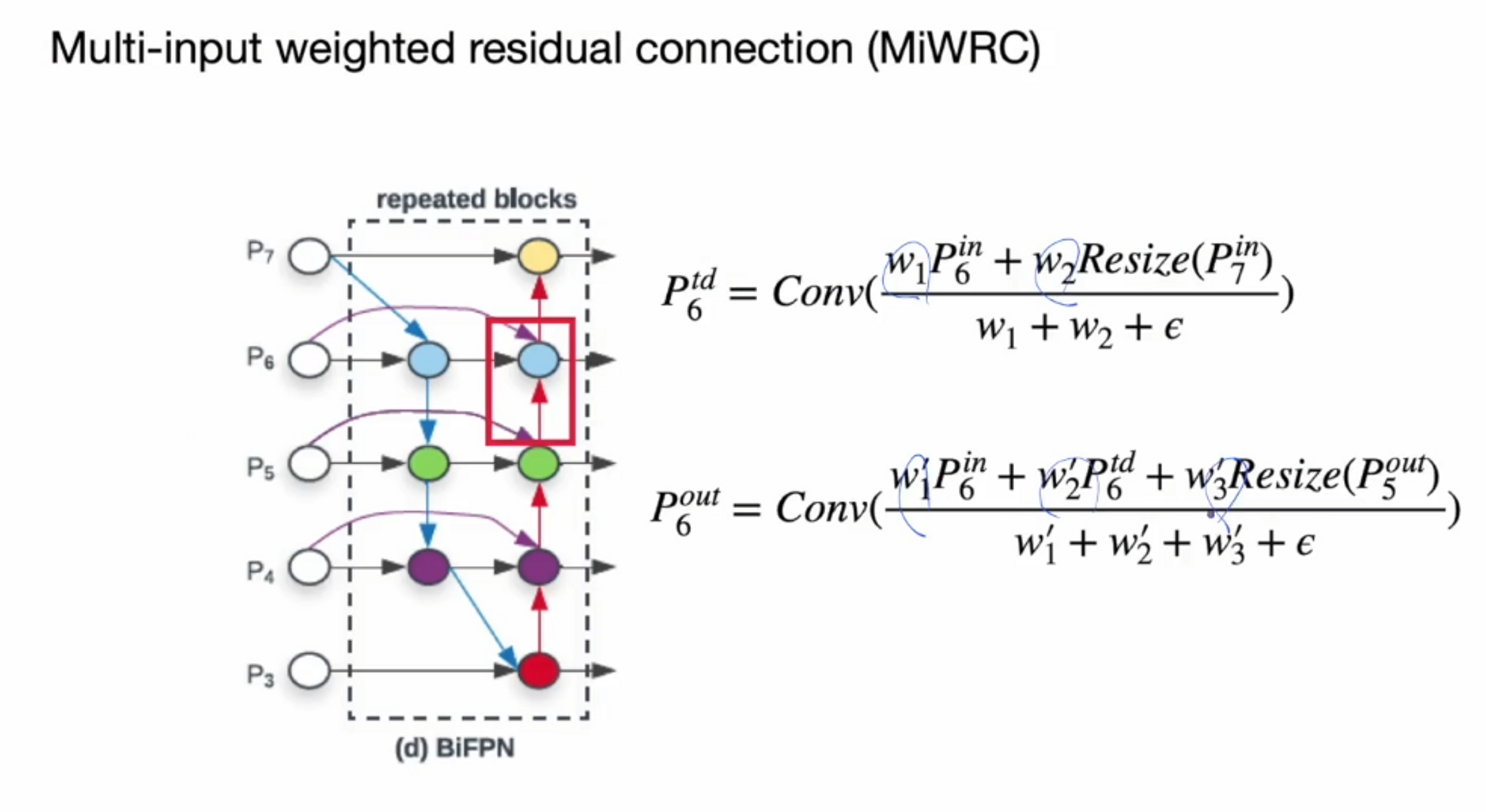
이걸 해결하기 위해서 각 scale을 더하거나 concat할 때 가중치를 주게됩니다.
가중 평균을 이용해서 scale이 안맞는 정보들을 결합하게 됩니다.
위의 식을 보면, P6에서 들어가는 정보를 P6 in 이라고 해볼게요. P7은 위에서 내려오기 때문에 Resize된 P7 in이 들어오게 됩니다. 각 정보들에게 가중치 w1, w2를 곱하게 되고 가중 평균을 이용하기 때문에 w1 w2를 더해서 나눠줍니다. 그리고 0이 되는 것을 방지하기 위해 입실론을 더해줍니다.
이를 Multi-input weighted residual connection ( MiWRC )라고 부르며 v4에서 사용하는 기술 중 하나입니다. 이 기술을 통해서 다양한 scale들을 효과적으로 다루게 됩니다.
성능 향상 BoF for detector
Bbox(detector)의 성능을 향상 시키기 위해 loss function을 mse가 아닌 다른 loss를 사용했습니다.
Bbox의 효율적인 최적화를 위해서는 3가지를 고려해야 한다고 저자들이 생각했습니다.
Bbox regression의 고려조건
- Overlap area 커야함
- Central point distance 작아야함
- Aspect ratio → ground truth 와 prediction의 높이 너비가 어느 정도 맞아야함.
CIoU ( Complete intersection over Union )
yolo v4에서 새로 등장한 loss는 아니고, 기존에 있던 loss들을 여러개 실험을 하면서 선택된 loss 입니다.
( source - Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression(2019) )
Bbox 예측을 위해 MSE 대신 CIoU loss를 적용했습니다.

Bbox의 최적화 조건들을 모두 다루는 식입니다.
- loss 값은 최소가 되어야 하므로 1에서 IoU를 먼저 빼줍니다.
