
자연어 처리(Natural Language Processing, NLP)
컴퓨터가 인간의 언어를 이해하고 생성하도록 하는 기술
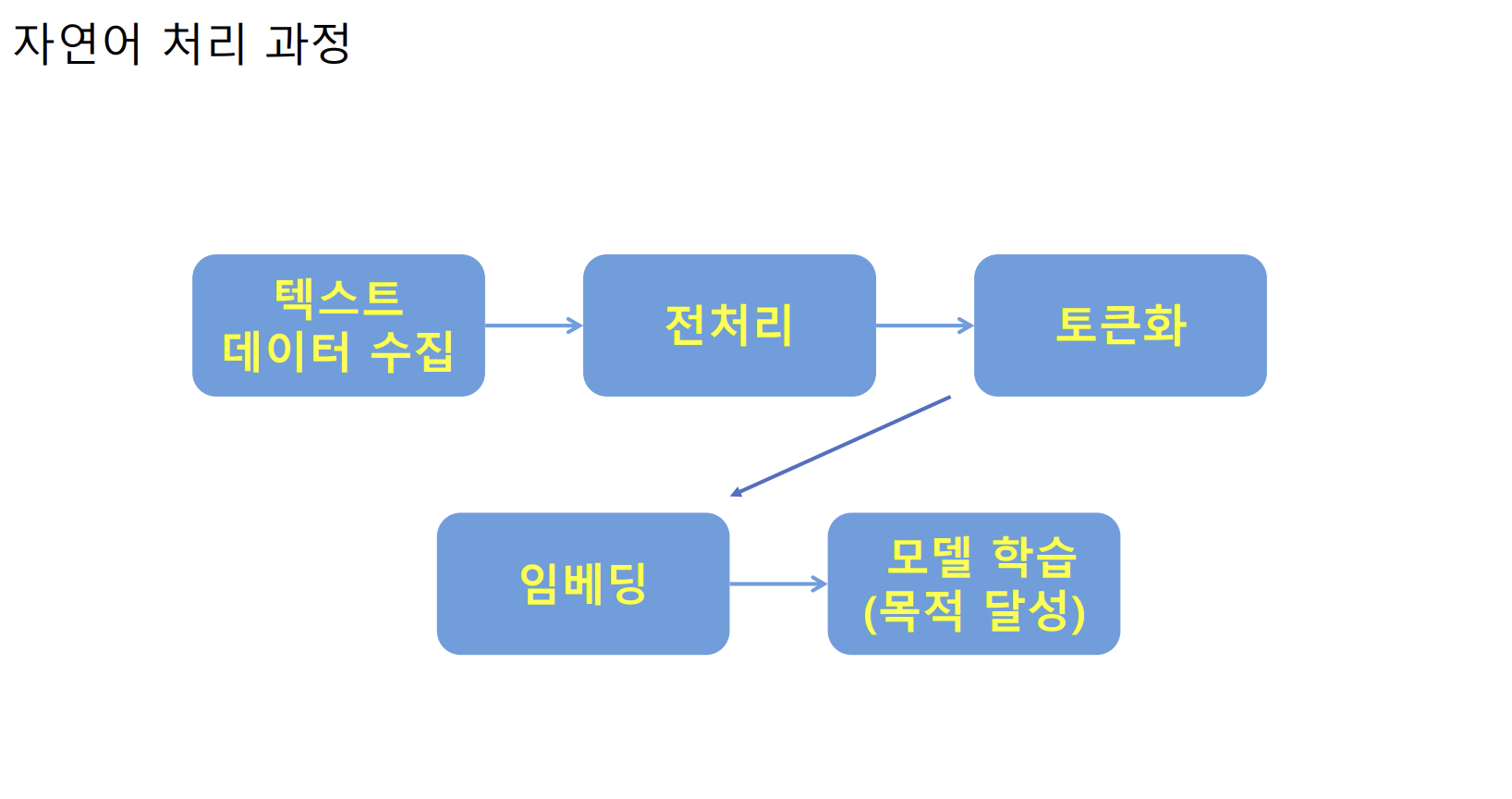
자연어 처리 과정
- 텍스트 데이터 수집
- 공공데이터(AI허브 등)
- 오픈 API를 통한 데이터 수집
- 크롤링을 이용한 Web 데이터 수집(SNS/블로그/카페 등)
- 전처리 : 텍스트 데이터에서 불필요한 데이터를 처리하는 작업
- 문장 부호 등 특수문자 제거
- 불용어(stopword) 제거 : 데이터 분석에서 큰 의미가 없는 단어 제거 (be 동사 등)
- 토큰화(tokenization) : 의미 있는 단위로 나누는 작업
- 문장 토큰화 : 문장의 끝을 나타내는 구두점 기호(.,!,?)를 기준으로 분할
- 단어 토큰화 : 띄어쓰기 기준으로 분할
- 형태소 토큰화 : 형태소 단위로 분할
- 임베딩 : 텍스트를 숫자로 표현
- 희소표현(sparse representation)
- 밀집표현(dense representation)
- 모델학습
- RNN(Recurrent Neural Network)
- LSTM(Long Short-Term Memory)
- Transformer
딥러닝 수업내용과 공식문서,GPT,블로그를 참조하여 정리한 내용을 바탕으로 작성하였습니다

AI & Robotics