yolov4
- YOLOv3만큼 여전히 빠르고 성능은 대폭 상승
- WRC , CSP , CmBN , Mish , Mosaic data aug. , DropBlock, CloU loss 등 적용
- GPU 하나로 학습이 가능
이 논문은 크게 두 가지 카테고리로 기술을 적용했다고 합니다.
- Bag of Freebies ( BoF ) → 추론 비용을 증가시키지 않고 학습 전략만 변경하거나 학습 비용만 증가시켜서 전체 퍼포먼스를 증가
- Data augmentation
- Regularization
- methods to solve data imbalance
- Bounduing box regrssion ( loss function )
- Bag of Special ( BoS ) → 추론 비용을 약간 증가시키지만 객체 감지의 정확도를 크게 향상
- Enhance receptive field
- Attention mechanism
- Feature integration
- Post-processing
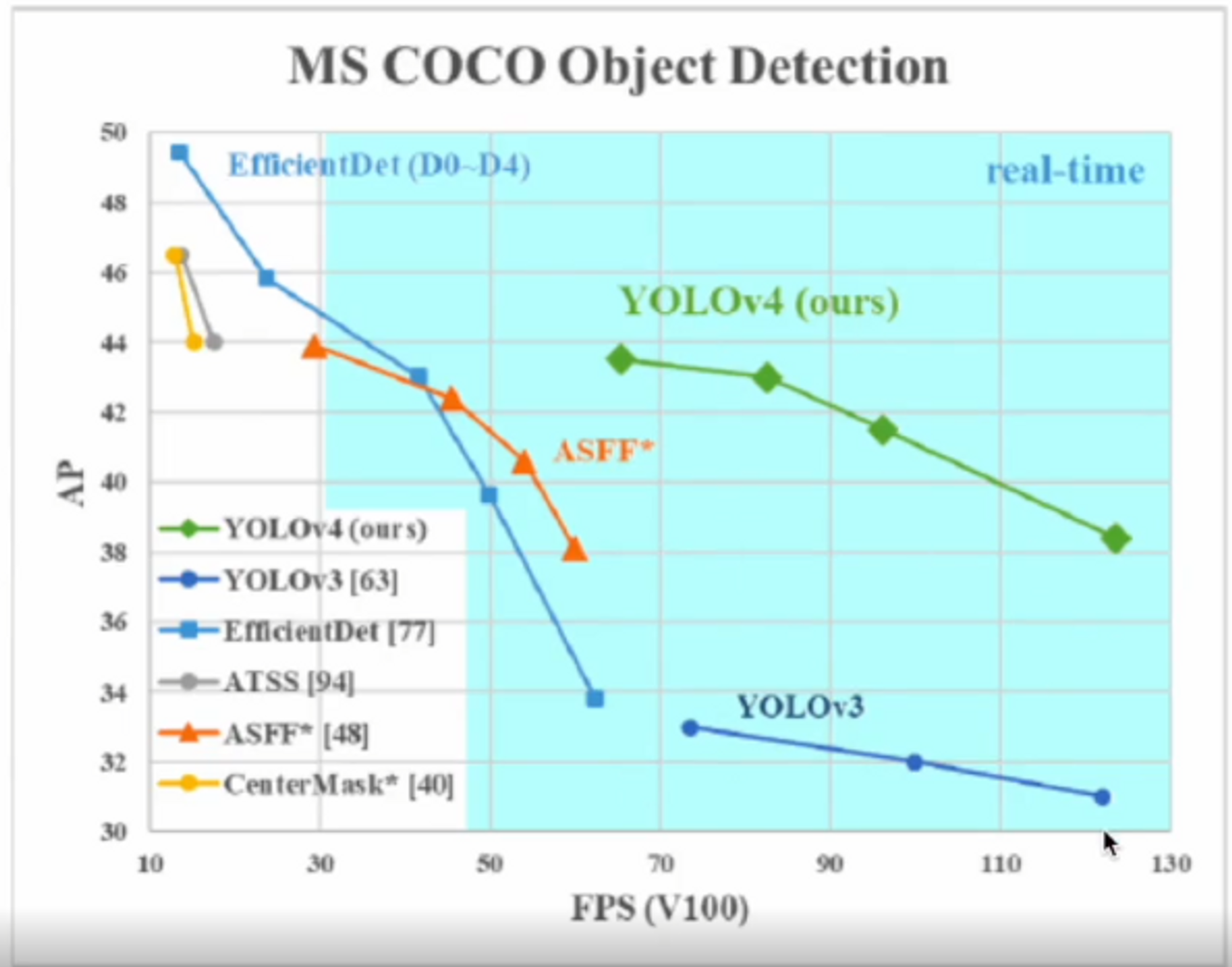
YOLOv4 는 이전 버전에 비해서 AP 성능이 확실히 좋아졌구요 Efficient 모델보다 FPS가 높으므로 속도가 더 빨라졌다는 것을 알 수 있습니다.