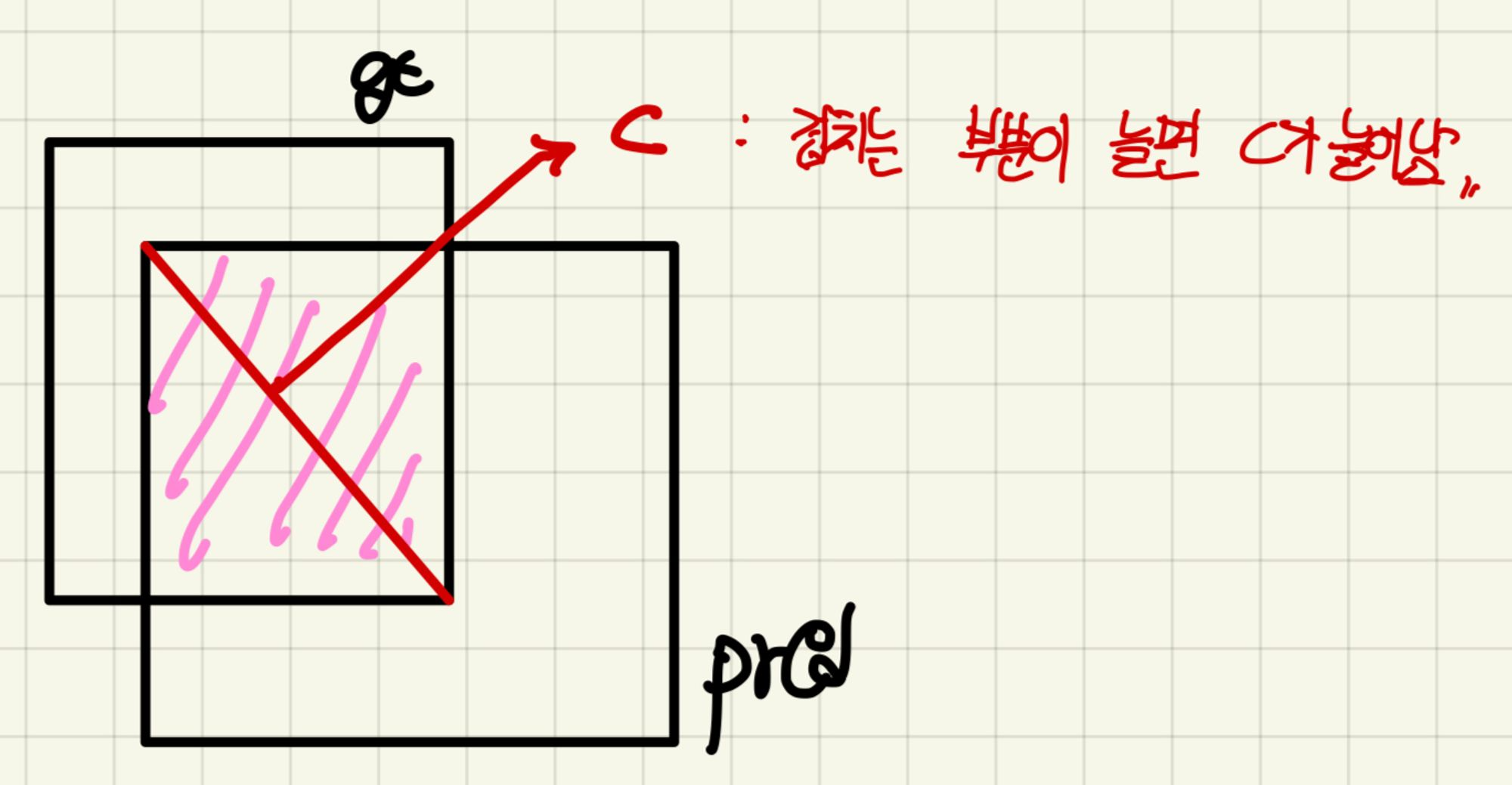
- 이 식에서 분모의 c는 gt와 pred가 겹치는 부분의 대각선을 의미합니다. Central point distance는 최소가 되어야 하므로 분모에 해당하는 c를 제곱합니다. p제곱은 우리가 알고있는 L2 distance와 동일하므로 Bbox의 gt와 pred의 거리를 구합니다. 거리를 계산하면서 겹치는 부분의 대각선까지 고려해주는 것입니다.
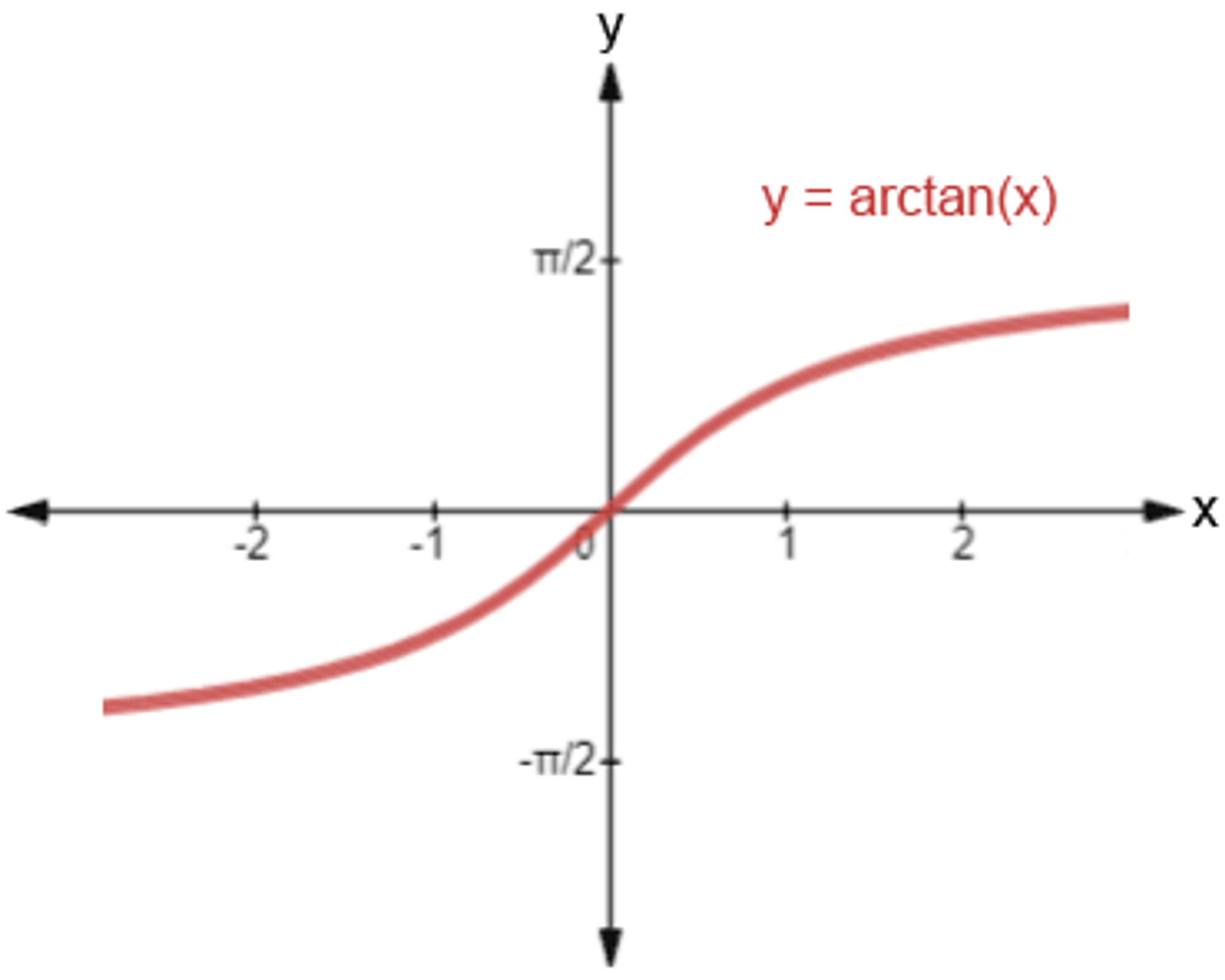
v의 식을 보면 gt의 높이와 너비의 비율과 pred의 높이와 너비의 비율을 Regression 형태의 loss를 만들어서 연산합니다. 여기서 그냥 비율을 빼지않고 arctan를 사용합니다. (arctan을 사용하여 범위를 한정)
a(알파)는 v의 가중치이죠?
