Transformer
- 순환 신경망의 한계
- 문장의 길이가 길수록 모든 정보를 하나의 백터에 포함하기에 부족(앞부분 단어 정보 손실)
- 입력 시퀀스의 순서에 따라 순차적으로 연산을 수행하기 때문에 병렬 처리가 어려움. 이는 RNN의 학습과 추론 속도를 느리게 하고, 대규모 데이터와 모델을 다루기 어렵게 만듦
- 2017년 구글이 발표한 논문 (Attention is all you need)
- 순환 신경망의 한계를 극복하기 위해 제안된 모델
- RNN을 사용하지 않고, 어텐션(attention) 알고리즘을 통해 시퀀스 데이터를 처리하는 모델
- Transformer 모델의 구조 : 인코더(encoder) + 디코더(decoder)
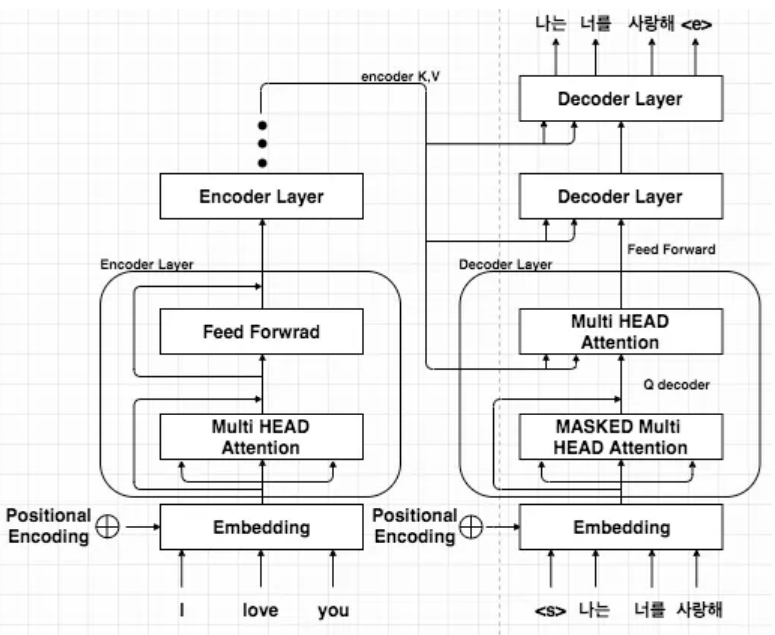
self-attention
- 입력 문장의 각 단어가 다른 단어들과 얼마나 관련이 있는지를 계산하고, 그 결과를 가중합하여 문장 전체의 문맥을 반영하는 contextual embedding vector를 생성하는 알고리즘
과정 1
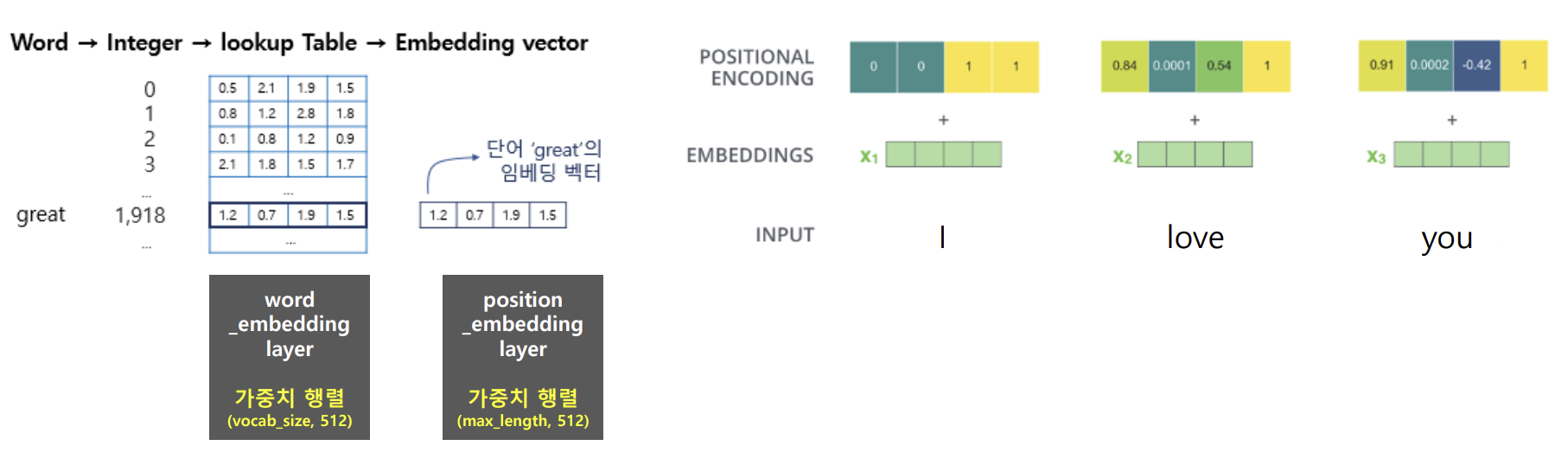
- 입력 문장 → 토큰화(WordPiece tokenizer, 정수 인코딩) + 단어 임베딩 + positional encoding
- 토큰화
- Word토큰화 > 단어사전 생성 (Special token 포함되어있음) > 정수 인코딩
- 단어 임베딩
- lookup Table (word_embedding layer)생성
- 가중치 행렬 사이즈(vocab_size, 512) 고정
- positional encoding
- 단어의 임베딩 벡터 > position_embedding layer 통과
- layer에서 각 단어의 상대적 위치 정보를 담고있는 새로운 배열과 더해짐 > 새로운 임베딩 행렬 생성
- 여기서의 가중치 행렬(max_length, 512)로 고정
- 단어를 순차적으로 처리하지않고 입력된 모든 단어를 병렬로 처리함
과정 2
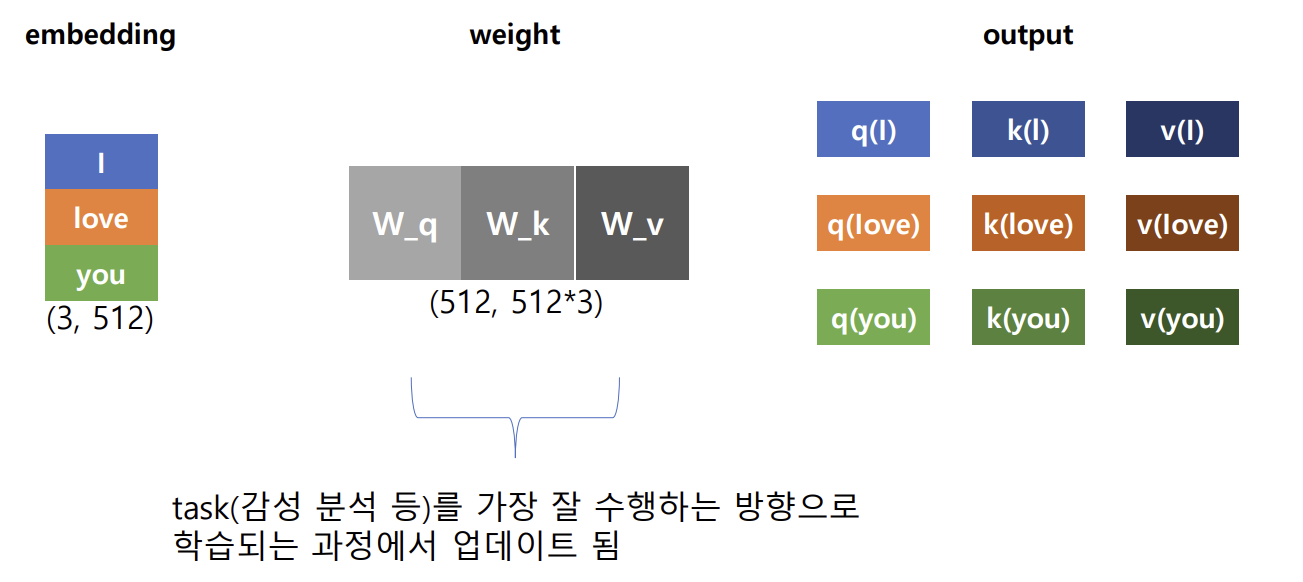
- 각 단어 임베딩 벡터 → 쿼리(Query), 키(Key), 값(Value) 벡터 생성
- 쿼리(Query), 키(Key), 값(Value) 벡터 간의 연산을 통해서 문맥적 관계성을 추출하는 과정
