SimpleRNN을 활용하여 IMDB 영화 리뷰 감성 분석 (긍정 부정 분류)
- 개요
- 데이터 : 50,000개의 영화 리뷰와 감성(sentiment, 긍정/부정)으로 구성된 IMDB
- 데이터 → 학습용 데이터 25,000개 + 평가용 데이터 25,000개
- 목표 : review의 문장(단어 sequence)을 기반으로 review의 sentiment를 예측하는 RNN 모델 생성, 학습, 평가 진행
데이터의 흐름
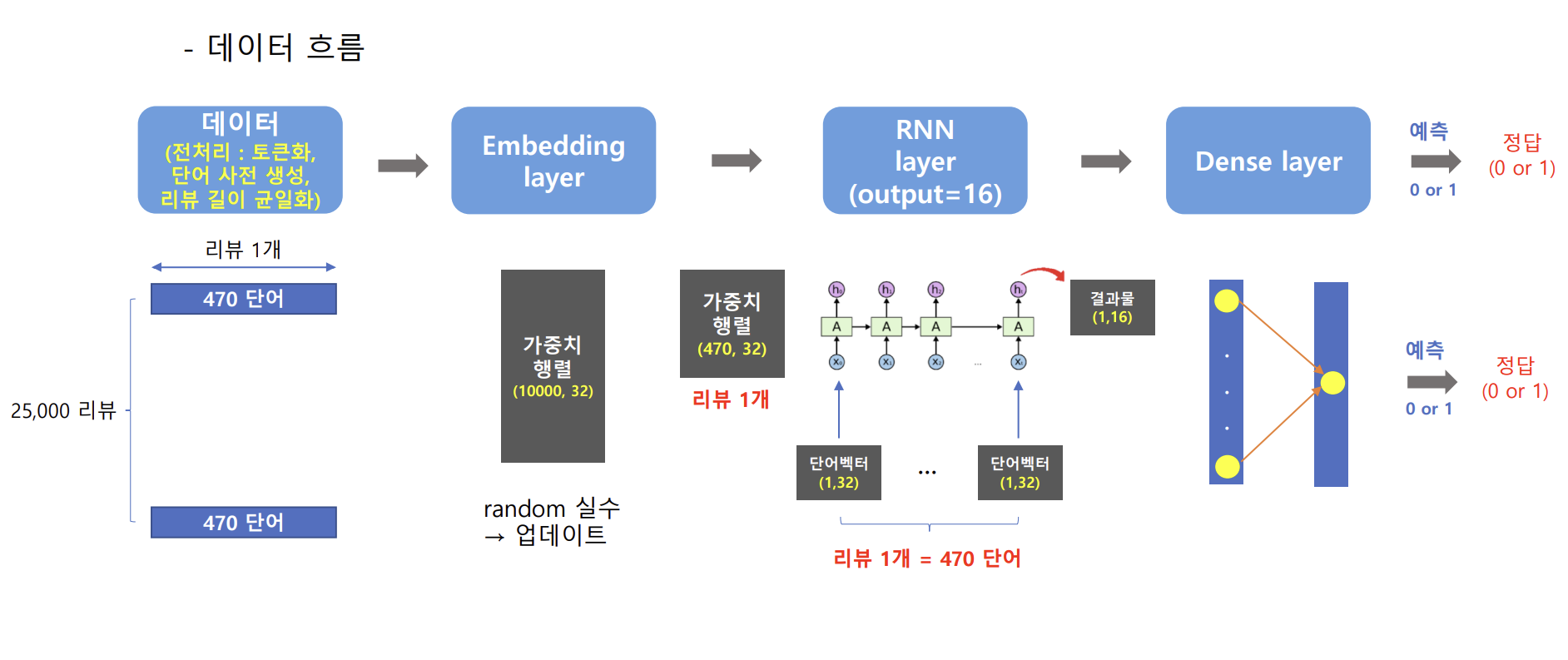
모델 생성
- model = Embedding layer(입력층) + RNN layer(은닉층) + Dense layer(출력층)
- Sequential() 함수 : 여러 개의 계층(layer)을 순차적으로 쌓을 수 있는 빈 껍질(컨테이너) 생성
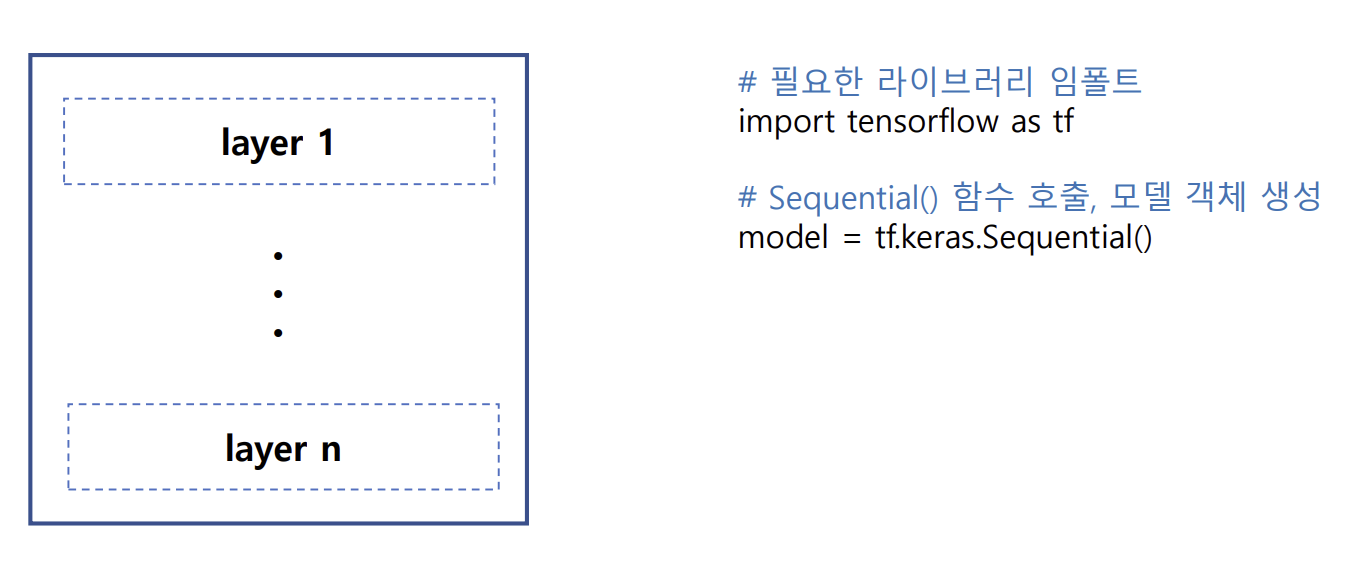
- add() 함수를 이용하여 레이어 추가 → model.add(매개변수 = layer)

Embedding layer
- 입력 : 입력 데이터의 단어 별 정수 인덱스 배열
- 출력 : 단어 임베딩 행렬
- 실행 코드 : tf.keras.layers.Embedding(input_dim, output_dim, input_length, embeddings_initializer)
- 주요 매개 변수:
① input_dim : 가중치 행렬의 행의 수, 단어 사전의 크기
② output_dim : 가중치 행렬의 열의 수, 임베딩 벡터의 크기
③ input_length : 입력 데이터의 길이
④ embeddings_initializer : 입력 데이터에 대한 가중치 행렬 초기화 방법 (예: 'uniform', 'normal’)
+ seed가 none일 경우 가중치를 랜덤하게 하기 때문에 모델이 반복 학습할 때 일관된 결과를 얻지 못함
RNN layer
- 입력 : 단어 임베딩 행렬
- 출력 : 문장 임베딩 행렬
- 실행 코드 : tf.keras.layers.SimpleRNN(units, kernel_initializer, recurrent_initializer)
- 주요 매개 변수:
① units : 문장 임베딩 행렬의 크기(size)
② kernel_initializer : 현재 시점의 단어 임베딩 행렬에 대한 가중치 행렬의 초기화 방법 (glorot_uniform, 기본값 seed = none)
③ recurrent_initializer : 이전 시점의 정보(단어 처리 결과)에 대한 가중치 행렬의 초기화 방법 (orthogonal, 기본값 seed = none)
Dense layer
- 완전 연결 계층(fc layer)을 생성하는 함수
- 결과 값을 출력하는 위치(출력층)에서 사용, 신경 세포(뉴런)의 기능 구현
- 입력 : 문장 임베딩 행렬
- 출력 : 분류 또는 회귀의 결과