1 - IoU는 항상 0보다 크거나 같은 값이 나오기 때문에 분모가 항상 분자보다 크거나 같습니다. 따라서 a는 1보다 작거나 같은 형태가 나옵니다. IoU가 0이라면 a는 1이 나오게됩니다.
즉, 겹치지 않는 경우에 대해서는 가중치를 최대로 올려서 loss function에서 v의 영향력을 키우겠다는 의미입니다.
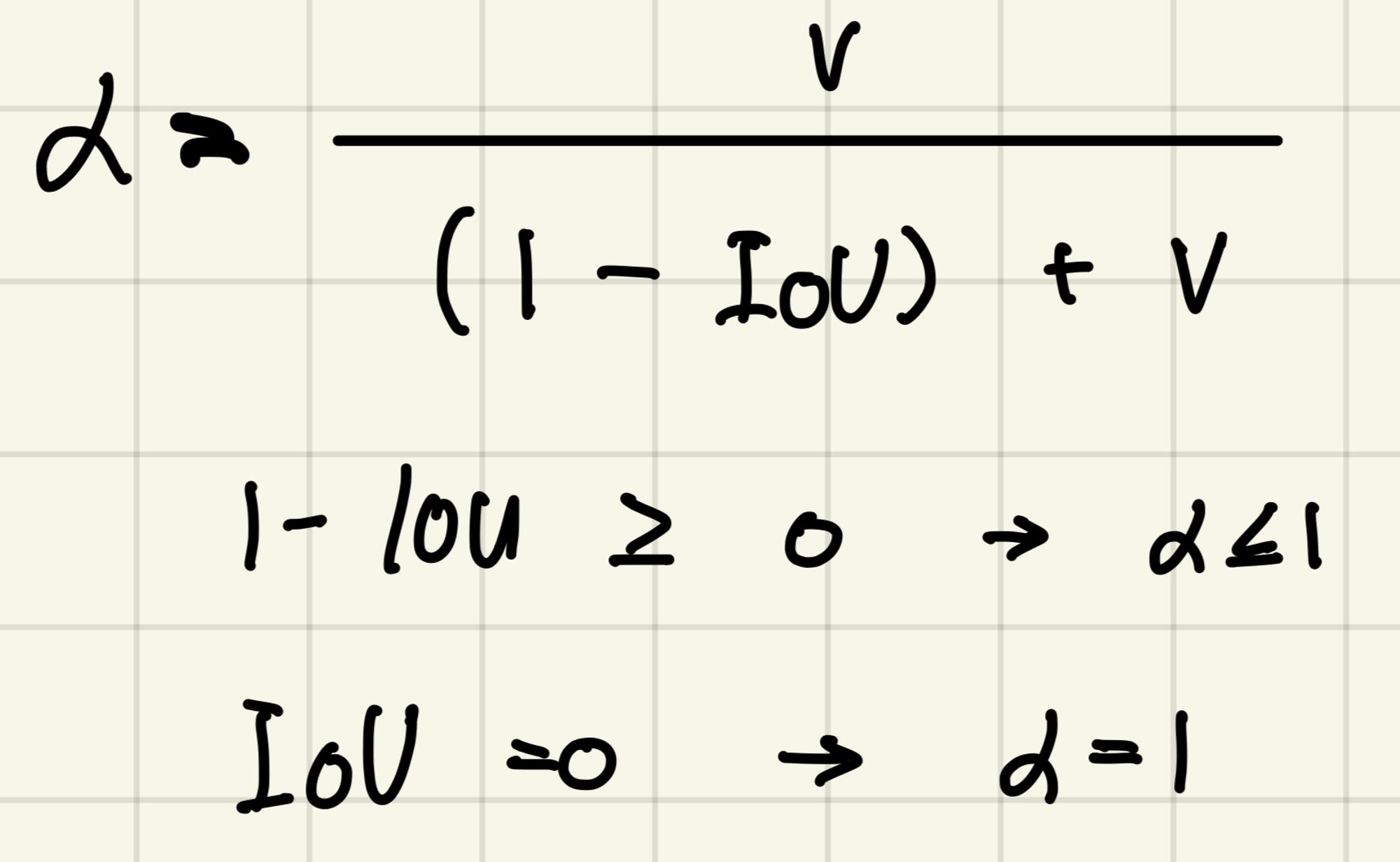
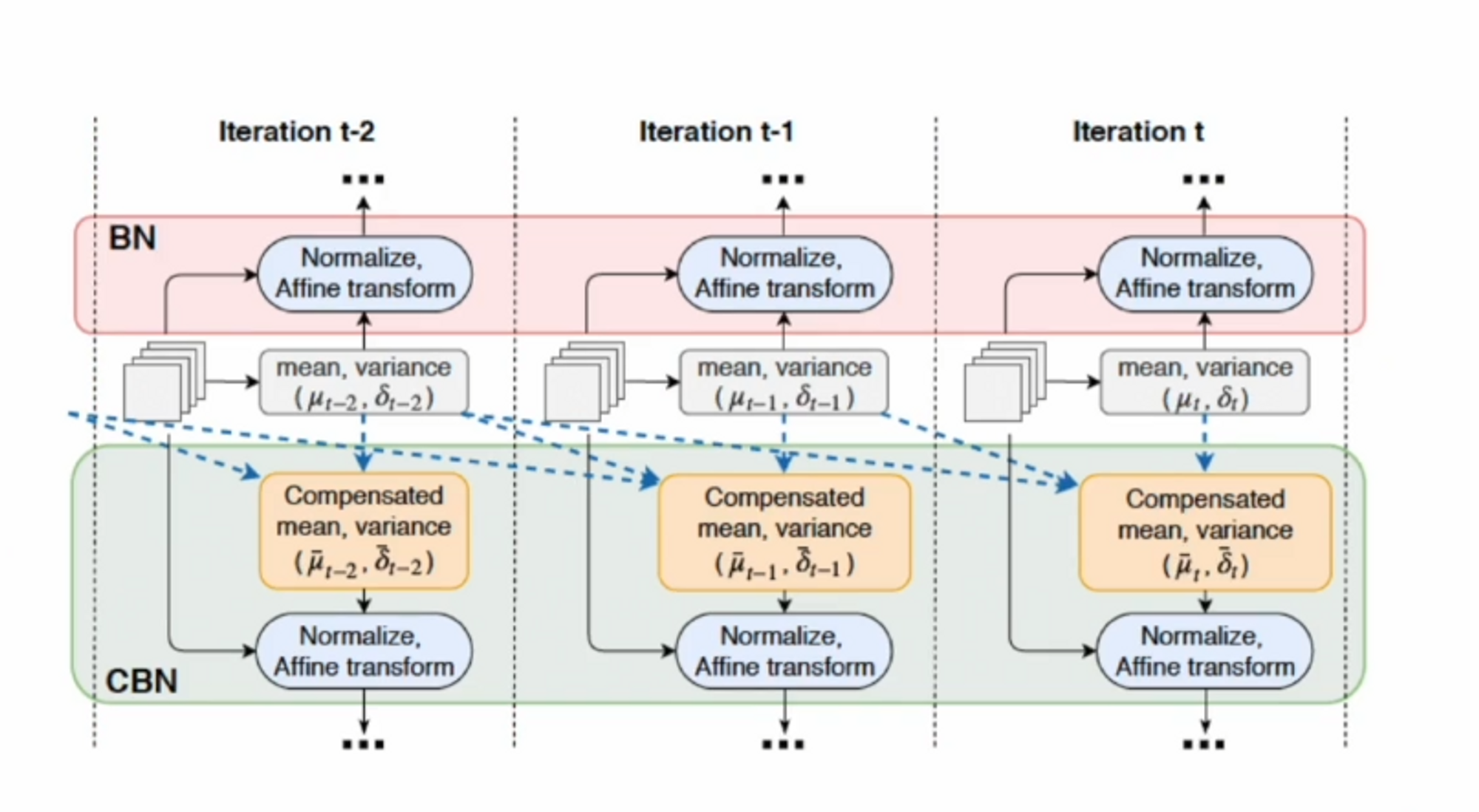
다음으로 학습을 할 때, yolo v4에서는 CBN(Cross Iteration Batch Normalization)을 튜닝해서 사용했습니다. 튜닝을 하기 전인 알고리즘을 먼저 보겠습니다.