객체 인식 구조
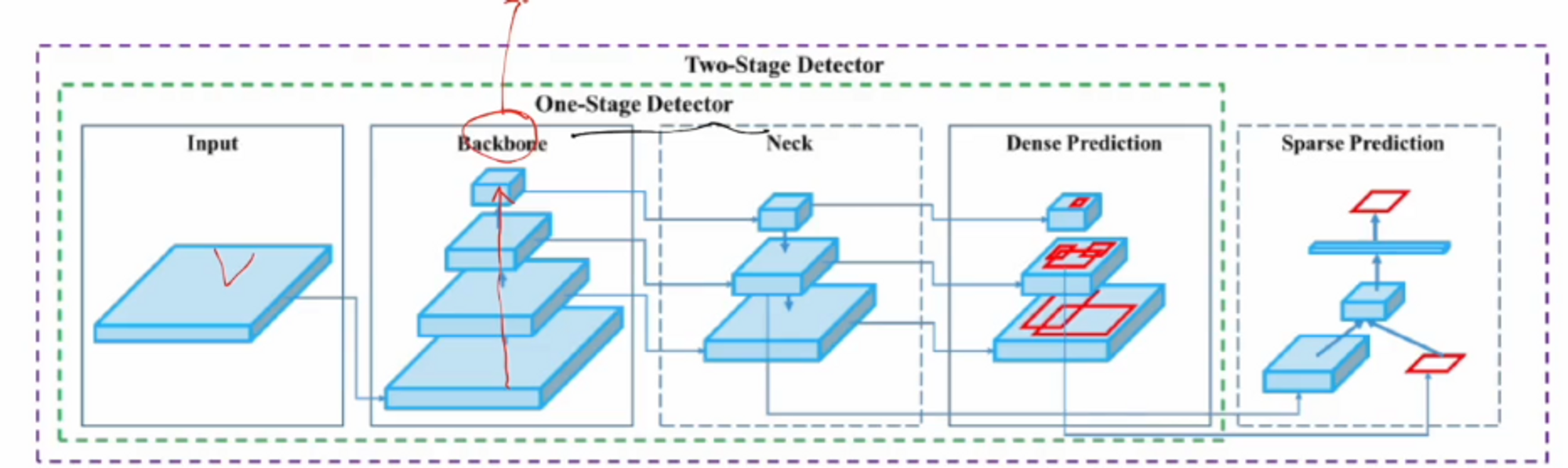
우리가 다루고 있는 YOLO 모델은 One-stage 입니다.
BackBone은 이미지 분류에서 사용하는 모델 ( Darknet, Resnet, VGG 등 )이 있다.
Neck에서는 v3에서 사용한 Feature Pyramid Network ( FPN )이 되겠습니다. 피라미드를 통해서 멀티 scale을 다뤘죠 ? 그 scale들을 통해 예측을 한 것입니다.
객체 인식 모델 (detector)이 갖춰야 할 조건
- 다중 작은 객체를 감지하기 위해서 high resolution input image
- higher receptive field 위한 더 깊은 층
- 다양한 사이즈를 처리하기 위해 더 많은 model parameters ( capacity )
YOLOv4의 핵심 주제가 model parameter는 더 키우지만 FPS는 떨어지지 않는 모델을 설계하는 것입니다.