- 세 가지 벡터는 입력 단어 벡터를 선형 변환(가중치 행렬 곱)하여 얻어짐
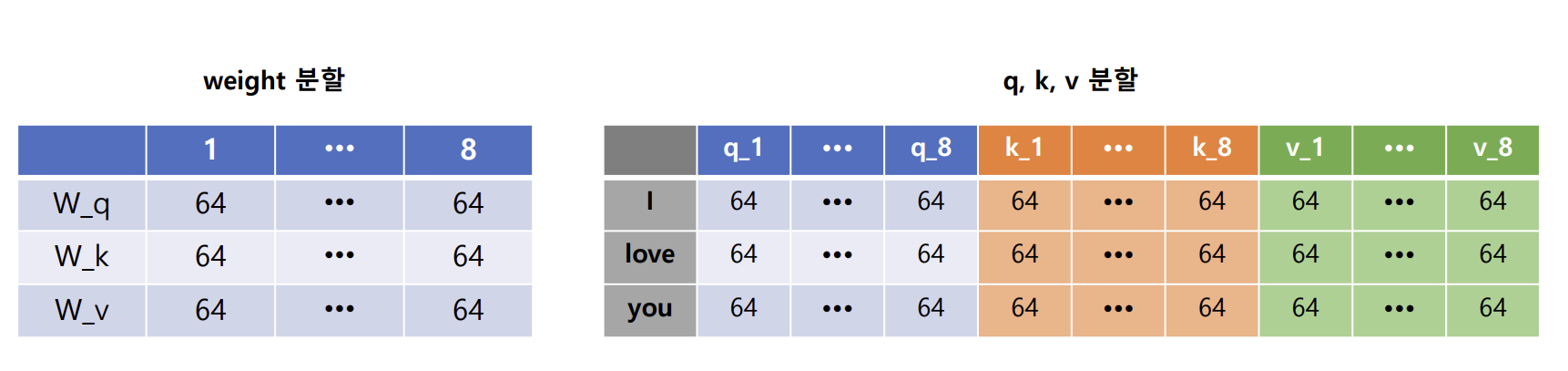
- 각 Q,K,V에 맞는 3개의 가중치를 담고 있는 데이터(512, 512*3)를 생성하고 추출하여 사용함
- 쿼리(Query), 키(Key), 값(Value)의 역할
1) Query : 문장 내 다른 단어들과 어떤 관계를 가지는지를 파악하고자 하는 특정 단어의 벡터 => 현재 단어가 다른 단어에 얼마나 주목해야 하는지
2) Key : Query가 문장 어떤 단어와 유사도가 큰 지를 계산하는 데 사용되는 단어 벡터(입력 문장의 전체 단어 벡터) => 다른 단어들이 얼마나 중요한지
3) Value : 가중치를 적용하여 최종 출력을 생성하는 데 사용되는 단어 벡터(입력 문장의 전체 단어 벡터) => 실제로 전달할 정보
과정 3
Scaled Dot-Product Attention
- attention score: Query 벡터와 Key 벡터의 내적을 통해 각 단어 간의 유사도 점수를 계산
- 각 단어의 Query 벡터와 모든 단어의 Key 벡터 간의 유사도를 계산함. 현재 단어가 다른 단어들에 얼마나 집중해야 하는지를 결정
- 유사도는 일반적으로 내적(dot product)을 통해 계산되며, 결과는 하나의 숫자로 나타남
- scaling: attention score 값 / Key 벡터의 차원 크기의 제곱근 → attention score 값의 크기를 조정
- attention weight
- 스케일링을 거친 attention score를 softmax 함수에 입력
- 각 Query와 Key 간의 유사도는 Softmax 함수를 통해 확률 값으로 변환됨 =>
입력 문장의 각 단어가 다른 단어들과 얼마나 관련이 있는지를 0과 1사이의 숫자로 표현- 이를 통해 각 단어에 얼마나 집중할지를 나타내는 가중치를 얻음
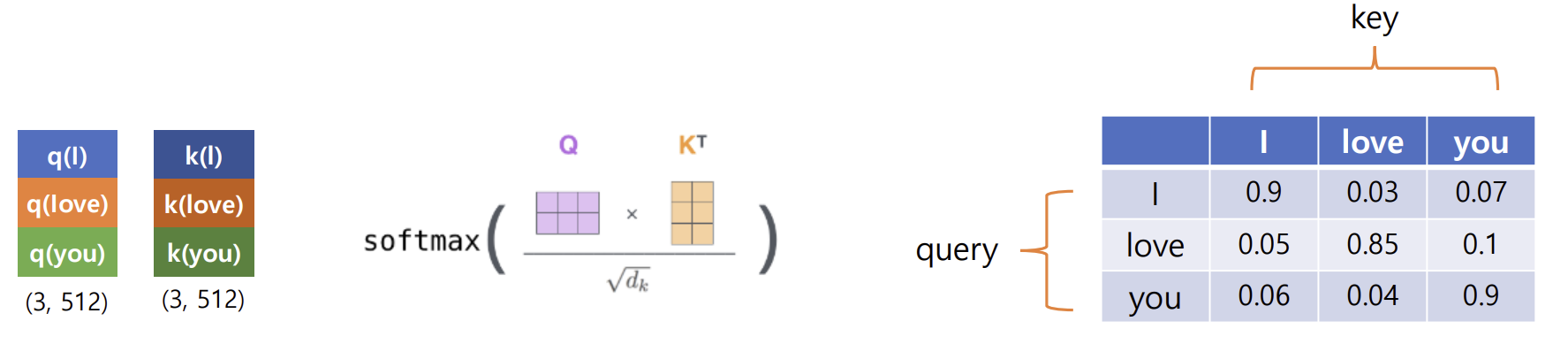
- 어텐션 출력(attention output) 벡터 생성
- 어텐션 가중치(attention weight)와 Value 벡터의 가중합 계산
- 문장을 구성하고 있는 각 단어 간의 관계를 반영한 새로운 단어 임베딩 벡터 생성
- 이 가중치가 적용된 Value 벡터들을 모두 더해 최종 출력 벡터를 만듬