- 실행 코드 : tf.keras.layers.Dense(units, activation, kernel_initializer)
- 주요 매개 변수:
① units : 출력 뉴런의 수
② activation : 출력 유형에 따른 활성화 함수
③ kernel_initializer : 가중치 행렬의 초기화 방법
+ 보충: 완전 연결 계층(fc, fully connected layer)
- 결과 값을 출력하는 위치(출력층)에서 사용
- 신경 세포(뉴런)의 기능 구현
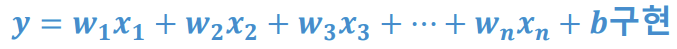
- 입력 값과 출력 값이 100% 연결 된 상태 → 완전 연결 계층(fc, fully connected layer)
(이 시리즈의 모든 코드는 코랩환경에서 Python으로 작성하였습니다)
IMDb 영화 리뷰 감성 분석 Code 1 (라이브러리 임폴트 및 데이터 다운로드)
# 라이브러리 임폴트
import tensorflow as tf
import numpy as np- 코랩 tensorflow 버전 2.17.0
# 텍스트 데이터 다운로드
(x_train,y_train),(x_test,y_test) = tf.keras.datasets.imdb.load_data()- tf.keras.datasets.imdb.load_data
- 25000개의 영화 리뷰에 대해 토큰화 및 단어사전을 제작해서 딕셔너리 형태로 제공함
- num_words - none일 경우 모든 단어(약 8만 단어)를 사용함
- only consider the top 10,000 most common words, but eliminate the top 20 most common words
- oov_char - 몇번 이상 나온 단어만 입력받음
- return
- Tuple of Numpy arrays: (x_train, y_train), (x_test, y_test)
# 단어 사전 다운로드
vocab = tf.keras.datasets.imdb.get_word_index()
vocab = sorted(vocab.items(), key = lambda item: item[1])
print(vocab)
print(len(vocab))- tf.keras.datasets.imdb.get_word_index() : 단어사전 출력
- sorted(dict_name.items(), key = lambda item: item[1])
- dict_name을 오름차순으로 정렬
#데이터 분석
print(x_train[0])
print('-'*80)
print(y_train[:20])IMDb 영화 리뷰 감성 분석 Code 2 (데이터 전처리)
# 리뷰별 단어의 수 분석 > train x data > 단어 수 추출
text_length = []
for i in x_train:
text_length.append(len(i))
print(text_length)# 단어 수 통계 분석
