임베딩(Embedding)
정의 : 텍스트를 숫자로 표현
① 방법 : 단어를 숫자로 표현
- 토큰화(token)한 text를 숫자(size)로 표현
- 하나의 숫자의 배열로 바뀜 (numpy 배열식)
- 임베딩의 방식에 따라 표현 형식이 달라짐
② 표현의 형식
- 희소 표현(sparse representation)
- 밀집 표현(dense representation)
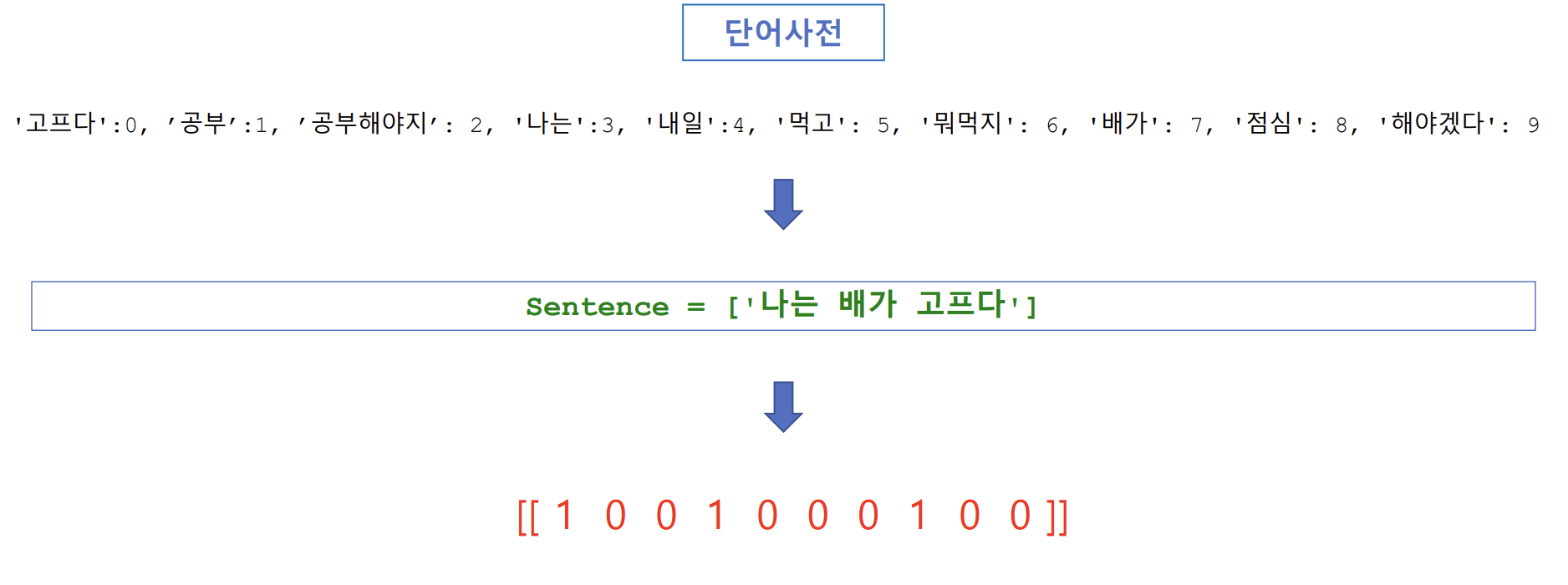
희소 표현(sparse representation)
- 대부분이 0으로 표현되는 방법
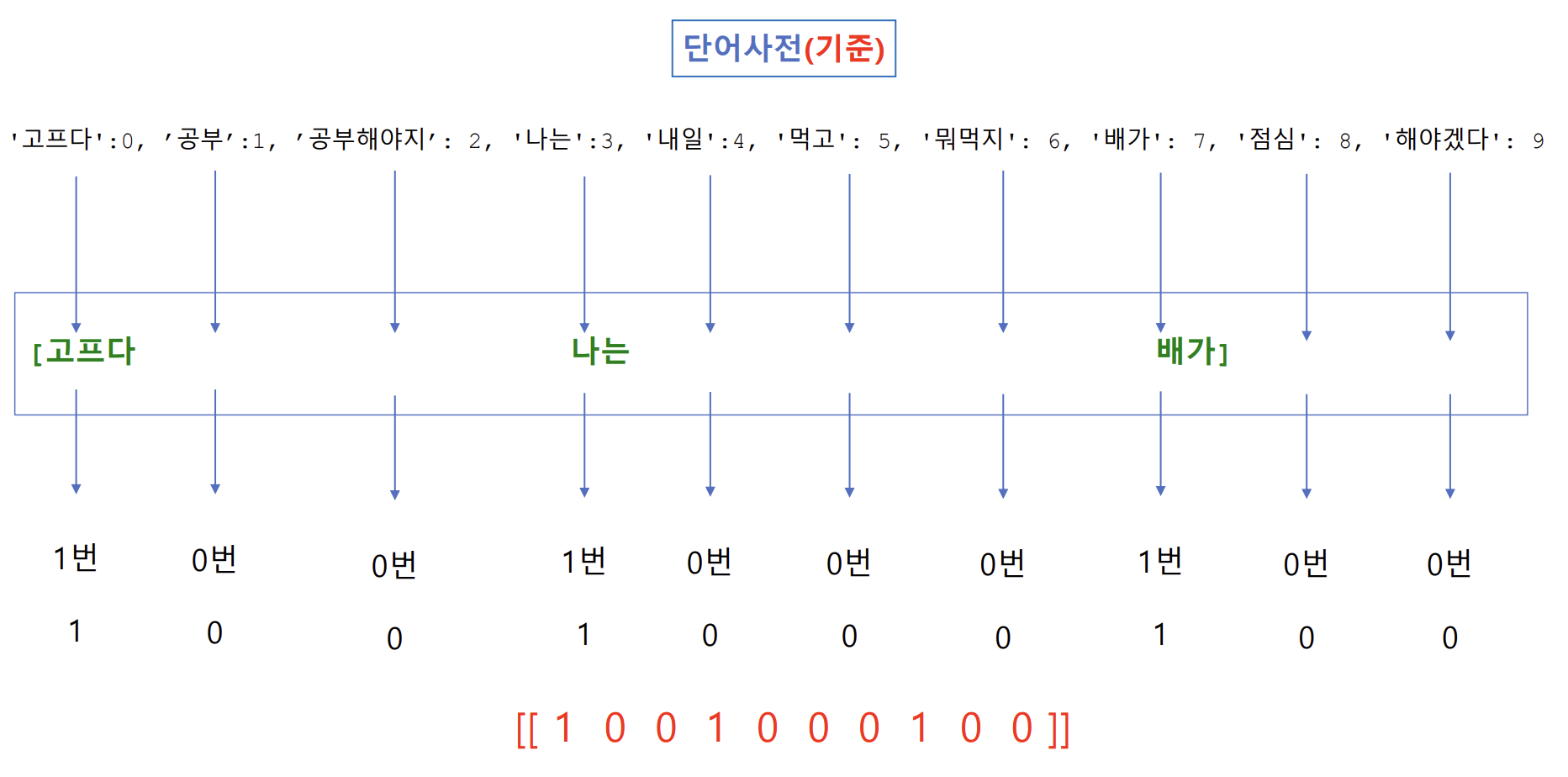
예) 나는 배가 고프다 → [ 1 0 0 1 0 0 0 1 0 0 ]- BoW(Bag of Words)
- 단어들의 문맥이나 순서를 무시
- 단어들의 출현 빈도수를 카운트(count)하여 단어를 수치화, 문장을 수치화하는 방법 => 대부분이 0(데이터로 가치없는 부분)으로 표현됨
- 문맥과 순서를 무시하고 빈도수만 수치화함
(ex - sklearn.~~.CountVectorizer)- 사전에 텍스트 데이터를 입력하여 단어사전을 생성 > 임베딩 할 문장 입력 > 단어사전에 있는 단어들의 출현 빈도수로 위치벡터를 만듬 (주객전도)
- 임베딩한 배열이 표준화가 됨(임베딩되는 형식을 통일할 수 있다): 단어사전 기준으로 임베딩되기 때문에 임베딩할 문장이 매우 길어도 단어사전 길이로 임베딩됨
- BoW으로 제대로 임베딩하려면 단어 사전이 풍부해야함 but, 메모리 소모가 매우 커짐(데이터의 밀집도가 낮다) => 단점이자 한계
- 모델 : CountVectorizer
CountVectorizer 클래스 함수를 이용한 BoW(Bag of Words) 구현
- 개념 : 단어들의 순서는 고려하지 않고, 단어들의 출현 빈도로만 표현하는 수치화 방법
- 구현 방법
① 텍스트 데이터(말뭉치, corpus) → 단어 사전{‘단어’:인덱스} 생성
② 임베딩 할 문장(sentence) : 단어 사전에 있는 각 단어들의 출현 빈도수로 표현
