[NLP 17] BERT(Bidirectional Encoder Representations from Transformers) 1 : masked language model
Natural Language Processing
목록 보기
17/22
GPT(Generative Pre-Training)
- 2018년에 OpenAI가 공개한 언어 모델
- 언어 모델 : 이전 단어들이 주어졌을 때 다음 단어로 어떤 단어가 적합한지 맞히는 과정에서 학습되는 모델
ex) “비행기를 타기 위해 □□□”- GPT1 : 1억1천7백만개의 가중치, GPT2 : 15억4천2백만 개의 가중치로 구성
- 문장 생성에 강점을 가진 모델
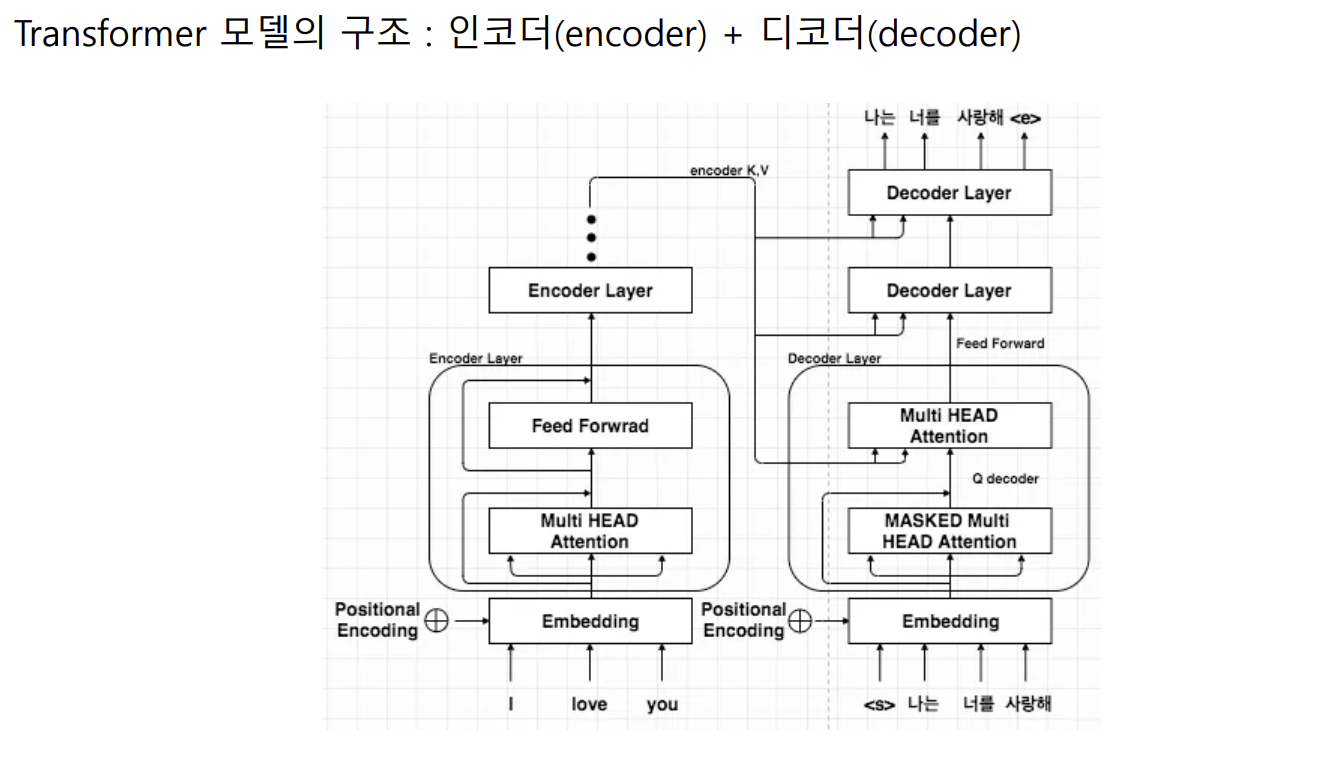
- Transformer의 디코더만 사용 => 문장 생성에 강점을 가진 모델
BERT(Bidirectional Encoder Representations from Transformers)
- 2018년에 구글이 공개한 MASK 언어 모델
- MASK 언어 모델 : 문장 내 특정 위치에 빈칸을 만들고 해당 빈칸에 적합한 단어가 무엇일지 분류하는 과정에서 학습되는 모델
ex) “비행기를 타기 위해 공항을 가는데 [MASK] 너무 막혀서 결국 비행기를 놓쳤다.”