- 어텐션 출력(attention output) 벡터 생성 예시

- 즉, transformer의 최종 출력값은 모든 문맥을 관련성에 따라 반영한다
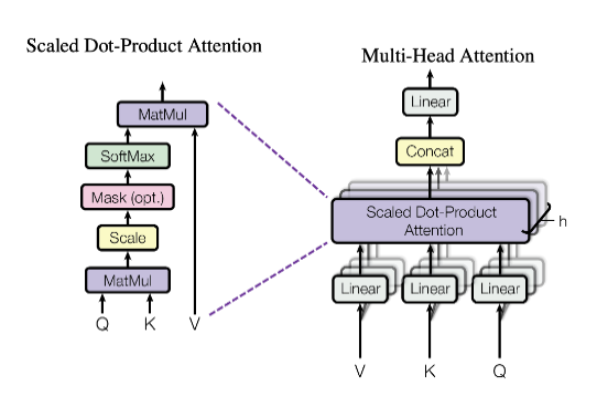
+ Multi-Head Attention
- self attention을 병렬로 수행
- 입력 문장의 다양한 측면을 병렬로 학습 → 속도 및 성능 향상
- 최종 결과(새로운 단어 임베딩 벡터) → concat
- 최종 출력
- 이 과정에서 각 단어는 다른 모든 단어들과의 관계를 반영한 새로운 벡터로 변환됨
- 이 벡터는 문맥 정보를 풍부하게 포함하게 되어, 다음 층에서 더 복잡한 패턴을 학습할 수 있음
여기서 각 Head는 독립적으로 Self-Attention을 수행하고, 출력들은 연결되어 다시 선형 변환이 적용됨
- Self-Attention의 장점
- 병렬 처리 가능
- 기존 순차적 모델과 달리, 모든 단어에 대해 동시에 계산할 수 있어 병렬 처리가 가능함
- 긴 의존 관계 처리
- 문장의 모든 단어가 서로 참조할 수 있어, 멀리 떨어진 단어들 간의 관계를 잘 학습함. 순차적으로 처리할 때 생기는 기억 상실 문제(기울기 소실)을 해결할 수 있음
- 유연함
- 특정 단어가 어떤 문맥에서 중요한지를 상황에 맞게 동적으로 학습함

(이 시리즈의 모든 코드는 코랩환경에서 Python으로 작성하였습니다)
transformer Code 1 (self-attention)
# 라이브러리 임폴트
import tensorflow as tf- tf.Tensor
- 넘파이와 배열과 모양은 비슷하지만 Tensor의 고유 자료형임
- 넘파이는 RAM(그래픽 카드)에서 연산이 불가능함
# 단어 임베딩 행렬 생성
'''
실습용 데이터 생성
1. sentence = "I love you"
2. 토큰화 --> [I, love, you]
3. 각 토큰 --> 512 차원의 임베딩 벡터로 변환 --> (3, 512) 임베딩 행렬 생성
4. 표준 정규 분포로부터 랜덤한 실수 샘플링 --> (3, 512) 임베딩 행렬에 해당하는 데이터 생성
'''
# (3,512) 임베딩 행렬에 해당하는 데이터 생성
embedding_shape = (3, 512)
embedding_matrix = tf.random.normal(shape = embedding_shape)