③ sklearn.feature_extraction.text.CountVectorizer 사용
CountVectorizer 클래스 함수를 이용한 BoW 구현 예시
(이 시리즈의 모든 코드는 코랩환경에서 Python으로 작성하였습니다)
sklearn.feature_extraction.text.CountVectorizer 1.3.2 method
- fit(raw_documents, y=None)
- raw_documents = 반복가능한 텍스트 데이터, y는 무시
- 결과를 자기자신에게 저장하기 때문에 추가적인 변수에 저장X
- 토큰화(어절 단위) > 토큰별 단어사전 생성
- vocabulary_ : 만들어진 단어 사전
- transform(raw_documents)
- 임베딩할 단어를 숫자화(임베딩) 해주는 함수
- raw_documents = 반복가능한 데이터
- 결과 : 희소행렬(행, 열)로 리턴함
- 2차원 배열로 데이터프레임을 만들어줌 (매우 중요)
- CountVectorizer의 기본 token_pattern
- r"(?u)\b\w\w+\b” - \b는 단어 경계를 의미하고, \w\w+는 두 글자 이상의 단어를 의미 : len > 1만 단어사전으로 생성함
- 변경하기 위해서는 token_pattern=r"(?u)\b\w+\b” > \w 제거
- CountVectorizer를 활용할 경우 단어 사전과 임베딩할 문장은 모두 list형식으로 만들어서 입력해야함
CountVectorizer Code 1 (한글 텍스트 데이터에 대한 임베딩)
# 클래스 함수 임폴트
from sklearn.feature_extraction.text import CountVectorizer
# 함수 호출, 임베딩 모델 생성
ko_cv = CountVectorizer(token_pattern=r"(?u)\b\w+\b")
en_cv = CountVectorizer(stop_words='english')
##########################################################