- 사람의 경우, 수많은 단어와 문장을 듣고 쓰고 말하며 언어능력을 학습했기 때문에, 확률적으로 ‘차가'라는 단어가 가장 적합하다고 판단할 수 있음
- 인공 지능 : 매우 큰 모델에 많은 양의 데이터를 학습
- 1억1천만 ~ 3억4천5백만 개의 가중치로 구성, 총 33억 단어를 학습시킨 모델
- MASK 토큰 앞뒤 문맥을 모두 참고하는 양방향 언어 모델
- 문장의 의미를 추출하는데 강점을 가진 모델
- Transformer의 인코더만 사용 => 문장의 의미를 추출하는데 강점을 가진 모델
마스크 언어 모델(masked language model) 방식의 학습
동작 과정 1
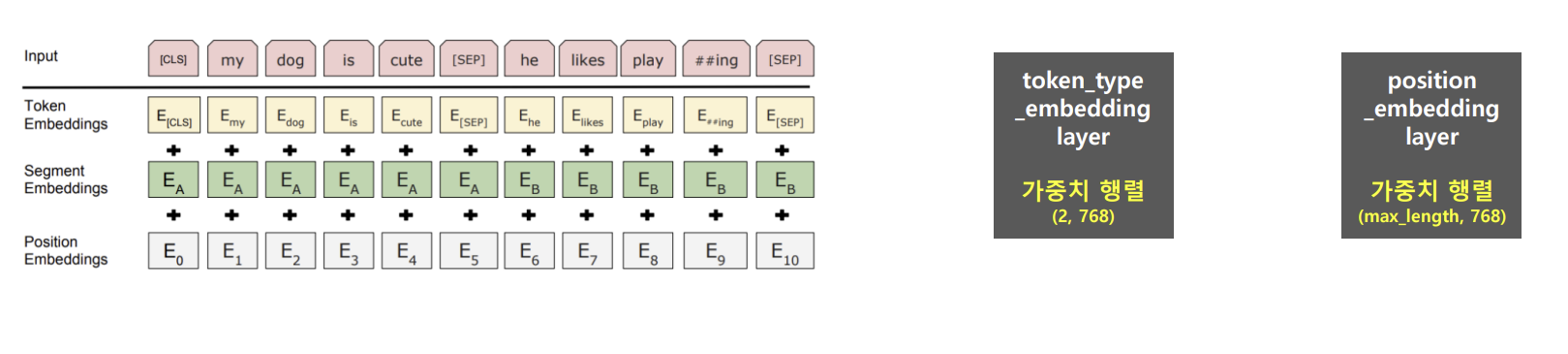
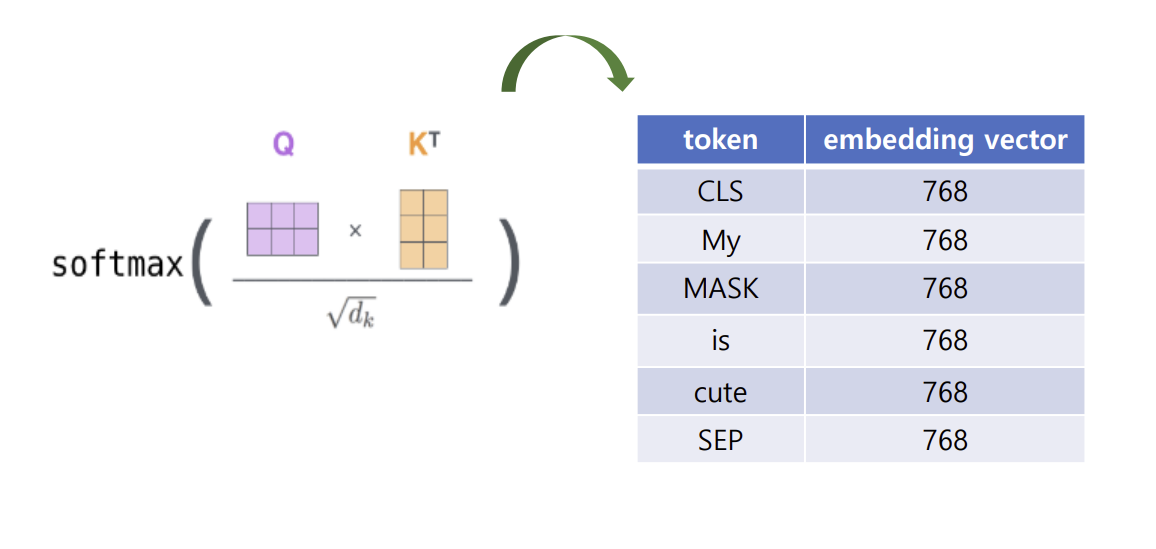
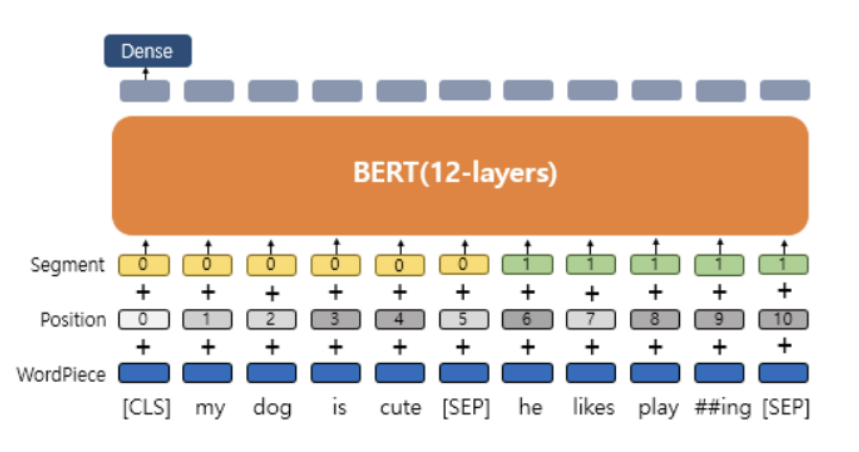