print(embedding_matrix)
- tf.random.normal : 표준정규분포 모양으로 랜덤하게 숫자를 뽑는 함수 (keras 함수아님) => 넘파이와 모양은 비슷하지만 Tensor의 고유 자료형임
- shape: 랜덤하게 출력할 숫자의 개수
- mean: 중심 결정 (기본값 : 0.0)
- stddev: 범위 설정 (기본값 : 1.0)
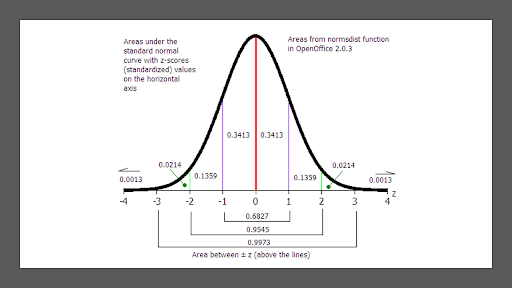
+ 표준정규분포
- 100개의 데이터에서 무작위로 뽑았을때 -2~2사이의 값일 확률 0.9545임
# 가중치 행렬 생성 Wq, Wk, Wv
'''
1. 가중치 행렬 W_q, W_k, W_v의 모양 : (512, 512)
2. 가중치 행렬의 초기 값 --> 랜덤한 실수로 설정
3. 표준 정규 분포로부터 랜덤한 실수 샘플링 --> (512, 512) 가중치 행렬에 해당하는 데이터 W_q, W_k, W_v 생성
'''
#(512, 512)모양의 가중치 행렬에 해당하는 데이터 3개 생성
weight_shape = (512, 512*3)
W = tf.random.normal(shape = weight_shape)
W_q = W[:, :512]
W_k = W[:, 512:512*2]
W_v = W[:, 512*2:]
print(W_q)
print(W_k)
print(W_v)# 전체 단어의 임베딩 행렬과 가중치 행렬의 행렬 곱 --> 각 단어별 q, k, v 행령 생성
# 전체 단어의 임베딩 행렬과 가중치 행렬의 행렬 곱
qkv = tf.linalg.matmul(a=embedding_matrix, b=W)
# 각 단어의 q, k, v 행렬 추출
q = qkv[:, :512]
k = qkv[:, 512:1024]
v = qkv[:, 1024:]
# 결과 확인하기
print(qkv)
print('-'*80)
print(q)
print('-'*80)
print(k)
print('-'*80)
print(v)transformer Code 2 (scaled dot-product attention)
# attention score
attention_score = tf.linalg.matmul(a=q, b=k, transpose_b=True)
print(f'attention_score : \n{attention_score}')# scaling
dk = 512
dk = tf.cast(dk, dtype=tf.float32)
scaled_attention_score = attention_score/tf.math.sqrt(dk)
print(f'scaled_attention_score : \n{scaled_attention_score}')# attention weight
attention_weight = tf.nn.softmax(scaled_attention_score)
print(f'attention_weight : \n{attention_weight}')# attention output : contextual embedding vector
output = tf.linalg.matmul(a=attention_weight, b=v)
print(f'output : \n{output}')참고자료
transformer : self-attention CODE (llama3 modle)
# llama3 modle - transformer : self-attention CODE
xq = xq.transpose(1, 2) # (bs, n_local_heads, seqlen, head_dim)
keys = keys.transpose(1, 2) # (bs, n_local_heads, cache_len + seqlen, head_dim)
values = values.transpose(
1, 2
) # (bs, n_local_heads, cache_len + seqlen, head_dim)
scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)
if mask is not None:
scores = scores + mask # (bs, n_local_heads, seqlen, cache_len + seqlen)
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
output = torch.matmul(scores, values) # (bs, n_local_heads, seqlen, head_dim)
output = output.transpose(1, 2).contiguous().view(bsz, seqlen, -1)
return self.wo(output)
AI & Robotics