텍스트 데이터 전처리
텍스트 데이터에서 불필요한 데이터를 처리하는 작업
텍스트 전처리
- 문장 부호 등 특수문자 제거
- 불용어(stopword) 제거: 빼도 말이 되는 단어 제거(be동사, 관사, 접속사, 조동사 등)
- Transformer 이후 모델들에선 문장 전체의 의미를 파악해야하기 때문에 안하는 추세
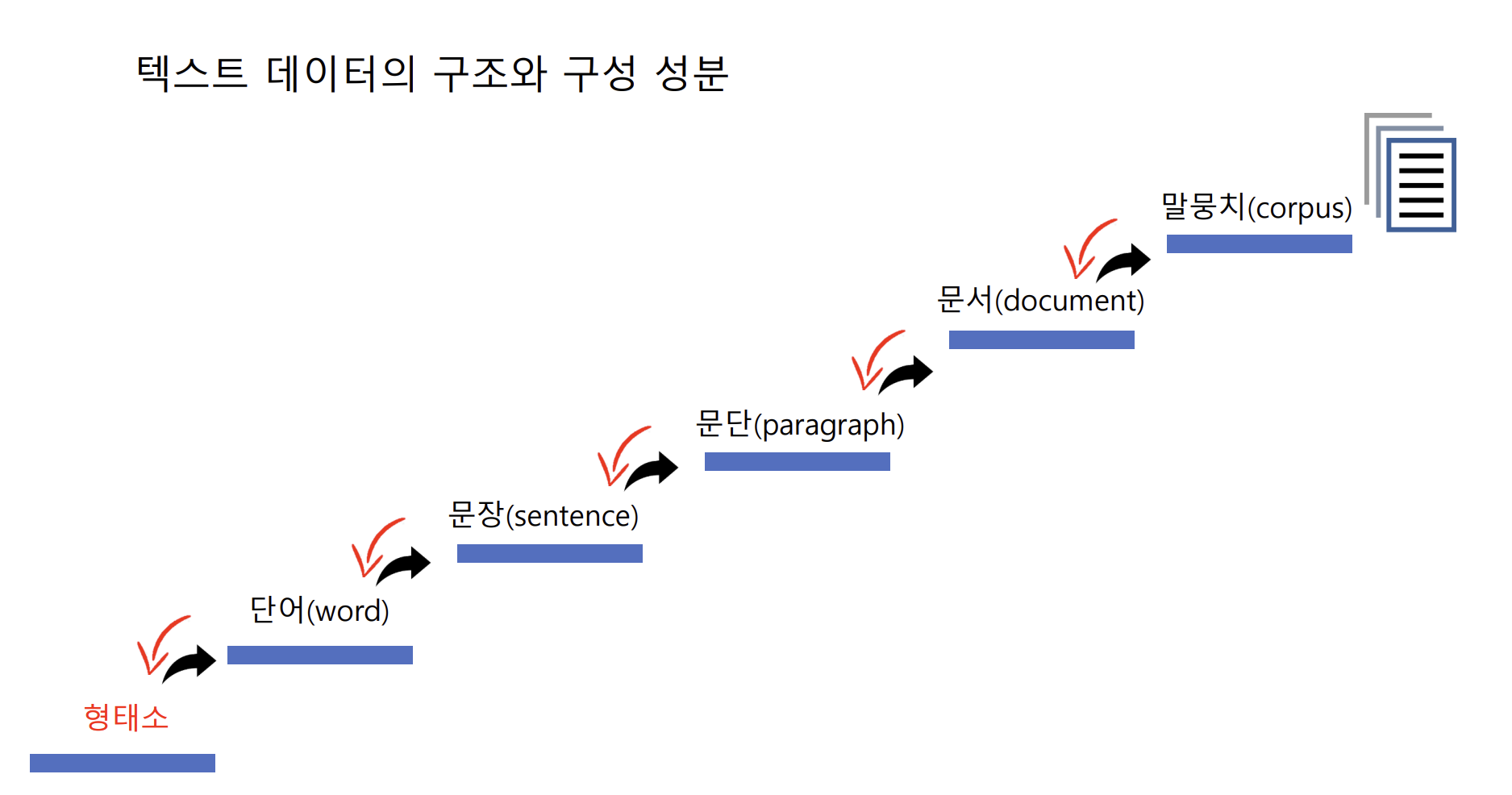
형태소
- 개념 : 뜻을 가지고 있는 말 중 가장 작은 단위, 더 나눌 수 없는 단위
- 9품사-조사를 제외하고 혼자 쓰일 수 있는 단어로 취급 (형식형태소(조사, 어미, 접사) == 불용어), 한글을 토큰화하기 위해서는 품사,단어 보다 작은 단위인 형태소 단위로 분할 해야함 > 형태소 분석기 등 활용
한국어와 영어의 불용어 차이
- 영어 : 불용어 → 단어(대명사, 관사, 접속사, 조동사 등)
- 한글 : 불용어 → 조사, 어미 등 형태소
① 꽃밭에 꽃이 많이 피었다
: 꽃밭(명사)+에(조사), 꽃(명사)+이(조사), 많이(부사), 피었다(동사)
② 용언의 경우 1단어가 어간 + 어미의 형태로 2개 이상의 형태소로 구성되는 경우가 많음
: 피었다 → 피 (어간)/었 (어미)/다 (어미)

AI & Robotics