- text 입력 → 토큰화(BertTokenizer) + Masking → Token 임베딩 + Segment 임베딩 + Position 임베딩 → 임베딩 행렬 생성
ex) My dog is cute → [‘My', 'dog', 'is’, 'cute’ ] → [ [CLS], ‘My’, [MASK], 'is’, 'cute’, [SEP] ]
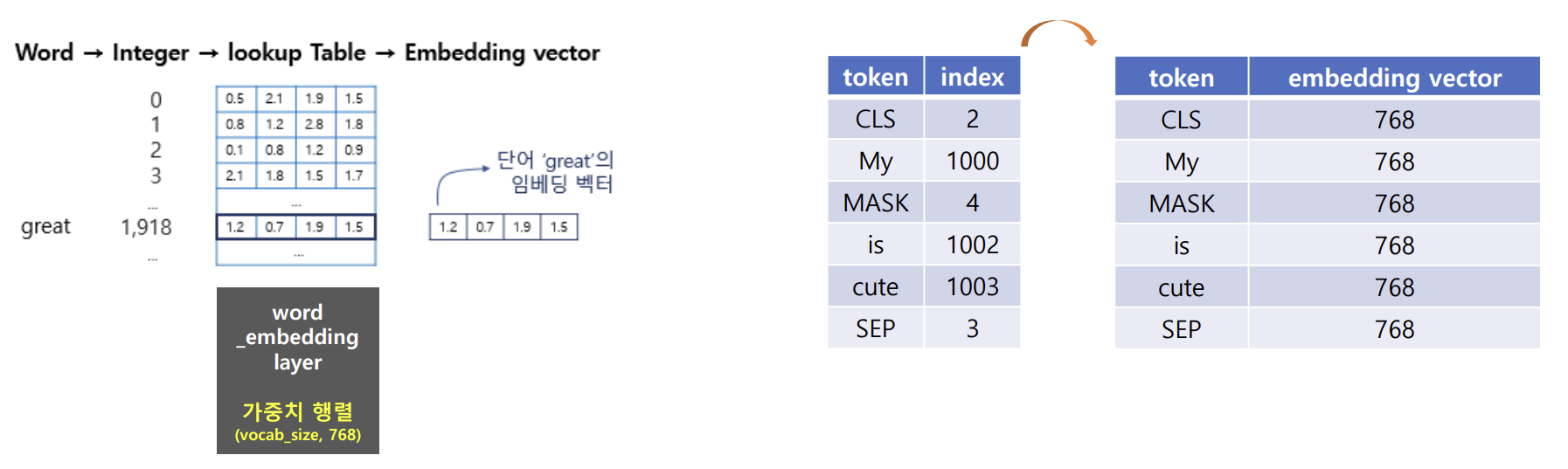
- 임베딩 벡터 size 768로 확장
- Token 임베딩 : 단어의 토큰화
- Segment 임베딩 : 단어가 어떤 클래스(문장)에 해당하는지
- Position 임베딩 : 단어의 위치(문맥&연관성)에 따른 가중치
- 최종 임베딩 행렬 == 3개의 가중합으로 출력됨
동작 과정 2
- q, k, v 벡터 생성
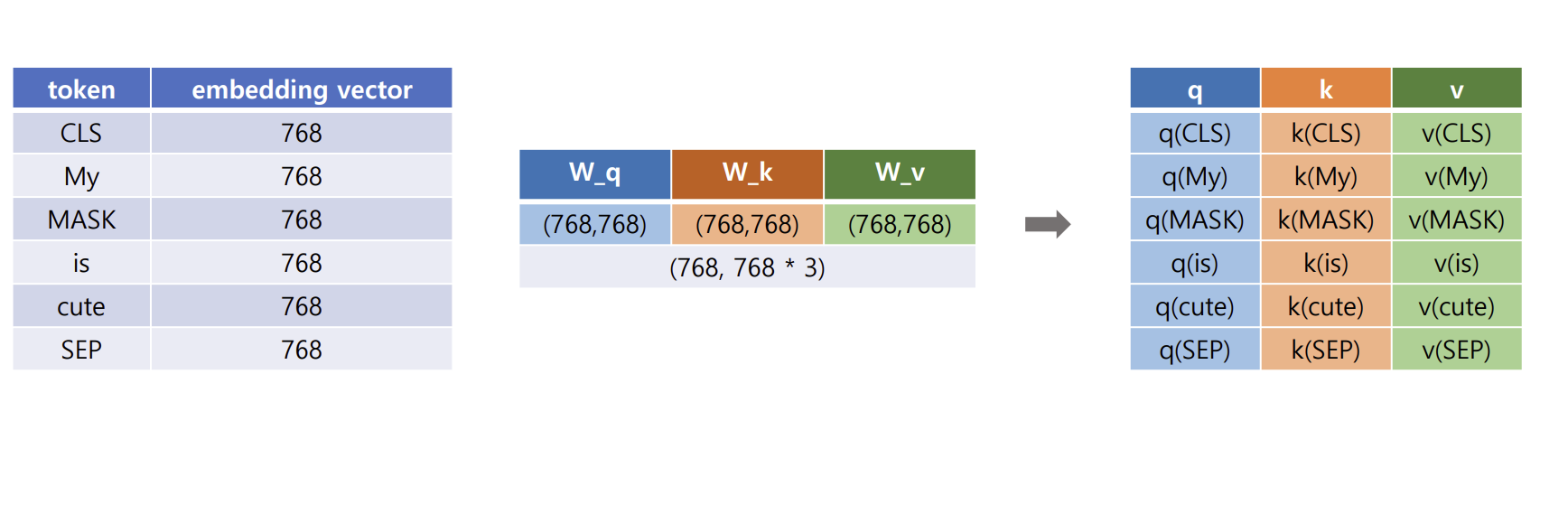