# 한글 텍스트 데이터 생성 및 단어 사전 생성
ko_text = ['나는 배가 고프다', '내일 점심 뭐먹지', '내일 공부 해야겠다', '점심 먹고 공부해야지'] #텍스트 데이터 생성
ko_cv.fit(ko_text) #함수호출 > 토큰화(어절 단위) > 토큰별 단어 사전 생성
ko_voca = ko_cv.vocabulary_ #생성된 단어 사전 확인
# 0번부터 재배치된 새로운 단어 사전 생성
sorted_voca = sorted(ko_voca.items(), key=lambda item: item[1])
ko_voca = {word: index for index, (word, _) in enumerate(sorted_voca)}
print(ko_voca)
##########################################################
# 한글 text데이터 임베딩 > 임베딩 행렬 생성
# 임베딩 할 text 생성
ko_sentences1 = ['나는 배가 고프다 내일 점심 먹고 공부 해야겠다']
ko_sentences2 = [ko_text[0], ko_text[1], ko_text[2]]
# transform 함수 호출 (toarray() == 배열로 변환)
ko_matrix1 = ko_cv.transform(ko_sentences1).toarray()
ko_matrix2 = ko_cv.transform(ko_sentences2).toarray()
print(ko_matrix1)
print(f'\n{"-"*80}\n')
print(ko_matrix2)- 사이킷런은 다른 라이브러리와 다르게 무조건 from ~ import로만 사용가능함 (코랩의 사이킷럿 버전은 1.3.2)
- 코랩의 사이킷런 버전에선 단어 사전이 정렬되어있지 않기 때문에
dict(sorted(vocab1.items(), key=lambda x:x[1])) 코드를 사용하여 보기 쉽게 숫자를 기준으로 정렬함
Q) BoW에서 단어사전과 임베딩할 문장을 잘 조절하면 0의 개수를 적게 만들 수 있는데 이러해도 희소표현이라고 하는가?