기존의 Batch Norm 알고리즘은 Batch 하나 당 평균과 분산을 구해서 그것들의 평균으로 전체 평균과 분산을 추정하죠?
여기서 문제는 Batch가 작을 때, 추정이 약해집니다. 고해상도의 데이터를 처리할 때는 batch를 크게 키울 수가 없기 때문에 표본 샘플 자체가 작습니다. 즉, batch norm의 효과가 떨어질 수 있습니다.
따라서 큰 모델이나 고해상도를 처리하는 모델에서는 batch norm을 사용하는게 비효율적입니다.
CBN은이전에 iteration에서 계산했던 정보를 가지고 현재 평균과 분산을 계산할 때 적용하겠다는 것입니다. 여기서 가정을 하게 됩니다. 근방의 parameter들의 weight은 smooth하게 변한다고 가정합니다.
smooth하는 것은 미분 가능하다는 말과 같습니다.
CmBN ( Cross mini-Batch Normalization )
yolo v4에서는 CBN을 사용하지는 않고 CmBN을 사용합니다.
mini batch란 원래 전체 데이터가 있으면 나눠서 batch를 돌리는 것을 의미합니다.
하지만 여기서 원래 우리가 알던 mini batch를 batch로 봅니다. 그래서 mini batch는 batch의 batch가 되는 것이죠. 예를 들어 데이터가 10000개이고 batch가 32라면 mini batch는 이것을 4개로 나누게 됩니다. 그러면 각 batch는 8개의 크기를 갖는 4개의 mini batch가 되는 것입니다.
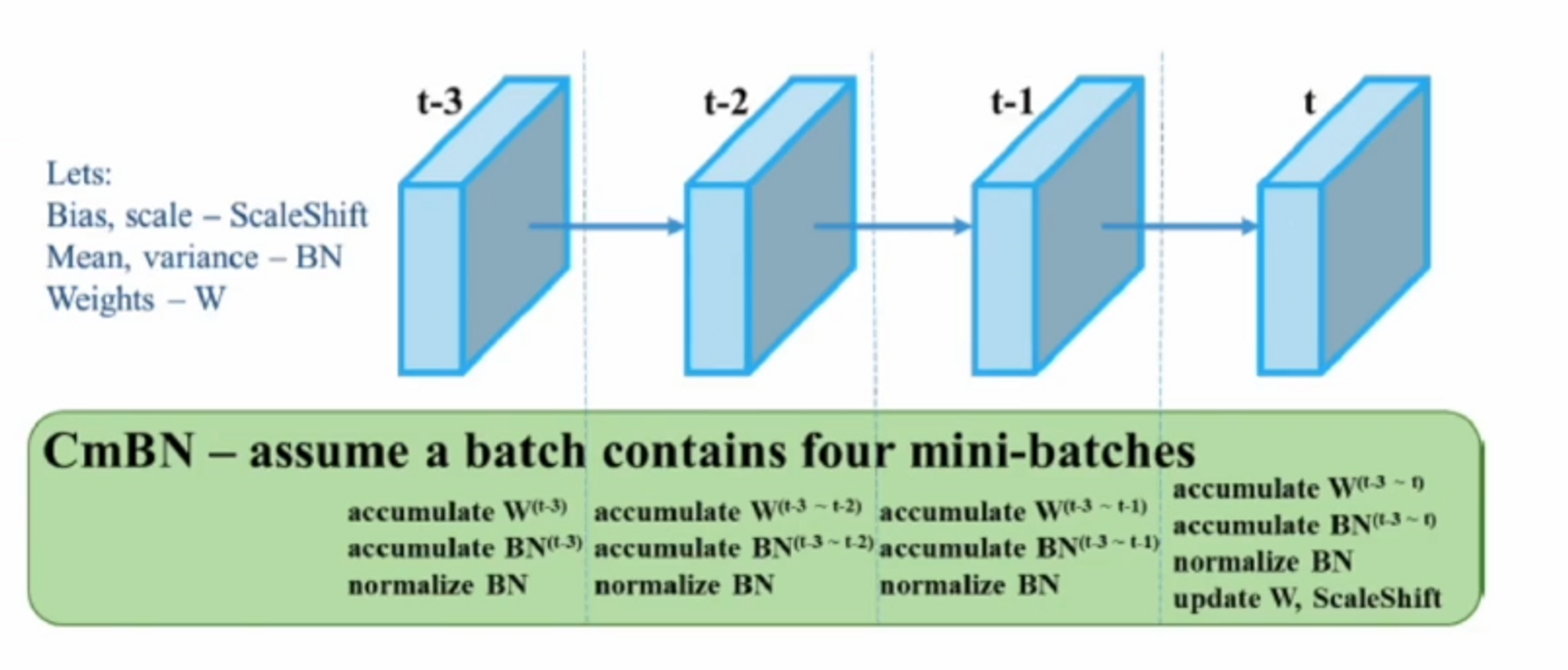
CBN의 매커니즘은 각 iteration마다 업데이트가 되었죠? 그래서 마지막의 값이 t일 때, 당시 평균이 어땠는지를 테일러 급수를 통해 추정을 했는데,
CmBN은 업데이트를 하지 않습니다. weight들을 계속 업데이트 하지 않고 마지막에 한 번 업데이트합니다. 이전의 통계값들을 가져오지 않고 단일 batch에서만 처리하게 됩니다. 이게 가장 큰 차이점입니다.