- self-attention과 동일하게 q,k는 attention weight에 활용되고, v는 최종 결과 값에 활용됨 but, MASK값이 추가되었음
동작 과정 3
- self-attention → 문장을 구성하고 있는 각 단어 간의 관계를 반영한 새로운 단어 임베딩 벡터 생성
동작 과정 4
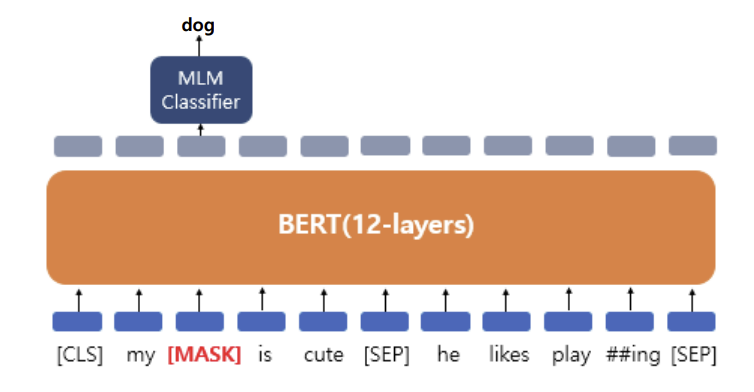
- 정답 토큰 예측 및 가중치 업데이트
- 단어 분류를 위한 Dense layer 추가
- 입력 : MASK 토큰에 대한 최종 임베딩 벡터
- 출력 units = 학습 대상 전체 단어의 수
- 출력 units의 결과 값 → softmax 함수 → 학습 대상 전체 단어에 대한 확률 계산
- 정답의 확률 증가, 나머지 단어의 확률 감소 → 학습 진행(가중치 업데이트)
+ 다음 문장 예측(Next Sentence Prediction, NSP) 방식의 학습
- 두 개의 문장을 입력 후 두 문장이 이어지는 문장인지 아닌지를 맞추는 방식으로 학습