stats = np.percentile(a=text_length,q=[75, 90, 99])
print(stats)- 입력받을 데이터의 범위 : 75%, 90%, 99% 중 하나
- np.percentile(a=text_length,q=[75, 90, 99])
- 배열 a에서 주어진 백분위수 q에 해당하는 값을 계산
- 백분위수는 데이터를 100개의 동일한 부분으로 나눈 지점
# 데이터 전처리 > 리뷰의 길이 최적화
max_len = 470
x_train_pad = tf.keras.utils.pad_sequences(x_train, maxlen=max_len)
x_test_pad = tf.keras.utils.pad_sequences(x_test, maxlen=max_len)
x_train_pad.shape, x_test_pad.shape- tf.keras.utils.pad_sequences
- sequences - 바꿀 리스트 변수명
- maxlen - 최대길이
- padding - 붙이기(기본값 : pre), pre > 앞부분, post > 뒷부분
- truncating - 자르기(기본값 : pre), pre > 앞부분, post > 뒷부분
- value - padding되는 값(기본값 : 0)
- Returns
- NumPy array with shape (len(sequences), maxlen)
IMDb 영화 리뷰 감성 분석 Code 3 (RNN 모델 생성)
- RNN
- RNN등 모델들은 여러 layer가 모인 복합 모델
- model.add을 활용하여 layer 추가
# embedding layer
vocab_size = len(vocab) + 3 #단어 사전의 길이
embedding_size = 32 #임베딩 벡터의 크기
# 가중치 행렬 초기화 값 설정
i = tf.keras.initializers.GlorotUniform(
seed = 0
)
# embedding layer 클래스 함수 호출 > (단어사전의 단어수, 임베딩 벡터의 크기) 모양의 가중치 행렬 생성
# seed = none이기 때문에 랜덤한 숫자의 가중치 생성
embedding = tf.keras.layers.Embedding(
input_dim = vocab_size,
output_dim = embedding_size,
embeddings_initializer = i,
)
input = x_train_pad #입력 데이터 생성
output_embedding = embedding(input) #입력의 결과 확인
print(output_embedding.shape)
print(output_embedding[0])- 가중치 행렬 seed 설정
- i = tf.keras.initializers.GlorotUniform(seed = 1)
- seed = none일 경우 첫 가중치 행렬이 랜덤하게 설정되어 학습을 초기화 할 때마다 값이 달라짐