Consine annealing , SAM, SAT, Hyperparameter optimization
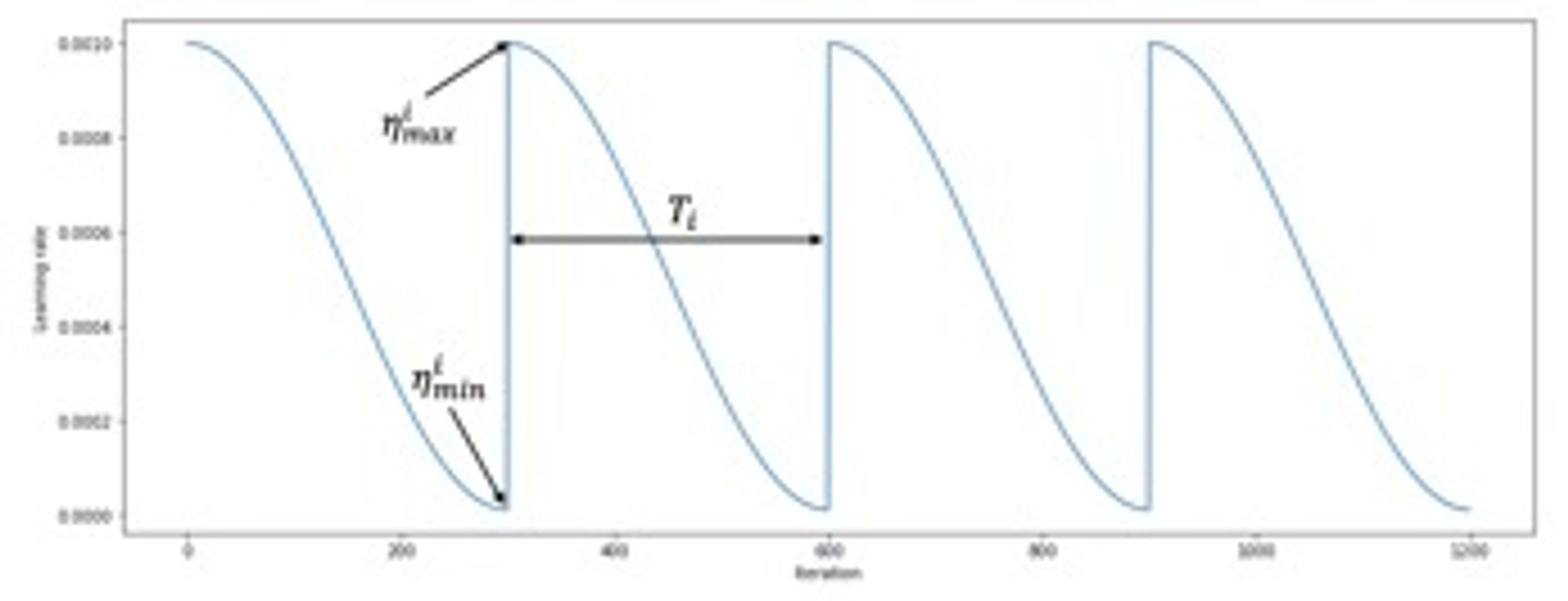
여기서도 learning rate scheduler를 사용했는데, Cosine annealing을 사용했습니다.
원래 epoch가 증가하면 learning rate은 작아지게 되는데, Cosine annealing은 그렇지 않습니다.
Cosine annealing에서는 epoch이 커지면 learning rate이 작아지다가 다시 커지고 작아지고를 반복하게됩니다. 이 방법의 장점은 gradient descent 베이스의 optimizer들은 local minimum인지 global minimum인지 잘 구분하지 못하잖아요? 그래서 만약에 local minimum에 빠졌을 때 lr이 작아지면 빠져나오기 힘들어요. 근데 Cosine annealing처럼 어느 순간 learning rate을 한 번 더 키워줄 때 local minimum에서 빠져나올 수 있는 여지가 있다는 것이죠.
( sorce - SGDR : Stochastic Gradient Descent with Warm Restars ( 2016 ) )

Self-Adversarial Training ( SAT)
Data augmentation을 할 때 SAT를 사용했다고 합니다. 논문에서는 정확한 내용은 나와있지 않아서 다른 논문을 참고했습니다.
( Source : EXPLAING AND HARNESSING ADVERSARIAL EXAMPLES ( 2015) )

판다 이미지에 노이즈를 살짝 더했더니 모델은 판다가 아닌 다른 객체로 인식을 합니다.
노이즈를 다양하게 생성을 해서 adversarial 이미지들을 많이 만들어둡니다. 그 이미지들은 여전히 label이 변하지 않기 때문에 정상적인 방법으로 수정된 이미지도 학습하게끔 일반 이미지와 함께 넣어줍니다. 이렇게 Data augmentation을 사용했습니다.
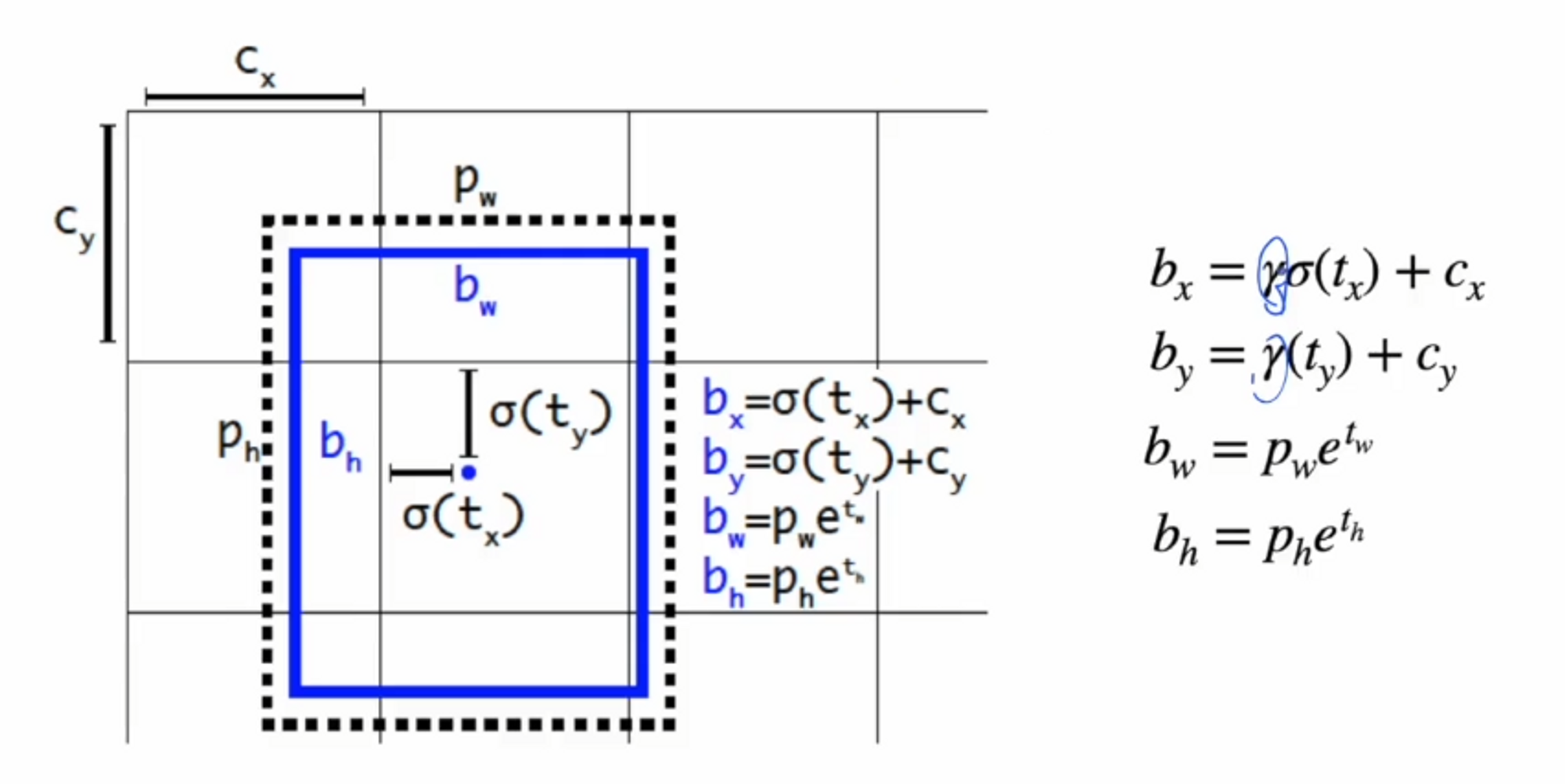
다음으로는 Eliminate grid sensitivity입니다.