- 두 개의 문장 입력 방식 → 50:50 비율로 실제 이어지는 두 개의 문장과 랜덤으로 이어 붙인 두 개의 문장 입력
- [CLS] token → 결과(Label) 출력 → Label : IsNextSentence or NotNextSentence
BERT 출력 : contextual word embedding vector
- 문장을 구성하는 각 단어들은 문장 내 모든 단어들을 참고한 문맥을 가진 임베딩 벡터가 됨
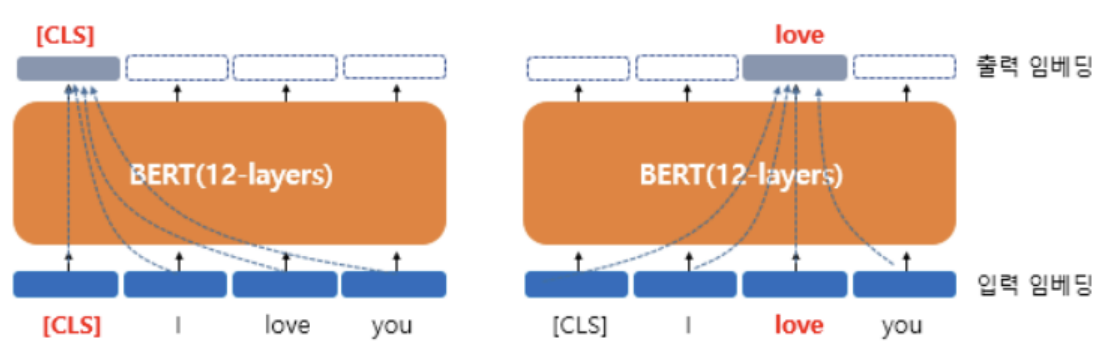
- 임베딩 벡터의 품질 우수 → 문장의 의미를 추출하는데 강점(읽고 이해하기)
1) text 분류
2) 자연어 추론
3) 개체명 인식
4) 질의 응답(QA)(기계 독해, MRC)
참고자료
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (논문)

AI & Robotics