# RNN layer
# RNN 생성 함수 호출, 모델 생성
rnn = tf.keras.layers.SimpleRNN(
units = 16,
kernel_initializer = i,
recurrent_initializer = 'orthogonal'
)
output_rnn = rnn(output_embedding)
print(output_rnn.shape)
print(output_rnn[0])# Dense layer
# Dense 생성 함수 호출, 모델 생성
dense = tf.keras.layers.Dense(
units = 1,
activation = 'sigmoid',
kernel_initializer = i
)
output_dense = dense(output_rnn)
#print(output_dense)
#입력 결과물 > 정답 레이블(0 & 1)로 변환
labels = []
for i in output_dense:
if i > 0.5:
labels.append(1)
else:
labels.append(0)
print(labels)- Dense layer
- 값이 둘중 하나만 출력된다(0 & 1) == 이진 분류 (binary classification)
- 값이 여러개로 나온다 (0~1 사이의 값) = 다중 분류
- Sigmoid 함수
- x == 입력의 총합
- Sigmoid 함수의 결과는 0 & 1로 나오기 때문에 이진분류의 적합함
Embedding Layer 단어 사전의 길이 : len() + 3에서 +3의 의미(special token)
- padding token (PAD)
- 모든 입력 시퀀스를 동일한 길이로 맞추기 위해 사용
- 입력되는 문장은 길이가 다양한데, 시퀀스들을 한 번에 처리하기 위해, (PAD) 토큰으로 채워져 길이를 맞춤
- 0값을 임베딩 하기 위함
- stat of sentence token (SOS &BOS)
- 시퀀스의 시작을 나타내기 위해 사용
- 모델이 시퀀스를 생성하거나 처리할 때, 이 토큰을 통해 시퀀스의 시작을 인식하고, 그에 맞게 상태를 초기화함
- 문장을 번역할 때, 모델이 (SOS) 토큰을 만나면 문장이 시작된다고 인식하고, 다음 단어를 예측함
- unknown token (UNK)
- 사전에 없는(모르는) 단어를 처리하기 위해 사용
- 훈련되지 않은 단어 또는 테스트 데이터에서 처음 마주치는 단어들은 임베딩 벡터가 없기 때문에, 이 단어들은 (UNK) 토큰으로 대체하여 처리함
참고자료
python dictionary 정렬 메소드 (블로그)
tf.keras.datasets.imdb.load_data 공식문서
tf.keras.layers.embedding 공식문서
tf.keras.initializers.GlorotUniform 공식문서
tf.keras.layers.SimpleRNN 공식문서

AI & Robotics