yolov3에서는 r(감마)값이 없었는데 v4에서는 감마값을 곱해서 사용합니다.
만약 식에서 시그모이드가 0이 된다면 bx가 cx가 되죠? ( bx = cx )
시그모이드가 1이라면 bx = cx + 1 이 됩니다.
저 그림이 기본적으로 normalization된 grid라고 했을 때, 시그모이드가 양 끝에 가까워지는 값이 나온다면 경계에 놓이게 됩니다. 그걸 방지하기 위해 scale 업을 해주는 감마값을 곱해줍니다.
감마값의 조건은 1보다 커야합니다.
추가 적용 사항
- Optimal hyperparameters을 구하기 위한 Genetic algorithm 적용 ( 정확히 어떤 유전 알고리즘을 사용했는지 나오지 않음) ex. grid search, gaussian process
- 단일 ground truth를 위해 다중 앵커 사용
- 작은 해상도 사용 시 자동 batch-size 증가 적용
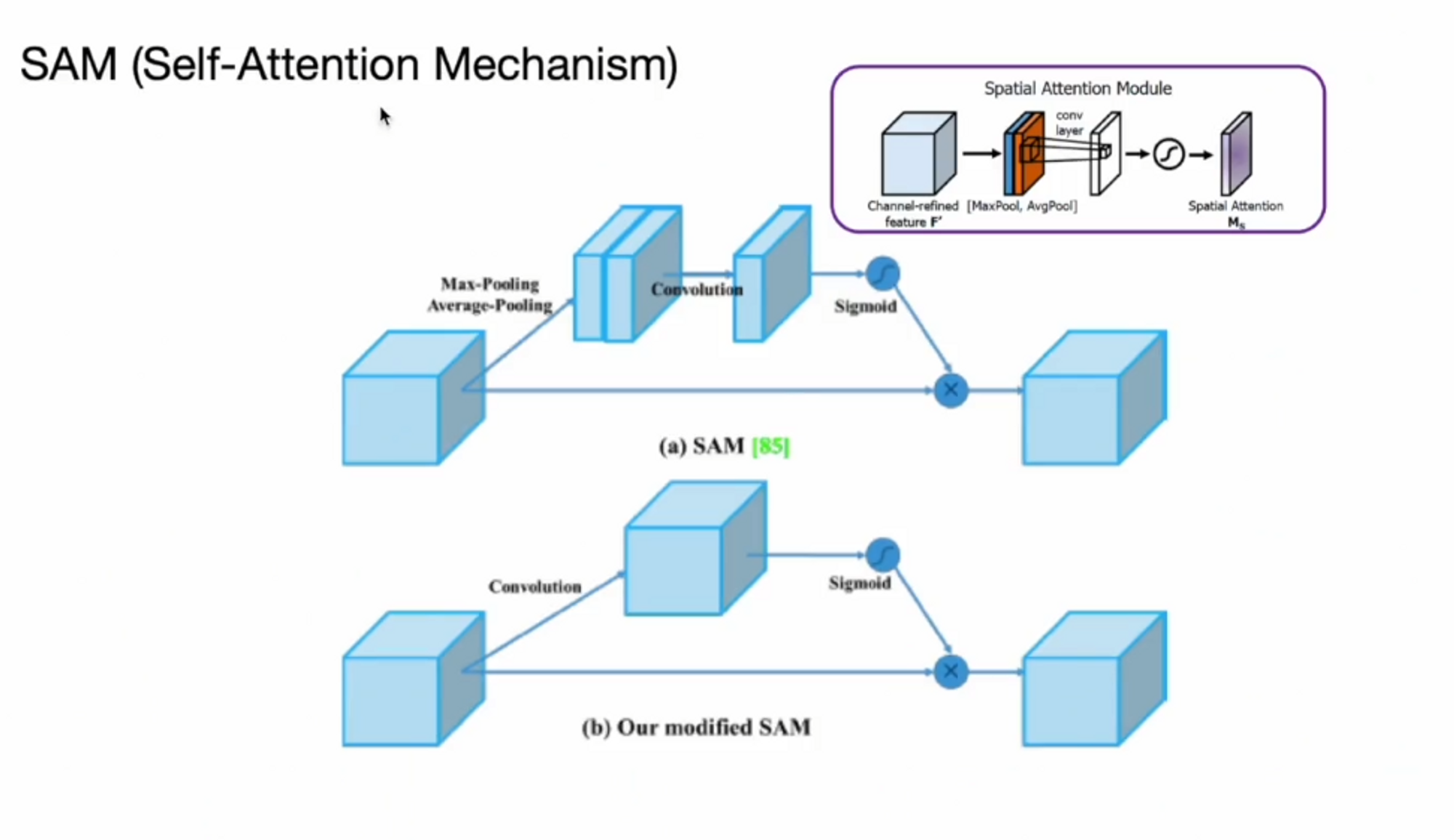
저자들은 attention 기법도 적용을 했습니다.
self-attention을 사용했습니다. 기존에 있던 feature에 mask를 씌워주는게 self attention 매커니즘의 핵심입니다.