- 알고리즘 ‘모델’이라 함은 하나의 데이터만 적용되는 것이 아닌 범용성이 중요함 즉, 몇개에 문장에 대해 0이 안나오게 할 수 있지만, 그외 대부분의 문장에 대해는 0을 더 많이 띄우기 때문에 희소표현이라고 할 수 있음
CountVectorizer Code 2 (kiwipiepy를 통해 불용어 제거 후 임베딩)
!pip install kiwipiepy #kiwi 라이브러리 설치
##########################################################
import kiwipiepy
kw = kiwipiepy. Kiwi() #함수 호출
stopword = kiwipiepy.utils.Stopwords() #불용어 함수 호출
##########################################################
sentence_list = [] #전체 결과를 저장할 리스트
for sent in ko_text:
sentence = [] #각 1개마다 결과를 저장할 리스트
morphs_list = kw.tokenize(sent, stopwords=stopword) #한 문장에 대한 형태소 분석 및 불용어 제거
for morph, _, _, _ in morphs_list: #형태소만 추출
sentence.append(morph)
string = ' '.join(sentence)
sentence_list.append(string)
print(sentence_list)# 보충 - join함수
sample = ['나는','배가','고프다']
string = ' '.join(sample)
print(string)- ‘ ‘.join(N) - ‘ ’안에 들어가는 단위'로' N의 원소들을 문자열로 연결
- 불용어를 제거하고 토큰화를 진행한 후 단어 사전을 생성할 경우, 임베딩할 문자도 똑같이 불용어를 제거하고 토큰화하여 진행해야 함 (한글에 경우)
CountVectorizer Code 3 (영어 텍스트 데이터에 대한 임베딩)
# 영어 텍스트 데이터 생성 및 단어 사전 생성
en_text = ['You already know what The Present is',
'You already know where to find it',
'And you already know how it can make you happy and successful',
'You knew it best when you were younger',
'You have simply forgotten']
en_lower = []
for sent in en_text:
en_lower.append(sent.lower())
en_cv.fit(en_lower)
en_voca = en_cv.vocabulary_ #단어 사전 생성
#단어 사전 순서 재배치
sorted_voca = sorted(en_voca.items(), key=lambda item: item[1])
en_voca = {word: index for index, (word, _) in enumerate(sorted_voca)}
print(en_voca)
##########################################################
# 영어 문장 임베딩
# 임베딩 할 텍스트 데이터 소문자로 생성
en_sentences1 = en_lower[:1]
en_sentences2 = en_lower[:]
print(en_sentences1)
print(en_sentences2)
print(f'\n{"-"*80}\n')
# transform 함수 호출
en_matrix1 = en_cv.transform(en_sentences1).toarray()
en_matrix2 = en_cv.transform(en_sentences2).toarray()
print(en_matrix1)
print(f'\n{"-"*80}\n')
print(en_matrix2)참고자료
CountVectorizer - scikit-learn 공식문서
scikit-learn/sklearn/feature_extraction/_stop_words.py (불용어 리스트)

AI & Robotics