Receptive Field
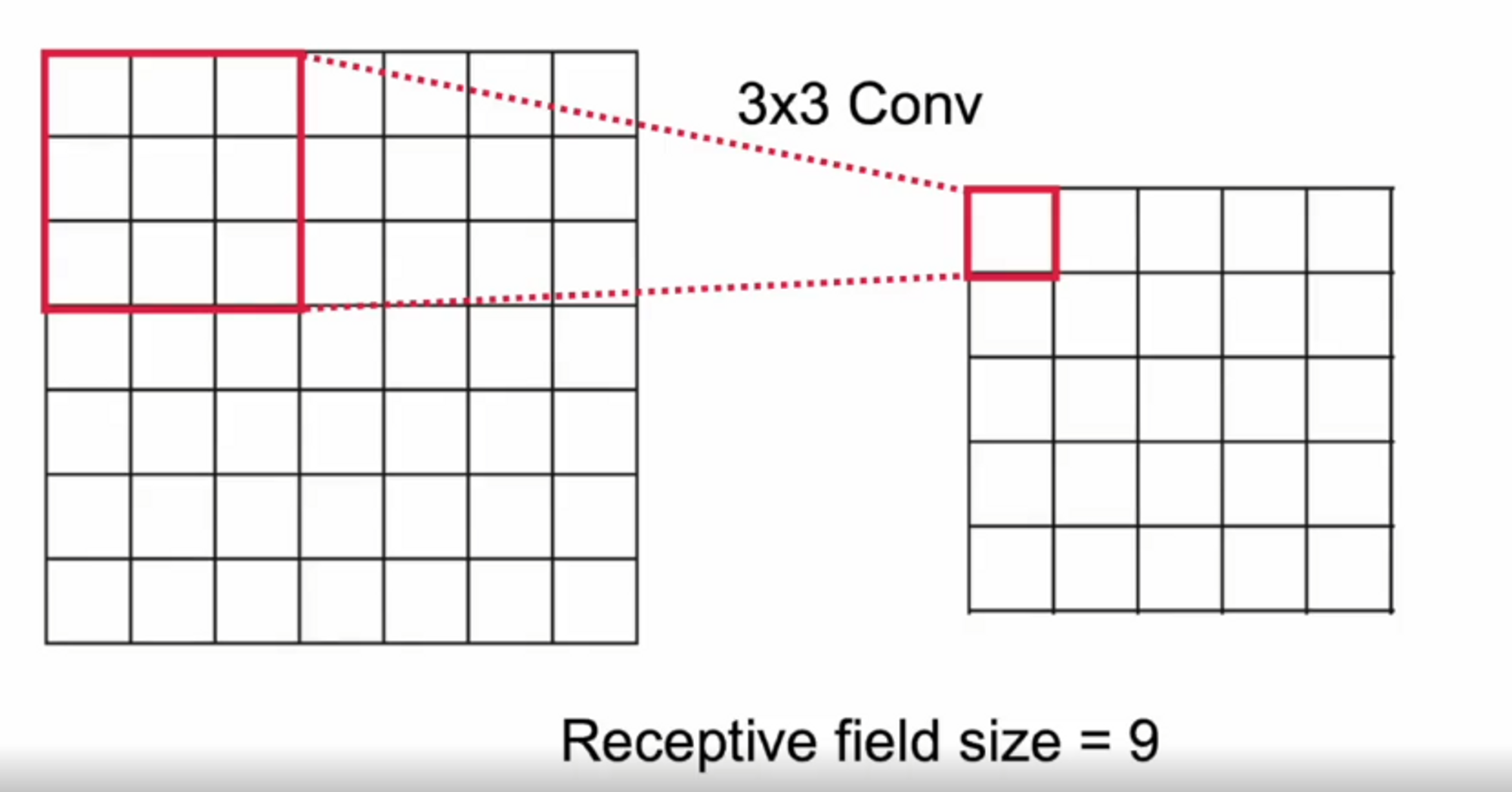
하나의 tensor에 영향을 미치는 입력 tensor들의 크기를 Receptive field라고 합니다.
우리가 원하는 feature map에서 하나의 요소에 영향을 미치는 입력 요소의 크기라고 생각하시면 됩니다. 만약에 conv layer가 1개 있을 때에는 위의 그림 처럼 Receptive field size는 9가 됩니다.
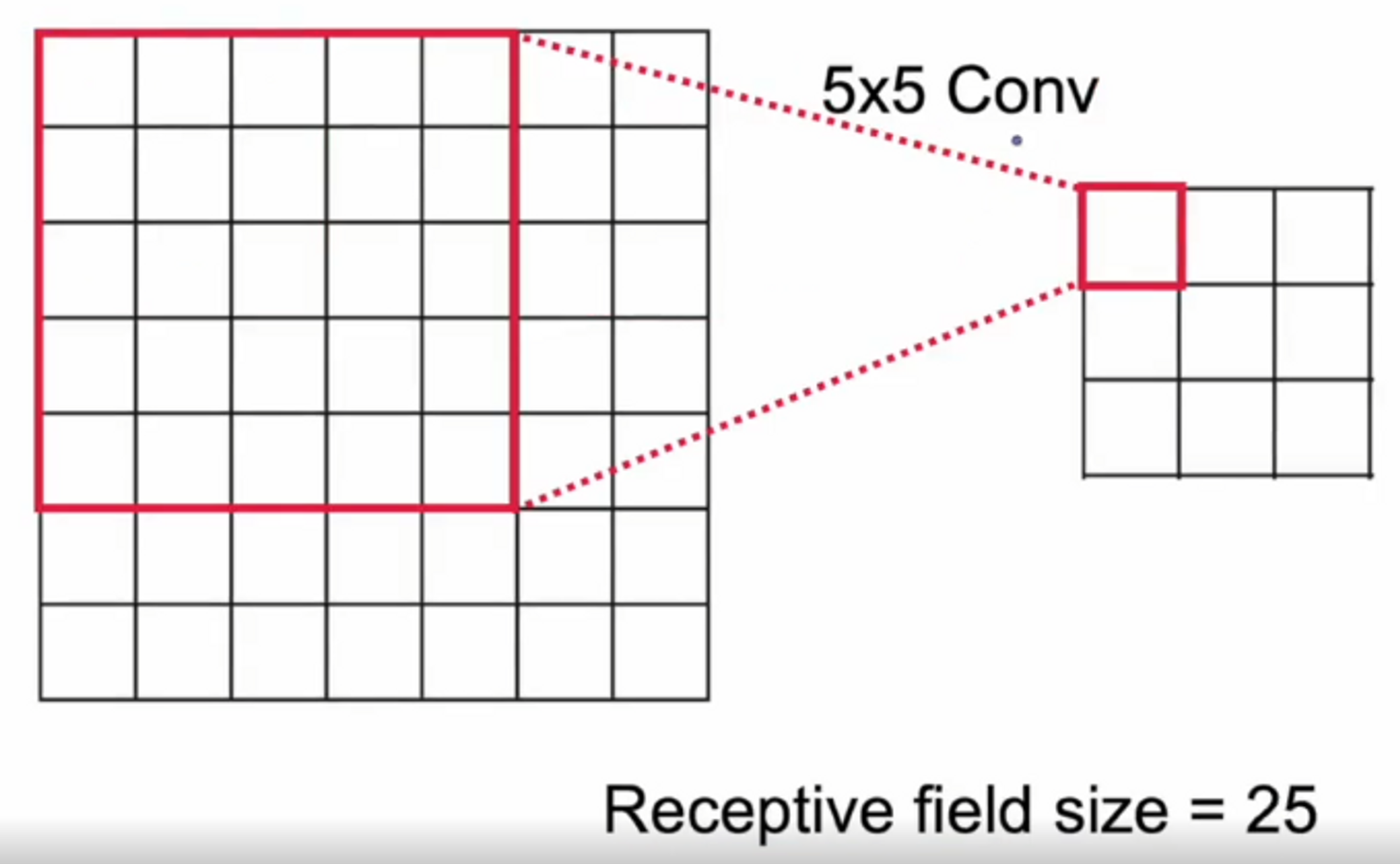
다음 그림은 5x5 conv layer를 하나 거쳤다면 다음 하나의 요소에 필요한 값은 25개가 되는 것이죠.
그럼 여기서 Receptive field size는 25가 되겠네요.
Image classification을 위한 모델 정보
- Darknet에 CSP 적용

다른 모델들이랑 비교를 한 표입니다.
CSpResNet50이라는 모델은 Input 이미지를 512 x 512 모델을 썼을 때, Receptive field size가 425 x 425 입니다.
즉 이미지 size 보다 작기 때문에 이미지 전체를 마지막 최종 출력 feature value 하나 당 전체 이미지를 사용하고 있지 않습니다. Receptive field size는 이런 식으로 해석을 하면 됩니다.
CSPDarknet53 모델은 Receptive field size가 725x725 입니다.
EfficientNet은 이 당시 최고의 이미지 분류 모델이었죠, 이 모델의 Receptive field size는 1311 x 1311 입니다.