( source : CBAM : Convolutional Block Attention Module 2018)
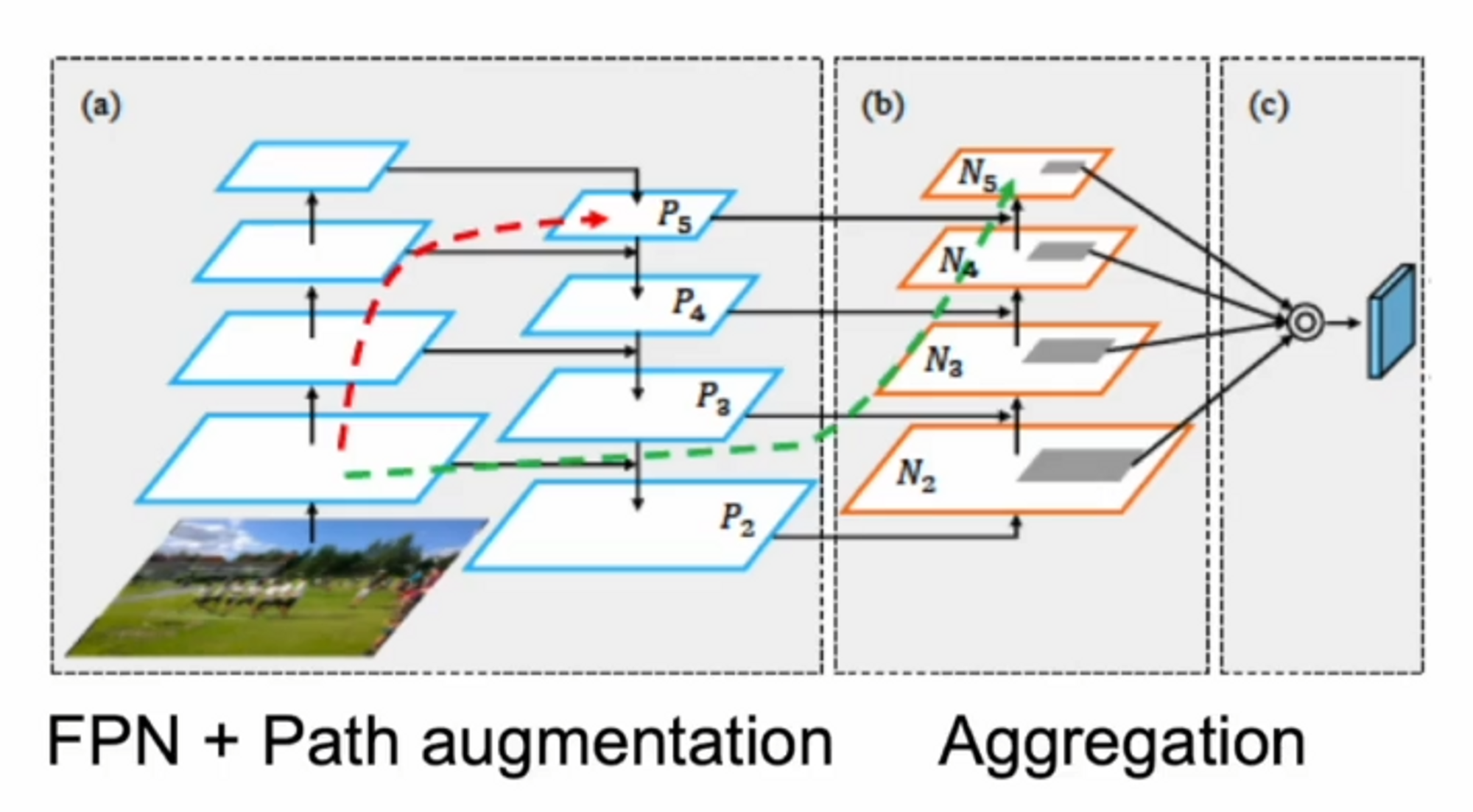
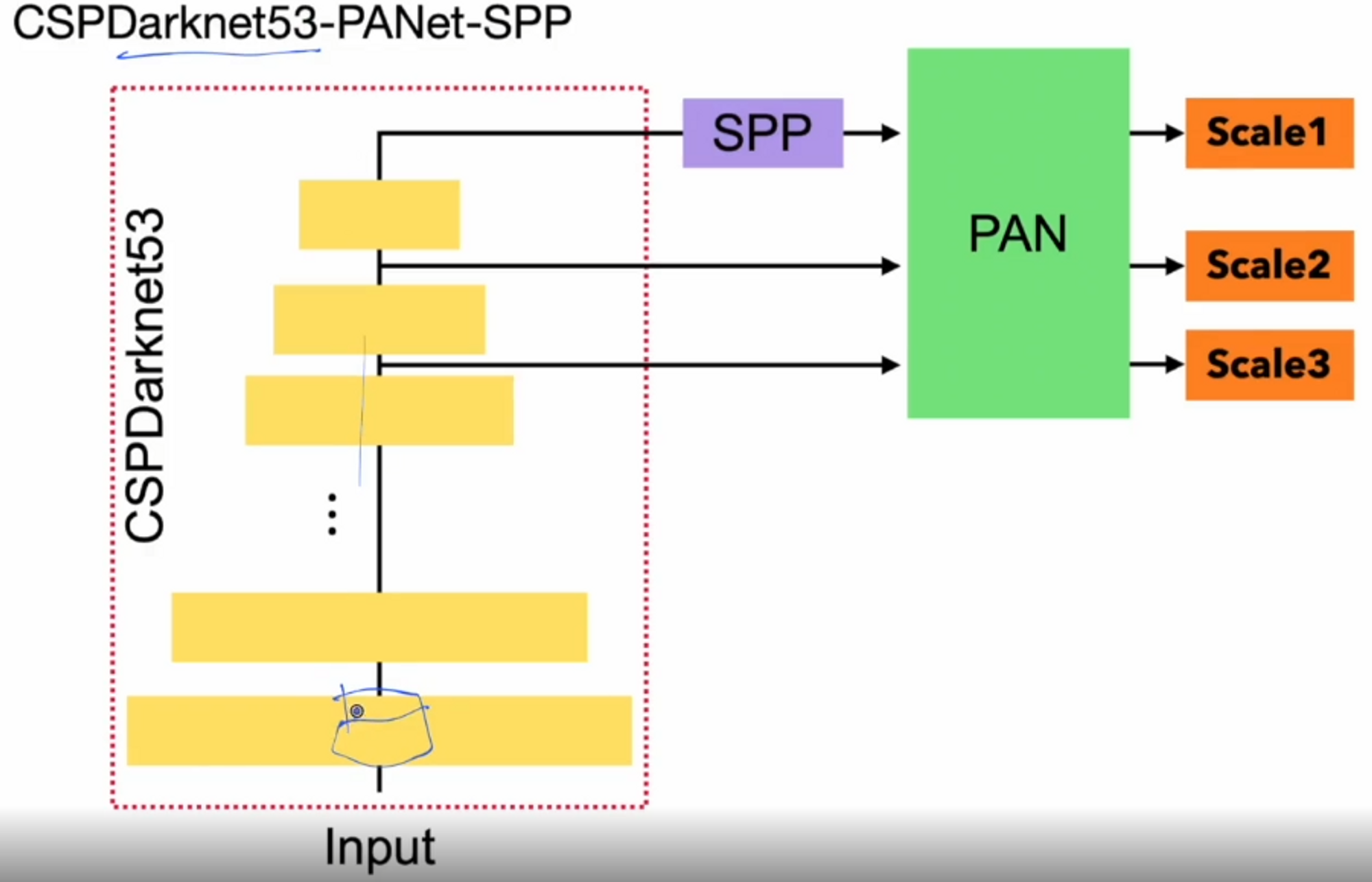
성능 향상 BoS for detector : 성능 개선 및 평가 결과 + PAN , SPP
PAN 이 부분은 BiFPN에서 했던 부분을 다시 반복하는 느낌 ?? 이해가 안가서 pass
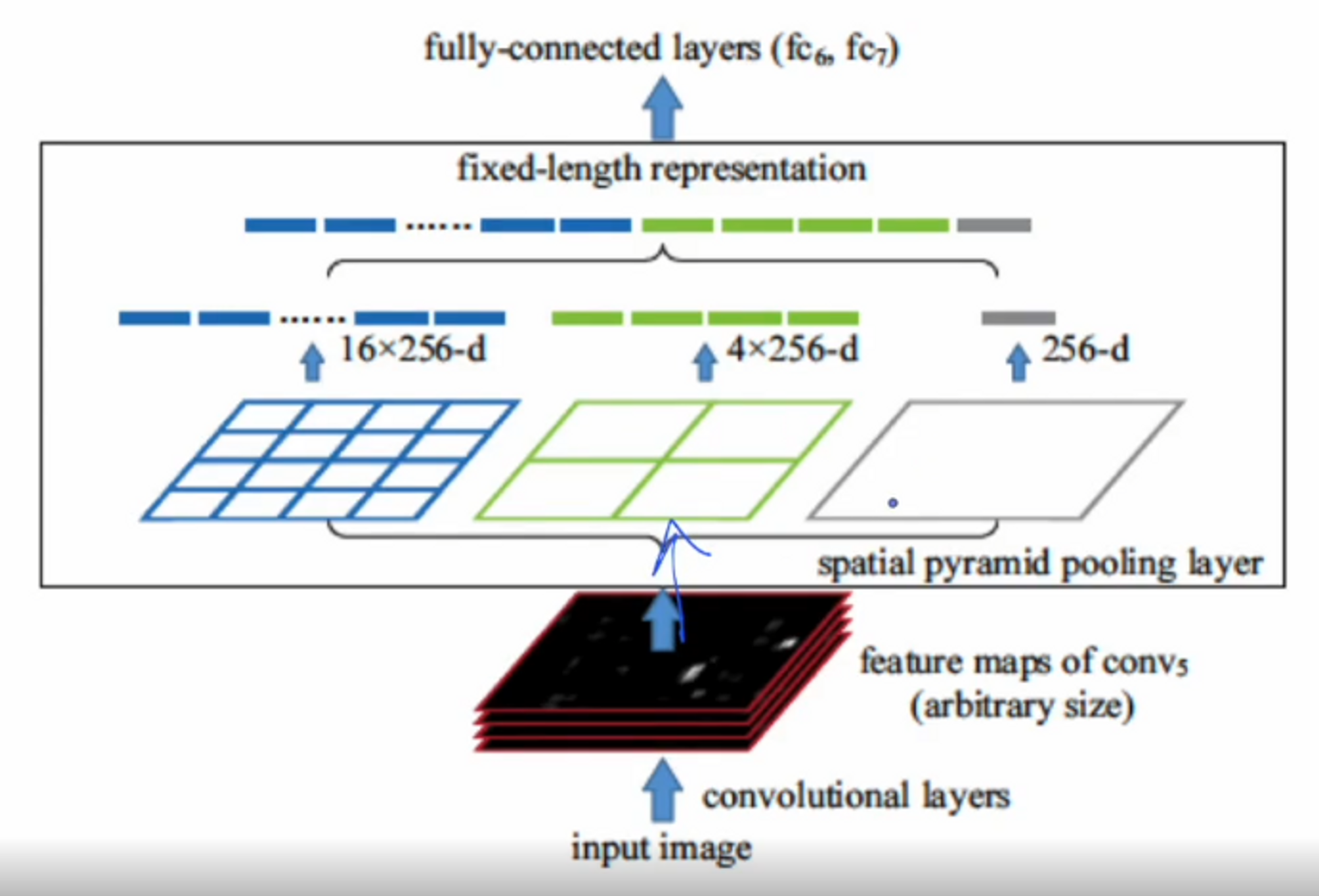
SPP ( Spatial Pyramid Pooling )
Backbone의 가장 마지막에 나오는 feature map을 가지고 spp 사용.
input이 들어오면 세 단계로 나눠서 연산을 해줍니다.