parameter를 보면 CSPDarknet53이 가장 높습니다. capacity를 어느 정도 확보한 것이죠. parameter가 많아지면 학습속도가 느려지는데 BFLOPs( 초당처리속도 )를 보면 제일 빠릅니다. 네트워크를 잘 만들어서 모델 parameter가 많음에도 불구하고 처리 속도를 빠르게 했습니다. 실제로 FPS도 가장 높습니다.
효율적인 모델을 만들기 위해서는 이런 구조를 잘 정해야 합니다.
무조건 깊게 가자 ! 하는 시대는 이제 지났네요. 불과 4~5년만에 기술이 매우 발전했다는 것을 알 수 있죠.
CSPDarknet53 - PANet-SPP
CSPDarknet53 모델을 사용해서 이미지 분류 모델로서 ImageNet으로 훈련을 하고 객체 인식에서는
FPN을 사용하지 않고 PANet-SPP를 사용합니다 .
- [Backbone] CSP ( Cross Stage Partial connections ) 적용 - 이미지 분류에서 기본이 되는 모델을 Backbone이라고 합니다. ( Darknet )
- [Neck] SPP ( Spatial Pyramid Pooling ) 적용 - Backbone 에서 각 feature에서 Multi scale을 FPN에 넣었는데, 이 부분을 Neck이라고 합니다.
- [Neck] FPN 대신 PANet path - aggregation 적용
- [Head] YOLOv3 구조 ( abchor based )
- 다양한 최신 기술 적용