max값을 취해서 채널수만 나올 수 있도록 만들어주고, 4분할 max pooling을 하고, 16분할 max pooling을 해서 채널 수를 만들어 줍니다.
모두 max pooling을 해줬기 때문에 들어오는 크기랑 상관없이 동일한 출력을 만들고 출력값들을 concat 해서 예측에 활용을 합니다.
이 방법의 장점은 receptive field를 크게 증가시켜 준다고 합니다. 그리고 증가와 동시에 max pooling을 해서 네트워크의 연산 속도도 거의 느려지지 않는다고 합니다.
그리고 추론을 할 때 수많은 bbox중에서 best bbox만 뽑아서 보여줘야 하잖아요? 그 때 사용하는 알고리즘이 NMS인데 NMS는 confidence score와 IoU만 고려했습니다.
하지만 여기서 중심 간의 거리도 고려해서 적용하는 방법이 DIoU-NMS 입니다.
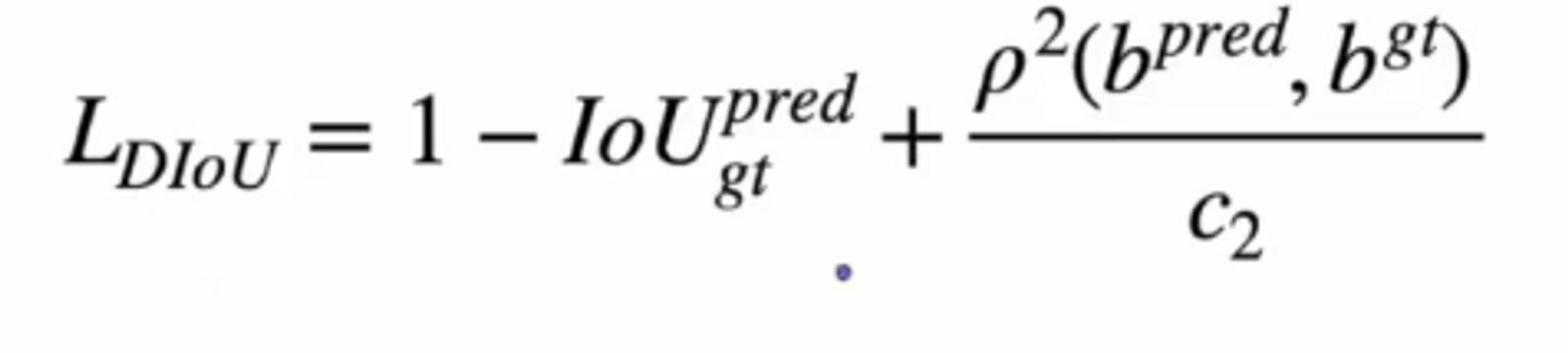
평가결과